Usando a API, sem código, é possível criar e treinar um modelo personalizado do Speech-to-Text para melhorar a acurácia do reconhecimento de um modelo que já existe. Esse serviço totalmente gerenciado provisiona automaticamente recursos de computação, executa o código do aplicativo de treinamento e garante a exclusão desses recursos após o job de treinamento. Você recebe um modelo de transcrição totalmente ajustado que é útil para qualquer aplicativo downstream.
Assim como os modelos de machine learning, o treinamento de um modelo personalizado do Speech-to-Text é geralmente iterativo e envolve selecionar um modelo base como ponto de partida, ajustá-lo com seus conjuntos de dados de texto e áudio e testar a qualidade de reconhecimento do modelo. Se os resultados não forem o esperado, treine novamente um modelo novo com uma combinação diferente de dados, teste novamente ou use-o diretamente para transcrição no seu domínio.
Antes de começar
Verifique se você se inscreveu em uma conta do Google Cloud , criou um projeto do Google Cloud e ativou a API Speech-to-Text: acesse Speech no console do Google Cloud e navegue até a API Speech-to-Text. Trabalhe na seção Modelos Personalizados da barra de navegação à esquerda.
Criar um modelo personalizado
Comece com a criação de um modelo personalizado do Speech-to-Text e defina os parâmetros dele, como modelo base e idioma de transcrição:
- Clique em Criar para gerar um modelo personalizado.[
- Insira um Nome do modelo, que será usado para exibição e referenciado nas suas solicitações de API e no console do Speech Google Cloud .
- Insira uma Descrição para o modelo.
- Selecione o Modelo base mais adequado ao seu caso de uso.
- Selecione o Idioma de transcrição do modelo.
