Para entrenar tu modelo personalizado, proporciona muestras representativas del tipo de documentos que deseas analizar, etiquetados de la manera en que deseas que AutoML Natural Language etiquete documentos similares. La calidad de los datos de entrenamiento tiene un gran impacto en la eficacia del modelo que creas y, por extensión, en la calidad de las predicciones que muestra ese modelo.
Recopilar y etiquetar documentos de entrenamiento
El primer paso es recopilar un conjunto diverso de documentos de entrenamiento que reflejen la variedad de documentos que deseas que procese el modelo personalizado. Los pasos de preparación de los documentos de entrenamiento varían según si estás entrenando un modelo para la clasificación, la extracción de entidades o el análisis de opiniones.
Extracción de entidades
Para entrenar un modelo de extracción de entidades, proporciona muestras representativas del tipo de contenido que deseas analizar, anotadas con etiquetas que identifiquen los tipos de entidades que deseas que identifique AutoML Natural Language.
Proporciona entre 50 y 100,000 documentos para usarlos en el entrenamiento de tu modelo personalizado. Usa entre 1 y 100 etiquetas únicas para anotar las entidades que deseas que el modelo aprenda a extraer. Cada anotación es un intervalo de texto y una etiqueta asociada. Los nombres de las etiquetas pueden tener entre 2 y 30 caracteres, y se pueden usar para anotar entre 1 y 10 palabras. Recomendamos usar cada etiqueta al menos 200 veces en tu conjunto de datos de entrenamiento.
Si anotas un tipo de documento estructurado o semiestructurado, como facturas o contratos, AutoML Natural Language puede considerar la posición de una anotación en la página como un factor que contribuye a la asignación de la etiqueta adecuada. Por ejemplo, un contrato de bienes raíces tiene una fecha de aceptación y una de cierre, y AutoML Natural Language puede aprender a distinguir entre las entidades según la posición espacial de la anotación.
Dar formato a los documentos de entrenamiento
Los datos de entrenamiento se suben en AutoML Natural Language como archivos JSONL que contienen los documentos de muestra. Cada línea del archivo es un único documento de entrenamiento, especificado en una de dos formas:
- El contenido completo del documento, con una longitud de entre 10 y 10,000 bytes (codificación UTF-8)
- El URI de un archivo PDF o TIFF de un bucket de Cloud Storage asociado al proyecto
La consideración de la posición espacial solo está disponible para los documentos de entrenamiento en formato PDF.
Puedes anotar los documentos de texto de tres maneras:
- Anotar los archivos JSONL directamente antes de subirlos
- Agregar anotaciones en la IU de AutoML Natural Language después de subir los documentos sin anotaciones
- Solicitar el etiquetado a personas mediante el Servicio de etiquetado de datos de AI Platform
Puedes combinar las dos primeras opciones subiendo archivos JSONL etiquetados y modificándolos en la IU.
Solo puedes anotar archivos PDF con la IU de AutoML Natural Language.
Documentos JSONL
Para ayudarte a crear archivos de entrenamiento JSONL, AutoML Natural Language ofrece una secuencia de comandos de Python que convierte archivos de texto sin formato en archivos JSONL con el formato adecuado. Mira los comentarios en la secuencia de comandos para obtener más detalles.
Cada documento del archivo JSONL tiene uno de los siguientes formatos:
Cada documento debe ocupar una línea en el archivo JSONL. El siguiente ejemplo incluye saltos de línea para facilitar la lectura. Es necesario quitarlos en el archivo JSONL. Para obtener más información, consulta http://jsonlines.org/.
Para los documentos no anotados:
{
"text_snippet":
{"content": string}
}
Para los documentos anotados:
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
Cada elemento text_extraction identifica una anotación dentro de text_snippet.content. Indica la posición del texto anotado mediante la especificación del número de caracteres desde el comienzo de text_snippet.content hasta el principio (start_offset) y el final (end_offset) del texto; display_name es la etiqueta de la entidad.
Tanto start_offset como end_offset son compensaciones de caracteres en lugar de bytes. El carácter de end_offset no está incluido en el segmento de texto. Consulta TextSegment para obtener más detalles. Los elementos text_extraction son opcionales. Puedes omitirlos si planeas anotar el documento con la IU de AutoML Natural Language. Cada anotación puede abarcar hasta diez tokens (palabras). No pueden superponerse. El start_offset de una anotación no puede estar entre el start_offset y el end_offset de otra anotación en el mismo documento.
