O Chirp 3 é a geração mais recente dos modelos generativos multilingues específicos de ASR da Google, concebidos para satisfazer as necessidades dos utilizadores com base no feedback e na experiência. Melhora os modelos originais Chirp e Chirp 2 em termos de precisão e velocidade, além de expandir-se para novas funcionalidades importantes, como a segmentação por orador.
Detalhes do modelo
Detalhes do Chirp_3
Identificadores do modelo
O Chirp 3 só está disponível na API Speech-to-Text V2 e pode usá-lo como qualquer outro modelo. Especifique o identificador adequado no seu pedido de reconhecimento quando usar a API ou o nome do modelo quando usar a Google Cloud consola.
| Modelo | Identificador do modelo |
| Chirp 3 | chirp_3 |
Métodos da API
Nem todos os métodos de reconhecimento suportam os mesmos conjuntos de disponibilidade de idiomas, uma vez que o Chirp 3 está disponível na API Speech-to-Text V2 e suporta os seguintes métodos de reconhecimento:
| API | Suporte de métodos da API | Apoio técnico |
| v2 | Voz. BatchRecognize (bom para áudio longo de 1 minuto a 1 hora) | Suportado |
| v2 | Speech.Recognize (adequado para áudio com menos de um minuto) | Não suportado |
| v2 | Speech.StreamingRecognize (adequado para streaming e áudio em tempo real) | Não suportado |
Disponibilidade regional
O Chirp 3 está disponível nas seguintes Google Cloud regiões, com mais regiões planeadas:
| Google Cloud Zona | Disposição para o lançamento |
| us-west1 | Pré-visualização privada |
Usando a API Locations, conforme explicado aqui, pode encontrar a lista mais recente de regiões, idiomas e locais, e funcionalidades suportados Google Cloud para cada modelo de transcrição.
Idiomas disponíveis para a transcrição
O Chirp 3 suporta a transcrição em BatchRecognize apenas nos seguintes idiomas:
| Idioma | Código BCP-47 |
| Árabe (Egito) | ar-EG |
| Árabe (Arábia Saudita) | ar-SA |
| Bengali (Bangladexe) | bn-BD |
| Bengali (Índia) | bn-IN |
| Checo (Chéquia) | cs-CZ |
| Dinamarquês (Dinamarca) | da-DK |
| Grego (Grécia) | el-GR |
| Espanhol (México) | es-MX |
| Estónio (Estónia) | et-EE |
| Persa (Irão) | fa-IR |
| Finlandês (Finlândia) | fi-FI |
| Filipino (Filipinas) | fil-PH |
| Francês (Canadá) | fr-CA |
| Guzerate (Índia) | gu-IN |
| Croata (Croácia) | hr-HR |
| Húngaro (Hungria) | hu-HU |
| Indonésio (Indonesia) | id-ID |
| Hebraico (Israel) | iw-IL |
| Canarim (Índia) | kn-IN |
| Lituano (Lituânia) | lt-LT |
| Letão (Letónia) | lv-LV |
| Malaiala (Índia) | ml-IN |
| Marati (Índia) | mr-IN |
| Neerlandês (Países Baixos) | nl-NL |
| Norueguês (Noruega) | no-NO |
| Punjabi (Índia) | pa-IN |
| Polaco (Polónia) | pl-PL |
| Português (Portugal) | pt-PT |
| Romeno (Roménia) | ro-RO |
| Russo (Rússia) | ru-RU |
| Eslovaco (Eslováquia) | sk-SK |
| Esloveno (Eslovénia) | sl-SI |
| Sérvio (Sérvia) | sr-RS |
| Sueco (Suécia) | sv-SE |
| Tâmil (Índia) | ta-IN |
| Telugu (Índia) | te-IN |
| Tailandês (Tailândia) | th-TH |
| Turco (Turquia) | tr-TR |
| Ucraniano (Ucrânia) | uk-UA |
| Urdu (Paquistão) | ur-PK |
| Vietnamita (Vietname) | vi-VN |
| Chinês (China) | zh-CN |
| Chinês (Taiwan) | zh-TW |
| Zulu (África do Sul) | zu-SA |
