将建议导出到 BigQuery
概览
借助 BigQuery Export,您可以查看组织的建议的每日快照。这是通过 BigQuery Data Transfer Service 实现的。如需了解 BigQuery Export 目前包含哪些 Recommender,请参阅此文档。
准备工作
为建议创建数据转移作业之前,请完成以下步骤:
- 授予 BigQuery Data Transfer Service 管理您的数据转移作业的权限。如果您使用 BigQuery 网页界面创建转移作业,则必须在您的浏览器中允许
console.cloud.google.com显示弹出式窗口以便于查看权限。如需了解详情,请参阅启用 BigQuery Data Transfer Service。 - 创建 BigQuery 数据集来存储数据。
- 数据转移作业使用创建数据集的区域。创建数据集和转移作业后,该位置将不可变。
- 该数据集会包含全球所有区域的数据分析和建议。因此,在该过程中,此操作会将所有这些数据汇总到一个全球区域。如果您有任何数据驻留地问题,请咨询 Google Cloud Customer Care。
- 如果新启动了数据集位置,则初始导出数据的可用性可能会延迟。
价格
所有 Recommender 客户都可以根据 Recommender 价格层级将建议导出到 BigQuery。
所需权限
设置数据转移作业时,您需要在创建数据转移作业的项目级层拥有以下权限:
bigquery.transfers.update- 允许您创建转移作业bigquery.datasets.update- 允许您更新目标数据集上的操作resourcemanager.projects.update- 允许您选择要存储导出数据的项目pubsub.topics.list- 允许您选择 Pub/Sub 主题,以接收关于导出的通知
您需要拥有组织级别的以下权限。此组织对应于正在为其设置导出操作的组织。
recommender.resources.export- 允许您将建议导出到 BigQuery
如需导出协议价以提供费用节省建议,您需要拥有以下权限:
billing.resourceCosts.get at project level- 允许导出协议价以提供项目级建议billing.accounts.getSpendingInformation at billing account level- 允许导出协议价以提供结算账号级建议
如果没有这些权限,系统会以标准价格(而非协议价)导出费用节省建议。
授予权限
您必须在创建数据转移作业的项目中授予以下角色:
- BigQuery Admin 角色 -
roles/bigquery.admin - Project Owner 角色 -
roles/owner - Project Owner 角色 -
roles/owner - Project Viewer 角色 -
roles/viewer - Project Editor 角色 -
roles/editor - Billing Account Administrator 角色 -
roles/billing.admin - Billing Account Costs Manager 角色 -
roles/billing.costsManager - Billing Account Viewer 角色 -
roles/billing.viewer