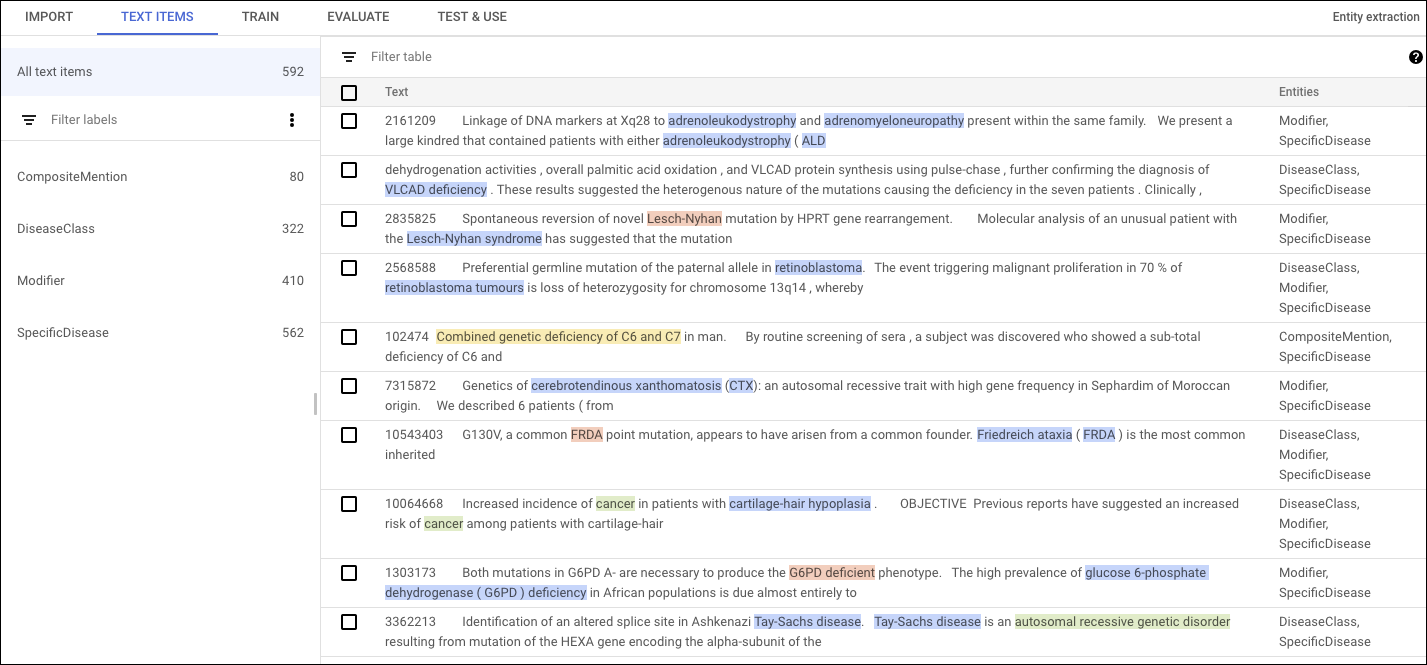
Por ejemplo, este documento de entrenamiento de ejemplo identifica las enfermedades específicas mencionadas en un resumen del corpus del NCBI.
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
Un archivo JSONL puede contener varios documentos de entrenamiento con esta estructura, uno en cada línea del archivo.
Documentos PDF o TIFF
Para subir un archivo PDF o TIFF como documento, ajusta la ruta del archivo dentro de un elemento document JSONL:
Cada documento debe ocupar una línea en el archivo JSONL. El siguiente ejemplo incluye saltos de línea para facilitar la lectura. Es necesario quitarlos en el archivo JSONL. Para obtener más información, consulta http://jsonlines.org/.
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
El valor del elemento input_uris es la ruta de acceso a un archivo PDF o TIFF en un bucket de Cloud Storage asociado con tu proyecto. El tamaño máximo del archivo PDF o TIFF es de 2 MB.
Importar documentos de entrenamiento
Puedes importar datos de entrenamiento en AutoML Natural Language mediante un archivo CSV en el que se enumeren los documentos y, opcionalmente, que incluya sus etiquetas de categoría o valores de opinión. AutoML Natural Language crea un conjunto de datos a partir de los documentos enumerados.
Datos de entrenamiento y de evaluación
AutoML Natural Language divide los documentos de entrenamiento en tres conjuntos para entrenar un modelo: un conjunto de entrenamiento, un conjunto de validación y un conjunto de prueba.
AutoML Natural Language usa el conjunto de entrenamiento para crear el modelo. El modelo prueba múltiples algoritmos y parámetros mientras busca patrones en los datos de entrenamiento. A medida que el modelo identifica patrones, usa el conjunto de validación para probar los algoritmos y patrones. AutoML Natural Language elige los algoritmos y patrones con mejor rendimiento de aquellos identificados durante la etapa de entrenamiento.
Después de identificar los patrones y algoritmos con mejor rendimiento, AutoML Natural Language los aplica al conjunto de pruebas para evaluar la tasa de error, la calidad y la exactitud.
De forma predeterminada, AutoML Natural Language divide los datos de entrenamiento de forma aleatoria en los tres conjuntos:
- El 80% de los documentos se usan para el entrenamiento.
- El 10% de los documentos se utilizan para la validación (ajuste de hiperparámetros o para decidir cuándo detener el entrenamiento).
- El 10% de los documentos se reservan para pruebas (no se usan durante el entrenamiento).
Si deseas especificar a qué conjunto debe pertenecer cada documento de tus datos de entrenamiento, puedes asignar explícitamente los documentos a los conjuntos en el archivo CSV como se describe en la siguiente sección.
Crear un archivo CSV de importación
Una vez que hayas recopilado todos tus documentos de entrenamiento, crea un archivo CSV en el que se enumeren todos. El archivo CSV puede tener cualquier nombre de archivo, debe estar codificado en UTF-8 y debe terminar con la extensión .csv. Debe almacenarse en el bucket de Cloud Storage asociado con su proyecto.
El archivo CSV tiene una fila para cada documento de entrenamiento y las siguientes columnas en cada fila:
A qué conjunto asignar el contenido de esta fila. Esta columna es opcional y puede ser uno de los siguientes valores:
TRAIN: Usa el document para entrenar el modelo.VALIDATION: Usa el document para validar los resultados que muestra el modelo durante el entrenamiento.TEST: Usa el document para verificar los resultados del modelo después de entrenarlo.
Si incluyes valores en esta columna para especificar los conjuntos, te recomendamos que identifiques, al menos, el 5% de tus datos para cada categoría. El uso de menos del 5% de tus datos para el entrenamiento, la validación o las pruebas puede producir resultados inesperados y modelos ineficaces.
Si no incluyes valores en esta columna, comienza cada fila con una coma para indicar que la primera columna está vacía. AutoML Natural Language divide de forma automática tus documentos en tres conjuntos: aproximadamente el 80% de los datos para entrenamiento, el 10% para validación y el 10% para pruebas (hasta 10,000 pares para validación y pruebas).
El contenido a clasificar. Esta columna contiene el URI de Cloud Storage para el documento. Los URI de Cloud Storage distinguen entre mayúsculas y minúsculas.
Para la clasificación y el análisis de opiniones, el documento puede ser un archivo de texto, un archivo PDF, un archivo TIFF o un archivo ZIP; para la extracción de entidades, es un archivo JSONL.
Para la clasificación y el análisis de opiniones, el valor de esta columna puede ser texto en línea entrecomillado en lugar de un URI de Cloud Storage.
Para los conjuntos de datos de clasificación, tienes la opción de incluir una lista de etiquetas separadas por comas que identifican cómo se categoriza el documento. Las etiquetas deben comenzar con una letra, y solo deben contener letras, números y guiones bajos. Puedes incluir hasta 20 etiquetas para cada documento.
Para los conjuntos de datos de análisis de opiniones, puedes incluir un número entero que indique el valor de la opinión para el contenido. El valor de la opinión varía de 0 (muy negativo) a un valor máximo de 10 (muy positivo).
Por ejemplo, el archivo CSV para un conjunto de datos de clasificación de varias etiquetas podría tener lo siguiente:
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
Errores comunes de .csv
- Usar caracteres unicode en las etiquetas. Por ejemplo, los caracteres japoneses no son compatibles
- Usar espacios y caracteres no alfanuméricos en las etiquetas
- Líneas vacías
- Columnas vacías (líneas con dos comas sucesivas)
- Comillas faltantes en texto insertado que incluya comas
- Uso incorrecto de mayúsculas en las rutas de Cloud Storage
- Un control de acceso incorrecto configurado para tus documentos Tu cuenta de servicio debe tener acceso de lectura o superior, o bien los archivos deben tener acceso público de lectura
- Referencias a archivos que no son de texto, como archivos JPEG Asimismo, los archivos que no son archivos de texto, pero que se renombraron con una extensión de texto, causarán un error
- El URI de un documento dirige a un bucket diferente del proyecto actual. Solo se puede acceder a los archivos del bucket del proyecto
- Archivos sin formato CSV
Crear un archivo ZIP de importación
Para los conjuntos de datos de clasificación, puedes importar documentos de entrenamiento mediante un archivo ZIP. En el archivo ZIP, crea una carpeta para cada etiqueta o valor de opinión, y guarda cada documento dentro de la carpeta correspondiente a la etiqueta o el valor que se aplicará a ese documento. Por ejemplo, el archivo ZIP de un modelo que clasifica correspondencia comercial podría tener esta estructura:
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
AutoML Natural Language aplica los nombres de las carpetas como etiquetas a los documentos de la carpeta. Para un conjunto de datos de análisis de opiniones, los nombres de las carpetas son los valores de opinión:
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt
¿Qué sigue?
- Importa tus datos para crear tu conjunto de datos.