Ce tutoriel explique comment installer Filestore en tant que système de fichiers réseau, sur un service Cloud Run, afin de partager des données entre plusieurs conteneurs et services. Ce tutoriel utilise l'environnement d'exécution de deuxième génération de Cloud Run.
L'environnement d'exécution de deuxième génération permet l'installation des systèmes de fichiers réseau dans un répertoire de conteneur. L'installation d'un système de fichiers permet de partager des ressources entre un système hôte et des instances, et de conserver les ressources après la récupération de mémoire de l'instance.
L'utilisation d'un système de fichiers réseau avec Cloud Run nécessite des connaissances Docker avancées, car votre conteneur doit exécuter plusieurs processus, tels que l'installation du système de fichiers et le processus d'application. Ce tutoriel présente les concepts nécessaires et un exemple fonctionnel. Toutefois, lorsque vous adapterez ce tutoriel à votre propre application, assurez-vous de bien comprendre les implications de toute modification que vous pourriez apporter.
Présentation de la conception
L'instance Filestore est hébergée au sein d'un réseau cloud privé virtuel (VPC, Virtual Private Cloud). Les ressources d'un réseau VPC utilisent une plage d'adresses IP privées pour communiquer avec les API et les services Google. Par conséquent, les clients doivent se trouver sur le même réseau que l'instance Filestore pour accéder aux fichiers stockés sur cette instance. Un connecteur d'accès au VPC sans serveur est nécessaire pour que le service Cloud Run se connecte au réseau VPC afin de communiquer avec Filestore. En savoir plus sur l'accès au VPC sans serveur.
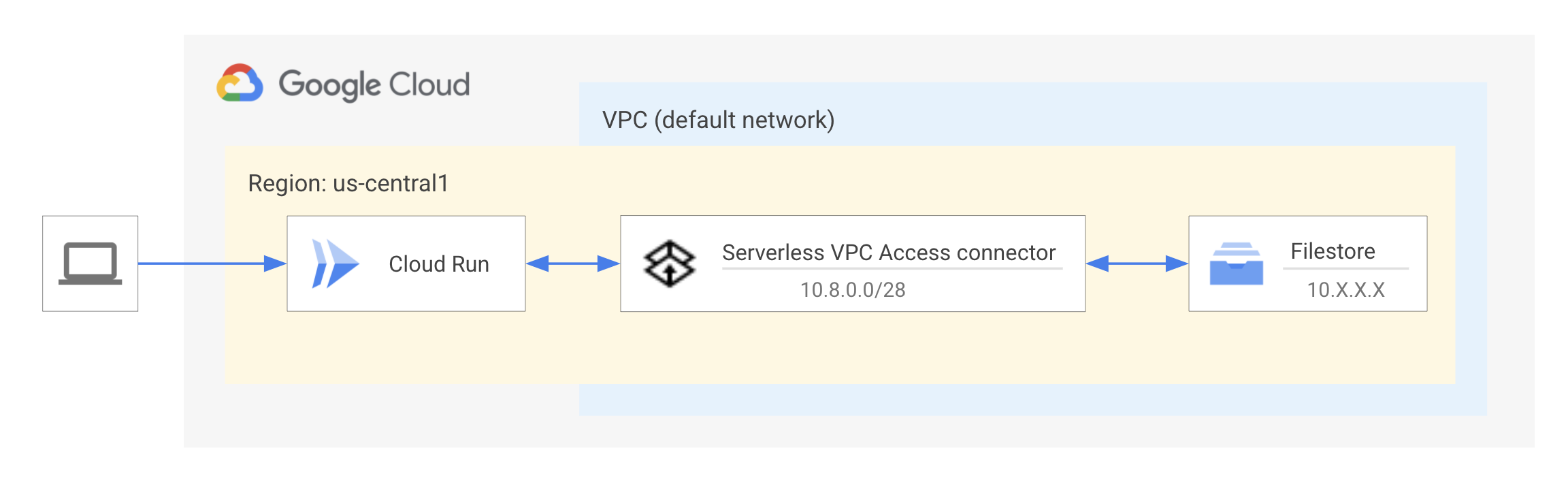
Le schéma montre le service Cloud Run en cours de connexion à l'instance Filestore via un connecteur d'accès au VPC sans serveur. Pour des performances optimales, l'instance et le connecteur Filestore sont situés dans le même réseau VPC, "default", et dans la même région/zone que le service Cloud Run.
Limites
Ce tutoriel n'explique pas comment choisir un système de fichiers ou des exigences de production. Apprenez-en plus sur Filestore et sur les niveaux de service disponibles.
Ce tutoriel n'explique pas comment utiliser un système de fichiers et ne traite pas des modèles d'accès aux fichiers.
Objectifs
Créez une instance Filestore sur le réseau VPC par défaut pour servir de partage de fichiers.
Créez un connecteur d'accès au VPC sans serveur sur le même réseau VPC par défaut pour vous connecter au service Cloud Run.
Créez un Dockerfile avec les packages système et les processus d'initialisation pour gérer les processus d'installation et d'application.
Déployez sur Cloud Run et vérifiez l'accès au système de fichiers dans le service.
Coûts
Ce tutoriel utilise des composants facturables de Google Cloud, dont :
Avant de commencer
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Cloud Run, Filestore, Serverless VPC Access, Artifact Registry, and Cloud Build .
- Installez et initialisez gcloud CLI.
- Mettez à jour Google Cloud CLI :
gcloud components update
Rôles requis
Pour obtenir les autorisations nécessaires pour suivre le tutoriel, demandez à votre administrateur de vous accorder les rôles IAM suivants sur votre projet :
-
Administrateur Artifact Registry (
roles/artifactregistry.admin) -
Éditeur Cloud Build (
roles/cloudbuild.builds.editor) -
Éditeur Cloud Filestore (
roles/file.editor) -
Administrateur Cloud Run (
roles/run.admin) -
Utilisateur de réseau Compute (
roles/compute.networkUser) -
Rôle d'administrateur pour l'accès au VPC sans serveur (
roles/vpcaccess.admin) -
Utilisateur du compte de service (
roles/iam.serviceAccountUser) -
Consommateur Service Usage (
roles/serviceusage.serviceUsageConsumer) -
Administrateur de l'espace de stockage (
roles/storage.admin)
Pour en savoir plus sur l'attribution de rôles, consultez la section Gérer les accès.
Vous pouvez également obtenir les autorisations requises via des rôles personnalisés ou d'autres rôles prédéfinis.
Configurer les paramètres par défaut de gcloud
Pour configurer gcloud avec les valeurs par défaut pour votre service Cloud Run, procédez comme suit :
Définissez le projet par défaut :
gcloud config set project PROJECT_ID
Remplacez PROJECT_ID par le nom du projet que vous avez créé pour ce tutoriel.
Configurez gcloud pour la région choisie :
gcloud config set run/region REGION
Remplacez REGION par la région Cloud Run compatible de votre choix.
Configurez gcloud pour Filestore :
gcloud config set filestore/zone ZONE
Remplacez ZONE par la zone Filestore acceptée de votre choix.
Récupérer l'exemple de code
Pour récupérer l’exemple de code à utiliser, procédez comme suit :
Clonez le dépôt de l'exemple d'application sur votre machine locale :
Node.js
git clone https://github.com/GoogleCloudPlatform/nodejs-docs-samples.git
Vous pouvez également télécharger l'exemple en tant que fichier ZIP et l'extraire.
Python
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git
Vous pouvez également télécharger l'exemple en tant que fichier ZIP et l'extraire.
Java
git clone https://github.com/GoogleCloudPlatform/java-docs-samples.git
Vous pouvez également télécharger l'exemple en tant que fichier ZIP et l'extraire.
Accédez au répertoire contenant l'exemple de code Cloud Run :
Node.js
cd nodejs-docs-samples/run/filesystem/
Python
cd python-docs-samples/run/filesystem/
Java
cd java-docs-samples/run/filesystem/
Comprendre le code
Normalement, vous devez exécuter un seul processus ou une seule application dans un conteneur. L'exécution d'un seul processus par conteneur réduit la complexité de gestion du cycle de vie de plusieurs processus : gestion des redémarrages, arrêt du conteneur en cas d'échec d'un processus, et responsabilités PID 1 telles que le transfert de signal et récupération d'enfant zombie. Toutefois, pour utiliser des systèmes de fichiers réseau dans Cloud Run, vous devez utiliser des conteneurs multiprocessus afin d'exécuter à la fois le processus d'installation du système de fichiers et l'application. Ce tutoriel explique comment arrêter le conteneur en cas d'échec du processus et gérer les responsabilités PID 1. La commande d'installation dispose d'une fonctionnalité intégrée de gestion des nouvelles tentatives.
Vous pouvez utiliser un gestionnaire de processus pour exécuter et gérer plusieurs processus en tant que point d'entrée du conteneur. Ce tutoriel utilise tini, un remplacement d'initialisation qui nettoie les processus zombie et effectue le transfert du signal. Plus précisément, ce processus d'initialisation permet au signal SIGTERM lors de l'arrêt de se propager à l'application. Le signal SIGTERM peut être détecté pour l'arrêt optimal de l'application. Apprenez-en plus sur le cycle de vie d'un conteneur sur Cloud Run.
Définir la configuration de votre environnement avec le fichier Dockerfile
Ce service Cloud Run nécessite un ou plusieurs packages système supplémentaires qui ne sont pas disponibles par défaut. L'instruction RUN installe tini en tant que processus d'initialisation et nfs-common, qui fournit une fonctionnalité minimale de client NFS. Pour en savoir plus sur l'utilisation des packages système dans votre service Cloud Run, consultez le tutoriel Utiliser des packages système.
Les instructions suivantes permettent de créer un répertoire de travail, de copier le code source et d'installer les dépendances de l'application.
ENTRYPOINT spécifie le binaire du processus d'initialisation qui précède les instructions CMD, dans ce cas il s'agit du script de démarrage. Cette opération lance un processus d'initialisation unique, puis sert de proxy pour tous les signaux reçus vers une session racine de ce processus enfant.
L'instruction CMD définit la commande à exécuter lors de l'exécution de l'image, le script de démarrage. Elle fournit également des arguments par défaut pour ENTRYPOINT. Découvrez comment CMD et ENTRYPOINT interagissent.
Node.js
Python
Java
Définir les processus dans le script de démarrage
Le script de démarrage crée un répertoire servant de point d'installation, où l'instance Filestore sera rendue accessible. Le script utilise ensuite la commande mount pour associer l'instance Filestore, en spécifiant l'adresse IP et le nom du partage de fichiers de l'instance, au point d'installation du service, puis démarre le serveur d'application. La commande mount dispose d'une fonctionnalité de nouvelle tentative intégrée. Un script bash supplémentaire n'est donc pas nécessaire. Enfin, la commande wait permet d'écouter les processus en arrière-plan à fermer, puis quitte le script.
Node.js
Python
Java
Utiliser des fichiers
Node.js
Consultez la page concernant index.js pour interagir avec le système de fichiers.
Python
Consultez la section concernant main.py pour interagir avec le système de fichiers.
Java
Consultez la section concernant FilesystemApplication.java pour interagir avec le système de fichiers.
Transmettre le service
Créez une instance Filestore :
gcloud filestore instances create INSTANCE_ID \ --tier=basic-hdd \ --file-share=name=FILE_SHARE_NAME,capacity=1TiB \ --network=name="default"Remplacez INSTANCE_ID par le nom de l'instance Filestore, c'est-à-dire
my-filestore-instance, et FILE_SHARE_NAME par le nom du répertoire diffusé à partir de l'instance Filestore, par exemplevol1. Consultez les sections Nommer votre instance et Nommer le partage de fichiers.Les clients (service Cloud Run) doivent se trouver sur le même réseau que l'instance Filestore pour accéder aux fichiers stockés sur cette instance. Cette commande crée l'instance dans le réseau VPC par défaut et attribue une plage d'adresses IP libre. Les nouveaux projets démarrent avec un réseau par défaut, et il est probablement inutile de créer un réseau distinct.
Consultez la page Créer des instances pour en savoir plus sur la configuration des instances.
Configurer un connecteur d'accès au VPC sans serveur :
Pour se connecter à votre instance Filestore, votre service Cloud Run doit avoir accès au réseau VPC autorisé de votre instance Filestore.
Chaque connecteur VPC nécessite son propre sous-réseau
/28pour y placer des instances. Cette plage d'adresses IP ne doit pas chevaucher les réservations d'adresses IP existantes sur votre réseau VPC. Par exemple,10.8.0.0(/28) fonctionnera dans la plupart des nouveaux projets ou vous pourrez spécifier une autre plage d'adresses IP personnalisée inutilisée, telle que10.9.0.0(/28). Vous pouvez afficher les plages d'adresses IP actuellement réservées dans la console Google Cloud.gcloud compute networks vpc-access connectors create CONNECTOR_NAME \ --region REGION \ --range "10.8.0.0/28"
Remplacez CONNECTOR_NAME par le nom de votre connecteur.
Cette commande crée un connecteur dans le réseau VPC par défaut, identique à l'instance Filestore, avec la taille de machine "e2-micro". L'augmentation de la taille de la machine du connecteur peut améliorer son débit, mais également augmenter les coûts. Le connecteur doit également se trouver dans la même région que le service Cloud Run. Découvrez comment configurer l'accès au VPC sans serveur.
Définissez une variable d'environnement avec l'adresse IP de l'instance Filestore :
export FILESTORE_IP_ADDRESS=$(gcloud filestore instances describe INSTANCE_ID --format "value(networks.ipAddresses[0])")
Créez un compte de service qui servira d'identité de service. Par défaut, il ne dispose d'aucun autre droit que l'abonnement au projet.
gcloud iam service-accounts create fs-identity
Ce service n'a pas besoin d'interagir avec autre chose dans Google Cloud. Par conséquent, aucune autorisation supplémentaire n'a besoin d'être attribuée à ce compte de service.
Créez et déployez l'image de conteneur dans Cloud Run :
gcloud run deploy filesystem-app --source . \ --vpc-connector CONNECTOR_NAME \ --execution-environment gen2 \ --allow-unauthenticated \ --service-account fs-identity \ --update-env-vars FILESTORE_IP_ADDRESS=$FILESTORE_IP_ADDRESS,FILE_SHARE_NAME=FILE_SHARE_NAMECette commande crée et déploie le service Cloud Run et spécifie le connecteur VPC et l'environnement d'exécution de deuxième génération. Le déploiement à partir de la source crée l'image à partir du Dockerfile et la transfère dans le dépôt Artifact Registry :
cloud-run-source-deploy.En savoir plus sur le déploiement à partir du code source.
Débogage
Si le déploiement échoue, consultez Cloud Logging pour plus d'informations.
Si la connexion expire, assurez-vous que vous fournissez l'adresse IP correcte de l'instance Filestore.
Si l'accès a été refusé par le serveur, vérifiez que le nom du partage de fichiers est correct.
Si vous souhaitez que tous les journaux du processus d'installation utilisent l'option
--verboseconjointement avec la commande d'installation, utilisez :mount --verbose -o nolock $FILESTORE_IP_ADDRESS:/$FILE_SHARE_NAME $MNT_DIR
Essayez-le !
Pour tester le service complet :
- Accédez dans votre navigateur à l'URL fournie par l'étape de déploiement ci-dessus.
- Vous devriez voir un fichier nouvellement créé dans votre instance Filestore.
- Cliquez sur le fichier pour en afficher le contenu.
Si vous décidez de poursuivre le développement de ces services, n'oubliez pas qu'ils ont un accès IAM restreint au reste de Google Cloud. Des rôles IAM supplémentaires devront donc leur être attribués afin de pouvoir accéder à de nombreux autres services.
Discussion sur les coûts
Exemple de répartition des coûts pour un service, hébergé dans l'Iowa (us-central1) avec une instance Filestore de 1 Tio et un connecteur d'accès au VPC sans serveur. Consultez les pages des tarifs individuels pour obtenir les prix les plus récents.
| Produit | Coût mensuel |
|---|---|
| Filestore (indépendant du volume utilisé) | Coût = capacité provisionnée (1 024 Gio ou 1 Tio) x prix du niveau régional (us-central1) Niveau HDD de base : 1 024 Gio x 0,16 $/mois = 163,84 $ Zonal (SSD) : 1 024 Gio x 0,25 $/mois = 256 $ Enterprise (SSD, disponibilité régionale) : 1 024 Gio x 0,45 $/mois = 460,80 $ |
| Accès au VPC sans serveur | Coût = prix de la machine x nombre d'instances (nombre minimal d'instances défini sur 2) f1-micro : 3,88 $ x 2 instances = 7,76 $ e2 micro : 6,11 $ x 2 instances = 12,22 $ e2-standard-4 : 97,83 $ x 2 instances = 195,66 $ |
| Cloud Run | Coût = processeur + mémoire + requêtes + mise en réseau |
| Total | 163,84 $ + 12,22 $ = 176,06 $/mois + coût de Cloud Run |
Ce tutoriel utilise une instance Filestore de niveau HDD de base. Le niveau de service d'une instance Filestore est une combinaison de type d'instance et de type de stockage. Le type d'instance peut être mis à niveau pour améliorer la capacité et l'évolutivité. Le type de stockage peut être mis à niveau pour améliorer les performances. Obtenez plus d'informations sur les recommandations concernant les types de stockage. La région et la capacité affectent également les tarifs de Filestore. Par exemple, une instance de 1 Tio de niveau HDD de base dans l'Iowa (us-central1) coûte 0,16 $ par Gio et par mois, soit environ 163,84 $ par mois.
Le connecteur d'accès au VPC sans serveur est facturé en fonction de la taille et du nombre d'instances, ainsi que de la sortie réseau. L'augmentation de cette taille et de ce nombre peut améliorer le débit ou réduire la latence des messages. Il existe trois tailles de machines : f1-micro, e2-micro et e2-standard-4. Le nombre minimal d'instances étant de 2, le coût minimal correspond au double du coût de cette taille de machine.
Cloud Run est facturé en fonction de l'utilisation des ressources, arrondie à la centaine de millisecondes la plus proche pour la mémoire, le processeur, le nombre de requêtes et la mise en réseau. Par conséquent, le coût varie en fonction des paramètres de votre service, du nombre de requêtes et du temps d'exécution. Le coût minimal de ce service est de 176,06 $ par mois. Affichez et explorez une estimation dans le simulateur de coût Google Cloud.
Effectuer un nettoyage
Si vous avez créé un projet pour ce tutoriel, supprimez-le. Si vous avez utilisé un projet existant et que vous souhaitez le conserver sans les modifications du présent tutoriel, supprimez les ressources créées pour ce tutoriel.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer les ressources du tutoriel
Supprimez le service Cloud Run que vous avez déployé dans ce tutoriel :
gcloud run services delete SERVICE-NAME
Où SERVICE-NAME est le nom de service que vous avez choisi.
Vous pouvez également supprimer des services Cloud Run à partir de Google Cloud Console.
Supprimez la configuration régionale gcloud par défaut que vous avez ajoutée lors de la configuration du tutoriel :
gcloud config unset run/regionSupprimez la configuration du projet :
gcloud config unset projectSupprimez les autres ressources Google Cloud créées dans ce tutoriel :
- Supprimez l'instance Filestore.
- Supprimez le connecteur d'accès au VPC sans serveur
- Supprimez l'image de conteneur du service, nommée
gcr.io/PROJECT_ID/filesystem-app, de Artifact Registry. - Supprimez le compte de service
fs-identity@PROJECT_ID.iam.gserviceaccount.com.
Étape suivante
- Consultez le guide de dépannage.
- En savoir plus sur Filestore.
- Approfondissez vos connaissances sur la configuration de l'accès au VPC sans serveur.
- Découvrez les outils de diagnostic de l'accès au VPC sans serveur pour résoudre les problèmes de réseau sans serveur.
- Découvrez comment choisir un processus d'initialisation pour les conteneurs multiprocessus.