Chirp 2 is the latest generation of Google's multilingual ASR-specific models, designed to meet user needs based on feedback and experience. It improves on the original Chirp model in accuracy and speed, as well as expanding into key new features like word-level timestamps, model adaptation, and speech translation.
|
|
 View notebook on GitHub View notebook on GitHub
|
Model details
Chirp 2 is exclusively available within the Speech-to-Text API V2.
Model identifiers
You can utilize Chirp 2 just like any other model by specifying the appropriate model identifier in your recognition request when using the API or the model name while in the Google Cloud console.
| Model | Model identifier |
|---|---|
| Chirp 2 | chirp_2 |
API methods
As Chirp 2 is exclusively available within the Speech-to-Text API V2, it supports the following recognition methods:
| Model | Model identifier | Language support |
|---|---|---|
V2 |
Speech.StreamingRecognize (good for streaming and real-time audio) |
Limited* |
V2 |
Speech.Recognize (good for short audio < 1 min) |
On par with Chirp |
V2 |
Speech.BatchRecognize (good for long audio 1 min to 8 hrs) |
On par with Chirp |
*You can always find the latest list of supported languages and features for each transcription model, using the locations API.
Regional availability
Chirp 2 is supported in the following regions:
| Google Cloud Zone | Launch Readiness |
|---|---|
us-central1 |
GA |
europe-west4 |
GA |
asia-southeast1 |
GA |
You can always find the latest list of supported Google Cloud regions, languages, and features for each transcription model, using the locations API as explained here.
Language availability for transcription
Chirp 2 supports transcription in StreamingRecognize, Recognize and BatchRecognize recognition methods. Language support however differs depending on the method used. Specifically BatchRecognize offers the most extensive language support. StreamingRecognize supports the following languages:
| Language | BCP-47 Code |
|---|---|
| Chinese (Simplified, China) | cmn-Hans-CN |
| Chinese (Traditional, Taiwan) | cmn-Hant-TW |
| Chinese, Cantonese (Traditional Hong Kong) | yue-Hant-HK |
| English (Australia) | en-AU |
| English (India) | en-IN |
| English (United Kingdom) | en-GB |
| English (United States) | en-US |
| French (Canada) | fr-CA |
| French (France) | fr-FR |
| German (Germany) | de-DE |
| Italian (Italy) | it-IT |
| Japanese (Japan) | ja-JP |
| Korean (South Korea) | ko-KR |
| Portuguese (Brazil) | pt-BR |
| Spanish (Spain) | es-ES |
| Spanish (United States) | es-US |
Language availability for translation
These are the supported languages for speech translation. Note that Chirp 2's language support for translation is not symmetrical. This means that while we may be able to translate from Language A to Language B, translation from Language B to Language A might not be available. The following language pairs are supported for Speech-Translation.
For translation to English:
| Source -> Target Language | Source -> Target Language Code |
|---|---|
| Arabic (Egypt) -> English | ar-EG -> en-US |
| Arabic (Gulf) -> English | ar-x-gulf -> en-US |
| Arabic (Levant) -> English | ar-x-levant -> en-US |
| Arabic (Maghrebi) -> English | ar-x-maghrebi -> en-US |
| Catalan (Spain) -> English | ca-ES -> en-US |
| Welsh (United Kingdom) -> English | cy-GB -> en-US |
| German (Germany) -> English | de-DE -> en-US |
| Spanish (Latin America) -> English | es-419 -> en-US |
| Spanish (Spain) -> English | es-ES -> en-US |
| Spanish (United States) -> English | es-US -> en-US |
| Estonian (Estonia) -> English | et-EE -> en-US |
| French (Canada) -> English | fr-CA -> en-US |
| French (France) -> English | fr-FR -> en-US |
| Persian (Iran) -> English | fa-IR -> en-US |
| Indonesian (Indonesia) -> English | id-ID -> en-US |
| Italian (Italy) -> English | it-IT -> en-US |
| Japanese (Japan) -> English | ja-JP -> en-US |
| Latvian (Latvia) -> English | lv-LV -> en-US |
| Mongolian (Mongolia) -> English | mn-MN -> en-US |
| Dutch (Netherlands) -> English | nl-NL -> en-US |
| Portuguese (Brazil) -> English | pt-BR -> en-US |
| Russian (Russia) -> English | ru-RU -> en-US |
| Slovenian (Slovenia) -> English | sl-SI -> en-US |
| Swedish (Sweden) -> English | sv-SE -> en-US |
| Tamil (India) -> English | ta-IN -> en-US |
| Turkish (Turkey) -> English | tr-TR -> en-US |
| Chinese (Simplified, China) -> English | cmn-Hans-CN -> en-US |
For translation from English:
| Source -> Target Language | Source -> Target Language Code |
|---|---|
| English -> Arabic (Egypt) | en-US -> ar-EG |
| English -> Arabic (Gulf) | en-US -> ar-x-gulf |
| English -> Arabic (Levant) | en-US -> ar-x-levant |
| English -> Arabic (Maghrebi) | en-US -> ar-x-maghrebi |
| English -> Catalan (Spain) | en-US -> ca-ES |
| English -> Welsh (United Kingdom) | en-US -> cy-GB |
| English -> German (Germany) | en-US -> de-DE |
| English -> Estonian (Estonia) | en-US -> et-EE |
| English -> Persian (Iran) | en-US -> fa-IR |
| English -> Indonesian (Indonesia) | en-US -> id-ID |
| English -> Japanese (Japan) | en-US -> ja-JP |
| English -> Latvian (Latvia) | en-US -> lv-LV |
| English -> Mongolian (Mongolia) | en-US -> mn-MN |
| English -> Slovenian (Slovenia) | en-US -> sl-SI |
| English -> Swedish (Sweden) | en-US -> sv-SE |
| English -> Tamil (India) | en-US -> ta-IN |
| English -> Turkish (Turkey) | en-US -> tr-TR |
| English -> Chinese (Simplified, China) | en-US -> cmn-Hans-CN |
Feature support and limitations
Chirp 2 supports the following features:
| Feature | Description |
|---|---|
| Automatic punctuation | Automatically generated by the model and can be optionally disabled. |
| Automatic capitalization | Automatically generated by the model and can be optionally disabled. |
| Speech adaptation (Biasing) | Provide hints to the model in the form of simple words or phrases to improve recognition accuracy for specific terms or proper nouns. Class tokens or custom classes are not supported. |
| Word-timings (Timestamps) | Automatically generated by the model and can be optionally enabled. It is possible that transcrption quality and speed will degrade slightly. |
| Profanity filter | Detect profane words and return only the first letter followed by asterisks in the transcript (for example, f***). |
| Language-agnostic audio transcription | The model automatically infers the spoken language in your audio file and transcribes in the most prevalent language. |
| Language-specific translation | The model automatically translates from the spoken language to the target language. |
| Forced normalization | If defined in the request body, the API will perform string replacements on specific terms or phrases, ensuring consistency in the transcription. |
| Word-level confidence scores | The API returns a value, but it isn't truly a confidence score. In the case of translation, confidence scores are not returned. |
| Denoiser and SNR-filtering | Denoise the audio before sending it to the model. Filter out audio segments if the SNR is lower than the specified threshold. |
Chirp 2 does not support the following features:
| Feature | Description |
|---|---|
| Diarization | Not supported |
| Language Detection | Not supported |
Transcribe using Chirp 2
Discover how to use Chirp 2 for your transcription and translation needs.
Perform streaming speech recognition
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_streaming_chirp2(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Perform synchronous speech recognition
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Perform batch speech recognition
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_batch_chirp2(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Using Chirp 2 Features
Explore how you can use the latest features, with code examples:
Perform a language-agnostic transcription
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 2.
Please see https://cloud.google.com/speech-to-text/v2/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Perform speech translation
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def translate_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Translates an audio file using Chirp 2.