要允许在目标数据集上创建转移作业以及更新操作,您必须授予以下角色:
有多个角色包含选择项目以存储导出数据以及选择 Pub/Sub 主题来接收通知的权限。如需获得这些权限,您可以授予以下角色:
有多个角色包含导出协议价以提供项目级费用节省建议所需的权限 billing.resourceCosts.get,授予其中任何一个角色即可:
有多个角色包含导出协议价以提供结算账号级费用节省建议所需的权限 billing.accounts.getSpendingInformation,授予其中任何一个角色即可:
您必须在组织级层授予以下角色:
- Google Cloud 控制台上的 Recommendations Exporter (
roles/recommender.exporter) 角色。
为建议创建数据转移作业
登录 Google Cloud 控制台。
从首页屏幕中点击建议标签页。
点击导出查看 BigQuery Export 表单。
选择一个目标项目以存储建议数据,然后点击下一步。

点击启用 API,为导出启用 BigQuery API。这可能需要几秒钟的时间才能完成。完成后,点击继续。
在配置转移作业表单中,提供以下详细信息:
在转移配置名称部分的显示名中,输入转移作业的名称。转移作业名称可以是任何容易辨识的值,让您以后在需要修改时能够轻松识别。
在时间表选项部分的时间表中,保留默认值(立即开始)或点击在设置的时间开始 (Start at a set time)。
在重复频率部分中,选择转移作业的运行频率选项。
- 每日一次(默认值)
- 每周
- 每月
- 自定义
- 按需
在开始日期和运行时间部分,输入开始转移作业的日期和时间。如果您选择的是立即开始,则系统会停用此选项。

在目标设置部分的目标数据集中,选择您创建的用来存储数据的数据集 ID。

在数据源详细信息部分,执行以下操作:
organization_id 的默认值是您当前查看其建议的组织。如果要将建议导出到其他组织,可以在控制台顶部的组织查看器中进行更改。

(可选)在通知选项部分,执行以下操作:
- 点击切换开关以启用电子邮件通知。启用此选项后,转移作业管理员会在转移作业运行失败时收到电子邮件通知。
- 在选择 Pub/Sub 主题部分,选择您的主题名称,或点击创建主题。此选项用于为您的转移作业配置 Pub/Sub 运行通知。

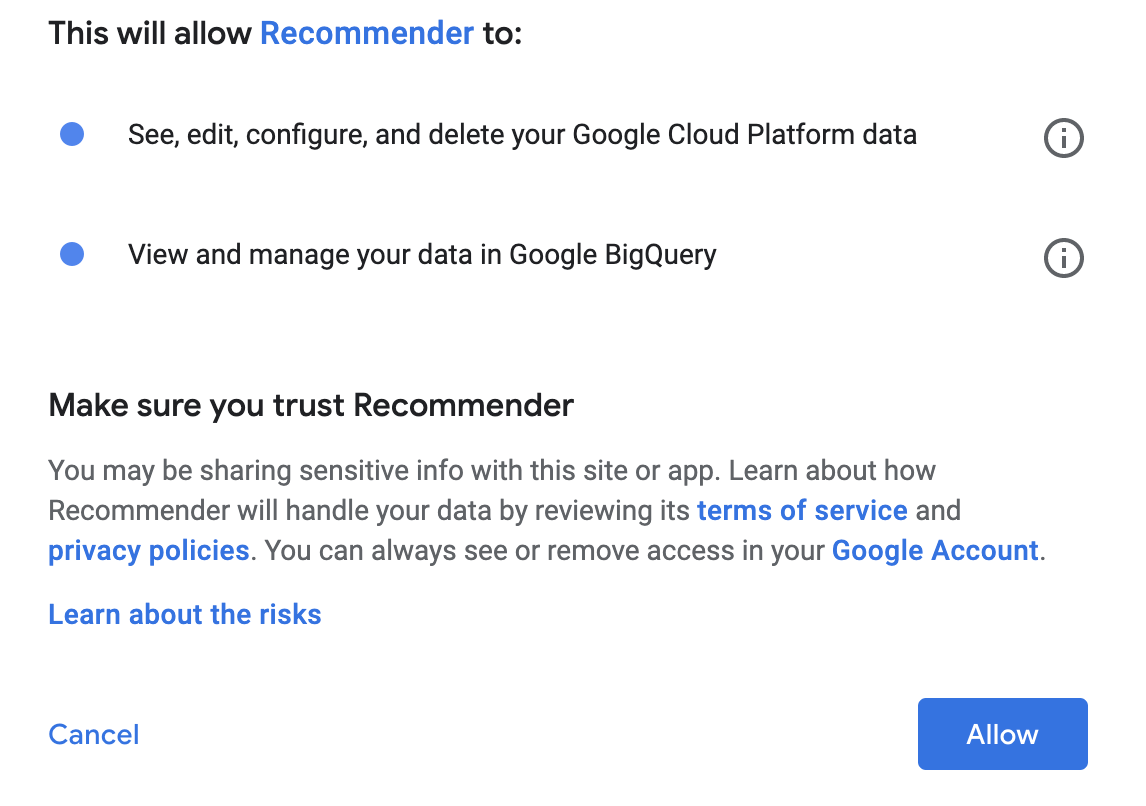
点击创建以创建转移作业。
在弹出的同意窗口中点击允许。
转移作业创建后,您将被定向回 Recommendation Hub。您可以点击链接以访问转移作业配置详细信息。或者,您也可以通过执行以下操作来访问转移作业:
转到 Google Cloud 控制台中的 BigQuery 页面。
点击数据传输。您可以查看所有可用的数据转移作业。
查看转移作业的运行历史记录
要查看转移作业的运行历史记录,请执行以下操作:
转到 Google Cloud 控制台中的 BigQuery 页面。
点击数据传输。您可以查看所有可用的数据转移作业。
点击列表中的相应转移作业。
在运行历史记录标签页下显示的运行转移作业列表中,选择您要查看其详情的转移作业。
系统会显示您选择的单个运行转移作业的运行详情面板。可能显示的运行详情如下:
- 由于源数据不可用,转移作业已推迟。
- 表示导出到表的行数的作业
- 缺少必须授予的某个数据源的权限,稍后安排回填。
何时导出数据?
创建数据转移作业时,首次导出操作会在两天内进行。首次导出后,导出作业将按照您在设置时指定的频率运行。以下条件适用:
特定日期 (D) 的导出作业会将当天结束时 (D) 的数据导出到 BigQuery 数据集,该作业通常会在次日结束时 (D+1) 完成。导出作业在 PST 时区运行,对于其他时区可能会有延迟。
每日导出作业在要导出的所有数据都可用之后才会运行。 这可能会导致数据集更新的日期和时间发生变化,有时可能会延迟。因此,最好使用最新可用的数据快照,而不是对特定日期表具有硬性时间敏感型依赖。
导出作业会传输每个区域的最新可用数据,这意味着不同区域提供的建议的最新日期可能会有所不同。
导出时的常见状态消息
了解将建议导出到 BigQuery 时您可能会看到的常见状态消息。
用户没有所需权限
如果用户没有所需的权限 recommender.resources.export,系统会显示以下消息。您将看到以下消息:
User does not have required permission "recommender.resources.export". Please, obtain the required permissions for the datasource and try again by triggering a backfill for this date
如需解决此问题,请向在组织级层为已设置导出的组织设置导出的 user/service account 授予 IAM 角色 roles/recommender.exporter。可以通过下面的 gcloud 命令授予该角色:
对于用户:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='user:*<user_name>*' --role='roles/recommender.exporter'对于服务账号:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'
由于源数据不可用,转移作业已推迟
由于源数据尚不可用,因此重新安排转移作业时,会出现以下消息。这不是错误,它表示当天的导出流水线尚未完成。转移作业将在新的计划时间重新运行,并将在导出流水线完成后成功。您将看到以下消息:
Transfer deferred due to source data not being available
未找到源数据
如果 F1toPlacer 流水线完成,但是没有为设置导出的组织找到建议或数据分析,则会出现以下消息。您将看到以下消息:
Source data not found for 'recommendations_export$<date>'insights_export$<date>
出现此消息的原因如下:
- 用户设置导出的时间还不到 2 天。通过客户指南,客户可以知道导出可用之前有一天的延迟。
- 组织在特定日期没有建议或数据分析。这可能是实际情况,也可能是流水线在当天所有建议或数据分析可用之前就已运行。
查看转移作业的表
将建议导出到 BigQuery 时,数据集包含两个按日期分区的表:
- recommendations_export
- insight_export
如需查看数据转移作业的表,请执行以下操作:
在 Google Cloud 控制台中转到 BigQuery 页面。 转到 BigQuery 页面
点击数据传输。您可以查看所有可用的数据转移作业。
点击列表中的相应转移作业。
点击配置标签页,然后点击数据集。
在浏览器面板中,展开您的项目并选择数据集。 说明和详细信息会显示在详细信息面板中。数据集的表以及数据集名称会在 Explorer 面板中列出。
安排回填
可以通过安排回填导出过去日期的建议(此日期晚于将组织加入导出的日期)。要安排回填,请执行以下操作:
转到 Google Cloud 控制台中的 BigQuery 页面。
点击数据传输。
在转移作业页面上,点击列表中的相应转移作业。
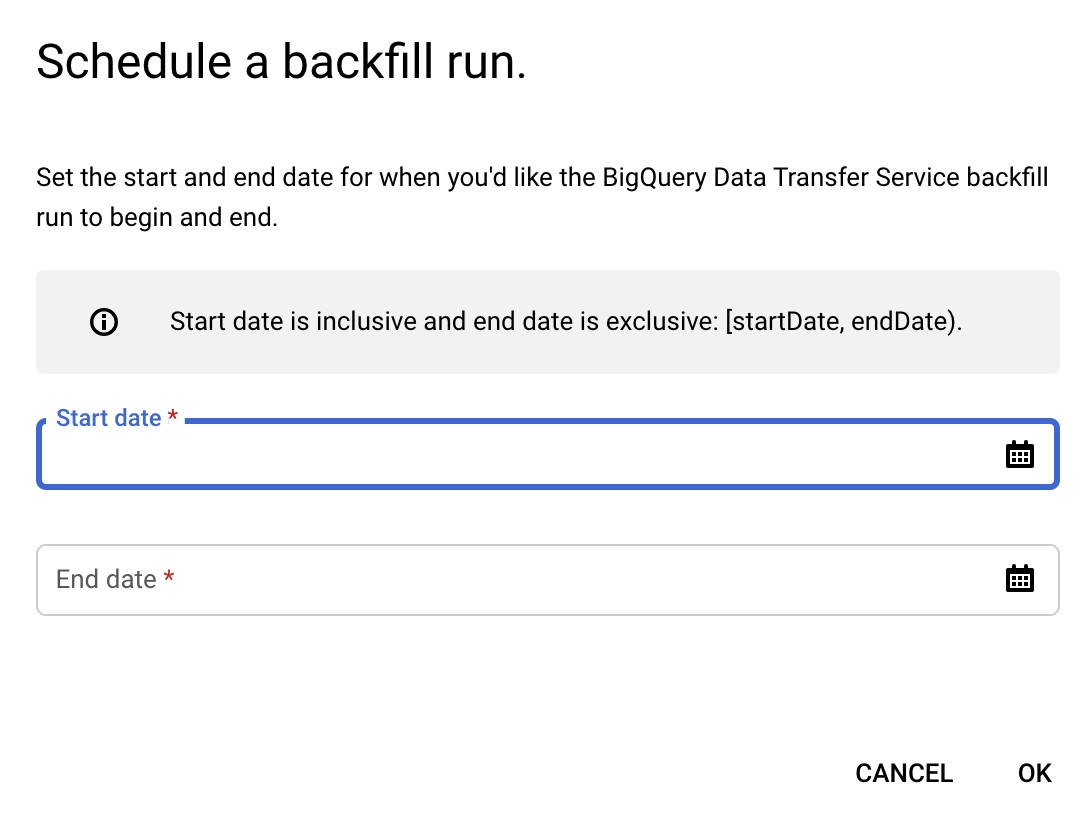
点击安排回填。
在安排回填对话框中,选择开始日期和结束日期。
如需详细了解如何处理转移作业,请参阅处理转移作业。
导出架构
建议导出表:
schema:
fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: recommender
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: recommender_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: primary_impact
type: RECORD
description: |
Required. The primary impact that this recommendation can have while trying to optimize
for one category.
schema:
fields:
- name: category
type: STRING
description: |
Category that is being targeted.
Values can be the following:
CATEGORY_UNSPECIFIED:
Default unspecified category. Do not use directly.
COST:
Indicates a potential increase or decrease in cost.
SECURITY:
Indicates a potential increase or decrease in security.
PERFORMANCE:
Indicates a potential increase or decrease in performance.
RELIABILITY:
Indicates a potential increase or decrease in reliability.
- name: cost_projection
type: RECORD
description: Optional. Use with CategoryType.COST
schema:
fields:
- name: cost
type: RECORD
description: |
An approximate projection on amount saved or amount incurred.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: cost_in_local_currency
type: RECORD
description: |
An approximate projection on amount saved or amount incurred in the local currency.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: duration
type: RECORD
description: Duration for which this cost applies.
schema:
fields:
- name: seconds
type: INTEGER
description: |
Signed seconds of the span of time. Must be from -315,576,000,000
to +315,576,000,000 inclusive. Note: these bounds are computed from:
60 sec/min * 60 min/hr * 24 hr/day * 365.25 days/year * 10000 years
- name: nanos
type: INTEGER
description: |
Signed fractions of a second at nanosecond resolution of the span
of time. Durations less than one second are represented with a 0
`seconds` field and a positive or negative `nanos` field. For durations
of one second or more, a non-zero value for the `nanos` field must be
of the same sign as the `seconds` field. Must be from -999,999,999
to +999,999,999 inclusive.
- name: pricing_type_name
type: STRING
description: |
A pricing type can either be based on the price listed on GCP (LIST) or a custom
price based on past usage (CUSTOM).
- name: reliability_projection
type: RECORD
description: Optional. Use with CategoryType.RELIABILITY
schema:
fields:
- name: risk_types
type: STRING
mode: REPEATED
description: |
The risk associated with the reliability issue.
RISK_TYPE_UNSPECIFIED:
Default unspecified risk. Do not use directly.
SERVICE_DISRUPTION:
Potential service downtime.
DATA_LOSS:
Potential data loss.
ACCESS_DENY:
Potential access denial. The service is still up but some or all clients
can not access it.
- name: details_json
type: STRING
description: |
Additional reliability impact details that is provided by the recommender in JSON
format.
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_insights
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: recommendation_details
type: STRING
description: |
Additional details about the recommendation in JSON format.
schema:
- name: overview
type: RECORD
description: Overview of the recommendation in JSON format
- name: operation_groups
type: OperationGroup
mode: REPEATED
description: Operations to one or more Google Cloud resources grouped in such a way
that, all operations within one group are expected to be performed
atomically and in an order. More here: https://cloud.google.com/recommender/docs/key-concepts#operation_groups
- name: operations
type: Operation
description: An Operation is the individual action that must be performed as one of the atomic steps in a suggested recommendation. More here: https://cloud.google.com/recommender/docs/key-concepts?#operation
- name: state_metadata
type: map with key: STRING, value: STRING
description: A map of STRING key, STRING value of metadata for the state, provided by user or automations systems.
- name: additional_impact
type: Impact
mode: REPEATED
description: Optional set of additional impact that this recommendation may have when
trying to optimize for the primary category. These may be positive
or negative. More here: https://cloud.google.com/recommender/docs/key-concepts?#recommender_impact
- name: priority
type: STRING
description: |
Priority of the recommendation:
PRIORITY_UNSPECIFIED:
Default unspecified priority. Do not use directly.
P4:
Lowest priority.
P3:
Second lowest priority.
P2:
Second highest priority.
P1:
Highest priority.
数据分析导出表:
schema:
- fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: insight_type
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: insight_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: category
type: STRING
description: |
Category being targeted by the insight. Can be one of:
Unspecified category.
CATEGORY_UNSPECIFIED = Unspecified category.
COST = The insight is related to cost.
SECURITY = The insight is related to security.
PERFORMANCE = The insight is related to performance.
MANAGEABILITY = The insight is related to manageability.
RELIABILITY = The insight is related to reliability.;
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_recommendations
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: insight_details
type: STRING
description: |
Additional details about the insight in JSON format
schema:
fields:
- name: content
type: STRING
description: |
A struct of custom fields to explain the insight.
Example: "grantedPermissionsCount": "1000"
- name: observation_period
type: TIMESTAMP
description: |
Observation period that led to the insight. The source data used to
generate the insight ends at last_refresh_time and begins at
(last_refresh_time - observation_period).
- name: state_metadata
type: STRING
description: |
A map of metadata for the state, provided by user or automations systems.
- name: severity
type: STRING
description: |
Severity of the insight:
SEVERITY_UNSPECIFIED:
Default unspecified severity. Do not use directly.
LOW:
Lowest severity.
MEDIUM:
Second lowest severity.
HIGH:
Second highest severity.
CRITICAL:
Highest severity.