Idiomas disponíveis para a separação de oradores
| Idioma | Código BCP-47 |
| Chinês (simplificado, China) | cmn-Hans-CN |
| Alemão (Alemanha) | de-DE |
| Inglês (Austrália) | en-AU |
| Inglês (Reino Unido) | en-GB |
| Inglês (Índia) | en-IN |
| Inglês (Estados Unidos) | en-US |
| Espanhol (Espanha) | es-ES |
| Espanhol (Estados Unidos) | es-US |
| Francês (França) | fr-FR |
| Hindi (Índia) | hi-IN |
| Italiano (Itália) | it-IT |
| Japonês (Japão) | ja-JP |
| Coreano (Coreia) | ko-KR |
| Português (Brasil) | pt-BR |
Suporte de funcionalidades e limitações
O Chirp 3 suporta as seguintes funcionalidades:
| Funcionalidade | Descrição | Fase de lançamento |
| Pontuação automática | Geradas automaticamente pelo modelo e podem ser desativadas opcionalmente. | Pré-visualização |
| Letras maiúsculas automáticas | Geradas automaticamente pelo modelo e podem ser desativadas opcionalmente. | Pré-visualização |
| Diarização de oradores | Identificar automaticamente os diferentes oradores numa amostra de áudio de canal único. | Pré-visualização |
| Transcrição de áudio independente do idioma. | O modelo infere automaticamente o idioma falado no seu ficheiro de áudio e transcreve-o no idioma mais predominante. | Pré-visualização |
O Chirp 3 não suporta as seguintes funcionalidades:
| Funcionalidade | Descrição |
| Indicações de tempo das palavras (datas/horas) | Geradas automaticamente pelo modelo e podem ser desativadas opcionalmente. |
| Pontuações de confiança ao nível da palavra | A API devolve um valor, mas não é verdadeiramente uma pontuação de confiança. |
| Adaptação da voz (tendência) | Forneça sugestões ao modelo sob a forma de expressões ou palavras para melhorar a precisão do reconhecimento de termos específicos ou nomes próprios. |
Usar o Chirp 3
Usar o Chirp 3 para tarefas de transcrição e segmentação de oradores.
Transcreva através do pedido em lote do Chirp 3 com diarização
Descubra como usar o Chirp 3 para as suas necessidades de transcrição
Realize o reconhecimento de voz em lote
Permitir que o serviço Cloud Speech leia o seu contentor de armazenamento do Cloud Storage (isto é necessário temporariamente durante a pré-visualização privada). Isto pode ser feito através da linha de comandos com o comando da CLI gcloud:
gcloud storage buckets add-iam-policy-binding gs://<YOUR_BUCKET_NAME_HERE> --member=serviceAccount:service-727103546492@gcp-sa-aiplatform.iam.gserviceaccount.com --role=roles/storage.objectViewer
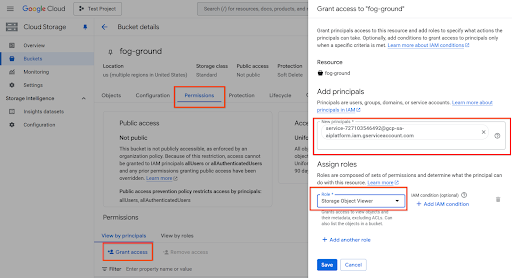
Em alternativa, use a Cloud Console navegando para http://console.cloud.google.com/storage/browser, escolha o seu contentor > clique em Autorizações > Conceder acesso > adicione a conta de serviço, da seguinte forma:
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-west1-speech.googleapis.com",
)
)
speaker_diarization_config = cloud_speech.SpeakerDiarizationConfig(
min_speaker_count=1, # minimum number of speakers
max_speaker_count=6, # maximum expected number of speakers
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
diarization_config=speaker_diarization_config,
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-west1/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript