Chirp 3 是 Google 最新一代多语言 ASR 专用生成模型,旨在根据用户反馈和体验满足用户需求。在准确率和速度方面,它比原始 Chirp 和 Chirp 2 模型有所改进,同时还扩展了讲话人区分功能等关键新功能。
模型详情
Chirp_3 详细信息
模型标识符
Chirp 3 仅在 Speech-to-Text API V2 中可用,您可以像使用任何其他模型一样使用它。使用 API 时,请在识别请求中指定相应的标识符;使用 Google Cloud 控制台时,请指定模型名称。
| 模型 | 型号标识符 |
| Chirp 3 | chirp_3 |
API 方法
并非所有识别方法都支持相同的语言可用性集,因为 Chirp 3 可在 Speech-to-Text API V2 中使用,所以它支持以下识别方法:
| API | API 方法支持 | 支持 |
| v2 | Speech.BatchRecognize(适合 1 分钟到 1 小时的长音频) | 支持 |
| v2 | Speech.Recognize(非常适合时长短于 1 分钟的音频) | 不支持 |
| v2 | Speech.StreamingRecognize (适用于流式音频和实时音频) | 不支持 |
区域可用性
Chirp 3 已在以下 Google Cloud 区域推出,未来还计划在更多区域推出:
| Google Cloud 可用区 | 发布就绪情况 |
| us-west1 | 非公开预览版 |
按照此处的说明使用地理位置 API,您可以找到每个转写模型支持的最新 Google Cloud 区域、语言和语言区域以及功能列表。
转写功能的语言支持情况
Chirp 3 支持在 BatchRecognize 中转录以下语言:
| 语言 | BCP-47 代码 |
| 阿拉伯语(埃及) | ar-EG |
| 阿拉伯语(沙特阿拉伯) | ar-SA |
| 孟加拉语(孟加拉) | bn-BD |
| 孟加拉语(印度) | bn-IN |
| 捷克语(捷克共和国) | cs-CZ |
| 丹麦语(丹麦) | da-DK |
| 希腊语(希腊) | el-GR |
| 西班牙语(墨西哥) | es-MX |
| 爱沙尼亚语(爱沙尼亚) | et-EE |
| 波斯语(伊朗) | fa-IR |
| 芬兰语(芬兰) | fi-FI |
| 菲律宾语(菲律宾) | fil-PH |
| 法语(加拿大) | fr-CA |
| 古吉拉特语(印度) | gu-IN |
| 克罗地亚语(克罗地亚) | hr-HR |
| 匈牙利语(匈牙利) | hu-HU |
| 印度尼西亚语(印度尼西亚) | id-ID |
| 希伯来语(以色列) | iw-IL |
| 卡纳达语(印度) | kn-IN |
| 立陶宛语(立陶宛) | lt-LT |
| 拉脱维亚语(拉脱维亚) | lv-LV |
| 马拉雅拉姆语(印度) | ml-IN |
| 马拉地语(印度) | mr-IN |
| 荷兰语(荷兰) | nl-NL |
| 挪威语(挪威) | no-NO |
| 旁遮普语(印度) | pa-IN |
| 波兰语(波兰) | pl-PL |
| 葡萄牙语(葡萄牙) | pt-PT |
| 罗马尼亚语(罗马尼亚) | ro-RO |
| 俄语(俄罗斯) | ru-RU |
| 斯洛伐克语(斯洛伐克) | sk-SK |
| 斯洛文尼亚语(斯洛文尼亚) | sl-SI |
| 塞尔维亚语(塞尔维亚) | sr-RS |
| 瑞典语(瑞典) | sv-SE |
| 泰米尔语(印度) | ta-IN |
| 泰卢固语(印度) | te-IN |
| 泰语(泰国) | th-TH |
| 土耳其语(土耳其) | tr-TR |
| 乌克兰语(乌克兰) | uk-UA |
| 乌尔都语(巴基斯坦) | ur-PK |
| 越南语(越南) | vi-VN |
| 中文(中国) | zh-CN |
| 中文(台湾) | zh-TW |
| 祖鲁语(南非) | zu-SA |
讲话人区分功能支持的语言
| 语言 | BCP-47 代码 |
| 简体中文 | cmn-Hans-CN |
| 德语(德国) | de-DE |
| 英语(澳大利亚) | en-AU |
| 英语(英国) | en-GB |
| 英语(印度) | en-IN |
| 英语(美国) | en-US |
| 西班牙语(西班牙) | en-ES |
| 西班牙语(美国) | en-US |
| 法语(法国) | fr-FR |
| 印地语(印度) | hi-IN |
| 意大利语(意大利) | it-IT |
| 日语(日本) | ja-JP |
| 韩语(韩国) | ko-KR |
| 葡萄牙语(巴西) | pt-BR |
功能支持和限制
Chirp 3 支持以下功能:
| 功能 | 说明 | 发布阶段 |
| 自动加注标点符号 | 由模型自动生成,可选择停用。 | 预览 |
| 自动大写 | 由模型自动生成,可选择停用。 | 预览 |
| 讲话人区分 | 自动识别单声道音频样本中的不同讲话人。 | 预览 |
| 与语言无关的音频转写。 | 模型会自动推断出音频文件中所讲的语言,并以最常用的语言进行转写。 | 预览 |
Chirp 3 不支持以下功能:
| 功能 | 说明 |
| 字词计时(时间戳) | 由模型自动生成,可选择停用。 |
| 字词级置信度分数 | API 会返回一个值,但这不是真正的置信度分数。 |
| 语音自适应(自定义调整) | 以短语或字词的形式向模型提供提示,以提高特定术语或专有名词的识别准确率。 |
使用 Chirp 3
使用 Chirp 3 执行转写和讲话人区分任务。
使用 Chirp 3 批量请求进行转写(带区分词)
了解如何使用 Chirp 3 来满足您的转写需求
执行批量语音识别
允许 Cloud Speech 服务读取您的 Cloud Storage 存储桶(非公开预览版暂时需要这样做)。您可以使用命令行通过 Google Cloud CLI 命令完成此操作:
gcloud storage buckets add-iam-policy-binding gs://<YOUR_BUCKET_NAME_HERE> --member=serviceAccount:service-727103546492@gcp-sa-aiplatform.iam.gserviceaccount.com --role=roles/storage.objectViewer
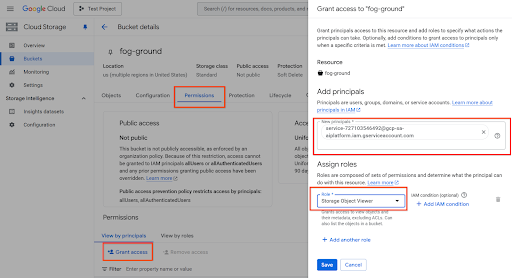
或者,您也可以使用 Cloud 控制台,前往 http://console.cloud.google.com/storage/browser,选择您的存储桶 > 点击权限 > 授予访问权限 > 添加服务账号,如下所示:
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-west1-speech.googleapis.com",
)
)
speaker_diarization_config = cloud_speech.SpeakerDiarizationConfig(
min_speaker_count=1, # minimum number of speakers
max_speaker_count=6, # maximum expected number of speakers
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
diarization_config=speaker_diarization_config,
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-west1/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript