En esta guía se explica cómo funcionan las funciones de fiabilidad de Pub/Sub.
¿Por qué Pub/Sub?
Como paradigma de mensajería, la publicación-suscripción se ha diseñado para desacoplar a los productores de mensajes de los consumidores de esos mensajes. En lugar de enviar solicitudes directas a los consumidores con los datos, los productores publican esos datos en un servicio de Pub/Sub, como Pub/Sub. El servicio envía esos mensajes de forma asíncrona a los consumidores interesados que se hayan suscrito.
El resultado es que el servicio absorbe todas las complejidades de encontrar consumidores interesados en los datos. El servicio también gestiona la velocidad a la que los consumidores reciben los datos en función de su capacidad. El desacoplamiento permite a los productores de datos escribir mensajes a gran escala con una latencia baja, independientemente del comportamiento de los consumidores.
Pub/Sub ofrece una entrega de mensajes fiable y altamente escalable. Aunque el servicio gestiona gran parte de este proceso automáticamente, puedes controlar diferentes aspectos de tus editores y suscriptores que pueden afectar a la disponibilidad y al rendimiento. En el resto de esta guía se ofrecen algunos detalles sobre estos aspectos.
Aislamiento
De forma predeterminada, Pub/Sub es un servicio global: los temas y las suscripciones no están vinculados de forma inherente a regiones específicas, y los mensajes fluyen dentro del servicio Pub/Sub entre regiones cuando es necesario. Cuando se usa el endpoint global, pubsub.googleapis.com, los editores y los suscriptores se conectan a la región más cercana de la red en la que se ejecuta Pub/Sub. Cuando se usan los puntos finales regionales, como us-central1-pubsub.googleapis.com, o los puntos finales de ubicación, como pubsub.us-central1.rep.googleapis.com, los editores y los suscriptores se conectan a Pub/Sub en la región especificada. Cuando ejecutes editores o suscriptores fuera de Google Cloud, es mejor que uses endpoints regionales o de ubicación para asegurarte de que los mensajes fluyan entre las regiones esperadas de forma coherente.
Aislamiento regional
Para minimizar la infraestructura de la que dependen las operaciones de publicación y suscripción fuera de una sola región y asegurarte de que todos los datos permanezcan aislados en esa región, sigue estos pasos:
Crea un tema por región.
Aunque el espacio de nombres de Pub/Sub es global y no puedes asociar temas y suscripciones a una región específica, los metadatos de todos los recursos se replican en almacenes de datos locales de la región. Por lo tanto, una vez que creas un recurso, su configuración está disponible incluso si hay un problema en otra región. Ten en cuenta que es posible que las actualizaciones de las configuraciones de temas o suscripciones no se propaguen inmediatamente en caso de interrupción.
Evita usar endpoints globales.
En su lugar, usa puntos finales regionales cuando estén disponibles y puntos finales de ubicación cuando no lo estén. Los endpoints regionales ofrecen un mayor aislamiento regional, pero aún no están disponibles en todas las regiones.
Usa una política de almacenamiento de mensajes y define
enforceInTransitcomoTrue.Si la opción Forzar en tránsito está habilitada, los datos nunca salen de la región y todos los clientes que se conectan al tema en una región específica definen la política de almacenamiento de mensajes en esa región.
Si los temas se configuran de esta forma, puedes estar seguro de que todas las operaciones de publicación y suscripción escriben y leen datos exclusivamente en la región. Si se produce un error en el editor, el suscriptor o Pub/Sub en una sola región, la entrega de mensajes se detendrá en esa región. El envío de mensajes a temas y suscripciones de otras regiones no se verá afectado.
Si también necesitas que las operaciones administrativas y el espacio de nombres de tus temas y suscripciones estén aislados por regiones, te recomendamos que uses Managed Service para Apache Kafka.
Conmutación por error
Si no necesitas aislamiento regional, puedes aprovechar la capacidad de Pub/Sub para enviar mensajes de forma eficiente en varias regiones y, de este modo, conseguir funciones de conmutación por error multirregional. En el resto de esta sección se explica cómo crear temas y suscripciones, y cómo colocar editores y suscriptores para admitir diferentes tipos de conmutación por error y redundancia de datos.
Semántica de conmutación por error predeterminada
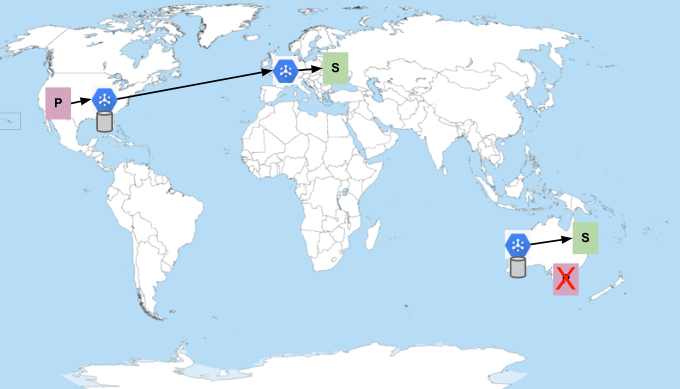
Imagina un caso en el que haya un solo tema y una sola suscripción. Los editores se encuentran en regiones de Australia y Estados Unidos, y los suscriptores, en regiones de Australia y Europa. Google Cloud En el caso de que todos los suscriptores tengan capacidad suficiente para recibir mensajes, el flujo de mensajes será el siguiente:
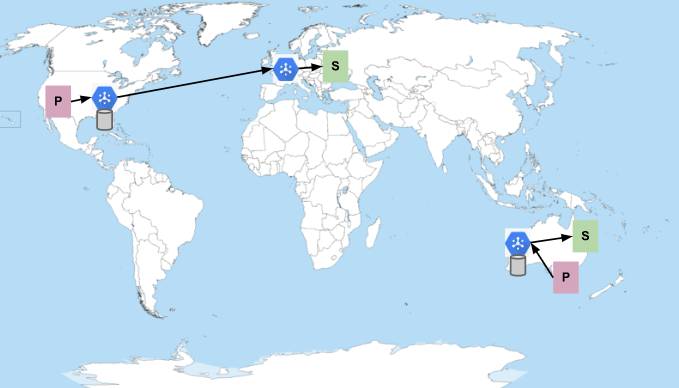
Las P representan a los editores y las S, a los suscriptores. El hexágono azul representa el servicio Pub/Sub. Los cilindros representan los lugares donde se almacenan los mensajes (los mensajes siempre se conservan en varias zonas de la región en la que se publican). Pub/Sub prefiere enviar mensajes en la misma región en la que se publicaron cuando hay suscriptores disponibles. De lo contrario, envía los mensajes a la región más cercana a la red con suscriptores que tengan capacidad. Por lo tanto, como se muestra en la imagen anterior, los mensajes publicados en Estados Unidos se envían a los suscriptores de Europa, y los mensajes publicados en Australia se quedan en Australia.
En las siguientes secciones se explica qué ocurre en diferentes situaciones de fallo.
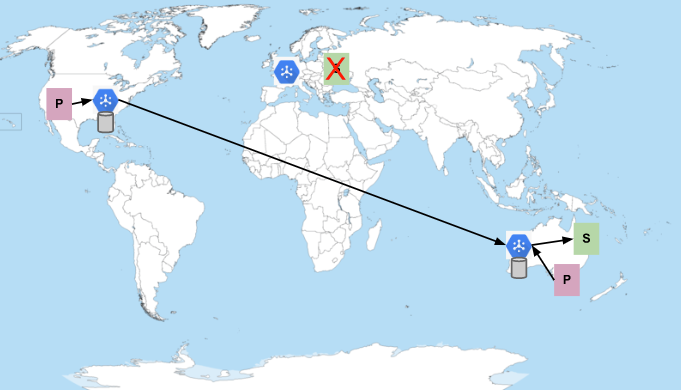
Los suscriptores de Europa no están disponibles
Supongamos que los suscriptores de Europa se han rechazado o que fallan con frecuencia y no pueden mantener una conexión con Pub/Sub. Si esto ocurriera, el servicio empezaría a enviar mensajes a los suscriptores de Australia:
Los suscriptores de Australia y Europa no están disponibles
Si todos los suscriptores no están disponibles, Pub/Sub almacena los mensajes hasta que se cumpla el periodo de retención de mensajes configurado.
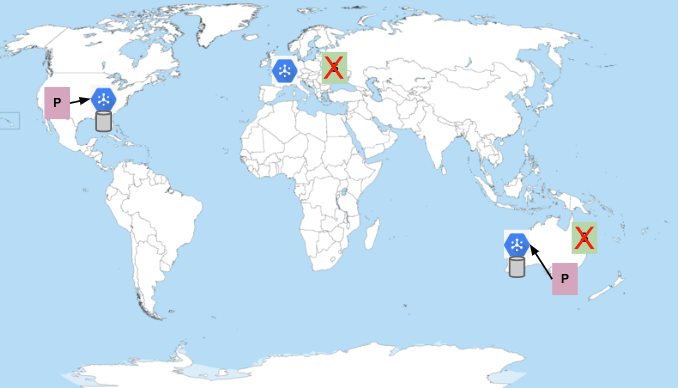
Cuando los suscriptores vuelvan a conectarse, los mensajes se entregarán, a menos que la interrupción dure más que el periodo de retención de mensajes configurado. De forma predeterminada, los mensajes de suscripción se conservan durante 7 días. También puedes configurar la retención de mensajes en un tema durante un máximo de 31 días. No elijas una duración de retención de mensajes inferior al tiempo máximo de interrupción que esperas o que estás dispuesto a tolerar.
Pub/Sub no está disponible en Europa
Aunque no es habitual, también puede que quieras gestionar los casos en los que Pub/Sub no esté disponible. La falta de disponibilidad de Pub/Sub se manifiesta como periodos prolongados de errores inesperados en las solicitudes de publicación o suscripción, o como la imposibilidad de entregar mensajes publicados a los suscriptores. Por ejemplo, si Pub/Sub no funcionara en la región de Europa, la situación sería muy parecida a cuando los suscriptores no funcionan:
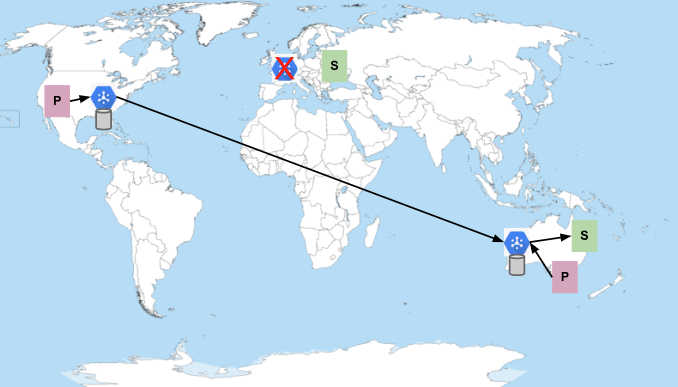
Ten en cuenta que, en este caso, los suscriptores de Europa no se conmutan por error a otra región, aunque utilicen el endpoint global. Pub/Sub no realiza una conmutación por error automáticamente. Imagina que son los propios suscriptores los que provocan un problema inesperado en Pub/Sub que da como resultado una falta de disponibilidad. Este tipo de problema se considera una interrupción grave. Sin embargo, el alcance de la interrupción se puede limitar a la región a la que se hayan conectado los suscriptores. Si el servicio les permitiera conmutar por error a otra región, los suscriptores también podrían provocar una falta de disponibilidad en esa región, lo que provocaría un error en cascada en todo el servicio.
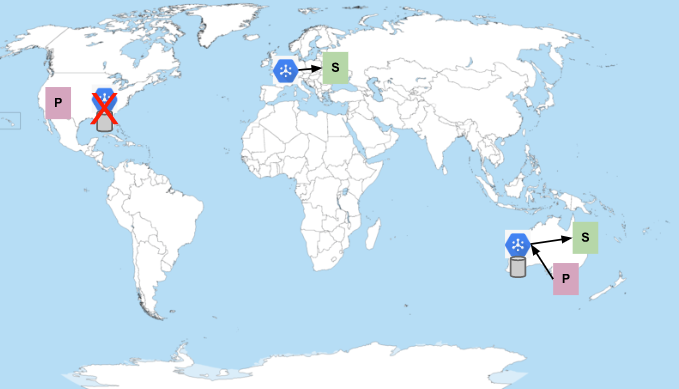
Los editores de Australia no están disponibles
Si los editores de una región dejan de estar disponibles, los mensajes que ya se hayan publicado se seguirán enviando a los suscriptores más cercanos:
Finalmente, los suscriptores consumen y confirman todos los mensajes. Al enviar mensajes, Pub/Sub intenta minimizar la distancia de la red. Por lo tanto, los suscriptores de la región de Australia pueden dejar de recibir mensajes si los suscriptores de Europa tienen capacidad suficiente para gestionar todos los mensajes publicados en Estados Unidos.
Pub/Sub no está disponible en Estados Unidos
Pub/Sub escribe mensajes de forma síncrona en varias zonas de una región. Por lo tanto, una interrupción zonal no es suficiente para impedir la entrega de mensajes; toda la región debe no estar disponible. Si Pub/Sub deja de estar disponible en una región en la que los editores están enviando mensajes, es posible que los mensajes de esa región no se entreguen hasta que el servicio se restaure por completo:
El mensaje se entrega finalmente (siempre que no haya pasado el periodo de conservación de mensajes), pero con un retraso equivalente a la duración de la interrupción. Ten en cuenta que, al igual que los suscriptores, los editores de Estados Unidos no se transfieren a otra región cuando falla el servicio. Este comportamiento ayuda a evitar que se produzcan fallos en cascada en varias regiones debido a un editor o un suscriptor defectuoso.
Conmutación por error y redundancia controladas por el cliente
Es posible que la semántica de conmutación por error predeterminada de Pub/Sub no garantice por completo que los mensajes siempre puedan fluir de los editores a los suscriptores si hay una interrupción en algún punto intermedio. Las interrupciones pueden producirse en varios sitios, como en tus clientes, en el servicio en el que se ejecutan tus editores o suscriptores, en la red o incluso, aunque sea raro, en Pub/Sub. Si necesitas que tus servicios sean resistentes a este tipo de interrupciones, debes implementar tus propias redundancias. Por lo general, estas redundancias incluyen el uso de varias instancias de clientes de editores y suscriptores, donde cada una usa un endpoint de ubicación diferente.
Puede que quieras que la aplicación sea resistente a dos ámbitos de impacto diferentes: zonal o regional. A continuación, se indican las opciones de configuración de cada una.
Resiliencia zonal
Pub/Sub tiene una replicación entre zonas integrada. No tienes que hacer nada especial para hacer frente a las interrupciones de una sola zona que afecten al propio servicio. Sin embargo, para que tus clientes o tu red puedan seguir funcionando en caso de interrupción, es mejor que ejecutes editores y suscriptores con capacidad suficiente en varias zonas de la región. Si una zona está inactiva, los clientes de la otra zona pueden recoger el tráfico y procesar los mensajes. Es una práctica recomendada no publicar los cambios en estos clientes simultáneamente para que, si se introduce un error, las otras zonas que no se hayan modificado puedan seguir procesando mensajes.
Resiliencia regional
Para que tu sistema sea resistente a los fallos regionales, configura redundancias adicionales en tus editores y suscriptores. Puedes ejecutar editores y suscriptores en varias regiones para hacer frente a la posibilidad de que se produzcan interrupciones en esos clientes o en la red.
Si quieres tener resiliencia ante posibles fallos de Pub/Sub en una región, debes tener un mecanismo de conmutación por error preparado para hacer frente a este tipo de interrupciones. Las estrategias posibles suponen un equilibrio entre la latencia de entrega de mensajes de extremo a extremo y el coste.
Para minimizar la latencia en caso de que el coste no sea un problema, la mejor estrategia es publicar y suscribirse simultáneamente en diferentes regiones. Primero, elige el número de regiones en las que quieres tener redundancia. A continuación, aunque no es estrictamente necesario, puedes configurar un tema y una suscripción para cada una de esas regiones.
Cada editor crea tantos clientes de editor como regiones haya (uno por región) y usa un endpoint de ubicación diferente para asegurarse de que los mensajes se dirijan a regiones distintas. Si se usan temas independientes, cada cliente editor debe publicar en el tema correspondiente de cada región. En cada mensaje, el editor llama a la función de publicación en cada cliente. Con las publicaciones redundantes, no es necesario volver a intentar publicar si falla alguna.
Del mismo modo, cada suscriptor crea ese número de clientes suscriptores (uno por región) y usa un endpoint de ubicación para conectarse a una región diferente. Si se usan suscripciones diferentes para cada región, cada cliente suscriptor debe usar la suscripción correspondiente. Ten en cuenta que las regiones usadas para los editores y los suscriptores no tienen por qué ser las mismas. Los suscriptores reciben mensajes en las tres suscripciones y los procesan.
Esta configuración tiene varias funciones y requisitos clave:
- Las interrupciones en una sola región no afectan al procesamiento de los mensajes que ya se hayan publicado ni a los que se publiquen durante la interrupción. Como los mensajes se publicaron en varias regiones, siguen estando disponibles en otras regiones en caso de que una de ellas no funcionara. Durante la interrupción, las llamadas de publicación fallan en la región afectada, pero se realizan correctamente en las demás.
- La latencia del procesamiento de mensajes no se ve afectada siempre que esté disponible alguna de las regiones por las que fluyen los mensajes.
- El procesamiento de mensajes debe ser idempotente. Como cada mensaje se va a enviar varias veces, el procesamiento de mensajes debe ser resistente a los duplicados. En caso de que se produzca una interrupción regional, es posible que algunos de esos duplicados lleguen mucho más tarde que la primera vez que se entregó el mensaje. Es probable que esos duplicados procedieran de otra región que no sufriera ninguna interrupción.
Si se ejecuta con este tipo de redundancia, se consigue la mayor resiliencia ante cualquier tipo de interrupción. Esta configuración es la más adecuada para los servicios internos de Google que dependen de Pub/Sub y requieren la máxima disponibilidad. Sin embargo, esta configuración conlleva el inconveniente de multiplicar el coste de envío de mensajes por el número de regiones utilizadas. También hay un coste adicional por el uso de la red entre regiones para los mensajes que tienen que moverse entre regiones.
Otro enfoque de la redundancia es conmutar por error solo cuando las solicitudes fallan o los mensajes no fluyen de los editores a los suscriptores como se espera. En este caso, tienes una región principal a la que diriges a tus editores y suscriptores a través de endpoints de ubicación. Al igual que antes, no tienen por qué ser de la misma región. También tienes una región de respaldo para editores y suscriptores que se usa cuando la región principal no está disponible.
Los editores solo publican en la región principal (a través del endpoint de ubicación) cuando sus solicitudes se envían correctamente. Cuando se determina que la región está inactiva, los editores empiezan a publicar en la región de respaldo. Para determinar que la región está inactiva y que se debe activar la conmutación por error, se pueden usar dos métodos. Se puede hacer mediante un proceso manual y la configuración se actualiza de forma dinámica en los editores. Los editores también pueden actualizar la configuración por su cuenta si la tasa de errores en las solicitudes de publicación es lo suficientemente alta.
Los suscriptores siempre deben conectarse a la región principal a través del endpoint de ubicación. Puedes decidir que el suscriptor pueda usar la región de respaldo con uno o varios de los siguientes activadores:
- Suscribirse siempre a la región de respaldo. En este caso, el suscriptor mantiene una conexión con la región principal y la de respaldo en todo momento. Se pueden usar las mismas regiones para la principal y la de reserva tanto para editores como para suscriptores. En ese caso, el suscriptor solo debe recibir mensajes a través de la región de copia de seguridad si el editor ha fallado.
- Detecta manualmente a los suscriptores y cámbialos a la región alternativa mediante una configuración. Si detectas una interrupción, puedes cambiar a la región de respaldo y, después, volver a la región principal cuando se haya solucionado.
- Conmutación por error en errores de suscriptor. Si las solicitudes de suscriptor devuelven errores, puedes usarlo como indicación de que debes cambiar a la región de respaldo. Ten en cuenta que las bibliotecas de cliente de Pub/Sub reintentan las solicitudes de extracción de streaming internamente en caso de errores transitorios, por lo que es posible que no puedas detectar que hay largos periodos de errores inesperados. Además, la tasa de errores de extracción de streaming debería ser del 100%, incluso durante el funcionamiento normal.
- Realiza una conmutación por error si el suscriptor pasa un tiempo inesperadamente largo sin recibir mensajes. Si los mensajes se publican de forma constante, los suscriptores siempre podrán recibirlos. Si pasa mucho tiempo sin recibir ningún mensaje, puede haber un problema del lado de la suscripción en Pub/Sub en la región principal. Esto se soluciona cambiando a la región de respaldo.
De las cuatro opciones, la primera es la ideal. Una conexión de suscriptor no cuesta dinero si no hay mensajes en ella. El único coste es el de la huella de la instancia adicional de la biblioteca de cliente de suscriptor, que puede ser insignificante. También debes tener en cuenta la cuota de número de conexiones StreamingPull abiertas por región.
La ventaja de este segundo modelo es que no hay un multiplicador en el coste de Pub/Sub, ya que los mensajes solo se publican una vez. Sin embargo, la contrapartida es que, en el caso de ciertos tipos de interrupciones, es posible que los mensajes publicados antes de que empezara la interrupción no estén disponibles hasta que se haya resuelto. Es posible que los mensajes almacenados en la región que no esté disponible no se puedan enviar a los suscriptores, independientemente de dónde se conecten. Los mensajes publicados durante la interrupción en la región de respaldo pueden estar disponibles. Además, puede haber un periodo de inactividad con un aumento de las tasas de error para los editores o los suscriptores. Esto depende del método que se utilice para detectar una interrupción y del tiempo que se tarde en conmutar por error a la región de respaldo.
Independientemente de la opción que elijas, ten en cuenta cómo puede interactuar con las funciones de Pub/Sub. Tanto la entrega ordenada como la entrega exactamente una vez ofrecen sus garantías en una región. Por ejemplo, si usas la técnica de redundancia de conmutación por error, el orden de entrega de los mensajes solo se garantiza para los mensajes publicados en la misma región. El suscriptor podría recibir mensajes publicados en la región de respaldo antes que los mensajes publicados en la región principal, aunque los mensajes se hayan publicado primero en la región principal.
Ajustar editores
Independientemente de la opción de conmutación por error que elijas, hay algunos pasos de ajuste adicionales que debes seguir en los propios editores. Ajustar el comportamiento de los editores asegura un rendimiento óptimo con cargas elevadas. Enviar mensajes por lotes es una forma de compensar la latencia para reducir los costes, pero no es un problema de fiabilidad y, por lo tanto, no se trata en este artículo. En su lugar, céntrate en otros parámetros que sean útiles para mejorar la fiabilidad, como los ajustes de reintento y los ajustes de control de flujo.
Las publicaciones pueden fallar por diferentes motivos, incluidos los transitorios, como la falta de disponibilidad de la red, o los que requieren la intervención del usuario, como los cambios de permisos. La biblioteca de cliente de Pub/Sub vuelve a intentar realizar las operaciones que han fallado debido a errores transitorios usando los parámetros especificados en los ajustes de reintento. Estos ajustes controlan el comportamiento de la retirada exponencial en los reintentos de las llamadas a procedimientos remotos de publicación que fallan por motivos transitorios. Aunque los ajustes predeterminados suelen funcionar bien en la mayoría de los casos, hay situaciones en las que puede que quieras modificar estos valores.
Las dos propiedades que probablemente quieras ajustar son el tiempo de espera inicial de la RPC y el tiempo de espera total. El tiempo de espera inicial de RPC es el tiempo que se le da a la primera RPC de publicación para completarse. Si falla alguna RPC o se agota el tiempo de espera, se intenta otra con un tiempo de espera más largo hasta que se supera el número total de solicitudes o el tiempo de espera total.
El tiempo de espera inicial se puede ajustar si su editor tiene limitaciones de red o está lejos del centro de datos más cercano que ejecuta Pub/Sub. Google Cloud Las restricciones de red pueden ser limitaciones en el rendimiento de la máquina en la que se ejecuta el editor o pueden ser el resultado de otros servicios que se ejecutan en la misma máquina y que requieren mucha red. Si el tiempo de espera es demasiado corto, es posible que las llamadas a procedimientos remotos iniciales fallen repetidamente, lo que provocará que se necesiten más intentos (con tiempos de espera más largos) para publicar correctamente. La necesidad repetida de reintentos aumenta la latencia de publicación. En esta situación, aumentar el tiempo de espera inicial podría acelerar las publicaciones.
Si la conexión de red no es fiable, puede aumentar el tiempo de espera total y el tiempo de espera inicial. Un tiempo de espera total mayor da más tiempo a la RPC de publicación para completarse correctamente. Si las RPC de publicación fallan de forma constante con errores de tiempo de espera agotado, plantéate ajustar estos valores.
Si se producen errores continuos por haber superado el plazo de publicación, puede que sea necesario ajustar el control de flujo del editor. Estos ajustes le permiten asegurarse de que sus editores sean resistentes a los picos de tráfico entrante que generan más mensajes para enviar a Pub/Sub. Un gran aumento de las solicitudes salientes podría sobrecargar la CPU, la memoria o la capacidad de red del editor. Cuando la publicación está sobrecargada, no puede procesar las solicitudes ni las respuestas de publicación antes de que se agote el tiempo de espera. Esto provoca que se envíen aún más solicitudes de publicación y, en última instancia, que se alcance el tiempo de espera total. El control de flujo del editor limita el número de mensajes o bytes que pueden estar pendientes sin una respuesta de la solicitud de publicación. Limitar el número de solicitudes de esta forma mantiene la utilización de recursos en un nivel gestionable, incluso durante los picos. En función de cómo opere tu editor, puedes permitir que las llamadas a procedimiento remoto de publicación posteriores esperen a que haya capacidad disponible permitiendo que la publicación bloquee otras solicitudes. También puedes rechazar las llamadas a tu servicio haciendo que el control de flujo devuelva un error cuando se alcance la capacidad. Puedes configurar cómo responde la biblioteca de cliente del editor con el comportamiento de límite superado.
Suscriptores de promoción
También puede ser necesario ajustar los parámetros de los suscriptores para que funcionen de forma fiable. Al igual que los editores, puedes ajustar la configuración de control de flujo de los suscriptores para asegurarte de que no se saturen. La biblioteca de cliente de suscriptor usa la extracción de streaming, en la que el cliente abre un flujo persistente al servidor y el servidor envía mensajes a medida que están disponibles. Si se produce un gran aumento en los mensajes publicados, es posible que el suscriptor reciba más mensajes de los que puede procesar. Con el control de flujo, se limita el número de mensajes pendientes de confirmación que se envían al cliente a la vez. De esta forma, se reduce el número de mensajes que se gestionan simultáneamente y se distribuye su procesamiento a lo largo de un periodo más largo. Repartir la carga permite a los suscriptores no superar los límites de recursos que afectan al procesamiento de mensajes, lo que puede provocar un efecto en cascada que derive en la imposibilidad de procesar ningún mensaje.
El control de flujo por sí solo es suficiente si solo esperas picos en la cantidad de datos que se van a procesar. Si el tráfico aumenta con el tiempo debido a un mayor uso, el control de flujo protege a los suscriptores. Sin embargo, puede provocar una acumulación de trabajo pendiente que impida que los mensajes se entreguen antes de que finalice el periodo de conservación. En estos casos, también puedes configurar el escalado automático para aumentar el número de suscriptores en respuesta al creciente número de mensajes sin confirmar. La forma de configurarlo depende de la plataforma de computación que utilices para tus suscriptores. Por ejemplo, el escalador automático de Compute Engine te permite escalar en función de métricas como el número de mensajes no entregados. Si usas tanto el ajuste de escala automático como el control de flujo, puedes asegurarte de que tus suscriptores sean resistentes a otros picos a corto plazo en el rendimiento de los mensajes y al crecimiento a largo plazo que requiera más potencia de cálculo. Sigue las prácticas recomendadas para usar las métricas de Pub/Sub como señal de escalado.
Usa las funciones de captura y búsqueda para realizar implementaciones seguras
La pérdida de mensajes suele ser un evento catastrófico. Pub/Sub ofrece una entrega al menos una vez para todos los mensajes publicados. Sin embargo, el procesamiento correcto de estos mensajes depende del comportamiento del suscriptor. Si los mensajes se confirman correctamente, Pub/Sub no los vuelve a enviar. Por lo tanto, si se introduce un error en el nuevo código de suscriptor que implementes y este confirma los mensajes sin haberlos procesado correctamente, se podrían perder mensajes debido al suscriptor. Pub/Sub ofrece la función snapshot y seek, que puede ayudarte a asegurarte de que procesas todos los mensajes correctamente, incluso si hay errores en los suscriptores.
El patrón de cada implementación de suscriptor debe ser el siguiente:
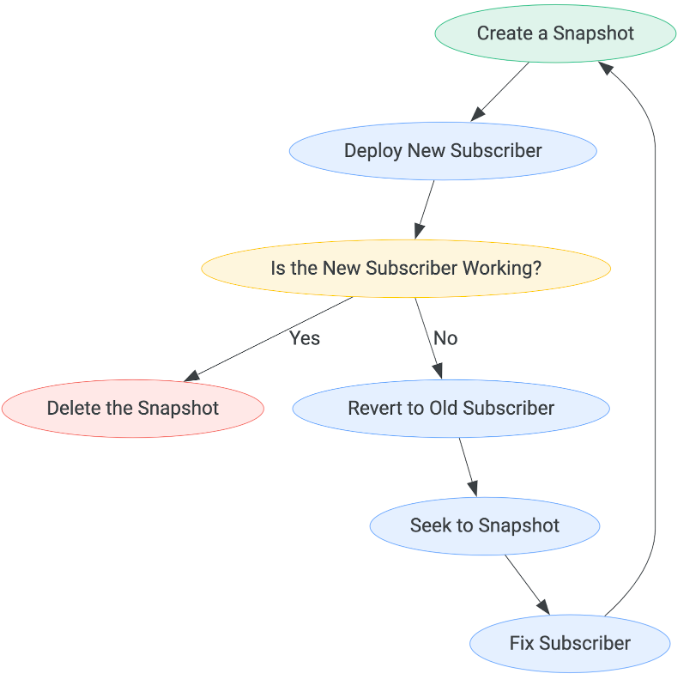
El tiempo que debes esperar antes de determinar si el nuevo suscriptor funciona puede variar en función de tu caso práctico. La única forma de salir del flujo de pasos es cuando se considera que un suscriptor funciona, momento en el que se puede eliminar la instantánea.
El uso de las funciones de creación de copias y de búsqueda no pretende sustituir las prácticas recomendadas para ejecutar software por primera vez en un entorno que no sea de producción y para desplegarlo gradualmente en producción. Proporcionan un nivel adicional de protección para asegurar el procesamiento fiable de los datos. La contrapartida es que, al buscar la instantánea, se pueden duplicar los mensajes que tu suscriptor haya procesado correctamente. Sin embargo, dado que Pub/Sub tiene una semántica de entrega al menos una vez de forma predeterminada, tus suscriptores ya son resistentes a la retransmisión de mensajes.