Un conjunto de datos contiene muestras representativas del tipo de contenido que deseas clasificar, con las etiquetas de categoría que quieres que use tu modelo personalizado. El conjunto de datos sirve como entrada para entrenar un modelo.
Los pasos principales para compilar un conjunto de datos son:
- Crear un recurso de conjuntos de datos
- Importar datos de entrenamiento al conjunto de datos.
- Etiquetar los documentos o identificar las entidades.
Para la clasificación y el análisis de opiniones, a menudo se combinan los pasos 2 y 3: puedes importar documentos con sus etiquetas ya asignadas.
Crea un conjunto de datos
El primer paso cuando se crea un modelo personalizado es crear un conjunto de datos vacío que finalmente tendrá los datos de entrenamiento para el modelo. El conjunto de datos recién creado no contendrá ningún dato hasta que importes elementos en él.
IU web
Sigue estos pasos para crear un conjunto de datos:
Abre la IU de AutoML Natural Language y selecciona Comenzar en el cuadro correspondiente al tipo de modelo que planeas entrenar.
Aparece la página Conjuntos de datos, que muestra el estado de los conjuntos de datos creados anteriormente para el proyecto actual.
Para agregar un conjunto de datos a un proyecto diferente, selecciona el proyecto de la lista desplegable en la esquina superior derecha de la barra de título.
Haz clic en el botón Conjunto de datos nuevo en la barra de título.
Escribe un nombre para el conjunto de datos y especifica en qué ubicación geográfica se almacenará.
Consulta la información sobre ubicaciones para obtener más detalles.
Selecciona el objetivo del modelo, que especifica qué tipo de análisis realizará el modelo entrenado con este conjunto de datos.
- La clasificación con una sola etiqueta asigna una sola etiqueta a cada documento clasificado.
- La clasificación con varias etiquetas permite asignar varias etiquetas a un documento.
- La extracción de entidades consiste en identificar entidades en los documentos.
- El análisis de opiniones consiste en analizar las actitudes de los autores de los documentos.
Haga clic en Crear conjunto de datos.
Aparecerá la página de importación para el conjunto de datos nuevo. Consulta Importar datos a un conjunto de datos.
Ejemplos de código
Clasificación
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID de tu proyecto
- location-id: la ubicación del recurso;
us-central1para la ubicación global oeupara la Unión Europea
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Cuerpo JSON de la solicitud:
{
"displayName": "test_dataset",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"name": "projects/434039606874/locations/us-central1/datasets/356587829854924648",
"displayName": "test_dataset",
"createTime": "2018-04-26T18:02:59.825060Z",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Python de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Java de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Node.js de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Go de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Idiomas adicionales
C# Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para PHP
Ruby: Sigue las Instrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para Ruby.
Extracción de entidades
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID de tu proyecto
- location-id: la ubicación del recurso;
us-central1para la ubicación global oeupara la Unión Europea
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Cuerpo JSON de la solicitud:
{
"displayName": "test_dataset",
"textExtractionDatasetMetadata": {
}
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
name: "projects/000000000000/locations/us-central1/datasets/TEN5582774688079151104"
display_name: "test_dataset"
create_time {
seconds: 1539886451
nanos: 757650000
}
text_extraction_dataset_metadata {
}
}
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Python de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Java de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Node.js de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Go de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Idiomas adicionales
C# Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para PHP
Ruby: Sigue las Instrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para Ruby.
Análisis de opiniones
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID de tu proyecto
- location-id: la ubicación del recurso;
us-central1para la ubicación global oeupara la Unión Europea
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Cuerpo JSON de la solicitud:
{
"displayName": "test_dataset",
"textSentimentDatasetMetadata": {
"sentimentMax": 4
}
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
name: "projects/000000000000/locations/us-central1/datasets/TST8962998974766436002"
display_name: "test_dataset_name"
create_time {
seconds: 1538855662
nanos: 51542000
}
text_sentiment_dataset_metadata {
sentiment_max: 7
}
}
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Python de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Java de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Node.js de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Go de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Idiomas adicionales
C# Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para PHP
Ruby: Sigue las Instrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para Ruby.
Importar datos de entrenamiento a un conjunto de datos
Después de haber creado un conjunto de datos, puedes importar los URI de documentos y etiquetas para documentos desde un archivo CSV almacenado en un bucket de Cloud Storage. Si deseas obtener detalles sobre cómo preparar tus datos y crear un archivo CSV para importar, consulta Preparar los datos de entrenamiento.
Puedes importar documentos a un conjunto de datos vacío o importar documentos adicionales a un conjunto de datos existente.
IU web
Para importar documentos a un conjunto de datos, sigue estos pasos:
Selecciona el conjunto de datos al que deseas importar documentos en la página Conjuntos de datos.
En la pestaña Importar, especifica dónde encontrar los documentos de entrenamiento.
Puede hacer lo siguiente:
Carga un archivo .csv que contenga los documentos de entrenamiento y sus etiquetas de categoría asociadas desde tu computadora local o desde Cloud Storage.
Carga una colección de archivos .txt, .pdf, .tif o .zip que contengan los documentos de entrenamiento de tu computadora local.
Selecciona los archivos por importar y la ruta de Cloud Storage para los documentos importados.
Haga clic en Import.
Muestras de código
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID de tu proyecto
- location-id: la ubicación del recurso;
us-central1para la ubicación global oeupara la Unión Europea - dataset-id: ID del conjunto de datos
- bucket-name: tu bucket de Cloud Storage
- csv-file-name: archivo de datos de entrenamiento en formato CSV
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets/dataset-id:importData
Cuerpo JSON de la solicitud:
{
"inputConfig": {
"gcsSource": {
"inputUris": ["gs://bucket-name/csv-file-name.csv"]
}
}
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías ver un resultado similar al siguiente. Puedes usar el ID de operación para obtener el estado de la tarea. Para ver un ejemplo, consulta Obtener el estado de una operación.
{
"name": "projects/434039606874/locations/us-central1/operations/1979469554520650937",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2018-04-27T01:28:36.128120Z",
"updateTime": "2018-04-27T01:28:36.128150Z",
"cancellable": true
}
}
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Python de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Java de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Node.js de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Go de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Idiomas adicionales
C# Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para PHP
Ruby: Sigue las Instrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para Ruby.
Etiquetar documentos de entrenamiento
Para que resulte útil en el entrenamiento de un modelo, cada documento de un conjunto de datos debe estar etiquetado de la misma forma en que quieres que AutoML Natural Language etiquete otros documentos similares. La calidad de los datos de entrenamiento tiene un gran impacto en la eficacia del modelo que creas y, por extensión, en la calidad de las predicciones que muestra ese modelo. AutoML Natural Language ignora los documentos no etiquetados durante el entrenamiento.
Puedes proporcionar etiquetas a los documentos de entrenamiento de tres maneras:
- Incluir etiquetas en el archivo .csv (solo para clasificación y análisis de opiniones)
- Etiquetar los documentos en la IU de AutoML Natural Language
- Solicitar el etiquetado a personas mediante el Servicio de etiquetado de datos de AI Platform
La API de AutoML no incluye métodos de etiquetado.
Para obtener detalles sobre cómo etiquetar documentos en tu archivo .csv, consulta Preparar los datos de entrenamiento.
Etiquetado para clasificación y análisis de opiniones
Para etiquetar documentos en la IU de AutoML Natural Language, selecciona el conjunto de datos de la página del listado a fin de ver los detalles. El nombre visible del conjunto de datos seleccionado aparece en la barra de título y, en la página, se muestran sus documentos individuales junto con sus etiquetas asignadas. La barra de navegación a la izquierda resume el número de documentos etiquetados y no etiquetados, y te permite filtrar la lista de documentos por etiqueta o valor de opinión.
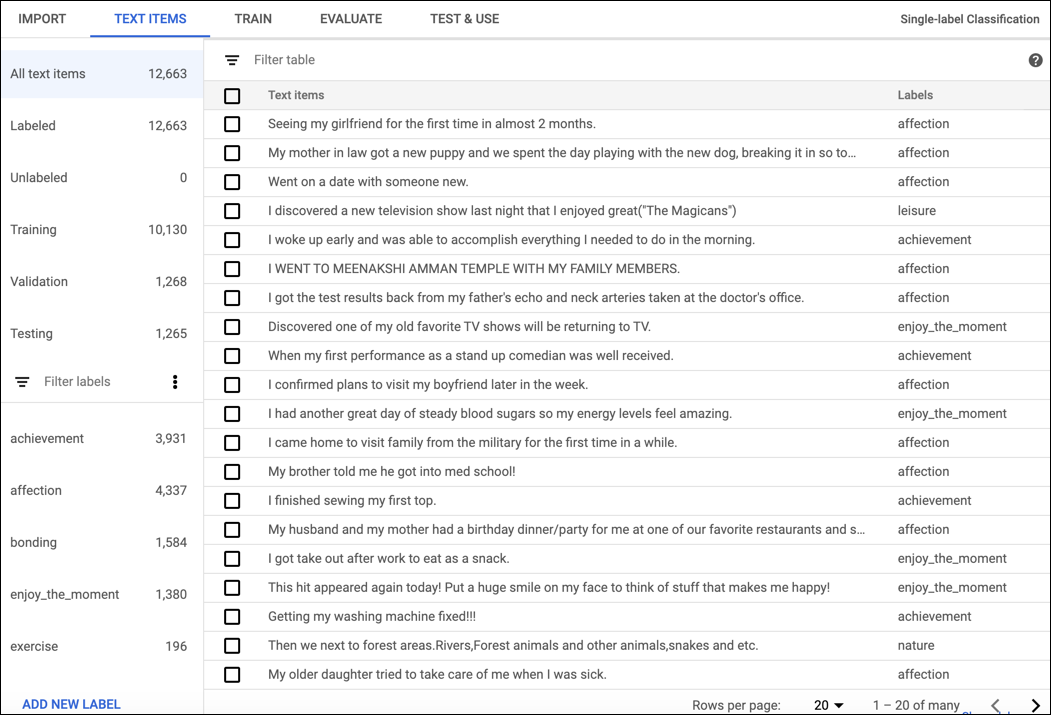
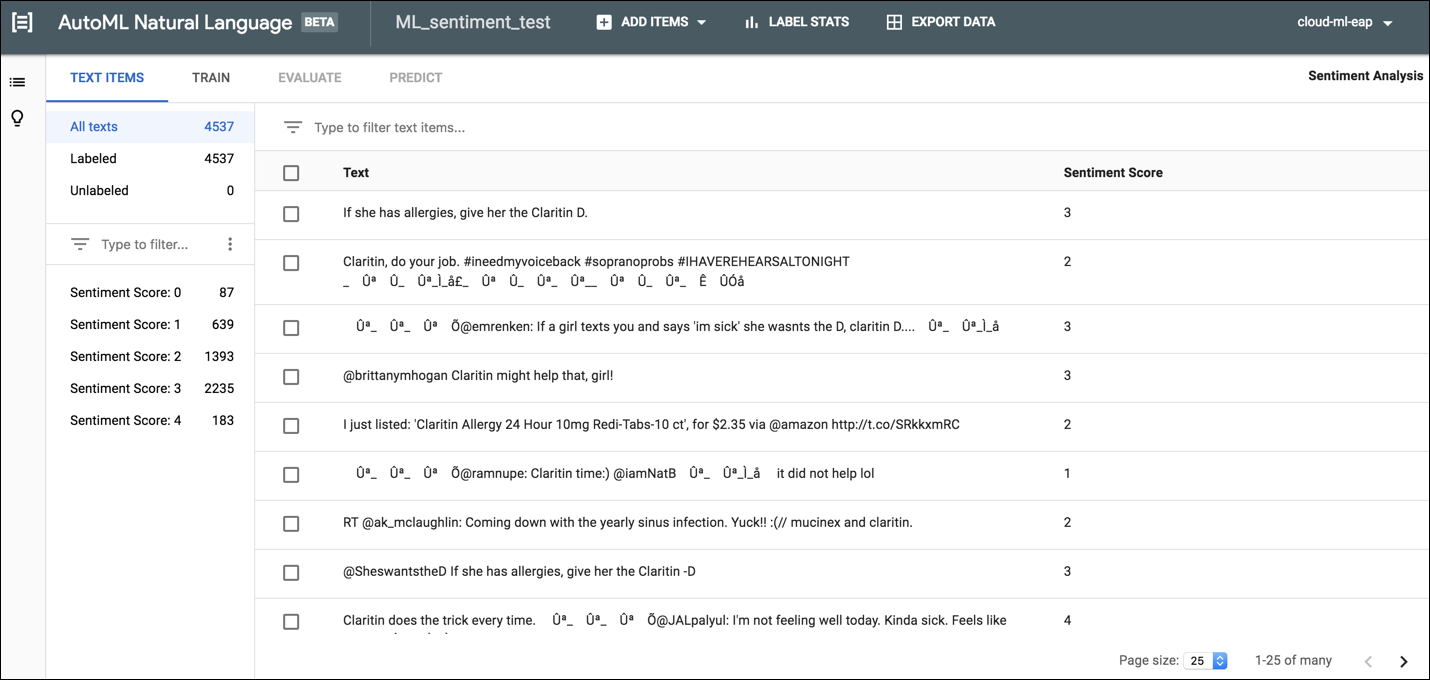
Para asignar etiquetas o valores de opinión a documentos sin etiquetar o cambiar etiquetas de documentos, selecciona los documentos que deseas actualizar y las etiquetas que quieres asignarles. Hay dos maneras de actualizar la etiqueta de un documento:
Haz clic en la casilla de verificación ubicada junto a los documentos que deseas actualizar y, luego, selecciona las etiquetas que deseas aplicar en la lista desplegable Etiqueta que aparece en la parte superior de la lista de documentos.
Haz clic en la fila del documento que deseas actualizar y, luego, selecciona las etiquetas o el valor que quieres aplicar de la lista que aparece en la página Detalles del texto.
Identificar entidades para la extracción de entidades
Antes de entrenar tu modelo personalizado, debes anotar los documentos de entrenamiento en el conjunto de datos. Puedes anotar los documentos de entrenamiento antes de importarlos o puedes agregar anotaciones en la IU de AutoML Natural Language.
Para realizar anotaciones en la IU de AutoML Natural Language, selecciona el conjunto de datos de la página del listado para ver los detalles. El nombre visible del conjunto de datos seleccionado aparece en la barra de título, y en la página, se muestran los documentos individuales del conjunto junto con las anotaciones que tengan. La barra de navegación ubicada a la izquierda resume las etiquetas y la cantidad de veces que aparece cada una. También puedes filtrar la lista de documentos por etiqueta.
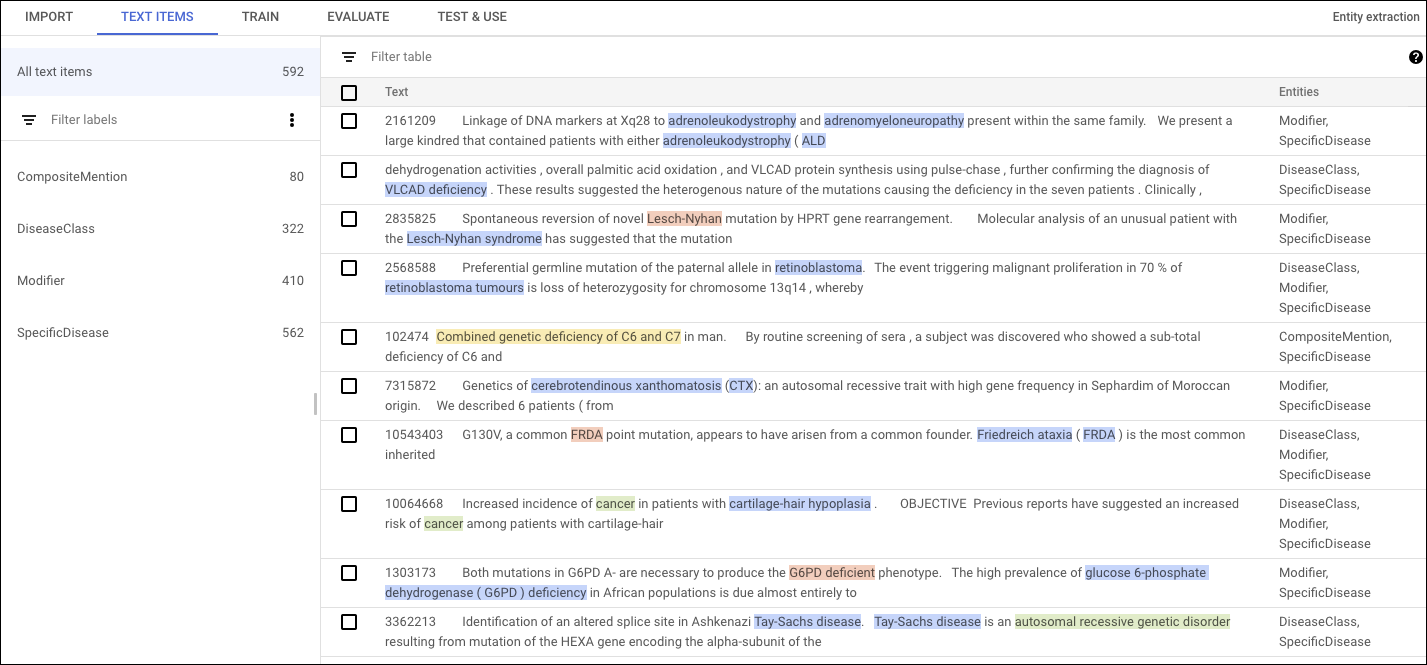
Para agregar o borrar anotaciones dentro de un documento, haz doble clic en el documento que deseas actualizar. En la página Editar, se muestra el texto completo del documento seleccionado, con todas las anotaciones anteriores destacadas.

En el caso de los documentos de entrenamiento en formato PDF o los importados con información de diseño, la página Editar tiene dos pestañas: Texto sin formato y Texto estructurado. En la pestaña Texto sin formato, se muestra el contenido sin procesar del documento de entrenamiento sin ningún formato. En la pestaña Texto estructurado, se recrea el diseño básico del documento de entrenamiento. (La pestaña Texto sin formato también tiene un vínculo al archivo PDF original).
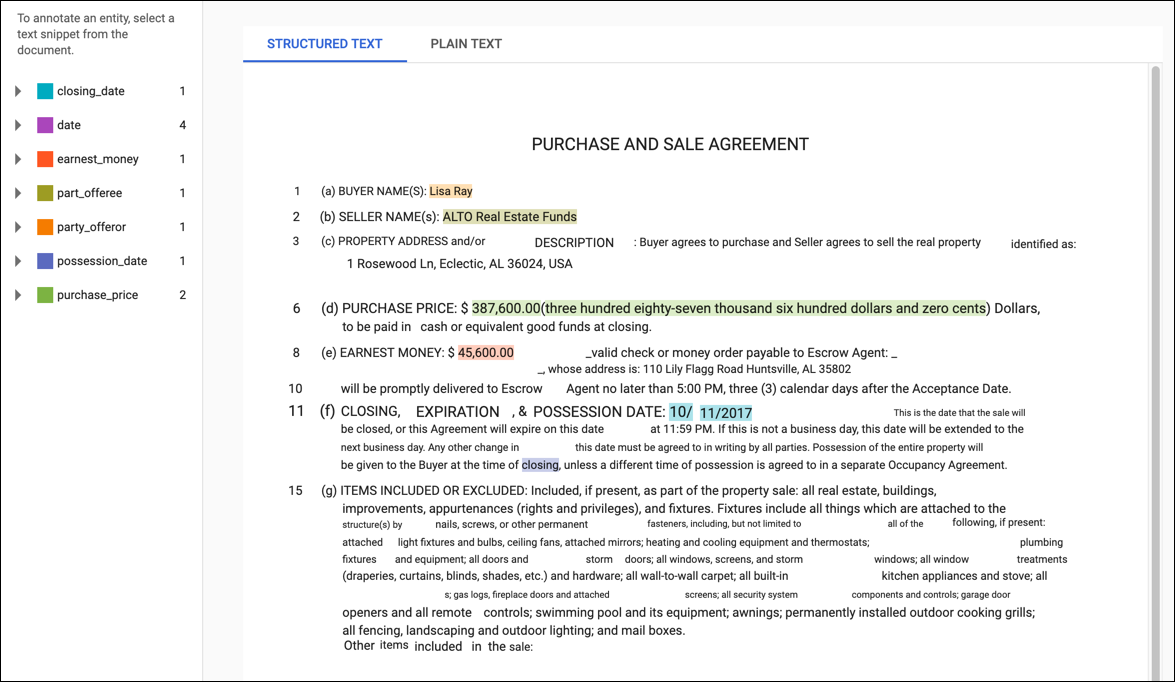
Para agregar una anotación nueva, destaca el texto que representa la entidad, selecciona la etiqueta del cuadro de diálogo Anotar y haz clic en Guardar. Cuando agregas anotaciones en la pestaña Texto estructurado, AutoML Natural Language captura la posición de la anotación en la página como un factor para tener en cuenta durante el entrenamiento.
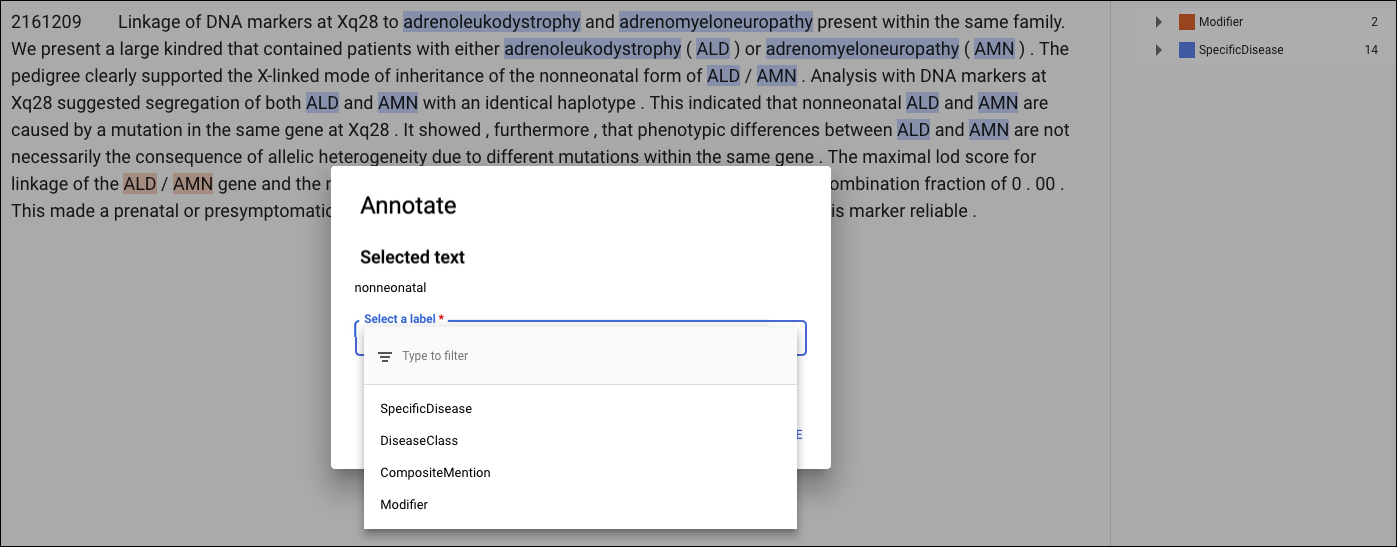
Para quitar una anotación, busca el texto en la lista de etiquetas de la derecha y haz clic en el ícono de la papelera que aparece junto a ella.