正常に生成されたすべてのデータ プロファイルを BigQuery に送信するように機密データの検出サービスを構成した場合は、それらのデータ プロファイルにクエリを実行してデータに関する分析情報を取得できます。Looker Studio などの可視化ツールを使用して、ビジネスニーズに合わせたカスタム レポートを作成することもできます。または、機密データの保護が提供する事前作成済みのレポートを使用して、調整し、必要に応じて共有することもできます。
このページでは、データ プロファイルについて詳しく確認するために使用できる SQL クエリの例を示します。また、Looker Studio でデータ プロファイルを可視化する方法も説明します。
データ プロファイルの詳細については、データ プロファイルをご覧ください。
始める前に
このページでは、組織、フォルダ、プロジェクトのレベルでプロファイリングが構成されていることを前提としています。検出スキャン構成で、[データ プロファイルのコピーを BigQuery に保存する] アクションが有効になっていることを確認します。検出スキャン構成の作成方法については、スキャン構成を作成するをご覧ください。
このドキュメントでは、エクスポートされたデータ プロファイルを含むテーブルを出力テーブルと呼びます。
出力テーブルのプロジェクト ID、データセット ID、テーブル ID を直ちに使用できることを確認してください。これらは、このページの手順を実施する際に必要です。
latest ビュー
機密データの保護は、出力テーブルにデータ プロファイルをエクスポートする際に、latest ビューも作成します。このビューは、データ プロファイルの最新のスナップショットのみを含む事前フィルタリングされた仮想テーブルです。latest ビューのスキーマは出力テーブルと同じであるため、SQL クエリと Looker Studio レポートでこの 2 つを互換性を持つ対象として使用できます。出力テーブルにデータ プロファイルの古いスナップショットが含まれているために、結果が異なる場合があります。
latest ビューは、出力テーブルと同じ場所に保存されます。名前は次のような形式になっています。
OUTPUT_TABLE_latest_VERSION
以下を置き換えます。
- OUTPUT_TABLE: エクスポートされたデータ プロファイルを含むテーブルの ID。
- VERSION: ビューのバージョン番号。
たとえば、出力テーブルの名前が table-profile の場合、latest ビューの名前は table-profile_latest_v1 のようになります。

SQL クエリで latest ビューを使用する場合は、プロジェクト ID、データセット ID、テーブル ID、サフィックスを含むビューの完全な名前を使用します(例: myproject.mydataset.table-profile_latest_v1)。
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
出力テーブルとlatestビューのいずれかを選択する
latest ビューには最新のデータ プロファイル スナップショットのみが含まれますが、出力テーブルには、古いスナップショットを含むすべてのデータ プロファイル スナップショットが含まれます。たとえば、出力テーブルに対するクエリは、同じ列に対して複数の列データ プロファイルを返すことができます(その列がプロファイリングされるたびに 1 つずつ)。
SQL クエリまたはデータポータル レポートで出力テーブルまたは latest ビューの使用を選択する際は、次の点を考慮してください。
latestビューは、再プロファイリングされたデータアセットが存在し、直近のプロファイルのみが表示され、その他の古いバージョンのプロファイルが表示されないようにする必要がある場合に活用できます。つまり、プロファイリングされたデータの現在の状態を確認する必要があります。出力テーブルは、プロファイリングされたデータの履歴ビューを取得する場合に活用できます。たとえば、組織で特定の infoType が格納されているかどうか、または特定のデータ プロファイルで行われた変更を確認することが必要な場合があります。
サンプル SQL クエリ
このセクションでは、データ プロファイルを分析する際に使用できるクエリの例を示します。これらのクエリを実行するには、インタラクティブ クエリの実行をご覧ください。
次の例では、TABLE_OR_VIEW を次のいずれかに置き換えます。
- 出力テーブルの名前。エクスポートされたデータ プロファイルを含むテーブルです(例:
myproject.mydataset.table-profile)。 - 出力テーブルの
latestビューの名前(例:myproject.mydataset.table-profile_latest_v1)。
いずれの場合も、プロジェクト ID とデータセット ID を配置する必要があります。
詳細については、このページの出力テーブルと latest ビューのいずれかを選択するをご覧ください。
発生したエラーのトラブルシューティングについては、エラー メッセージをご覧ください。
フリーテキスト スコアが高く、他の infoType 一致の証拠があるすべての列を一覧表示する
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
これらの検出結果の修正方法については、データリスクを軽減するために推奨される戦略をご覧ください。
自由テキストスコアとその他の infoType 指標の詳細については、列データ プロファイルをご覧ください。
クレジット カード番号の列を含むすべてのテーブルを一覧表示する
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER は、クレジット カード番号を表す組み込み infoType です。
これらの検出結果の修正方法については、データリスクを軽減するために推奨される戦略をご覧ください。
クレジット カード番号、社会保障番号、人名の列を含むテーブル プロファイルを一覧表示する
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
このクエリは、次の組み込み infoType を使用します。
CREDIT_CARD_NUMBER: クレジット カード番号を表しますPERSON_NAME: 人のフルネームを表しますUS_SOCIAL_SECURITY_NUMBERは米国社会保障番号を表します
これらの検出結果の修正方法については、データリスクを軽減するために推奨される戦略をご覧ください。
機密性スコアが SENSITIVITY_HIGH のバケットを一覧表示する
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
詳細については、ファイル ストアのデータ プロファイルをご覧ください。
機密性スコアが SENSITIVITY_HIGH の場合にスキャンされたすべてのバケットパス、クラスタ、ファイル拡張子を一覧表示する
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
詳細については、ファイル ストアのデータ プロファイルをご覧ください。
クレジット カード番号が検出されたスキャン対象のすべてのバケットパス、クラスタ、ファイル拡張子を一覧表示する
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER は、クレジット カード番号を表す組み込み infoType です。
詳細については、ファイル ストアのデータ プロファイルをご覧ください。
クレジット カード番号、人名、社会保障番号が検出されたスキャン対象のすべてのバケットパス、クラスタ、ファイル拡張子を一覧表示する
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
このクエリでは、次の組み込み infoType を使用します。
CREDIT_CARD_NUMBER: クレジット カード番号を表しますPERSON_NAME: 人のフルネームを表しますUS_SOCIAL_SECURITY_NUMBERは米国社会保障番号を表します
詳細については、ファイル ストアのデータ プロファイルをご覧ください。
Looker Studio でデータ プロファイルを操作する
Looker Studio でデータ プロファイルを可視化するには、既製のレポートを使用します。または、独自のレポートを作成することもできます。
事前に作成されているレポートを使用する
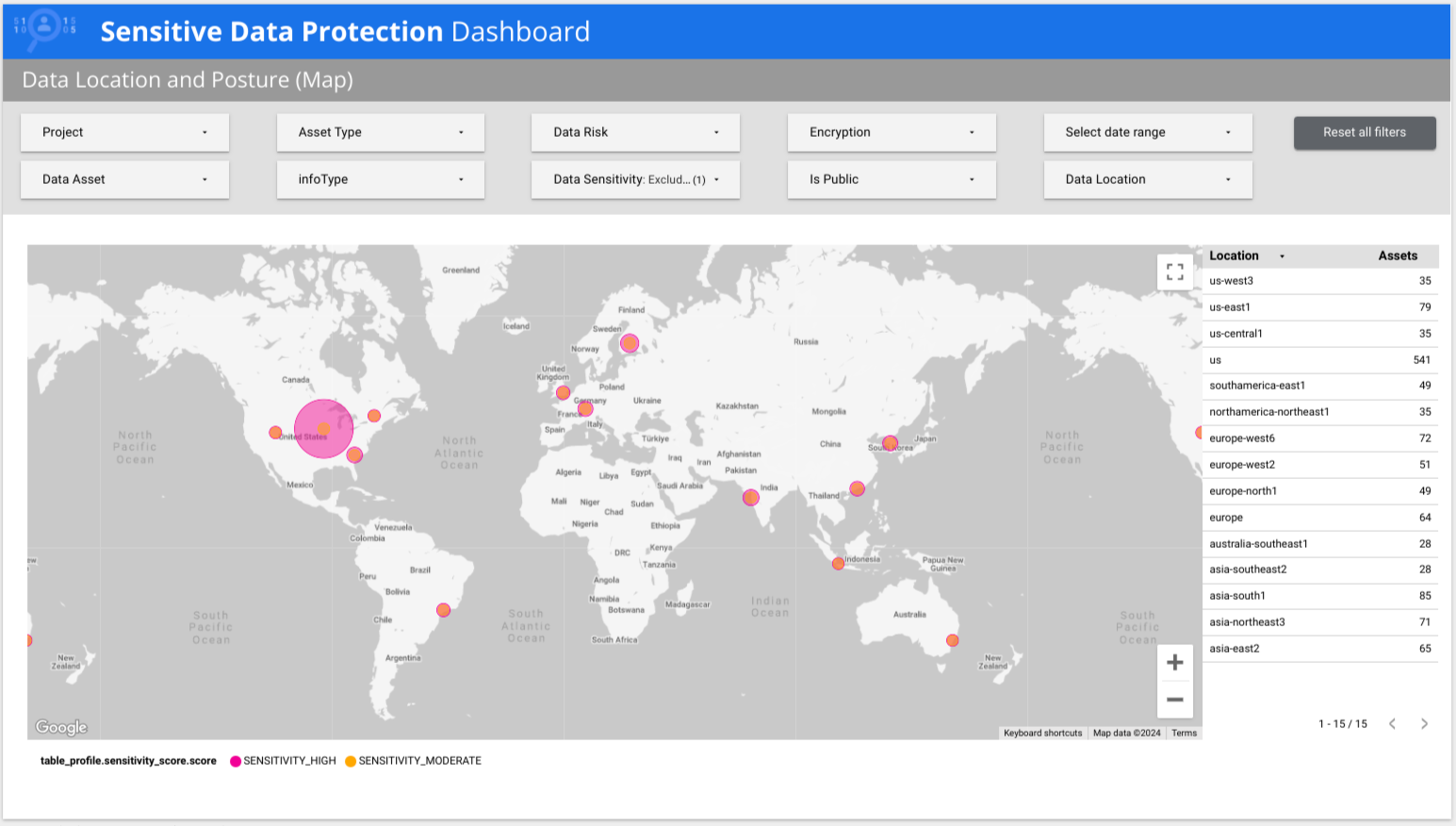
機密データの保護は、データ プロファイルの豊富な分析情報を際立たせる事前作成された Looker Studio レポートを提供します。Sensitive Data Protection ダッシュボードは、データ プロファイルの概要を素早く確認できるマルチページ レポートです。リスク、infoType、場所によって異なります。他のタブで、地域別やポスチャー リスク別のビューを確認したり、特定の指標にドリルダウンしたりできます。この既製のレポートをそのまま使用できます。または必要に応じてカスタマイズすることもできます。これは既製レポートの推奨バージョンです。
データを使用して既製のレポートを表示するには、次の URL に必要な値を入力します。次に、生成された URL をブラウザにコピーします。
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
以下を置き換えます。
- PROJECT_ID: 出力テーブルを含むプロジェクト。
- DATASET_ID: 出力テーブルを含むデータセット。
TABLE_OR_VIEW:次のいずれかになります。
- 出力テーブルの名前。エクスポートされたデータ プロファイルを含むテーブルです(例:
myproject.mydataset.table-profile)。 - 出力テーブルの
latestビューの名前(例:myproject.mydataset.table-profile_latest_v1)。
詳細については、このページの出力テーブルと
latestビューのいずれかを選択するをご覧ください。- 出力テーブルの名前。エクスポートされたデータ プロファイルを含むテーブルです(例:
Looker Studio でレポートにデータが読み込まれるまでに、数分かかることがあります。エラーが発生した場合や、レポートが読み込まれない場合は、このページの事前作成レポートに関するエラーのトラブルシューティングをご覧ください。
次の例では、低機密データと高機密データが世界中の複数の国に存在することがダッシュボードに表示されています。
以前のバージョンの既製レポート
既製レポートの最初のバージョンは、引き続き次のアドレスで入手できます。
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
レポートを作成する
Looker Studio では、インタラクティブなレポートを作成できます。このセクションでは、BigQuery の出力テーブルにエクスポートされたデータ プロファイルに基づいて、Looker Studio で簡単なテーブル レポートを作成します。
出力テーブルのプロジェクト ID、データセット ID、テーブル ID、または latest ビューをすぐに使用できることを確認してください。この手順を実行するために必要です。
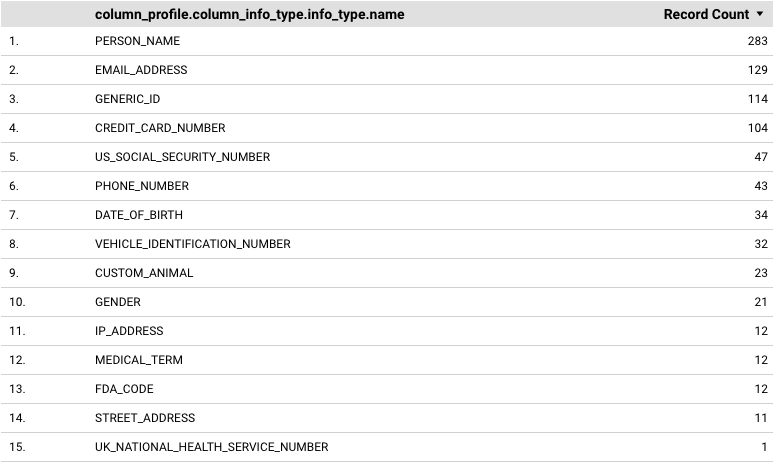
この例では、データ プロファイルでレポートされた各 infoType とその頻度を示すテーブルを含むレポートを作成する方法を示します。
通常、Looker Studio 経由で BigQuery にアクセスすると、BigQuery の使用料金が発生します。詳細については、Looker Studio を使用して BigQuery データを可視化するをご覧ください。
レポートを作成する手順は次のとおりです。
- Looker Studio を開いてログインします。
- [空のレポート] をクリックします。
- [Connect to data] タブで、[BigQuery] カードをクリックします。
- プロンプトが表示されたら、Looker Studio が BigQuery プロジェクトにアクセスすることを承認します。
BigQuery データに接続する:
- [プロジェクト] で、出力テーブルを含むプロジェクトを選択します。プロジェクトは、[最近のプロジェクト]、[マイ プロジェクト]、[共有プロジェクト] の各タブで検索できます。
- [データセット] で、出力テーブルを含むデータセットを選択します。
[テーブル] で、出力テーブルまたは出力テーブルの
latestビューを選択します。詳細については、このページの出力テーブルと
latestビューのいずれかを選択するをご覧ください。[Add] をクリックします。
表示されるダイアログで、[レポートに追加] をクリックします。
レポートされる各 infoType と対応する頻度(レコード数)を表示するテーブルを追加するには、次の手順に従います。
- [グラフを追加] をクリックします。
- テーブルのスタイルを選択します。
グラフを配置する領域をクリックします。
グラフが表形式で表示されます。
必要に応じて表のサイズを変更します。
テーブルが選択されていれば、そのプロパティが [グラフ] ペインに表示されます。
[グラフ] ペインの [設定] タブで、事前に選択されているディメンションと指標を削除します。
[ディメンション] に、
column_profile.column_info_type.info_type.nameまたはfile_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.nameを追加します。これらの例では、列レベルとファイル クラスタレベルでデータを提供します。他のディメンションも試すことができます。たとえば、テーブルレベルとバケットレベルのディメンションを使用できます。
[指標] で [レコード数] を追加します。
結果のテーブルは次のようになります。
Looker Studio のテーブルについて詳しく確認します。
事前作成レポートに関するエラーのトラブルシューティング
作成済みのレポートを読み込むときにエラーが表示されたり、コントロールやグラフが欠落している場合は、作成済みのレポートで最新のフィールドが使用されていることを確認してください。
事前作成されたレポートが出力テーブルに接続されている場合は、このテーブルがアクティブな検出スキャン構成に接続されていることを確認します。スキャン構成の設定を表示するには、スキャン構成を表示するをご覧ください。
作成済みのレポートが
latestビューに接続されている場合は、このビューが BigQuery にまだ存在することを確認します。存在する場合は、ビューを変更してみてください。または、ビューのコピーを作成し、そのコピーに事前作成されたレポートを接続します。latestビューの詳細については、このページのlatestビューをご覧ください。
上記の手順を試してもエラーが解消されない場合は、Cloud カスタマーケアにお問い合わせください。
次のステップ
データ プロファイルの検出結果を修正するために実行できるアクションについて学習する。