Args:
audio_file (str): Path to the local audio file to be translated.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the translated results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["fr-FR"], # Set language code to targeted to detect language.
translation_config=cloud_speech.TranslationConfig(target_language="fr-FR"), # Set target language code.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Translated transcript: {result.alternatives[0].transcript}")
return response
Enable word-level timestamps
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API, providing word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
features=cloud_speech.RecognitionFeatures(
enable_word_time_offsets=True, # Enabling word-level timestamps
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Improve accuracy with model adaptation
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Denoiser and SNR-filtering details
denoiser_audio=true can effectively help you reduce background music or noises like rain and street traffic. Note that a denoiser cannot remove background human voices.
You can set snr_threshold=X to control the minimum loudness of speech required
for transcription. This helps to filter out non-speech audio or background
noise, preventing unwanted text in your results. A higher snr_threshold means
the user needs to speak louder for the model to transcribe the utterances.
SNR-filtering can be utilized in real-time streaming use cases to avoid sending unnecessary sounds to a model for transcription. A higher value for this setting means that your speech volume must be louder relative to the background noise to be sent to the transcription model.
The configuration of snr_threshold will interact
with whether denoise_audio is true or false. When denoise_audio=true,
background noise is removed, and speech becomes relatively clearer. The
overall SNR of the audio goes up.
If your use case involves only the user's voice without others speaking, set denoise_audio=true to increase the sensitivity of SNR-filtering, which can
filter out non-speech noise. If your use case involves people
speaking in the background and you want to avoid transcribing background speech,
consider setting denoise_audio=false and lowering the SNR threshold.
The following are recommended SNR threshold values. A reasonable snr_threshold
value can be set from 0 - 1000. A value of 0 means don't filter anything, and 1000
means filter everything. Fine-tune the value if recommended setting does not
work for you.
| Denoise audio | SNR threshold | Speech sensitivity |
|---|---|---|
| true | 10.0 | high |
| true | 20.0 | medium |
| true | 40.0 | low |
| true | 100.0 | very low |
| false | 0.5 | high |
| false | 1.0 | medium |
| false | 2.0 | low |
| false | 5.0 | very low |
Enable denoiser and SNR-filtering
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API, providing word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
denoiser_config={
denoise_audio: True,
# Medium snr threshold
snr_threshold: 20.0,
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Use Chirp 2 in the Google Cloud console
- Sign up for a Google Cloud account, and create a project.
- Go to Speech in the Google Cloud console.
- If the API isn't enabled, enable the API.
Make sure that you have an STT console Workspace. If you don't have a workspace, you must create a workspace.
Go to the transcriptions page, and click New Transcription.
Open the Workspace drop-down and click New Workspace to create a workspace for transcription.
From the Create a new workspace navigation sidebar, click Browse.
Click to create a new bucket.
Enter a name for your bucket and click Continue.
Click Create to create your Cloud Storage bucket.
After the bucket is created, click Select to select your bucket for use.
Click Create to finish creating your workspace for the Speech-to-Text API V2 console.
Perform a transcription on your actual audio.
