Después de que se entrena un modelo, AutoML Natural Language utiliza documentos del conjunto TEST para evaluar la calidad y la exactitud del nuevo modelo.
AutoML Natural Language proporciona un conjunto agregado de métricas de evaluación que indican el desempeño general del modelo, así como métricas de evaluación para cada etiqueta de categoría, que indican el desempeño del modelo para esa etiqueta.
La precisión (Precision) y la recuperación (Recall) miden qué tan bien captura la información el modelo y qué omite. La precisión indica, a partir de todos los documentos identificados como una entidad o etiqueta en particular, cuántos se suponía que debían asignarse a esa entidad o etiqueta. La recuperación indica, de todos los documentos que deberían haberse identificado como una entidad o etiqueta en particular, cuántos se asignaron realmente a esa entidad o etiqueta.
La matriz de confusión (Confusion matrix) (solo disponible para modelos de una sola etiqueta por documento) representa el porcentaje de veces que se predijo cada etiqueta en el conjunto de entrenamiento durante la evaluación. Lo ideal es que la etiqueta one se asigne solo a documentos clasificados con la etiqueta one, etc., por lo que una matriz perfecta se vería así:
100 0 0 0
0 100 0 0
0 0 100 0
0 0 0 100
En el ejemplo anterior, si un documento se clasificó como one, pero el modelo predijo two, la primera fila se verá de la siguiente manera:
99 1 0 0
AutoML Natural Language crea la matriz de confusión para hasta 10 etiquetas. Si tienes más de 10 etiquetas, la matriz incluye las 10 con mayor confusión (predicciones incorrectas).
Para los modelos de opiniones:
El error absoluto medio (EAM) y el error cuadrático medio (ECM) miden la distancia entre el valor de la opinión que se predijo y el valor de la opinión real. Los valores más bajos significan modelos más precisos.
Los índices kappa con ponderación lineal y cuadrática miden el nivel de coincidencia entre los valores de opinión asignados por el modelo y los asignados por evaluadores humanos. Valores más altos indican modelos más exactos.
Usa estas métricas para evaluar la preparación de tu modelo. La presencia de puntuaciones bajas de precisión y recuperación pueden indicar que tu modelo necesita datos de entrenamiento adicionales o que tiene anotaciones incongruentes. La presencia de puntuaciones perfectas de las mismas métricas puede indicar que los datos son demasiado fáciles de evaluar y que no pueden generalizarse bien. Consulta la guía para principiantes si deseas obtener más sugerencias sobre cómo evaluar modelos.
Si no estás satisfecho con los niveles de calidad, puedes volver a realizar los pasos anteriores para mejorar la calidad:
- Puedes agregar más documentos a cualquier etiqueta de calidad baja.
- Es posible que necesites agregar diferentes tipos de documentos. Por ejemplo, documentos más largos o más cortos, o documentos de diferentes autores que utilizan diferentes palabras o estilos.
- Puedes limpiar las etiquetas.
- Considera eliminar las etiquetas por completo si no tiene suficientes documentos de entrenamiento.
Una vez que hayas hecho los cambios, entrena y evalúa un nuevo modelo hasta que alcances un nivel de calidad lo suficientemente alto.
IU web
Para ver las métricas de evaluación de tu modelo, sigue estos pasos:
Haz clic en el ícono de la bombilla en la barra de navegación izquierda para ver los modelos disponibles.
Para ver los modelos de un proyecto diferente, selecciónalo de la lista desplegable en la parte superior derecha de la barra de título.
Haz clic en la fila del modelo que deseas evaluar.
Si es necesario, haz clic en la pestaña Evaluar (Evaluate) justo debajo de la barra de título.
Si completaste el entrenamiento para el modelo, AutoML Natural Language mostrará las métricas de evaluación.
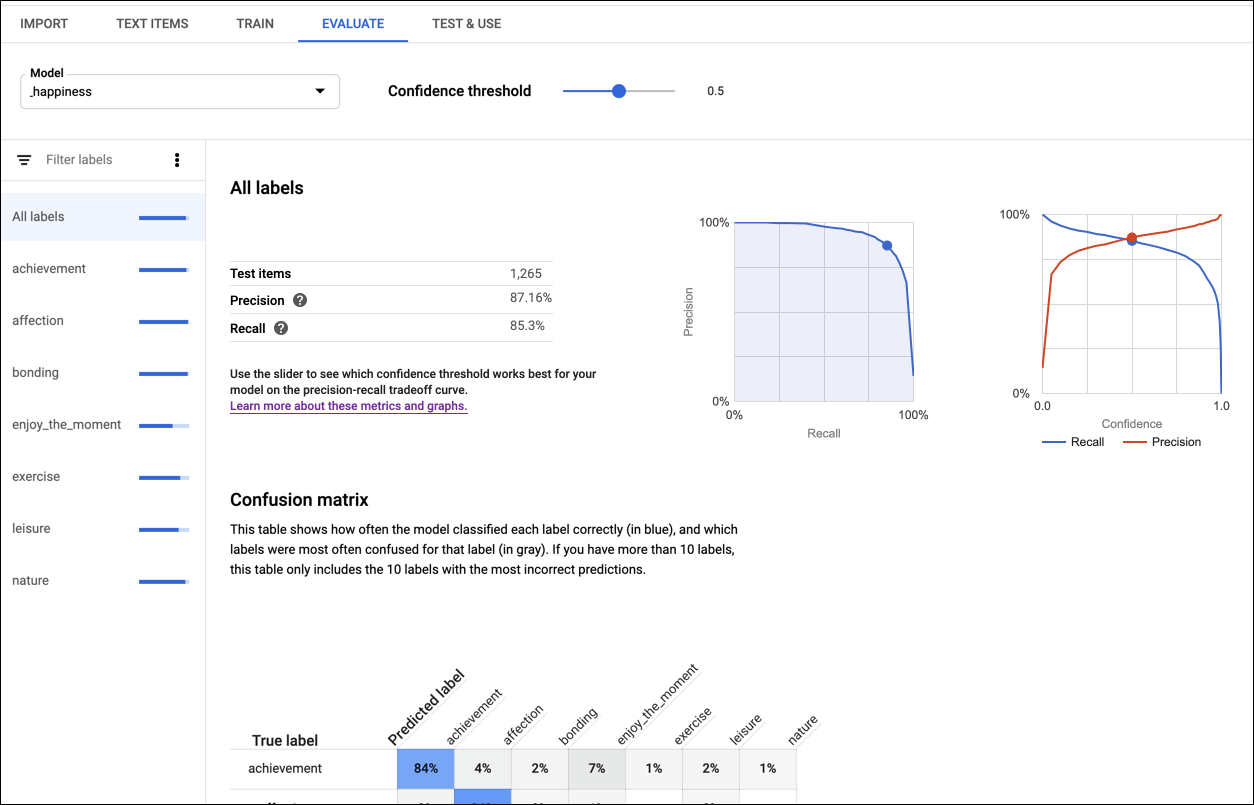
Para ver las métricas de una etiqueta específica, selecciona el nombre de la etiqueta de la lista que aparece en la parte inferior de la página.
Muestras de código
Las muestras proporcionan una evaluación del modelo en su conjunto. También puedes obtener las métricas de una etiqueta específica (displayName) mediante un ID de evaluación.
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: El ID de tu proyecto
- location-id: la ubicación del recurso;
us-central1para la ubicación global oeupara la Unión Europea - model-id: ID del modelo
Método HTTP y URL:
GET https://automl.googleapis.com/v1/projects/project-id/locations/location-id/models/model-id/modelEvaluations
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"modelEvaluation": [
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603448",
"annotationSpecId": "17040929661974749",
"classificationMetrics": {
"auPrc": 0.99772006,
"baseAuPrc": 0.21706384,
"evaluatedExamplesCount": 377,
"confidenceMetricsEntry": [
{
"recall": 1,
"precision": -1.3877788e-17,
"f1Score": -2.7755576e-17,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.05,
"recall": 0.997,
"precision": 0.867,
"f1Score": 0.92746675,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.1,
"recall": 0.995,
"precision": 0.905,
"f1Score": 0.9478684,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.15,
"recall": 0.992,
"precision": 0.932,
"f1Score": 0.96106446,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.2,
"recall": 0.989,
"precision": 0.951,
"f1Score": 0.96962786,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.25,
"recall": 0.987,
"precision": 0.957,
"f1Score": 0.9717685,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
...
],
},
"createTime": "2018-04-30T23:06:14.746840Z"
},
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603671",
"annotationSpecId": "1258823357545045636",
"classificationMetrics": {
"auPrc": 0.9972302,
"baseAuPrc": 0.1883289,
...
},
"createTime": "2018-04-30T23:06:14.649260Z"
}
]
}
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Python de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Java de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Node.js de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Natural Language, consulta Bibliotecas cliente de AutoML Natural Language. Para obtener más información, consulta la API de Go de AutoML Natural Language documentación de referencia.
Para autenticarte en AutoML Natural Language, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Idiomas adicionales
C# Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para PHP
Ruby: Sigue las Instrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita Documentación de referencia de AutoML Natural Language para Ruby.