Otimize uma app Go
Neste tutorial, implementa uma aplicação Go intencionalmente ineficiente que está configurada para recolher dados de perfil. Usa a interface do criador de perfis para ver os dados do perfil e identificar potenciais otimizações. Em seguida, modifica a aplicação, implementa-a e avalia o efeito da modificação.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Para abrir o Cloud Shell, na Google Cloud barra de ferramentas da consola, clique em
Ativar Cloud Shell:

Após alguns momentos, é aberta uma sessão do Cloud Shell na Google Cloud consola:

No Cloud Shell, execute os seguintes comandos:
git clone https://github.com/GoogleCloudPlatform/golang-samples.git cd golang-samples/profiler/shakesappExecute a aplicação com a versão definida como
1e o número de rounds definido como 15:go run . -version 1 -num_rounds 15Após um ou dois minutos, são apresentados os dados do perfil. Os dados do perfil são semelhantes ao seguinte exemplo:
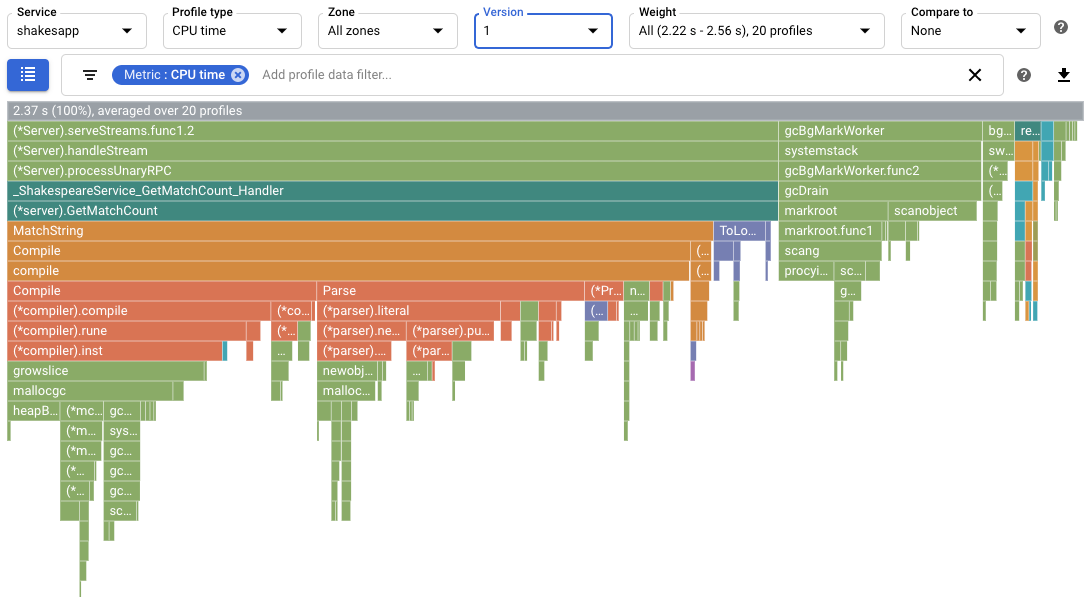
Na captura de ecrã, repare que o Tipo de perfil está definido como
CPU time. Isto indica que os dados de utilização da CPU são apresentados no gráfico de chamas.A saída de exemplo impressa no Cloud Shell é apresentada abaixo:
$ go run . -version 1 -num_rounds 15 2020/08/27 17:27:34 Simulating client requests, round 1 2020/08/27 17:27:34 Stackdriver Profiler Go Agent version: 20200618 2020/08/27 17:27:34 profiler has started 2020/08/27 17:27:34 creating a new profile via profiler service 2020/08/27 17:27:51 Simulated 20 requests in 17.3s, rate of 1.156069 reqs / sec 2020/08/27 17:27:51 Simulating client requests, round 2 2020/08/27 17:28:10 Simulated 20 requests in 19.02s, rate of 1.051525 reqs / sec 2020/08/27 17:28:10 Simulating client requests, round 3 2020/08/27 17:28:29 Simulated 20 requests in 18.71s, rate of 1.068947 reqs / sec ... 2020/08/27 17:44:32 Simulating client requests, round 14 2020/08/27 17:46:04 Simulated 20 requests in 1m32.23s, rate of 0.216849 reqs / sec 2020/08/27 17:46:04 Simulating client requests, round 15 2020/08/27 17:47:52 Simulated 20 requests in 1m48.03s, rate of 0.185134 reqs / sec
O resultado do Cloud Shell apresenta o tempo decorrido para cada iteração e a taxa de pedidos média. Quando a aplicação é iniciada, a entrada "Simulated 20 requests in 17.3s, rate of 1.156069 reqs / sec" indica que o servidor está a executar cerca de 1 pedido por segundo. Na última ronda, a entrada "Simulated 20 requests in 1m48.03s, rate of 0.185134 reqs / sec" indica que o servidor está a executar cerca de 1 pedido a cada 5 segundos.
