使用 API,您无需编写任何代码即可创建和训练自定义 Speech-to-Text 模型,以提高现有 Speech-to-Text 模型的识别准确率。此全托管式服务会自动预配计算资源、执行训练应用代码,并确保在训练作业后删除计算资源。您将获得一个经过完全调优的转写模型,适用于任何下游应用。
与机器学习模型类似,自定义 Speech-to-Text 模型的训练通常是迭代的,涉及选择基本模型作为起点,使用文本和音频数据集对其进行调优,然后测试模型的识别质量。如果结果不符合预期,您可以使用不同数据组合重新训练新模型、再次测试,或直接在您的网域中使用该模型进行转写。
准备工作
确保您已注册 Google Cloud 账号、创建 Google Cloud 项目并启用 Speech-to-Text API:在 Google Cloud 控制台中前往语音,然后进入 Speech-to-Text API。在左侧导航栏的自定义模型部分操作。
创建自定义模型
首先,创建自定义 Speech-to-Text 模型并定义其参数,例如基本模型和转写语言:
- 点击创建以创建自定义模型。
- 输入模型名称,该名称将用于显示,并在 API 请求和 Google Cloud 语音控制台中引用。
- 为模型输入说明。
- 选择最适合您的应用场景的基本模型。
- 选择模型的转写语言。
- 选择应用于进行训练的区域。
- 点击继续。
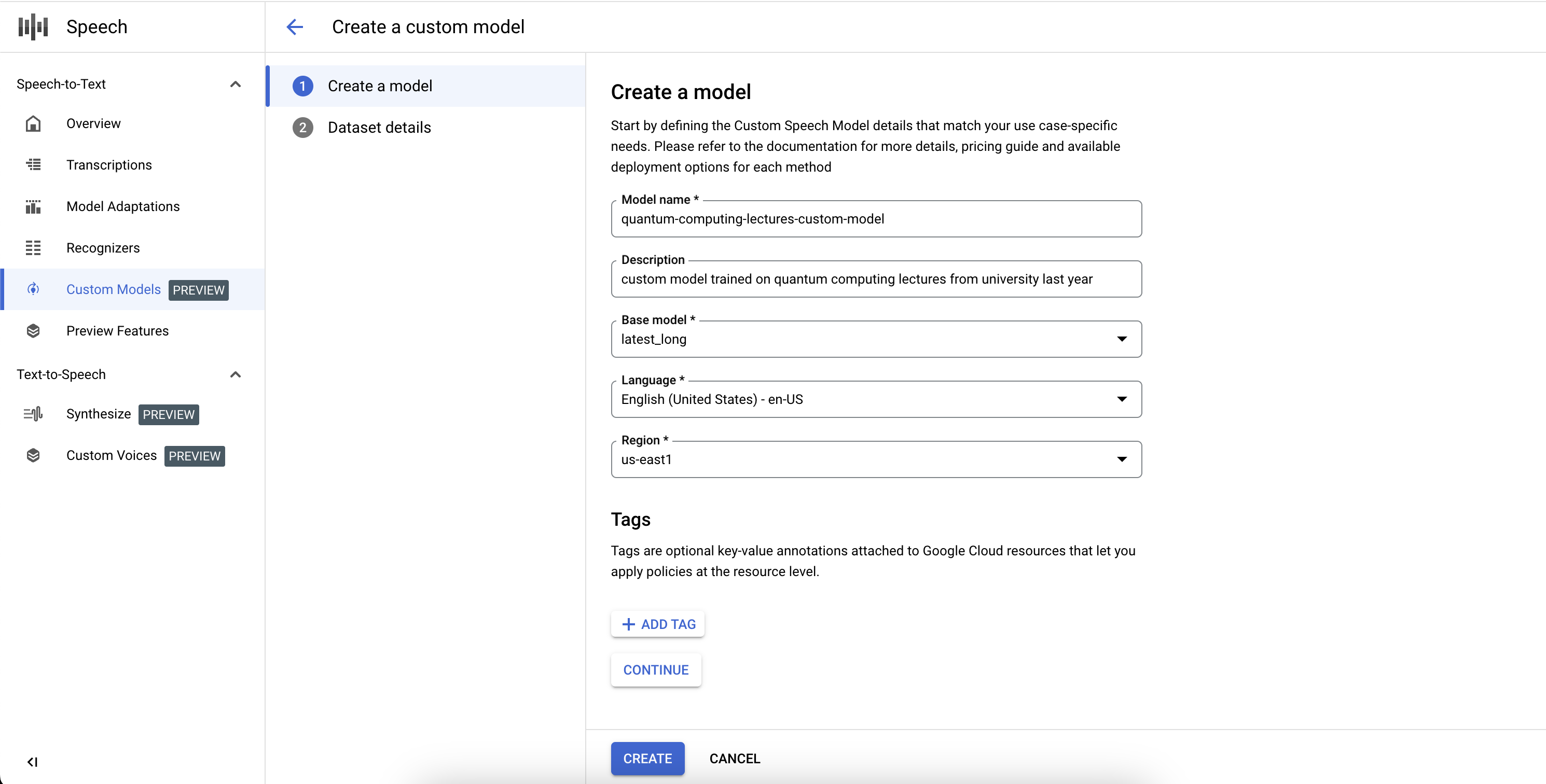
