このページでは、組織のデータリスクを特定して是正するために推奨される戦略について説明します。
データの保護は、取り扱うデータの種類、機密データの所在地、データの保護方法と使用方法を理解するところから始めます。データとそのセキュリティ対策を包括的に把握すると、適切な対策を講じてデータを保護し、コンプライアンスとリスクを継続的にモニタリングすることが可能になります。
このページは、検出サービスと検査サービスおよびその違いを理解していることを前提としています。
機密データの検出を有効にする
ビジネスにおいて機密データが存在する場所を特定するには、組織、フォルダ、プロジェクトのいずれかのレベルで検出を構成します。このサービスでは、機密レベルやデータリスク レベルなどのデータに関する指標と分析情報を含むデータ プロファイルが生成されます。
サービスとして、検出はデータアセットに関する信頼できる情報源として機能して、監査レポートの指標を自動的に報告することが可能となります。また、検出は Security Command Center、Google Security Operations、Dataplex Universal Catalog などの他の Google Cloud サービスに接続して、セキュリティ運用とデータ マネジメントを強化できます。
検出サービスは継続的に実行され、組織の運営と成長に合わせて新しいデータを検出します。たとえば、組織内の誰かが新しいプロジェクトを作って大量の新しいデータをアップロードすると、検出サービスによって新しいデータが自動的に検出され、分類と報告が行われます。
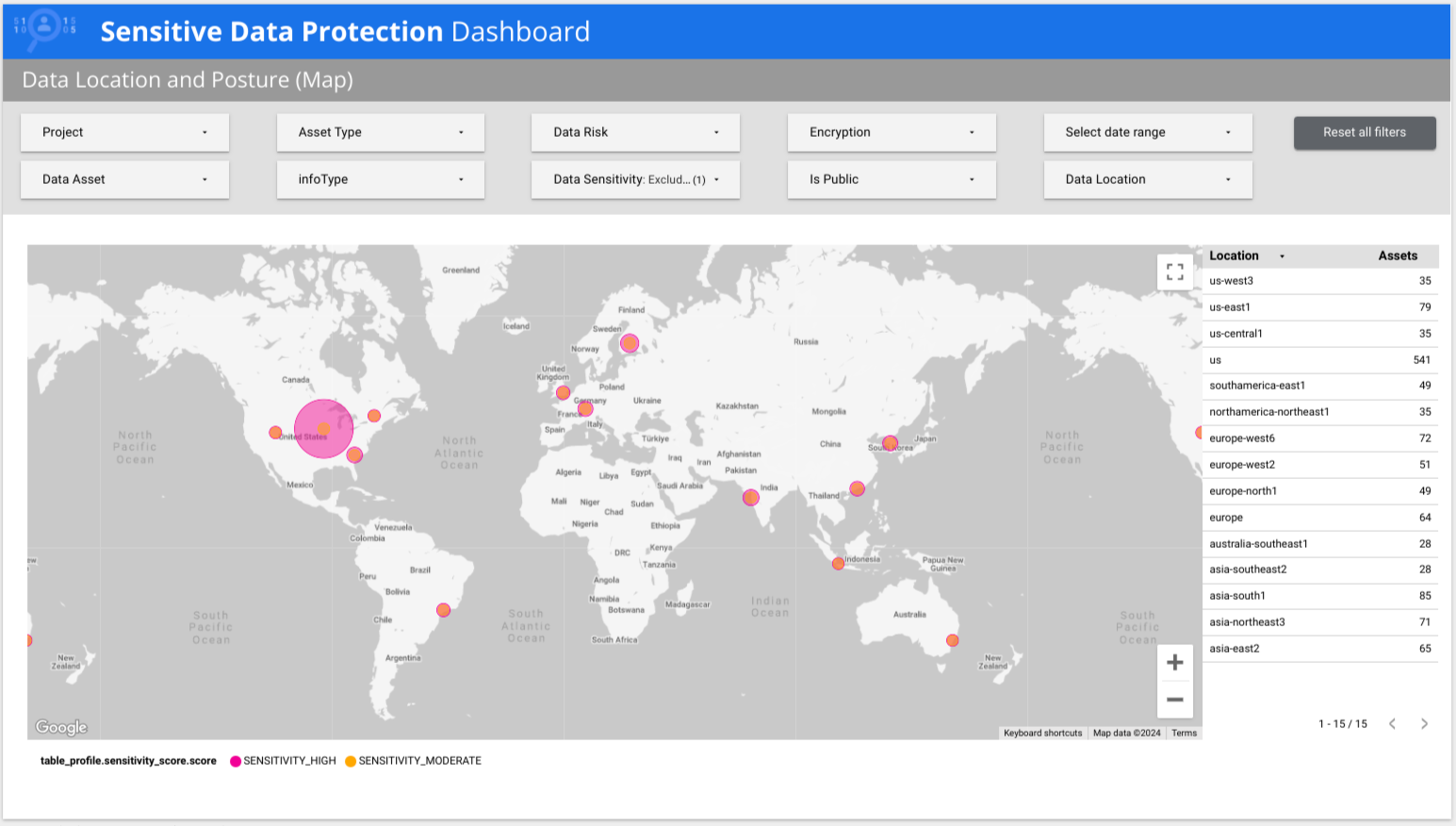
機密データの保護には、リスク別、infoType 別、場所別の各内訳といったデータの全体像を示す複数ページの Looker レポートがあらかじめ用意されています。次の例では、低機密データと高機密データが世界中の複数の国に存在することがダッシュボードに表示されています。
検出結果に基づいて対応する
データ セキュリティ対策の全体像を把握すると見つかった問題を是正できます。一般に、検出結果は次のいずれかのシナリオに分類されます。
- シナリオ 1: 機密データが、想定されて適切に保護されているワークロードで発見された。
- シナリオ 2: 機密データが、想定外のワークロードや適切に管理が行われていないワークロードで発見された。
- シナリオ 3: 機密データが発見されたが、さらに調査が必要である。
シナリオ 1: 機密データが発見され、適切に保護されている
このシナリオでは具体的なアクションは必要ありませんが、データ プロファイルを監査レポートとセキュリティ分析ワークフローに追加して、データを危険にさらす可能性がある変更を引き続きモニタリングする必要があります。
次の手順を行うことをおすすめします。
セキュリティ対策のモニタリングとサイバー脅威の調査を行うためのツールにデータ プロファイルを公開します。データ プロファイルは、機密データを危険にさらす可能性があるセキュリティの脅威や脆弱性の重大度を判断するのに役立ちます。データ プロファイルは、以下のサイトに自動的にエクスポートできます。