- Para ver a tabela, clique em list Focar lista de funções.
- Ordene a tabela por Total. A coluna com a etiqueta
Total mostra a utilização do tempo da CPU de uma função e dos respetivos elementos subordinados.
Neste exemplo,
GetMatchCounté a primeira funçãoshakesapp/server.goapresentada. Essa função usou 1,7 s do tempo total da CPU, ou 72% do tempo total da CPU das aplicações. Sabe-se que esta função está a processar os pedidos gRPC.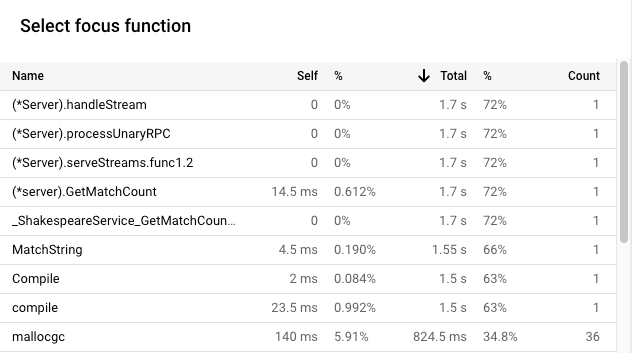
O gráfico de rastreio em pilhas sobrepostas mostra que a função
shakesapp/server.goGetMatchCountchamaMatchString, que, por sua vez, está a gastar a maior parte do seu tempo a chamarCompile:
Execute a aplicação com a versão da aplicação definida como
2:go run . -version 2 -num_rounds 40Uma secção posterior mostra que, com a otimização, o tempo necessário para executar uma única ronda é muito inferior ao da aplicação não modificada. Para garantir que a aplicação é executada durante tempo suficiente para recolher e carregar perfis, o número de ciclos é aumentado.
Aguarde pela conclusão da aplicação e, em seguida, veja os dados do perfil para esta versão da aplicação:
- Clique em AGORA para carregar os dados do perfil mais recentes. Para mais informações, consulte o artigo Intervalo de tempo.
- No menu Versão, selecione 2.
O número de pedidos por segundo aumentou de menos de 1 por segundo para 5,8 por segundo.
O tempo da CPU por pedido, calculado dividindo a utilização da CPU pelo número de pedidos por segundo, diminuiu de 23,7% para 13,4%.
Tenha em atenção que o tempo da CPU por pedido diminuiu, apesar de a utilização do tempo da CPU ter aumentado de 2,37 segundos, o que corresponde a 23,7% de utilização de um único núcleo da CPU, para 7,8 segundos, ou 78% de um núcleo da CPU.
Os perfis de memória mostram a quantidade de memória atribuída na memória do programa no instante em que o perfil é recolhido.
Os perfis de memória atribuída mostram a quantidade total de memória que foi atribuída na memória dinâmica do programa durante o intervalo em que o perfil foi recolhido. Ao dividir estes valores por 10 segundos, o intervalo de recolha de perfis, pode interpretá-los como taxas de atribuição.
Execute a aplicação com a versão da aplicação definida como
3e ative a recolha de perfis de memória dinâmica e memória dinâmica alocada.go run . -version 3 -num_rounds 40 -heap -heap_allocAguarde pela conclusão da aplicação e, em seguida, veja os dados do perfil para esta versão da aplicação:
- Clique em AGORA para carregar os dados do perfil mais recentes.
- No menu Versão, selecione 3.
- No menu Tipo de Profiler, selecione Heap alocado.
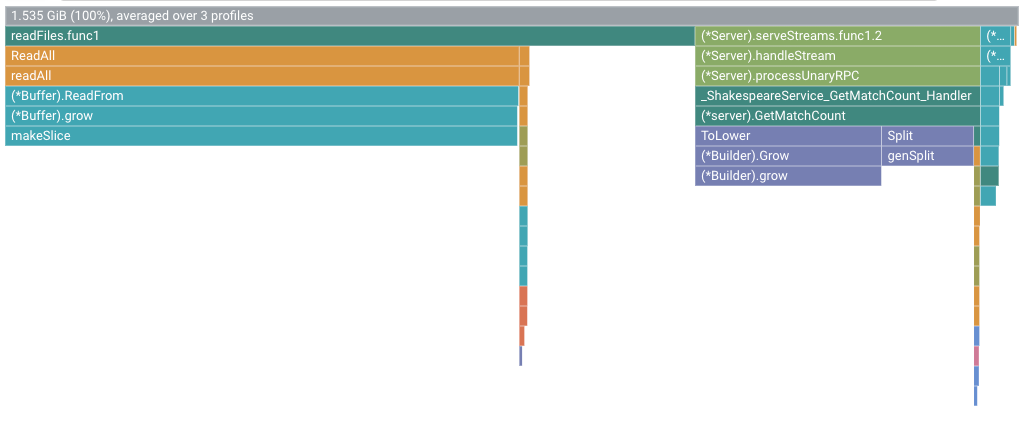
Por exemplo, o gráfico de chamas é apresentado da seguinte forma:
- Ignorar a otimização se a utilização do tempo da CPU for inferior a 5%.
- Otimize se a utilização do tempo da CPU for, pelo menos, de 25%.
Execute a aplicação com a versão da aplicação definida como
4:go run . -version 4 -num_rounds 60 -heap -heap_allocAguarde pela conclusão da aplicação e, em seguida, veja os dados do perfil para esta versão da aplicação:
- Clique em AGORA para carregar os dados do perfil mais recentes.
- No menu Versão, selecione 4.
- No menu Tipo de Profiler, selecione Heap alocado.
Para quantificar o efeito da alteração de
readFilesna taxa de atribuição de memória, compare os perfis de memória atribuída da versão 4 com os recolhidos para a versão 3: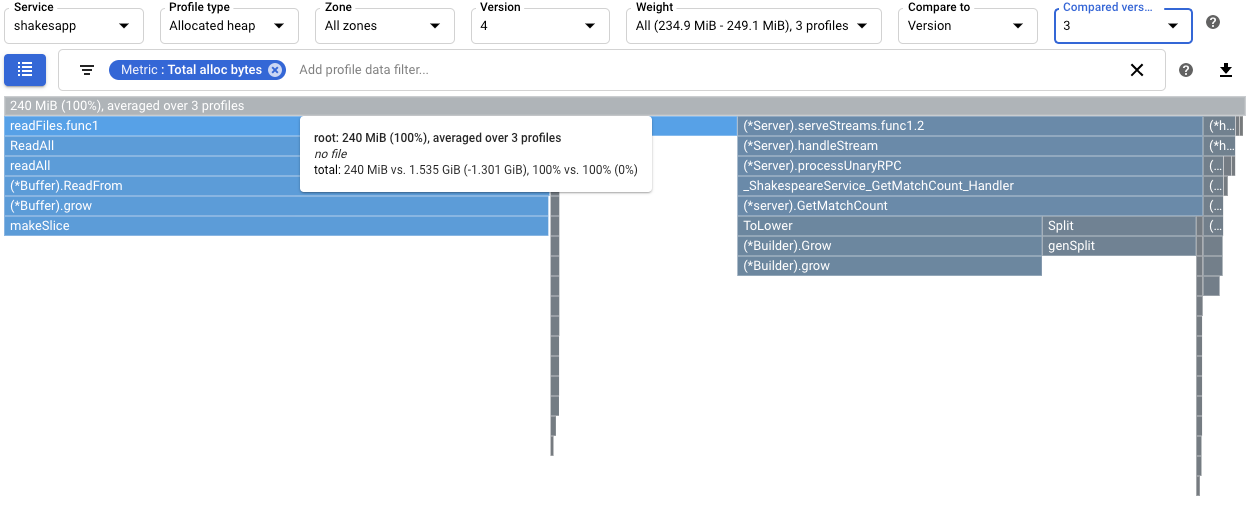
A dica de ferramenta da frame raiz mostra que, com a versão 4, a quantidade média de memória alocada durante a recolha de perfis diminuiu 1,301 GiB, em comparação com a versão 3. A sugestão de
readFiles.func1mostra uma diminuição de 1045 GiB:
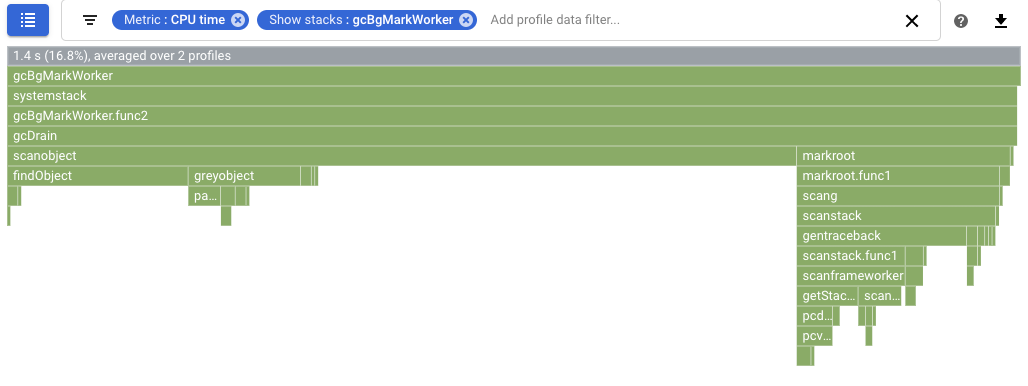
Para quantificar o efeito na recolha de lixo, configure uma comparação dos perfis de tempo de CPU. Na captura de ecrã seguinte, é aplicado um filtro para mostrar as pilhas do coletor de lixo do Go
runtime.gcBgMarkWorker.*. A captura de ecrã mostra que a utilização da CPU para a recolha de lixo foi reduzida de 16,8% para 4,97%.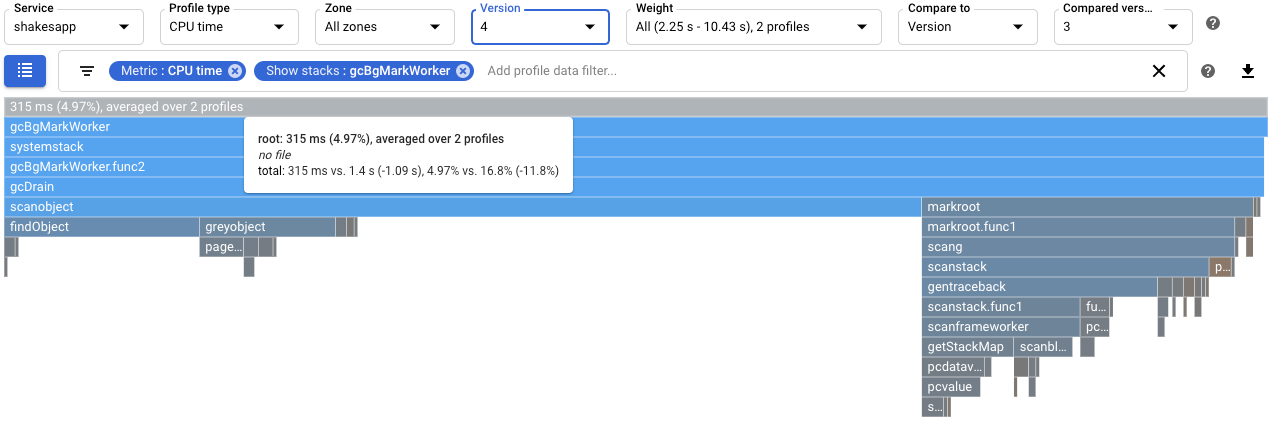
Para determinar se existe um impacto da alteração no número de pedidos por segundo processados pela aplicação, veja o resultado no Cloud Shell. Neste exemplo, a versão 4 conclui até 15 pedidos por segundo, o que é substancialmente superior aos 5,8 pedidos por segundo da versão 3:
$ go run . -version 4 -num_rounds 60 -heap -heap_alloc 2020/08/27 21:51:42 Simulating client requests, round 1 2020/08/27 21:51:42 Stackdriver Profiler Go Agent version: 20200618 2020/08/27 21:51:42 profiler has started 2020/08/27 21:51:42 creating a new profile via profiler service 2020/08/27 21:51:44 Simulated 20 requests in 1.47s, rate of 13.605442 reqs / sec 2020/08/27 21:51:44 Simulating client requests, round 2 2020/08/27 21:51:45 Simulated 20 requests in 1.3s, rate of 15.384615 reqs / sec 2020/08/27 21:51:45 Simulating client requests, round 3 2020/08/27 21:51:46 Simulated 20 requests in 1.31s, rate of 15.267176 reqs / sec ...
O aumento nas consultas por segundo publicadas pela aplicação pode dever-se a menos tempo gasto na recolha de lixo.
Pode compreender melhor o efeito da modificação a
readFilesao ver os perfis de memória. Uma comparação dos perfis de memória dinâmica da versão 4 com os da versão 3 mostra que a utilização de memória dinâmica diminuiu de 70,95 MiB para 18,47 MiB: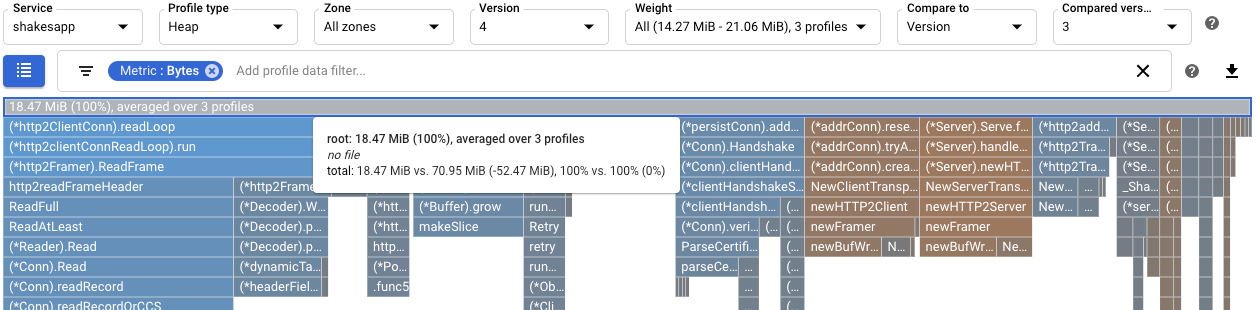
Ao usar perfis de tempo da CPU, foi identificada uma função com utilização intensiva da CPU. Após aplicar uma alteração simples, a taxa de pedidos do servidor aumentou para 5,8 por segundo, em comparação com cerca de 1 por segundo.
Ao usar perfis de memória dinâmica alocada, a função
shakesapp/server.goreadFilesfoi identificada como tendo uma taxa de alocação elevada. Após a otimização dereadFiles, a taxa de pedidos do servidor aumentou para 15 pedidos por segundo e a quantidade média de memória atribuída durante a recolha de perfis de 10 segundos diminuiu 1,301 GiB.Para obter informações sobre como os perfis são recolhidos e enviados para o seu Google Cloud projeto, consulte Recolha de perfis.
Leia os nossos recursos sobre DevOps e explore o nosso programa de investigação.
- Criação de perfis de aplicações Go
- Criar perfis de aplicações Java
- Criação de perfis de aplicações Node.js
- Criar perfis de aplicações Python
- Criação de perfis de aplicações em execução fora Google Cloud
Aplicação de exemplo
O objetivo principal é maximizar o número de consultas por segundo que o servidor pode processar. Um objetivo secundário é reduzir a utilização de memória eliminando atribuições de memória desnecessárias.
O servidor, através de uma framework gRPC, recebe uma palavra ou uma expressão e, em seguida, devolve o número de vezes que a palavra ou a expressão aparece nas obras de Shakespeare.
O número médio de consultas por segundo que o servidor consegue processar é determinado através de testes de carga do servidor. Para cada ronda de testes, é chamado um simulador de cliente e são dadas instruções para emitir 20 consultas sequenciais. Quando uma ronda é concluída, são apresentados o número de consultas enviadas pelo simulador de cliente, o tempo decorrido e o número médio de consultas por segundo.
O código do servidor é intencionalmente ineficiente.
Executar a aplicação de exemplo
Transfira e execute a aplicação de exemplo:
Usar perfis de tempo da CPU para maximizar as consultas por segundo
Uma abordagem para maximizar o número de consultas por segundo é identificar métodos com utilização intensiva da CPU e otimizar as respetivas implementações. Nesta secção, usa perfis de tempo da CPU para identificar um método intensivo da CPU no servidor.
Identificar a utilização do tempo da CPU
O frame raiz do gráfico de chamas indica o tempo total da CPU usado pela aplicação durante o intervalo de recolha de 10 segundos:
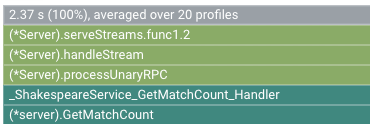
Neste exemplo, o serviço usado é 2.37 s. Quando o sistema é executado num único núcleo, uma utilização do tempo da CPU de 2,37 segundos corresponde a uma utilização de 23,7% desse núcleo. Para mais informações, consulte o artigo
Tipos de criação de perfis disponíveis.
Modificar a aplicação
Passo 1: que função requer muito tempo de CPU?
Uma forma de identificar o código que pode ter de ser otimizado é ver a tabela de funções e identificar funções gananciosas:
A avaliar a alteração
Para avaliar a alteração, faça o seguinte:
Por exemplo, o gráfico de chamas é apresentado da seguinte forma:
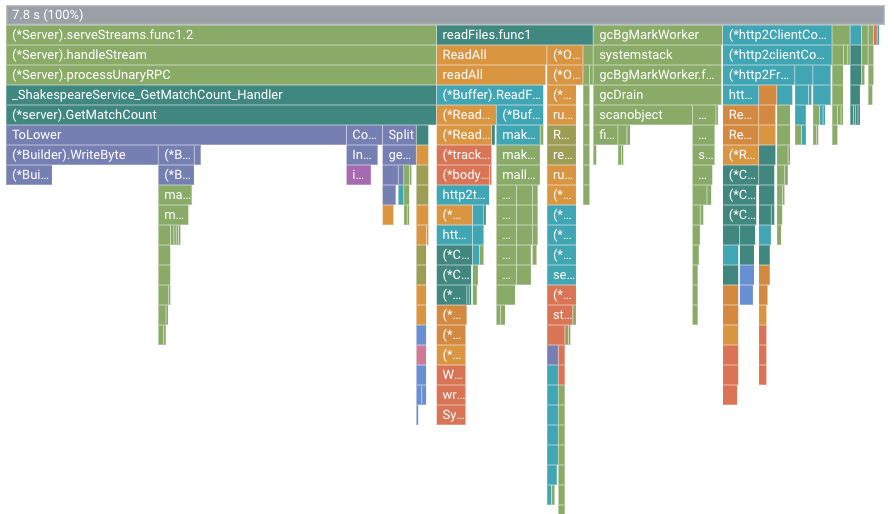
Nesta figura, o frame raiz mostra um valor de 7.8 s. Como resultado da alteração da função de correspondência de strings, o tempo de CPU usado pela aplicação aumentou de 2,37 segundos para 7,8 segundos, ou a aplicação passou a usar 23,7% de um núcleo da CPU para usar 78% de um núcleo da CPU.
A largura do frame é uma medida proporcional da utilização do tempo da CPU. Neste exemplo, a largura da moldura para GetMatchCount indica que a função usa cerca de 49% de todo o tempo da CPU usado pela aplicação.
No gráfico de chamas original, este mesmo frame representava cerca de 72% da largura do gráfico.
Para ver a utilização exata do tempo da CPU, pode usar a sugestão de ferramenta de frames ou a lista de funções de foco:
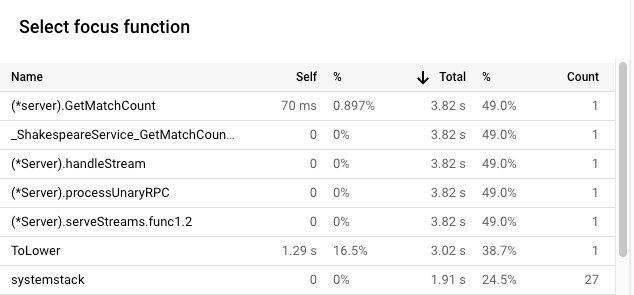
O resultado no Cloud Shell mostra que a versão modificada está a concluir cerca de 5,8 pedidos por segundo:
$ go run . -version 2 -num_rounds 40 2020/08/27 18:21:40 Simulating client requests, round 1 2020/08/27 18:21:40 Stackdriver Profiler Go Agent version: 20200618 2020/08/27 18:21:40 profiler has started 2020/08/27 18:21:40 creating a new profile via profiler service 2020/08/27 18:21:44 Simulated 20 requests in 3.67s, rate of 5.449591 reqs / sec 2020/08/27 18:21:44 Simulating client requests, round 2 2020/08/27 18:21:47 Simulated 20 requests in 3.72s, rate of 5.376344 reqs / sec 2020/08/27 18:21:47 Simulating client requests, round 3 2020/08/27 18:21:51 Simulated 20 requests in 3.58s, rate of 5.586592 reqs / sec ... 2020/08/27 18:23:51 Simulating client requests, round 39 2020/08/27 18:23:54 Simulated 20 requests in 3.46s, rate of 5.780347 reqs / sec 2020/08/27 18:23:54 Simulating client requests, round 40 2020/08/27 18:23:58 Simulated 20 requests in 3.4s, rate of 5.882353 reqs / sec
A pequena alteração à aplicação teve dois efeitos diferentes:
Usar perfis de memória atribuídos para melhorar a utilização de recursos
Esta secção ilustra como pode usar os perfis de memória dinâmica e de memória dinâmica alocada para identificar um método com utilização intensiva de alocações na aplicação:
Ativar a recolha de perfis de memória
Identificar a taxa de atribuição de memória
O frame raiz apresenta a quantidade total de memória dinâmica que foi alocada durante os 10 segundos em que um perfil foi recolhido, calculada com base na média de todos os perfis. Neste exemplo, o frame raiz mostra que, em média, foram alocados 1,535 GiB de memória.
Modificar a aplicação
Passo 1: vale a pena minimizar a taxa de atribuição de memória?
O tempo de utilização da CPU da função de recolha de lixo em segundo plano do Go,
runtime.gcBgMarkWorker.*, pode ser usado para determinar se vale a pena otimizar uma aplicação para reduzir os custos de recolha de lixo:
Para este exemplo, a utilização do tempo de CPU do coletor de lixo em segundo plano é de 16,8%. Este valor é suficientemente elevado para valer a pena tentar otimizar em função de shakesapp/server.go:
Passo 2: que função atribui muita memória?
O ficheiro shakesapp/server.go contém duas funções que podem ser alvos de otimização:
GetMatchCount e readFiles. Para determinar
a taxa de atribuição de memória para estas funções, defina o
Tipo de perfil como Heap atribuído e, em seguida, use a
list
Lista de funções de foco.
Neste exemplo, a alocação total de memória dinâmica para readFiles.func1
durante a recolha do perfil de 10 segundos é, em média, de 1,045 GiB ou 68% da
memória total alocada. A atribuição de memória dinâmica automática durante a recolha de perfis de 10 segundos é de 255,4 MiB:
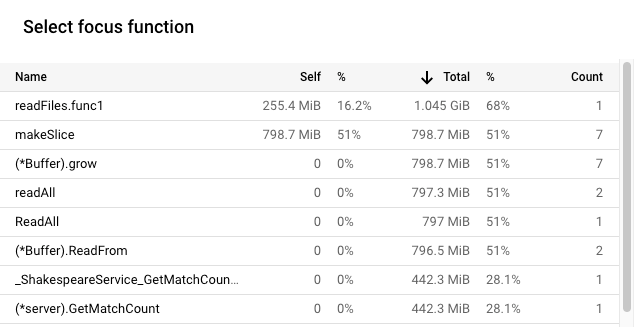
Neste exemplo, o método Go makeSlice alocou 798,7 MiB
durante a recolha do perfil de 10 segundos, em média.
A forma mais simples de reduzir estas atribuições
é reduzir as chamadas para makeSlice. A função
readFiles chama
makeSlice através de um método de biblioteca.
O resultado desta análise sugere que pode ser possível reduzir a taxa de atribuições de memória dinâmica otimizando readFiles.
A avaliar a alteração
Para avaliar a alteração, faça o seguinte:
Resumo
Neste início rápido, foram usados perfis de tempo de CPU e de memória dinâmica alocada para identificar potenciais otimizações a uma aplicação. Os objetivos eram maximizar o número de pedidos por segundo e eliminar as atribuições desnecessárias.