示例查询
您可以使用以下示例查询来分析导出的数据。
查看建议的节省费用(以天为单位显示建议时长)
SELECT name, recommender, target_resources,
case primary_impact.cost_projection.cost.units is null
when true then round(primary_impact.cost_projection.cost.nanos * power(10,-9),2)
else
round( primary_impact.cost_projection.cost.units +
(primary_impact.cost_projection.cost.nanos * power(10,-9)), 2)
end
as dollar_amt,
primary_impact.cost_projection.duration.seconds/(60*60*24) as duration_in_days
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and primary_impact.category = "COST"
查看未使用的 IAM 角色的列表
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REMOVE_ROLE"
查看必须被更小角色取代的已授予角色的列表
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REPLACE_ROLE"
查看建议的数据分析
SELECT recommendations.name as recommendation_name,
insights.name as insight_name,
recommendations.cloud_entity_id,
recommendations.cloud_entity_type,
recommendations.recommender,
recommendations.recommender_subtype,
recommendations.description,
recommendations.target_resources,
recommendations.recommendation_details,
recommendations.state,
recommendations.last_refresh_time as recommendation_last_refresh_time,
insights.insight_type,
insights.insight_subtype,
insights.category,
insights.description,
insights.insight_details,
insights.state,
insights.last_refresh_time as insight_last_refresh_time
FROM `<project>.<dataset>.recommendations_export` as recommendations,
`<project>.<dataset>.insights_export` as insights
WHERE DATE(recommendations._PARTITIONTIME) = "<date>"
and DATE(insights._PARTITIONTIME) = "<date>"
and insights.name in unnest(recommendations.associated_insights)
查看属于特定文件夹的项目的建议
此查询会返回从项目开始的最多五层父文件夹。
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and "<folder_id>" in unnest(ancestors.folder_ids)
查看到目前为止已导出的最新可用日期的建议
DECLARE max_date TIMESTAMP;
SET max_date = (
SELECT MAX(_PARTITIONTIME) FROM
`<project>.<dataset>.recommendations_export`
);
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE _PARTITIONTIME = max_date
使用表格探索 BigQuery 数据
作为在 BigQuery 上执行查询的替代方法,您可以使用新的 BigQuery 数据连接器“关联工作表”从电子表格中访问、分析、直观呈现和共享数十亿行 BigQuery 数据。如需了解详情,请参阅 Google 表格中的 BigQuery 数据使用入门。
使用 BigQuery Command Line & REST API 设置导出
-
您可以通过 Google Cloud 控制台或命令行获取所需的 Identity and Access Management 权限。
例如,如需使用命令行获取服务账号的组织级 recommender.resources.export 权限,请运行以下命令:
gcloud organizations add-iam-policy-binding *<organization_id>* --member=serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter' -
Datasource to use: 6063d10f-0000-2c12-a706-f403045e6250 创建导出:
使用 BigQuery 命令行:
bq mk \ --transfer_config \ --project_id=project_id \ --target_dataset=dataset_id \ --display_name=name \ --params='parameters' \ --data_source=data_source \ --service_account_name=service_account_name
其中:
- project_id 是项目 ID。
- dataset 是转移作业配置的目标数据集 ID。
- name 是转移作业配置的显示名。转移作业名称可以是任何容易辨识的值,让您以后在需要修改时能够轻松识别。
- parameters 包含所创建转移作业配置的参数(采用 JSON 格式),对于建议和数据分析的 BigQuery Export,您必须提供需要导出建议和数据分析的 organization_id。参数格式:“{"organization_id":"<org id>"}”
- data_source 是要使用的数据源:“6063d10f-0000-2c12-a706-f403045e6250”
- service_account_name 是用于对导出进行身份验证的服务账号名称。该服务账号应属于用于创建转移作业的同一
project_id,并且应具有上面列出的所有必要权限。
通过界面或 BigQuery 命令行管理现有导出:
注意 - 无论后续有哪些用户对导出配置进行了更新,导出作业都会以设置该账号的用户身份运行。例如,如果导出是使用某个服务账号进行设置的,并且后续某个用户通过 BigQuery Data Transfer Service 界面更新了导出配置,那么导出作业将继续以该服务账号身份运行。在这种情况下,系统会在每次运行导出作业时检查该服务账号的“recommender.resources.export”权限。