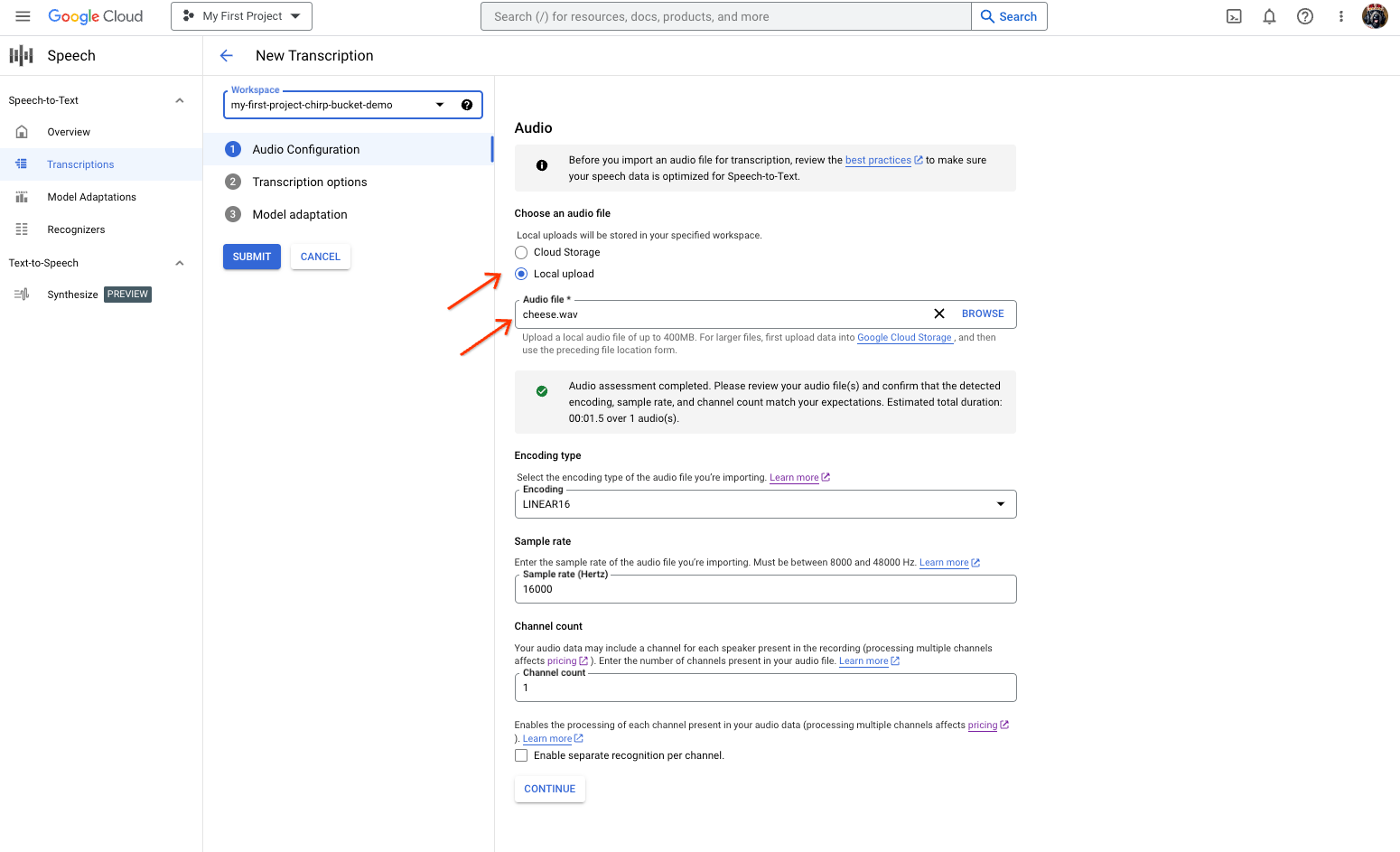
From the New Transcription page, select your audio file through either upload (Local upload) or specifying an existing Cloud Storage file (Cloud storage).
Click Continue to move to the Transcription options.
Select the Spoken language that you plan to use for recognition with Chirp from your previously created recognizer.
In the model drop-down, select chirp_2.
In the Recognizer drop-down, select your newly created recognizer.
Click Submit to run your first recognition request using
chirp_2.
View your Chirp 2 transcription result.
From the Transcriptions page, click the name of the transcription to view its result.
In the Transcription details page, view your transcription result, and optionally playback the audio in the browser.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used on this page, follow these steps.
-
Optional: Revoke the authentication credentials that you created, and delete the local credential file.
gcloud auth application-default revoke
-
Optional: Revoke credentials from the gcloud CLI.
gcloud auth revoke
Console
gcloud
What's next
- Learn how to transcribe streaming audio.
- Learn how to transcribe short audio files.
- Learn how to transcribe long audio files.
- For best performance, accuracy, and other tips, see the best practices documentation.