- Selecione a Região onde o treinamento será realizado.
- Clique em Continuar.
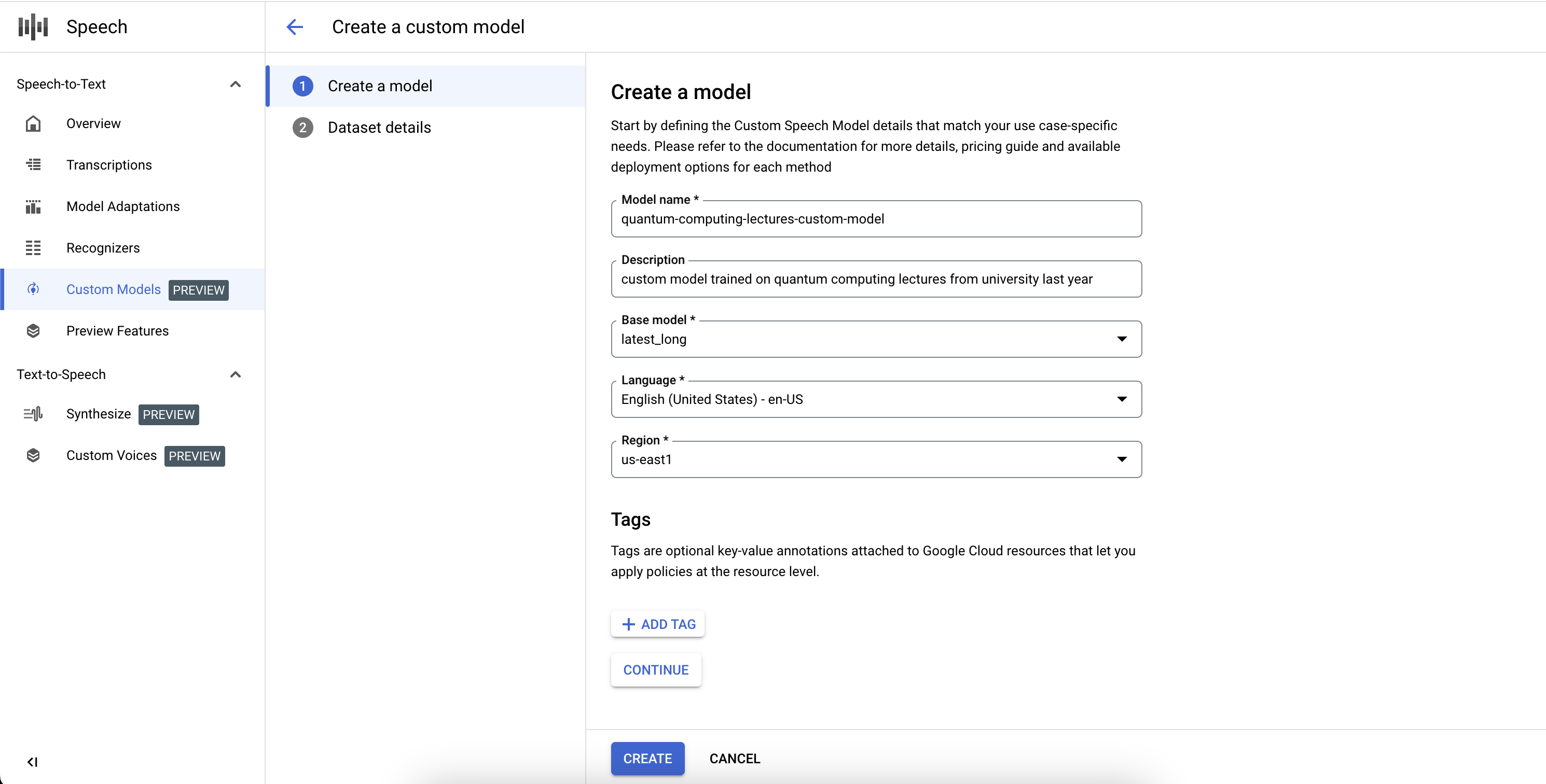
Para concluir a definição do job do modelo personalizado do Speech-to-Text e iniciar o treinamento, você precisará definir os conjuntos de dados de treinamento e de validação.
- Selecione um conjunto de dados de treinamento fornecendo um URI válido do diretório do Cloud Storage. Verifique se há apenas arquivos de áudio e texto e se a duração total do áudio segue os requisitos do conjunto de dados de treinamento.
- Selecione um conjunto de dados de validação fornecendo um URI válido do diretório do Cloud Storage. Verifique se há apenas arquivos de áudio e texto e se a duração total do áudio segue os requisitos do conjunto de dados de validação.
- Clique em Criar para iniciar o processo de treinamento.
Se não houver horas de áudio suficientes indexadas ou os arquivos não seguirem as diretrizes, o job de treinamento falhará.
Os jobs de treinamento podem ser enfileirados atrás de outros jobs em nosso sistema, e o treinamento de um modelo pode levar de algumas horas a alguns dias, dependendo do tamanho do conjunto de dados. Após o treinamento de modelo, o estado dele será sinalizado como Ativo.
Excluir um modelo personalizado
Antes de começar, verifique se não há nenhum tráfego roteado para o modelo personalizado do Speech-to-Text por qualquer endpoint, porque a exclusão impedirá que ele atenda às solicitações.
- Acesse a guia Modelos da seção Modelos Personalizados.
- Clique para expandir as opções e depois em Excluir. Após alguns instantes, o modelo personalizado do Speech-to-Text será excluído com todos os endpoints e deixará de atender a qualquer tráfego.
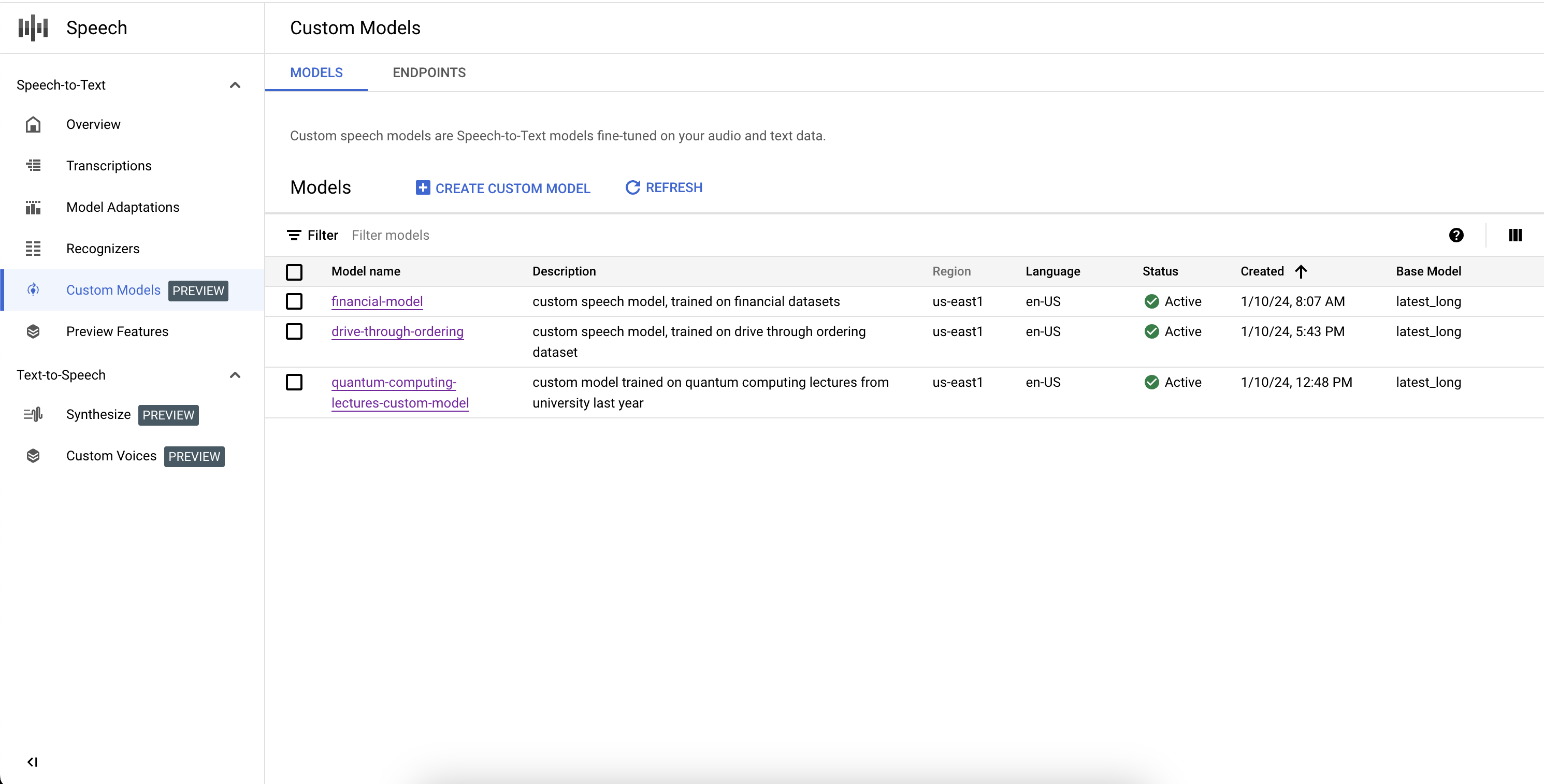
Listar os modelos personalizados
Ao selecionar os Modelos na seção Modelos Personalizados, também é possível listar todos os modelos do Speech-to-Text, incluindo aqueles que estão em treinamento, ativos e sendo excluídos.
A seguir
Siga os recursos para aproveitar os modelos de fala personalizados no seu aplicativo:
- Implantar e gerenciar endpoints de modelo
- Usar os modelos personalizados
- Avaliar os modelos personalizados