Chirp 2는 의견과 경험을 바탕으로 사용자의 요구사항을 충족하도록 설계된 Google의 최신 다국어 ASR 전용 모델입니다. 정확성과 속도에서 기존 Chirp 모델을 개선하고 단어 수준 타임스탬프, 모델 적응, 음성 번역과 같은 주요 새 기능으로 확장합니다.
|
|
 GitHub에서 노트북 보기 GitHub에서 노트북 보기
|
모델 세부정보
Chirp 2는 Speech-to-Text API V2 내에서만 사용할 수 있습니다.
모델 식별자
Google Cloud 콘솔에서 API를 사용하거나 모델 이름을 사용할 때 인식 요청에 적절한 모델 식별자를 지정하여 다른 모델과 마찬가지로 Chirp 2를 활용할 수 있습니다.
| 모델 | 모델 식별자 |
|---|---|
| Chirp 2 | chirp_2 |
API 메서드
Chirp 2는 Speech-to-Text API V2 내에서만 사용할 수 있으므로 다음과 같은 인식 방법을 지원합니다.
| 모델 | 모델 식별자 | 언어 지원 |
|---|---|---|
V2 |
Speech.StreamingRecognize (스트리밍 및 실시간 오디오에 적합) |
제한됨* |
V2 |
Speech.Recognize (1분 미만의 짧은 오디오에 적합) |
Chirp와 동일 |
V2 |
Speech.BatchRecognize (1분~8시간의 긴 오디오에 적합) |
Chirp와 동일 |
*locations API를 사용하여 언제든지 각 스크립트 모델에 지원되는 최신 언어 및 기능 목록을 확인할 수 있습니다.
사용 가능한 리전
Chirp 2는 다음 리전에서 지원됩니다.
| Google Cloud 영역 | 출시 준비 |
|---|---|
us-central1 |
GA |
europe-west4 |
GA |
asia-southeast1 |
비공개 미리보기 |
여기에 설명된 대로 locations API를 사용하여 언제든지 각 스크립트 모델의 최신 지원되는 Google Cloud 리전, 언어, 기능 목록을 확인할 수 있습니다.
스크립트 작성 지원 언어
Chirp 2는 StreamingRecognize, Recognize, BatchRecognize 인식 메서드에서 스크립트 작성을 지원합니다. 하지만 언어 지원은 사용되는 방법에 따라 다릅니다. 특히 BatchRecognize는 가장 광범위한 언어 지원을 제공합니다. StreamingRecognize는 다음 언어를 지원합니다.
| 언어 | BCP-47 코드 |
|---|---|
| 중국어 간체(중국) | cmn-Hans-CN |
| 중국어(번체, 타이완) | cmn-hant-tw |
| 중국어, 광둥어(번체 홍콩) | yue-Hant-HK |
| 영어(호주) | en-AU |
| 영어(인도) | en-IN |
| 영어(영국) | en-GB |
| 영어(미국) | en-US |
| 프랑스어(캐나다) | fr-CA |
| 프랑스어(프랑스) | fr-FR |
| 독일어(독일) | de-DE |
| 이탈리아어(이탈리아) | it-IT |
| 일본어(일본) | ja-JP |
| 포르투갈어(브라질) | pt-BR |
| 스페인어(스페인) | es-ES |
| 스페인어(미국) | es-US |
번역 지원 언어
다음은 음성 번역에 지원되는 언어입니다. Chirp 2의 번역 언어 지원은 대칭적이지 않습니다. 즉, 언어 A에서 언어 B로 번역할 수는 있지만 언어 B에서 언어 A로 번역할 수는 없습니다. Speech-Translation에서는 다음 언어 쌍이 지원됩니다.
영어로 번역:
| 소스 -> 대상 언어 | 소스 -> 대상 언어 코드 |
|---|---|
| 아랍어 (이집트) -> 영어 | ar-EG -> en-US |
| 아랍어 (걸프) -> 영어 | ar-x-gulf -> en-US |
| 아랍어 (레반트) -> 영어 | ar-x-levant -> en-US |
| 아랍어 (마그레브) -> 영어 | ar-x-maghrebi -> en-US |
| 카탈로니아어 (스페인) -> 영어 | ca-ES -> en-US |
| 웨일스어 (영국) -> 영어 | cy-GB -> en-US |
| 독일어 (독일) -> 영어 | de-DE -> en-US |
| 스페인어 (라틴 아메리카) -> 영어 | es-419 -> en-US |
| 스페인어 (스페인) -> 영어 | es-ES -> en-US |
| 스페인어 (미국) -> 영어 | es-US -> en-US |
| 에스토니아어 (에스토니아) -> 영어 | et-EE -> en-US |
| 프랑스어 (캐나다) -> 영어 | fr-CA -> en-US |
| 프랑스어 (프랑스) -> 영어 | fr-FR -> en-US |
| 페르시아어 (이란) -> 영어 | fa-IR -> en-US |
| 인도네시아어 (인도네시아) -> 영어 | id-ID -> en-US |
| 이탈리아어 (이탈리아) -> 영어 | it-IT -> en-US |
| 일본어 (일본) -> 영어 | ja-JP -> en-US |
| 라트비아어 (라트비아) -> 영어 | lv-LV -> en-US |
| 몽골어 (몽골) -> 영어 | mn-MN -> en-US |
| 네덜란드어 (네덜란드) -> 영어 | nl-NL -> en-US |
| 포르투갈어 (브라질) -> 영어 | pt-BR -> en-US |
| 러시아어 (러시아) -> 영어 | ru-RU -> en-US |
| 슬로베니아어 (슬로베니아) -> 영어 | sl-SI -> en-US |
| 스웨덴어 (스웨덴) -> 영어 | sv-SE -> en-US |
| 타밀어 (인도) -> 영어 | ta-IN -> en-US |
| 터키어 (튀르키예) -> 영어 | tr-TR -> en-US |
| 중국어 (간체, 중국) -> 영어 | zh-Hans-CN -> en-US |
영어에서 번역하는 경우:
| 소스 -> 대상 언어 | 소스 -> 대상 언어 코드 |
|---|---|
| 영어 -> 아랍어 (이집트) | en-US -> ar-EG |
| 영어 -> 아랍어 (걸프) | en-US -> ar-x-gulf |
| 영어 -> 아랍어 (레반트) | en-US -> ar-x-levant |
| 영어 -> 아랍어 (마그레브) | en-US -> ar-x-maghrebi |
| 영어 -> 카탈루냐어 (스페인) | en-US -> ca-ES |
| 영어 -> 웨일스어 (영국) | en-US -> cy-GB |
| 영어 -> 독일어 (독일) | en-US -> de-DE |
| 영어 -> 에스토니아어 (에스토니아) | en-US -> et-EE |
| 영어 -> 페르시아어 (이란) | en-US -> fa-IR |
| 영어 -> 인도네시아어 (인도네시아) | en-US -> id-ID |
| 영어 -> 일본어 (일본) | en-US -> ja-JP |
| 영어 -> 라트비아어 (라트비아) | en-US -> lv-LV |
| 영어 -> 몽골어 (몽골) | en-US -> mn-MN |
| 영어 -> 슬로베니아어 (슬로베니아) | en-US -> sl-SI |
| 영어 -> 스웨덴어 (스웨덴) | en-US -> sv-SE |
| 영어 -> 타밀어 (인도) | en-US -> ta-IN |
| 영어 -> 터키어 (터키) | en-US -> tr-TR |
| 영어 -> 중국어 (간체, 중국) | en-US -> zh-Hans-CN |
기능 지원 및 제한사항
Chirp 2는 다음 기능을 지원합니다.
| 특성 | 설명 |
|---|---|
| 자동 구두점 | 모델에 의해 자동으로 생성되며 원하는 경우 사용 중지할 수 있습니다. |
| 자동 대문자 사용 | 모델에 의해 자동으로 생성되며 원하는 경우 사용 중지할 수 있습니다. |
| 음성 적응 (편향) | 간단한 단어 또는 문구 형식으로 모델에 힌트를 제공하여 특정 용어 또는 지명에 대한 인식 정확도를 개선합니다. 클래스 토큰 또는 맞춤 클래스는 지원되지 않습니다. |
| 단어 시간 (타임스탬프) | 모델에 의해 자동으로 생성되며 원하는 경우 사용 설정할 수 있습니다. 스크립트 품질과 속도가 약간 저하될 수 있습니다. |
| 언어 제약이 없는 오디오 스크립트 작성 | 모델은 오디오 파일에서 음성 언어를 자동으로 추론하고 가장 흔한 언어로 스크립트로 변환합니다. |
| 언어별 번역 | 모델은 구어체 언어를 타겟 언어로 자동 번역합니다. |
| 강제 정규화 | 요청 본문에 정의된 경우 API는 특정 용어 또는 구문에 문자열을 대체하여 스크립트의 일관성을 보장합니다. |
| 단어 수준의 신뢰도 점수 | API가 값을 반환하지만 실제 신뢰도 점수는 아닙니다. 번역의 경우에는 신뢰도 점수가 반환되지 않습니다. |
Chirp 2는 다음 기능을 지원하지 않습니다.
| 특성 | 설명 |
|---|---|
| 대화목록 생성 | 지원되지 않음 |
| 언어 감지 | 지원되지 않음 |
| 욕설 필터 | 지원되지 않음 |
Chirp 2를 사용하여 스크립트 작성
스크립트 작성 및 번역 작업에 Chirp 2를 사용하는 방법을 알아보세요.
스트리밍 음성 인식 수행
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_streaming_chirp2(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
동기 음성 인식 수행
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
일괄 음성 인식 수행
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_batch_chirp2(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Chirp 2 기능 사용
코드 예시를 통해 최신 기능을 사용하는 방법을 살펴보세요.
언어 제약이 없는 스크립트 작성 수행
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 2.
Please see https://cloud.google.com/speech-to-text/v2/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
음성 번역 수행
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def translate_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Translates an audio file using Chirp 2.
Args:
audio_file (str): Path to the local audio file to be translated.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the translated results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["fr-FR"], # Set language code to targeted to detect language.
translation_config=cloud_speech.TranslationConfig(target_language="fr-FR"), # Set target language code.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Translated transcript: {result.alternatives[0].transcript}")
return response
단어 수준 타임스탬프 사용 설정
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API, providing word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
features=cloud_speech.RecognitionFeatures(
enable_word_time_offsets=True, # Enabling word-level timestamps
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
모델 적응으로 정확성 개선
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Google Cloud 콘솔에서 Chirp 2 사용하기
- Google Cloud 계정에 가입하고 프로젝트를 만들었는지 확인합니다.
- Google Cloud 콘솔에서 음성으로 이동합니다.
- API가 아직 사용 설정되지 않았으면 사용 설정합니다.
STT 콘솔 작업공간이 있는지 확인합니다. 아직 워크스페이스가 없다면 만들어야 합니다.
스크립트 작성 페이지로 이동하여 새 스크립트 작성을 클릭합니다.
작업공간 드롭다운을 열고 새 작업공간을 클릭하여 스크립트 작성용 작업공간을 만듭니다.
새 작업공간 만들기 탐색 사이드바에서 찾아보기를 클릭합니다.
클릭하여 새 버킷을 만듭니다.
버킷 이름을 입력하고 계속을 클릭합니다.
만들기를 클릭하여 Cloud Storage 버킷을 만듭니다.
버킷을 만든 후 선택을 클릭하여 사용할 버킷을 선택합니다.
만들기를 클릭하여 Speech-to-Text API V2 콘솔의 작업공간 만들기를 완료합니다.
실제 오디오에서 텍스트 변환을 수행합니다.
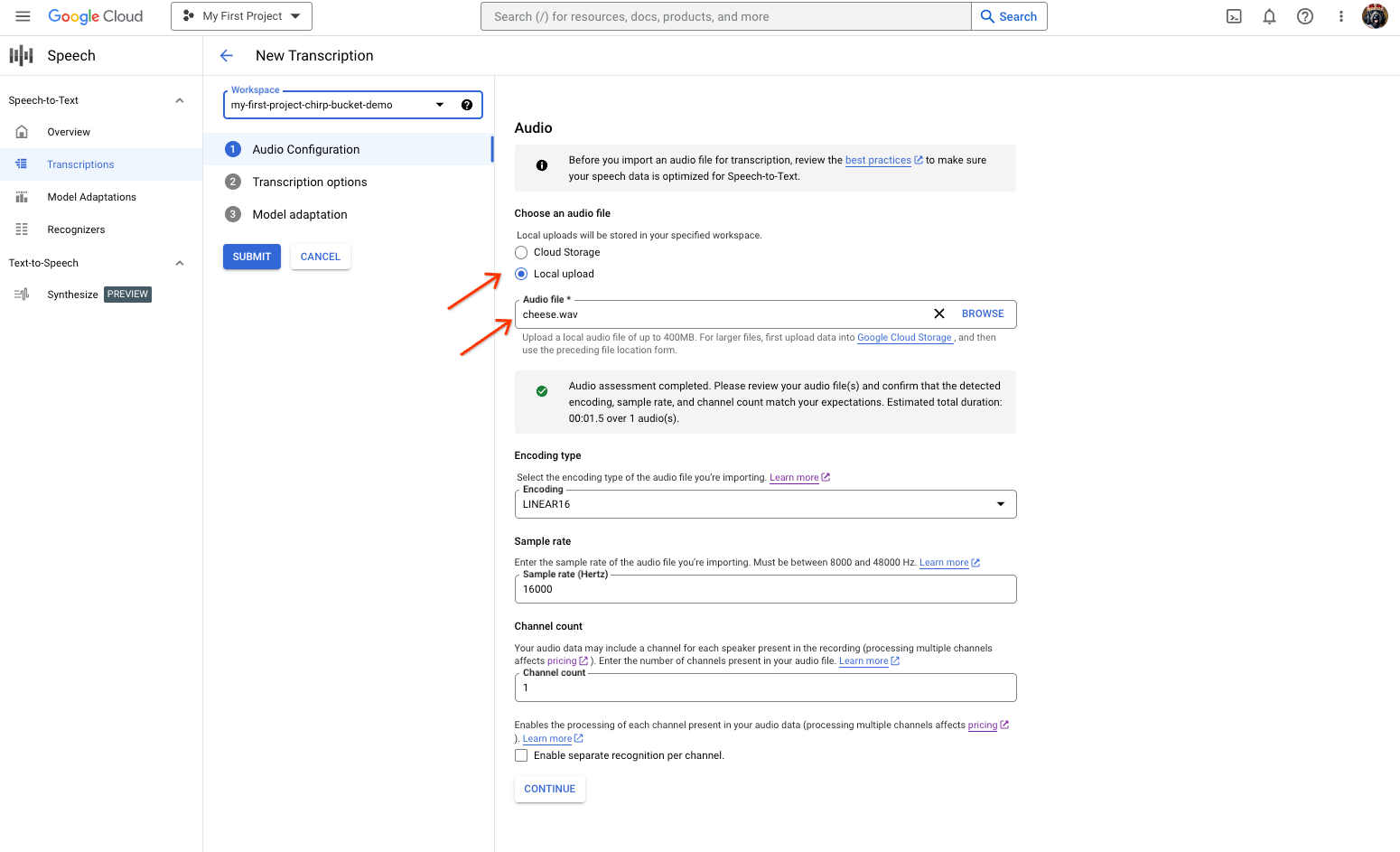
새 텍스트 변환 페이지에서 업로드(로컬 업로드) 또는 기존 Cloud Storage 파일(Cloud Storage)을 지정하여 오디오 파일을 선택합니다.
계속을 클릭하여 스크립트 작성 옵션으로 이동합니다.
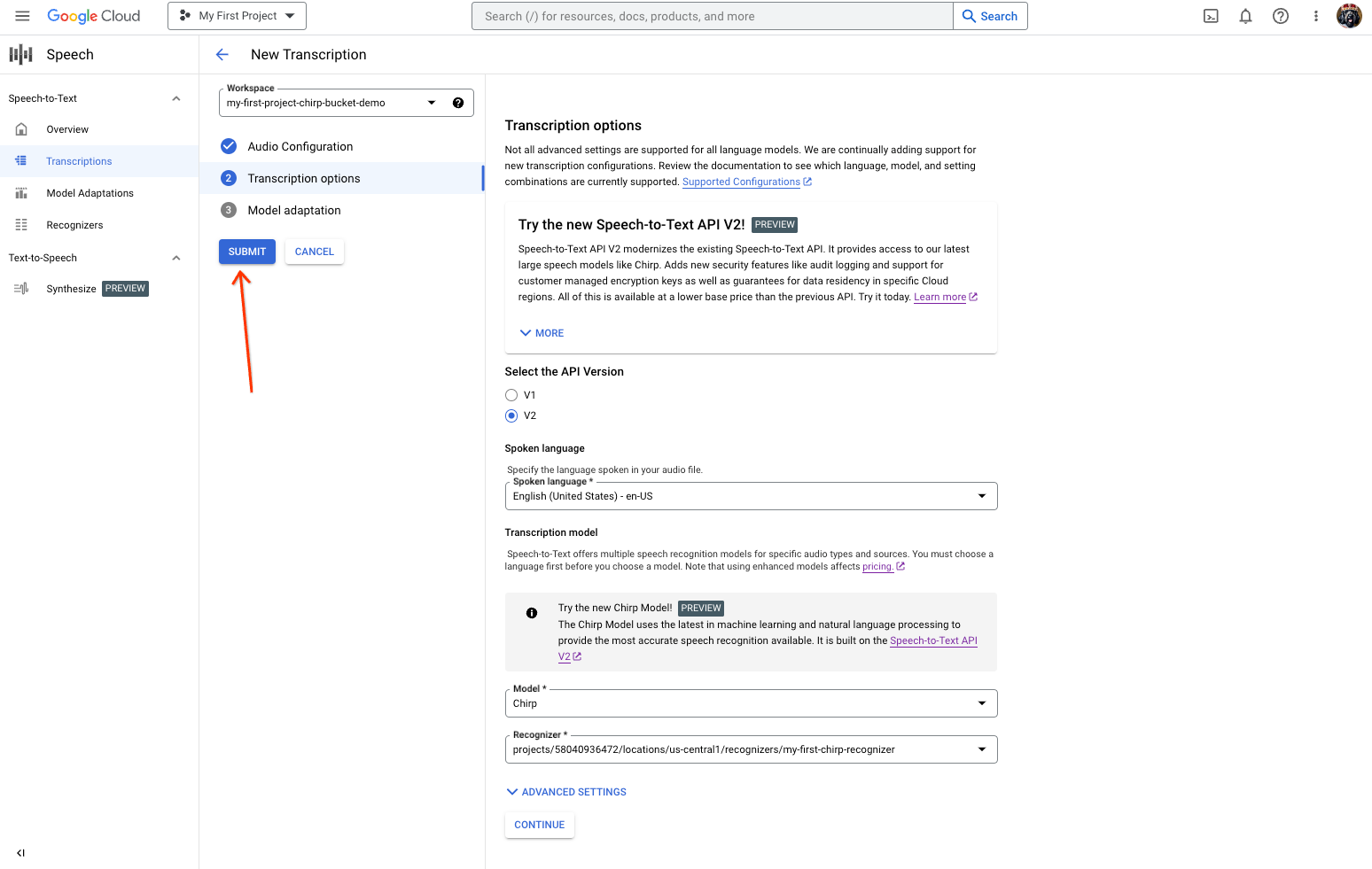
이전에 만든 인식기에서 Chirp의 인식에 사용할 음성 언어를 선택합니다.
모델 드롭다운에서 Chirp - 범용 음성 모델을 선택합니다.
인식기 드롭다운에서 새로 만든 인식기를 선택합니다.
제출을 클릭하여 Chirp을 사용하여 첫 번째 인식 요청을 실행합니다.
Chirp 2 텍스트 변환 결과를 확인합니다.
스크립트 작성 페이지에서 스크립트 작성 이름을 클릭하여 결과를 확인합니다.
텍스트 변환 세부정보 페이지에서 텍스트 변환 결과를 확인하고 원하는 경우 브라우저에서 오디오를 재생합니다.
삭제
이 페이지에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 수행합니다.
-
Optional: Revoke the authentication credentials that you created, and delete the local credential file.
gcloud auth application-default revoke
-
Optional: Revoke credentials from the gcloud CLI.
gcloud auth revoke
콘솔
gcloud
Delete a Google Cloud project:
gcloud projects delete PROJECT_ID
다음 단계
- 짧은 오디오 파일의 스크립트 작성 연습
- 스트리밍 오디오의 텍스트 변환 방법 알아보기
- 긴 오디오 파일의 텍스트 변환 방법 알아보기
- 권장사항 문서에서 최상의 성능, 정확도, 기타 팁 참조