如需完成自定义 Speech-to-Text 模型作业的定义并开始训练,您需要定义训练和验证数据集。
- 通过提供有效的 Cloud Storage 目录 URI,选择训练数据集。确保只存在音频和文本文件,并且音频总时长符合训练数据集要求。
- 通过提供有效的 Cloud Storage 目录 URI,选择验证数据集。确保只存在音频和文本文件,并且音频总时长符合验证数据集要求。
- 点击创建以开始训练过程。
如果在音频小时数不足的情况下编入索引或文件未遵循指南,则训练作业将失败。
训练作业可以在我们系统中的其他作业之后排入队列,训练模型可能需要几个小时到几天的时间,具体取决于数据集大小。模型训练完成后,其状态将被标记为活跃。
删除自定义模型
开始之前,请确保没有通过任何端点路由到您的自定义 Speech-to-Text 模型的流量,因为删除该模型会阻止其处理任何请求。
- 前往自定义模型部分的模型标签页。
- 点击展开选项,然后点击删除。片刻之后,自定义 Speech-to-Text 模型及其所有端点将被删除,不再处理任何流量。
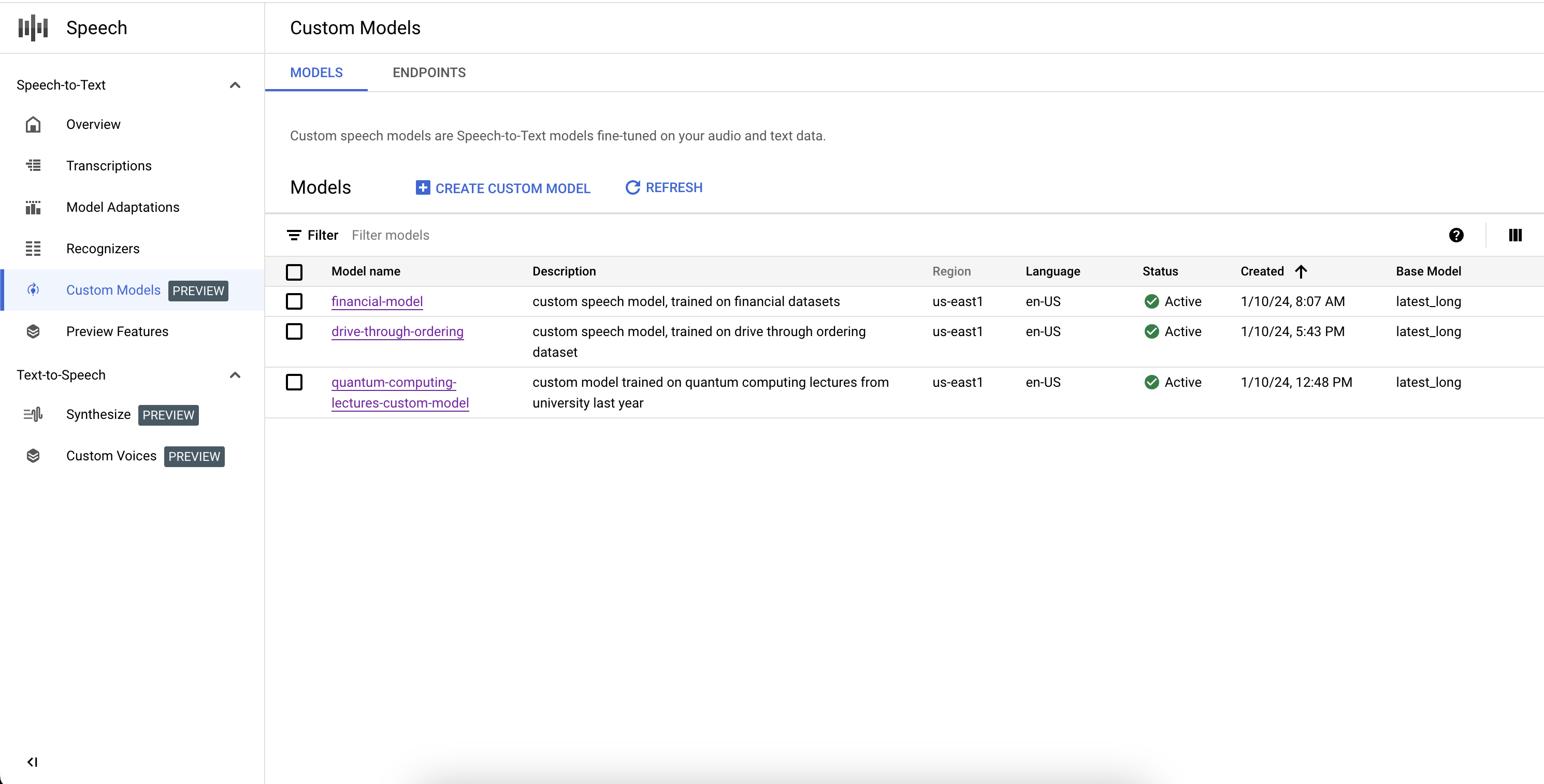
列出您的自定义模型
在自定义模型部分中选择模型后,您还可以列出所有自定义 Speech-to-Text 模型,包括正在训练、活跃和删除的模型。
后续步骤
请按照以下资源在应用中利用自定义语音模型: