Para treinar seu modelo personalizado, forneça amostras representativas dos tipos de documentos que serão analisados, rotulados da maneira como o AutoML Natural Language precisa rotular documentos semelhantes. A qualidade dos dados de treinamento tem forte impacto sobre a eficácia do modelo criado e, por consequência, sobre a qualidade das predições retornadas pelo modelo.
Como coletar e rotular documentos de treinamento
A primeira etapa é coletar um conjunto diversificado de documentos de treinamento que reflita o intervalo de documentos que você quer processar com o modelo personalizado. As etapas de preparação para documentos de treinamento variam de acordo com o treinamento de um modelo para classificação, extração de entidade ou análise de sentimento.
Extração de entidade
Para treinar um modelo de extração de entidades, forneça amostras representativas do tipo de conteúdo que você quer analisar, anotado com rótulos que identificam os tipos de entidades que você quer que o AutoML Natural Language identifique.
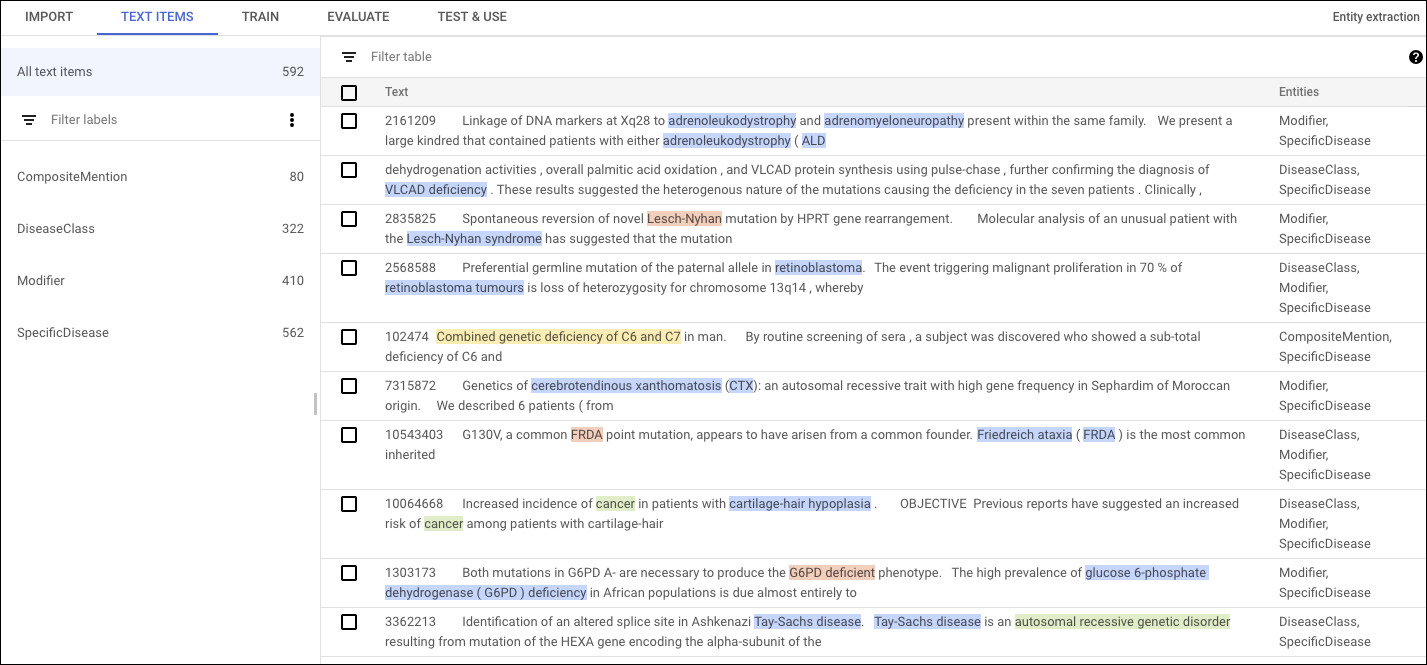
Você fornece entre 50 e 100 mil documentos para treinar seu modelo personalizado. Use entre um e 100 rótulos exclusivos para anotar as entidades que você quer que o modelo aprenda a extrair. Cada anotação é um período de texto e um rótulo associado. Os nomes dos rótulos podem ter entre dois e 30 caracteres e podem ser usados para anotar entre uma e dez palavras. Recomendamos o uso de cada rótulo pelo menos 200 vezes em seu conjunto de dados de treinamento.
Se você estiver anotando um tipo de documento estruturado ou semiestruturado, como faturas ou contratos, o AutoML Natural Language poderá considerar a posição de uma anotação na página como um fator que contribua para o rótulo adequado. Por exemplo, um contrato imobiliário tem uma data de aceitação e uma data de encerramento, e o AutoML Natural Language pode aprender a diferenciar as entidades com base na posição espacial da anotação.
Como formatar documentos de treinamento
Você faz upload dos dados de treinamento para o AutoML Natural Language como JSONL (em inglês) que contêm os documentos de amostra. Cada linha no arquivo é um único documento de treinamento, especificado de uma destas duas maneiras:
- O conteúdo completo do documento, entre dez e dez mil bytes de comprimento, codificado em UTF-8
- O URI de um arquivo PDF ou TIFF de um bucket do Cloud Storage associado ao seu projeto
A consideração da posição espacial está disponível apenas para documentos de treinamento em formato PDF.
É possível anotar os documentos de texto de três maneiras:
- Anote os arquivos JSONL diretamente antes de fazer upload deles.
- Adicione anotações na interface do usuário do AutoML Natural Language após o upload de documentos não anotados.
- Use o Serviço de rotulagem de dados do AI Platform para solicitar o serviço de rotuladores profissionais.
É possível combinar as duas primeiras opções fazendo upload de arquivos JSONL rotulados e modificando-os na UI.
Só é possível fazer anotações em arquivos PDF usando a interface do usuário do AutoML Natural Language.
Documentos JSONL
Para ajudá-lo a criar arquivos de treinamento em JSONL, o AutoML Natural Language oferece um script Python que converte arquivos de texto simples em arquivos JSONL formatados adequadamente. Veja os detalhes nos comentários do script.
Cada documento no arquivo JSONL tem um destes formatos:
Cada documento precisa ser uma linha no arquivo JSONL. O exemplo abaixo inclui quebras de linha para facilitar a leitura. Você precisa removê-las no arquivo JSONL. Veja mais informações em http://jsonlines.org/ (em inglês).
Para documentos não anotados:
{
"text_snippet":
{"content": string}
}
Para documentos anotados:
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
Cada elemento text_extraction identifica uma anotação dentro de text_snippet.content. Indica a posição do texto anotado especificando o número de caracteres a partir do início de text_snippet.content até o começo (start_offset) e o término (end_offset) do texto. display_name é o rótulo da entidade.
Tanto start_offset quanto end_offset são desvios de caracteres em vez de desvios de bytes. O caractere em end_offset não é incluído no segmento de texto. Consulte TextSegment para mais detalhes. Os elementos text_extraction são opcionais. Omita-os se planeja anotar o documento usando a interface do usuário do AutoML Natural Language. Cada anotação pode cobrir até dez tokens (palavras). Elas não podem se sobrepor. O start_offset de uma anotação não pode estar entre start_offset e end_offset de uma anotação no mesmo documento.
Por exemplo, este documento de treinamento de exemplo identifica as doenças específicas mencionadas em um resumo do corpus do NCBI (em inglês).
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
Um arquivo JSONL pode conter vários documentos de treinamento com essa estrutura, um em cada linha do arquivo.
Documentos PDF ou TIFF
Para fazer upload de um arquivo PDF ou TIFF como documento, coloque o caminho do arquivo dentro de um elemento document do JSONL:
Cada documento precisa ser uma linha no arquivo JSONL. O exemplo abaixo inclui quebras de linha para facilitar a leitura. Você precisa removê-las no arquivo JSONL. Veja mais informações em http://jsonlines.org/ (em inglês).
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
O valor do elemento input_uris é o caminho para um arquivo PDF ou TIFF em um bucket do Cloud Storage associado ao seu projeto. O tamanho máximo do arquivo PDF ou TIFF é de 2 MB.
Como importar documentos de treinamento
Você importa dados de treinamento para o AutoML Natural Language usando um arquivo CSV que lista os documentos e, opcionalmente, inclui seus rótulos de categoria ou valores de sentimento. O AutoML Natural Language cria um conjunto de dados com base nos documentos listados.
Dados de treinamento x avaliação
O AutoML Natural Language divide seus documentos de treinamento em três conjuntos para treinar um modelo: um conjunto de treinamento, um conjunto de validação e um conjunto de teste.
O AutoML Natural Language usa o conjunto de treinamento para criar o modelo. O modelo testa vários algoritmos e parâmetros enquanto procura padrões nos dados de treinamento. Conforme o modelo identifica padrões, ele usa o conjunto de validação para testar os algoritmos e padrões. O AutoML Natural Language escolhe os algoritmos e padrões de melhor desempenho daqueles identificados durante a etapa de treinamento.
Depois de identificar os algoritmos e padrões de melhor desempenho, o AutoML Natural Language os aplica ao conjunto de teste para testar a taxa de erros, a qualidade e a acurácia.
Por padrão, o AutoML Natural Language divide seus dados de treinamento aleatoriamente em três conjuntos:
- 80% dos documentos são utilizados para treinamento
- 10% dos documentos são usados para validação (ajuste de hiperparâmetros e/ou decidir quando parar de treinar)
- 10% dos documentos são reservados para testes (não usados durante o treinamento)
Se quiser especificar a que conjunto cada documento nos seus dados de treinamento deve pertencer, atribua explicitamente documentos a conjuntos no arquivo CSV, conforme descrito na próxima seção.
Como criar um arquivo CSV de importação
Depois de coletar todos os documentos de treinamento, crie um arquivo CSV que liste todos eles. O arquivo CSV pode ter qualquer nome de arquivo, precisa ser codificado em UTF-8 e terminar com uma extensão .csv. Ele precisa ser armazenado no bucket do Cloud Storage associado ao seu projeto.
O arquivo CSV tem uma linha para cada documento de treinamento, com estas colunas em cada linha:
A que conjunto atribuir o conteúdo da linha. Essa coluna é opcional e pode ter um dos seguintes valores:
TRAIN: use o document para treinar o modelo.VALIDATION: use o document para validar os resultados que o modelo retorna durante o treinamento.TEST: use o document para verificar os resultados do modelo após ele ter sido treinado.
Se você incluir valores nessa coluna para especificar os conjuntos, recomendamos que identifique pelo menos 5% dos seus dados para cada categoria. O uso de menos de 5% dos dados para treinamento, validação ou teste pode produzir resultados inesperados e modelos ineficazes.
Se você não incluir valores nessa coluna, inicie cada linha com uma vírgula para indicar a primeira coluna vazia. O AutoML Natural Language divide automaticamente seus documentos em três conjuntos, usando cerca de 80% dos dados para treinamento, 10% para validação e 10% para teste (até dez mil pares para validação e teste).
O conteúdo a ser categorizado. Esta coluna contém o URI do Cloud Storage do documento. Esses URIs diferenciam maiúsculas de minúsculas.
Para classificação e análise de sentimento, o documento pode ser um arquivo de texto, PDF, TIFF ou ZIP. Para extração de entidade, é um arquivo JSONL.
Para classificação e análise de sentimentos, o valor nesta coluna pode ser citado em texto em linha, em vez de um URI do Cloud Storage.
Para conjuntos de dados de classificação, inclua uma lista separada por vírgulas de rótulos que identificam como o documento é categorizado. Os rótulos precisam começar com uma letra e conter apenas letras, números e sublinhado. É possível incluir até 20 marcadores para cada documento.
Para conjuntos de dados de análise de sentimento, inclua um número inteiro indicando o valor de sentimento do conteúdo. O valor de sentimento varia de 0 (fortemente negativo) a um valor máximo de 10 (altamente positivo).
Por exemplo, o arquivo CSV de um conjunto de dados de classificação de vários rótulos pode ter:
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
Erros comuns de .csv
- Uso de caracteres Unicode em rótulos. Por exemplo, caracteres japoneses não são compatíveis.
- Uso de espaços e caracteres não alfanuméricos em rótulos.
- Linhas vazias.
- Colunas vazias (linhas com duas vírgulas sucessivas).
- O texto incorporado que inclui vírgulas não está entre aspas.
- Uso incorreto de maiúsculas e minúsculas dos caminhos do Cloud Storage.
- Controle de acesso incorreto configurado para seus documentos. Sua conta de serviço precisa ter acesso de leitura ou maior ou os arquivos precisam ser legíveis publicamente.
- Referências a arquivos que não são de texto, como arquivos JPEG. Da mesma forma, arquivos que não são de texto, mas que forem renomeados com uma extensão de texto, causarão um erro.
- O URI de um documento aponta para um bucket diferente do atual. Somente arquivos no bucket do projeto podem ser acessados.
- Arquivos não formatados em CSV.
Como criar um arquivo ZIP de importação
Para conjuntos de dados de classificação, importe os documentos de treinamento usando um arquivo ZIP. No arquivo ZIP, crie uma pasta para cada valor de rótulo ou sentimento e salve cada documento na pasta correspondente ao rótulo ou valor a ser aplicado a esse documento. Por exemplo, o arquivo ZIP de um modelo que classifica correspondência comercial pode ter esta estrutura:
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
O AutoML Natural Language aplica os nomes das pastas como rótulos aos documentos na pasta. Para um conjunto de dados de análise de sentimento, os nomes das pastas são os valores de sentimento:
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt
A seguir
- Importe dados para criar um conjunto de dados.