データ プロファイルを Dataplex Universal Catalog またはインベントリ システムに公開して、データ プロファイルの指標を他の適切なビジネス メタデータとともに追跡します。データ プロファイルを Dataplex Universal Catalog に自動的にエクスポートする方法については、データ プロファイルの分析情報に基づいて Dataplex Universal Catalog のアスペクトを追加するをご覧ください。
シナリオ 2: 機密データが発見されたが、適切に保護されていない
検出により、アクセス制御で適切に保護されていないリソースの機密データが発見された場合は、このセクションで説明する推奨事項を検討してください。
データに対する適切な管理とデータ セキュリティ対策を確立したら、データを危険にさらす可能性がある変更をモニタリングします。シナリオ 1 の推奨事項をご覧ください。
一般的な推奨事項
次のことを検討してください。
データの匿名化されたコピーを作成して機密性の高い列をマスクまたはトークン化し、データ アナリストやエンジニアが未加工の機密情報(個人を特定できる情報(PII)など)を公開することなくデータを扱えるようにする。
Cloud Storage データの場合は、機密データの保護の組み込み機能を使用して匿名化されたコピーを作成できます。
データが不要な場合は、データの削除を検討してください。
BigQuery データを保護するための推奨事項
- IAM を使用してテーブルレベルの権限を調整します。
BigQuery のポリシータグを使用してきめ細かい列レベルのアクセス制御を設定し、機密性の高い列やリスクの高い列へのアクセスを制限する。この機能を使用すると、テーブルの残りの部分へのアクセスを許可しながら、これらの列を保護できます。
また、ポリシータグで自動データ マスキングを有効にして、ユーザーに部分的に難読化されたデータを提供することもできます。
BigQuery の行レベルのセキュリティ機能を使用し、ユーザーやグループが許可リストにあるかどうかによって特定のデータ行を表示または非表示にする。
Cloud Storage データの保護に関する推奨事項
シナリオ 3: 機密データが発見されたが、さらに調査が必要である
場合によっては、さらに調査が必要という結果になることもあります。たとえば、データ プロファイルで、機密データの証拠となるフリーテキストのスコアが高い列が指定されている場合があります。フリーテキストのスコアが高いということは、データが予測可能な構造を持っておらず、機密データのインスタンスが断続的に含まれている可能性があることを示しています。これは、特定の行に PII(名前、連絡先情報、行政機関発行の識別子など)が含まれているメモの列かもしれません。この場合、テーブルに追加のアクセス制御を設定して、シナリオ 2 で説明されているその他の是正措置を行うことをおすすめします。また、対象を絞ったより詳細な検査を行ってリスクの範囲を特定することをおすすめします。
検査サービスを使用すると、単一のリソース(個別の BigQuery テーブルや Cloud Storage バケットなど)の徹底的なスキャンを実行できます。検査サービスで直接サポートされていないデータソースについては、Cloud Storage のバケットまたは BigQuery テーブルにデータをエクスポートして、そのリソースに対して検査ジョブを実行できます。たとえば、Cloud SQL データベースで検査する必要があるデータがある場合は、そのデータを Cloud Storage の CSV または AVRO ファイルにエクスポートして検査ジョブを実行できます。
検査ジョブは、テーブルセル内の文中のクレジット カード番号など、機密データの個々のインスタンスを特定します。このレベルの詳細情報は、非構造化列やデータ オブジェクト(テキスト ファイル、PDF、画像、その他のリッチ ドキュメント形式など)にどのような種類のデータが存在するかを理解するのに役立ちます。その後、シナリオ 2 で説明した推奨事項のいずれかにより検出結果を是正できます。
シナリオ 2 で推奨されている手順に加えて、機密情報がバックエンドのデータ ストレージに入るのを防ぐための対策を講じることも検討してください。Cloud Data Loss Prevention API の content メソッドでは、移動中のデータの検査やマスキングのために、あらゆるワークロードやアプリケーションからのデータの受け入れが可能です。たとえば、アプリケーションで次のようなことができます。
- ユーザーが入力したコメントを受け入れる。
content.deidentifyを実行して、その文字列の機密データを匿名化する。- 元の文字列ではなく、匿名化された文字列をバックエンドのストレージに保存する。
ベスト プラクティスの概要
次の表に、このドキュメントで推奨するベスト プラクティスをまとめます。
| 課題 | アクション |
|---|---|
| 組織がどのような種類のデータを保存しているか知る必要がある。 | 組織、フォルダ、プロジェクトのいずれかのレベルで検出を実行します。 |
| すでに保護されているリソースで機密データが発見された。 | 検出を実行し、プロファイルを Security Command Center、Google SecOps、Dataplex Universal Catalog に自動的にエクスポートして、そのリソースを継続的にモニタリングします。 |
| 保護されていないリソースで機密データが発見された。 | データを閲覧しているユーザーに応じてデータの表示 / 非表示を切り替えます(IAM、列レベルのセキュリティ、行レベルのセキュリティを使用)。Sensitive Data Protection の匿名化ツールを使用して、機密データを変換または削除することもできます。 |
| 機密データが発見され、データリスクの程度を把握するためにさらに調査する必要がある。 | リソースに対して検査ジョブを実行します。また、ほぼリアルタイムでデータを処理する DLP API の同期 content メソッドを使用して、機密データがバックエンドのストレージに侵入するのを事前に防止することもできます。 |