Un ensemble de données contient des échantillons représentatifs du type de contenu que vous souhaitez classifier, dotés des libellés de catégorie que le modèle personnalisé doit utiliser. Il sert d'entrée pour l'entraînement d'un modèle.
Voici les principales étapes à suivre pour créer un ensemble de données :
- Créez une ressource d'ensemble de données.
- Importez des données d'entraînement dans l'ensemble de données.
- Attribuez une étiquette aux documents ou identifiez les entités.
Pour la classification et l'analyse des sentiments, les étapes 2 et 3 sont souvent combinées : vous pouvez importer des documents avec des étiquettes déjà attribuées.
Créer un ensemble de données
La première étape de l'élaboration d'un modèle personnalisé consiste à créer un ensemble de données vide, qui contiendra à terme les données d'entraînement du modèle. Le nouvel ensemble de données ne contient aucune donnée tant que vous n'y avez pas importé de documents.
UI Web
Pour créer un ensemble de données, procédez comme suit :
Ouvrez l'interface utilisateur d'AutoML Natural Language, puis sélectionnez Premiers pas dans le champ correspondant au type de modèle que vous souhaitez entraîner.
La page Ensembles de données s'affiche. Elle indique l'état des ensembles de données précédemment créés pour le projet en cours.
Si vous souhaitez ajouter un ensemble de données pour un autre projet, sélectionnez ce dernier dans la liste déroulante située dans l'angle supérieur droit de la barre de titre.
Cliquez sur le bouton Nouvel ensemble de données de la barre de titre.
Saisissez un nom pour l'ensemble de données et spécifiez l'emplacement géographique dans lequel stocker l'ensemble de données.
Pour plus d'informations, consultez la documentation sur les emplacements.
Sélectionnez l'objectif du modèle. Il sert à spécifier le type d'analyse que vous allez effectuer avec le modèle que vous entraînez à l'aide de cet ensemble de données.
- Classification à étiquette unique. Cette classification attribue une étiquette unique à chaque document classé.
- Classification multi-étiquette. Cette classification permet d'attribuer plusieurs étiquettes à un même document.
- L'extraction d'entités identifie les entités dans les documents.
- Analyse des sentiments. Cette option analyse les attitudes au sein des documents.
Cliquez sur Créer un ensemble de données.
La page Importer du nouvel ensemble de données s'affiche. Consultez la section sur l'importation des données dans un ensemble de données.
Exemples de code
Classification
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
- project-id : ID de votre projet.
- location-id : emplacement de la ressource,
us-central1pour l'emplacement mondial oueupour l'Union européenne
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Corps JSON de la requête :
{
"displayName": "test_dataset",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/434039606874/locations/us-central1/datasets/356587829854924648",
"displayName": "test_dataset",
"createTime": "2018-04-26T18:02:59.825060Z",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Python
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Python.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Java.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Node.js.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Go.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour .NET.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour PHP.
Ruby : Veuillez suivre les Instructions de configuration pour Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour Ruby.
Extraction d'entités
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
- project-id : ID de votre projet.
- location-id : emplacement de la ressource,
us-central1pour l'emplacement mondial oueupour l'Union européenne
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Corps JSON de la requête :
{
"displayName": "test_dataset",
"textExtractionDatasetMetadata": {
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
name: "projects/000000000000/locations/us-central1/datasets/TEN5582774688079151104"
display_name: "test_dataset"
create_time {
seconds: 1539886451
nanos: 757650000
}
text_extraction_dataset_metadata {
}
}
Python
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Python.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Java.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Node.js.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Go.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour .NET.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour PHP.
Ruby : Veuillez suivre les Instructions de configuration pour Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour Ruby.
Analyse des sentiments
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
- project-id : ID de votre projet.
- location-id : emplacement de la ressource,
us-central1pour l'emplacement mondial oueupour l'Union européenne
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Corps JSON de la requête :
{
"displayName": "test_dataset",
"textSentimentDatasetMetadata": {
"sentimentMax": 4
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
name: "projects/000000000000/locations/us-central1/datasets/TST8962998974766436002"
display_name: "test_dataset_name"
create_time {
seconds: 1538855662
nanos: 51542000
}
text_sentiment_dataset_metadata {
sentiment_max: 7
}
}
Python
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Python.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Java.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Node.js.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Go.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour .NET.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour PHP.
Ruby : Veuillez suivre les Instructions de configuration pour Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour Ruby.
Importer des données d'entraînement dans un ensemble de données
Après avoir créé un ensemble de données, vous pouvez importer des URI et des étiquettes de documents à partir d'un fichier CSV stocké dans un bucket Cloud Storage. Pour en savoir plus sur la préparation de vos données et la création d'un fichier CSV à importer, consultez la section Préparer les données d'entraînement.
Vous pouvez importer des documents dans un ensemble de données vide ou importer des documents supplémentaires dans un ensemble de données existant.
UI Web
Pour importer des documents dans un ensemble de données, procédez comme suit :
Sélectionnez l'ensemble de données dans lequel vous souhaitez importer des documents à partir de la page Ensembles de données.
Dans l'onglet Importer, indiquez où se trouvent les documents d'entraînement.
Vous pouvez :
Télécharger un fichier CSV contenant les documents d'entraînement et leurs étiquettes de catégorie associées depuis votre ordinateur local ou depuis Cloud Storage
Télécharger une collection de fichiers TXT, PDF, TIF ou ZIP contenant les documents d'entraînement depuis votre ordinateur local
Sélectionner le ou les fichiers à importer et le chemin d'accès Cloud Storage des documents importés.
Cliquez sur Importer.
Exemples de code
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
- project-id : ID de votre projet.
- location-id : emplacement de la ressource,
us-central1pour l'emplacement mondial oueupour l'Union européenne - dataset-id : ID de votre ensemble de données
- bucket-name : votre bucket Cloud Storage
- csv-file-name : votre fichier CSV de données d'entraînement
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets/dataset-id:importData
Corps JSON de la requête :
{
"inputConfig": {
"gcsSource": {
"inputUris": ["gs://bucket-name/csv-file-name.csv"]
}
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Des résultats semblables aux lignes suivantes devraient s'afficher : Vous pouvez obtenir l'état de la tâche à l'aide de l'ID d'opération. Vous trouverez un exemple dans la section Obtenir l'état d'une opération.
{
"name": "projects/434039606874/locations/us-central1/operations/1979469554520650937",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2018-04-27T01:28:36.128120Z",
"updateTime": "2018-04-27T01:28:36.128150Z",
"cancellable": true
}
}
Python
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Python.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Java.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Node.js.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Pour savoir comment installer et utiliser la bibliothèque cliente pour AutoML Natural Language, consultez la page Bibliothèques clientes AutoML Natural Language. Pour en savoir plus, consultez la documentation de référence de l'API AutoML Natural Language Go.
Pour vous authentifier auprès d'AutoML Natural Language, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour .NET.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour PHP.
Ruby : Veuillez suivre les Instructions de configuration pour Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Natural Language pour Ruby.
Étiquetage des documents d'entraînement
Pour servir à l'entraînement d'un modèle, chaque document d'un ensemble de données doit être étiqueté de la manière dont vous souhaitez qu'AutoML Natural Language étiquette les documents similaires. La qualité de vos données d'entraînement influe fortement sur l'efficacité du modèle que vous créez et, par extension, sur la qualité des prédictions renvoyées par ce modèle. AutoML Natural Language ignore les documents non-étiquetés pendant l'entraînement.
Vous pouvez attribuer des étiquettes à vos documents d'entraînement de trois façons différentes :
- En incluant des étiquettes dans votre fichier CSV (pour la classification et l'analyse des sentiments uniquement)
- En attribuant une étiquette à vos documents dans l'interface utilisateur d'AutoML Natural Language
- En confiant l'étiquetage à des professionnels via le service d'étiquetage de données AI Platform
L'API AutoML n'inclut pas de méthodes permettant d'appliquer des libellés.
Pour en savoir plus sur l'étiquetage de documents dans votre fichier CSV, consultez la page Préparer les données d'entraînement.
Étiquetage pour la classification et l'analyse des sentiments
Pour étiqueter des documents avec l'interface utilisateur AutoML Natural Language, sélectionnez l'ensemble de données à partir de la page où figure la liste des ensembles de données pour afficher les détails correspondants. Le nom à afficher de l'ensemble de données sélectionné apparaît dans la barre de titre et la page répertorie les différents documents de l'ensemble de données ainsi que leurs étiquettes actuelles. La barre de navigation sur la gauche récapitule le nombre de documents étiquetés et non-étiquetés, et vous permet de filtrer la liste de documents par étiquette ou valeur de sentiment.
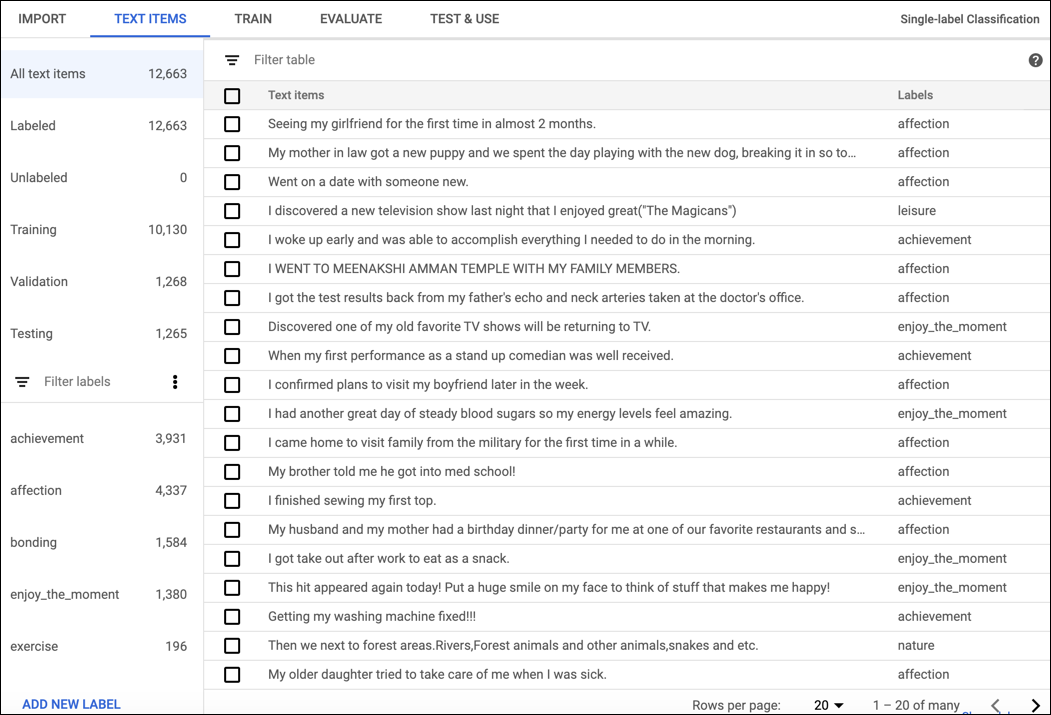
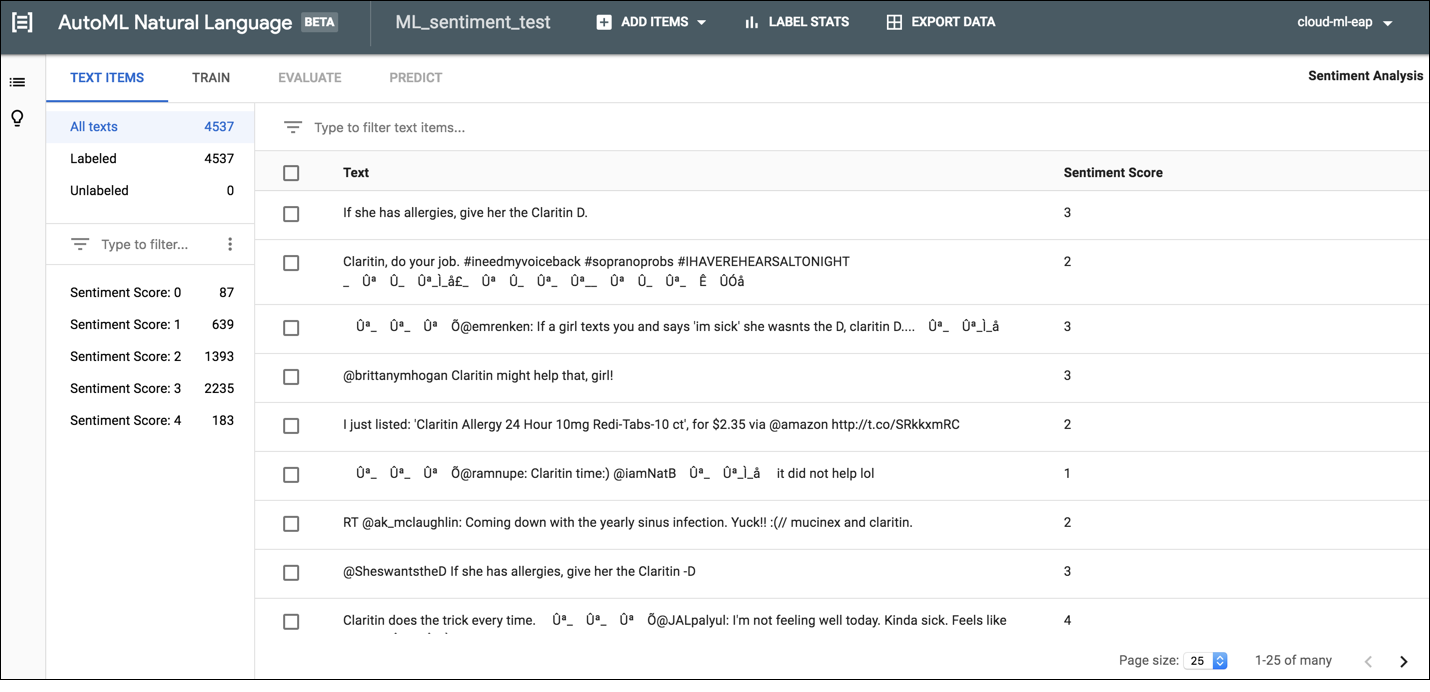
Pour attribuer des étiquettes ou des valeurs de sentiment à des documents sans étiquette ou pour changer les étiquettes des documents, sélectionnez les documents à mettre à jour, ainsi que la ou les étiquettes à attribuer. Il existe deux façons pour mettre à jour l'étiquette d'un document :
Cochez la case à côté des documents à mettre à jour, puis sélectionnez la ou les étiquettes à attribuer dans la liste déroulante Étiquette qui apparaît en haut de la liste de documents.
Cliquez sur la ligne du document que vous souhaitez mettre à jour, puis sélectionnez la ou les étiquettes à attribuer dans la liste qui apparaît sur la page Détails du texte.
Identifier les entités pour l'extraction d'entités
Avant d'entraîner votre modèle personnalisé, vous devez annoter les documents d'entraînement dans l'ensemble de données. Vous pouvez annoter les documents d'entraînement avant de les importer, ou ajouter des annotations dans l'interface utilisateur d'AutoML Natural Language.
Pour ajouter des annotations dans l'interface utilisateur d'AutoML Natural Language, sélectionnez l'ensemble de données à partir de la page répertoriant les ensembles de données pour afficher les détails correspondants. Le nom à afficher de l'ensemble de données sélectionné apparaît dans la barre de titre et la page répertorie les documents individuels de l'ensemble de données, ainsi que les annotations qu'ils contiennent. La barre de navigation sur la gauche répertorie les étiquettes et le nombre de fois où chaque étiquette apparaît. Vous pouvez également filtrer la liste de documents par étiquette.
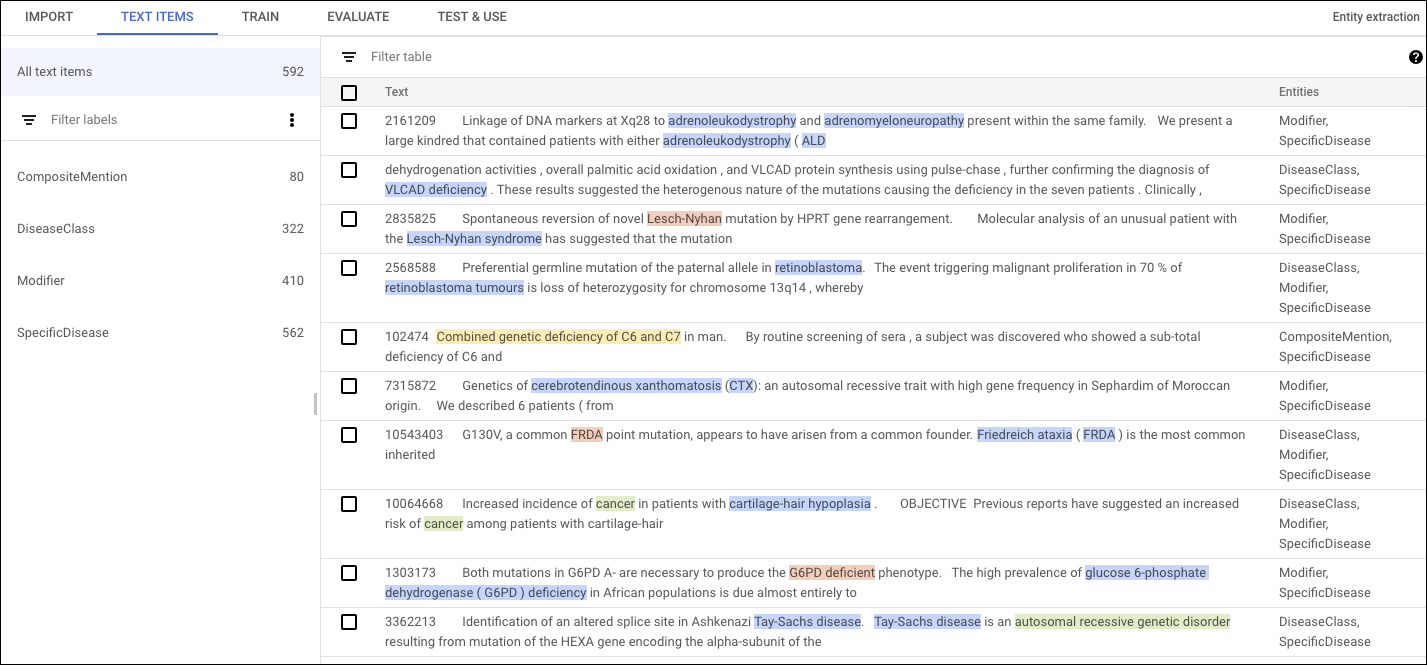
Pour ajouter ou supprimer des annotations dans un document, double-cliquez sur le document à mettre à jour. La page Modifier affiche le texte complet du document sélectionné, avec toutes les annotations précédentes en surbrillance.

La page Modifier comporte deux onglets : Texte brut et Texte structuré, afin d'accommoder les documents d'entraînement au format PDF et les documents importés qui contiennent des informations de mise en page. L'onglet Texte brut affiche le contenu brut du document d'entraînement sans aucune mise en forme. L'onglet Texte structuré reproduit la mise en page de base du document d'entraînement. (L'onglet Texte brut comporte également un lien vers le fichier PDF d'origine.)
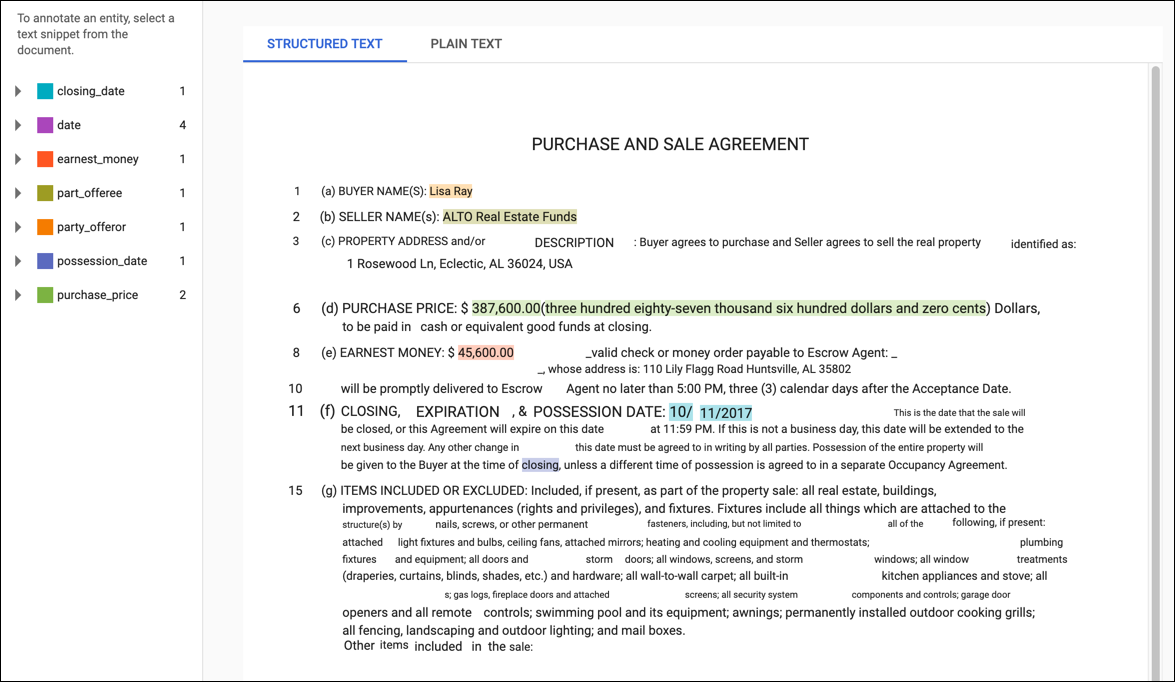
Pour ajouter une annotation, sélectionnez le texte qui représente l'entité, sélectionnez l'étiquette dans la boîte de dialogue Annoter, puis cliquez sur Enregistrer. Lorsque vous ajoutez des annotations dans l'onglet Texte structuré, AutoML Natural Language capture la position de l'annotation sur la page en tant que facteur pris en compte lors de l'entraînement.
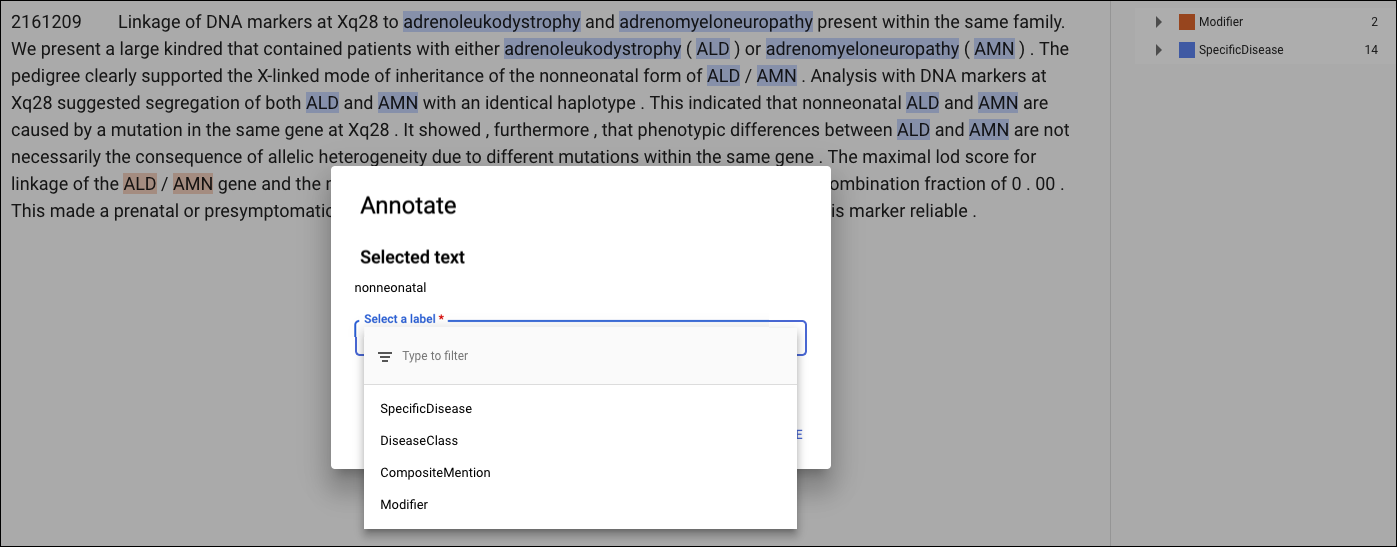
Pour supprimer une annotation, localisez le texte dans la liste des étiquettes sur la droite, puis cliquez sur l'icône de la corbeille à côté de celle-ci.