在生产应用或基准化分析工作流中使用经过训练的自定义 Speech-to-Text 模型。您必须通过专用端点部署和公开模型,创建的端点部分用于在所选区域中部署模型。您可以通过识别器对象自动获取程序化访问权限。您可以直接通过 V2 API 或在 Google Cloud 控制台中使用模型。您可以在与训练模型不同的区域中部署模型,但系统会在端点指定的区域中创建模型的副本。
如需使用自定义语音模型,您需要通过专用端点进行部署和公开。通过创建端点,您可以在所选区域中部署模型。您通过识别器对象自动获得程序化访问权限,从而直接通过 V2 API 进行推理或在 Google Cloud 控制台中使用。
准备工作
确保您已注册 Google Cloud 账号、创建项目并训练自定义语音模型。
- 前往 Google Cloud 控制台中的语音,然后进入 Speech-to-Text。
- 前往左侧导航栏的自定义模型部分。
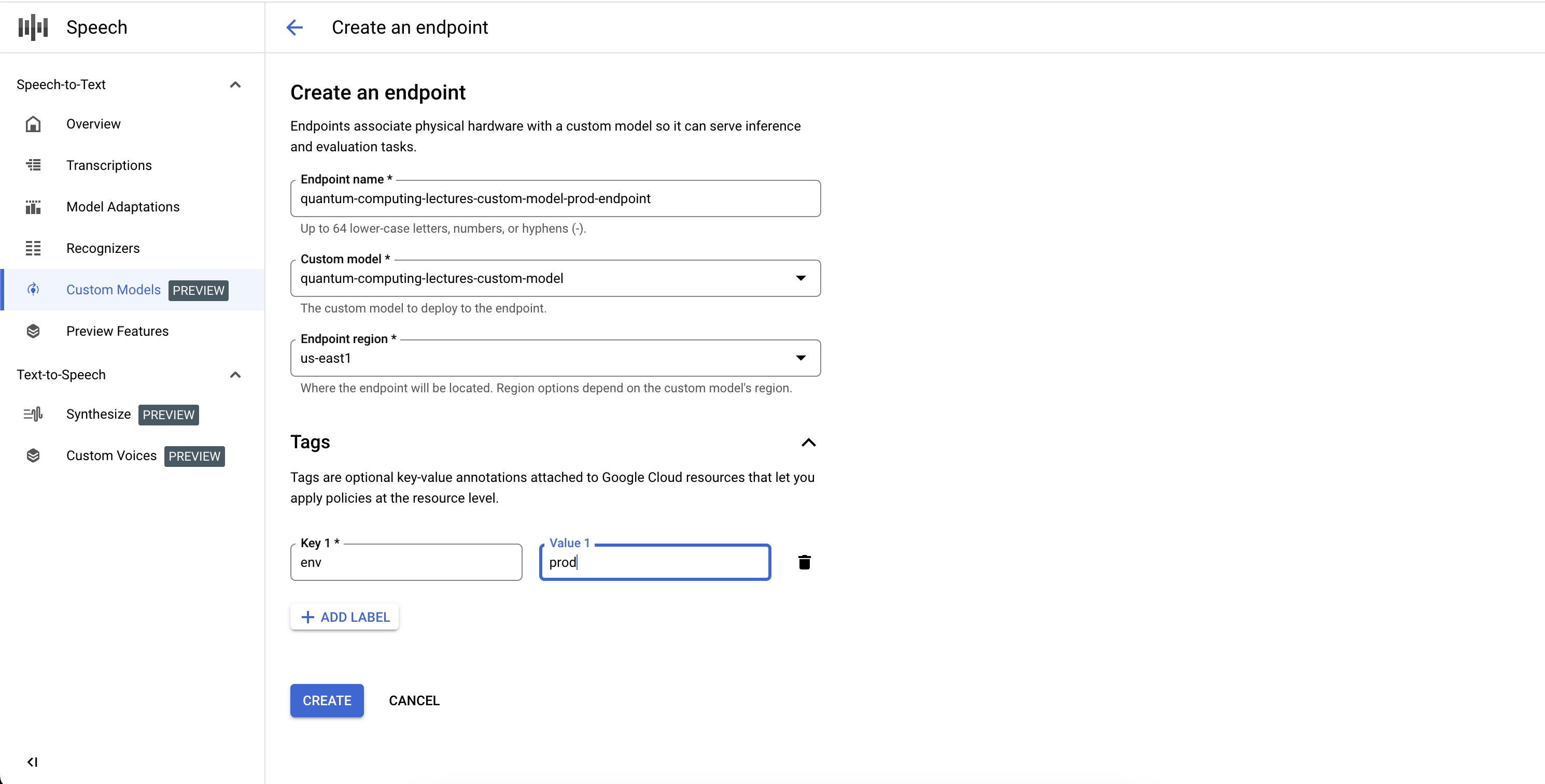
创建端点
- 前往自定义模型部分的端点标签页。
- 点击新建端点。
- 定义端点的名称。该名称充当端点资源的唯一标识符,用于调用自定义语音模型以进行推理。
- 定义要在其中部署自定义语音模型的区域。如果训练模型的区域与端点配置中定义的区域不同,则系统会自动创建新的模型副本。
- 从您希望通过端点公开的列表中选择经过训练的自定义语音模型。
- 点击创建,片刻之后,自定义语音模型就会部署到端点中,可随时用于推理和基准化分析。
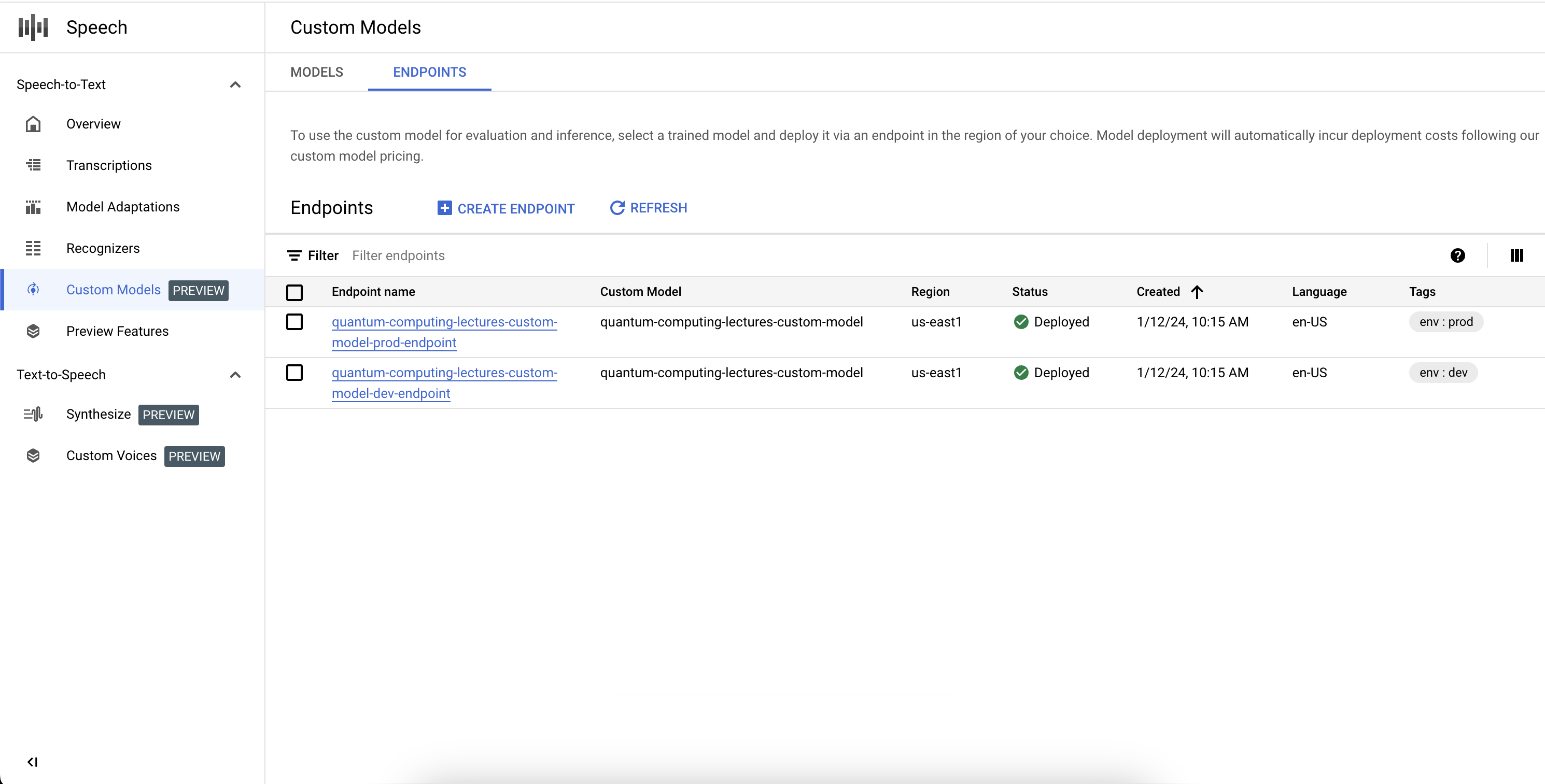
列出端点
您可以通过选择“自定义模型”部分下的“端点”标签页,在控制台中管理关联的端点。您还可以列出您在控制台中创建的端点,以及其当前状态和关联的自定义 Speech-to-Text 模型。
删除端点
开始之前,请确保没有通过端点路由的流量,因为删除端点会阻止其处理任何请求。
- 前往自定义模型部分的端点标签页。
- 在端点标签页下,点击展开选项,然后点击删除。片刻之后,端点就会被删除,不再处理任何流量。
对模型进行基准测试
如需使用自定义 Speech-to-Text 模型和基准化分析数据集来评估模型的准确率,请按照衡量并提高准确率指南进行操作。