Architecture de la CLI Migrate to Containers
Cette page décrit en détail comment la CLI Migrate to Containers transforme vos applications hébergées sur des instances de machine virtuelle (VM) en artefacts que vous pouvez utiliser pour déployer vos composants d'application depuis l'environnement source vers un cluster cible sur Google Kubernetes Engine (GKE) ou GKE Enterprise
Composants de la CLI Migrate to Containers
La modernisation à l'aide de la CLI Migrate to Containers se déroule en trois étapes : transformation, déploiement des charges de travail et maintenance.
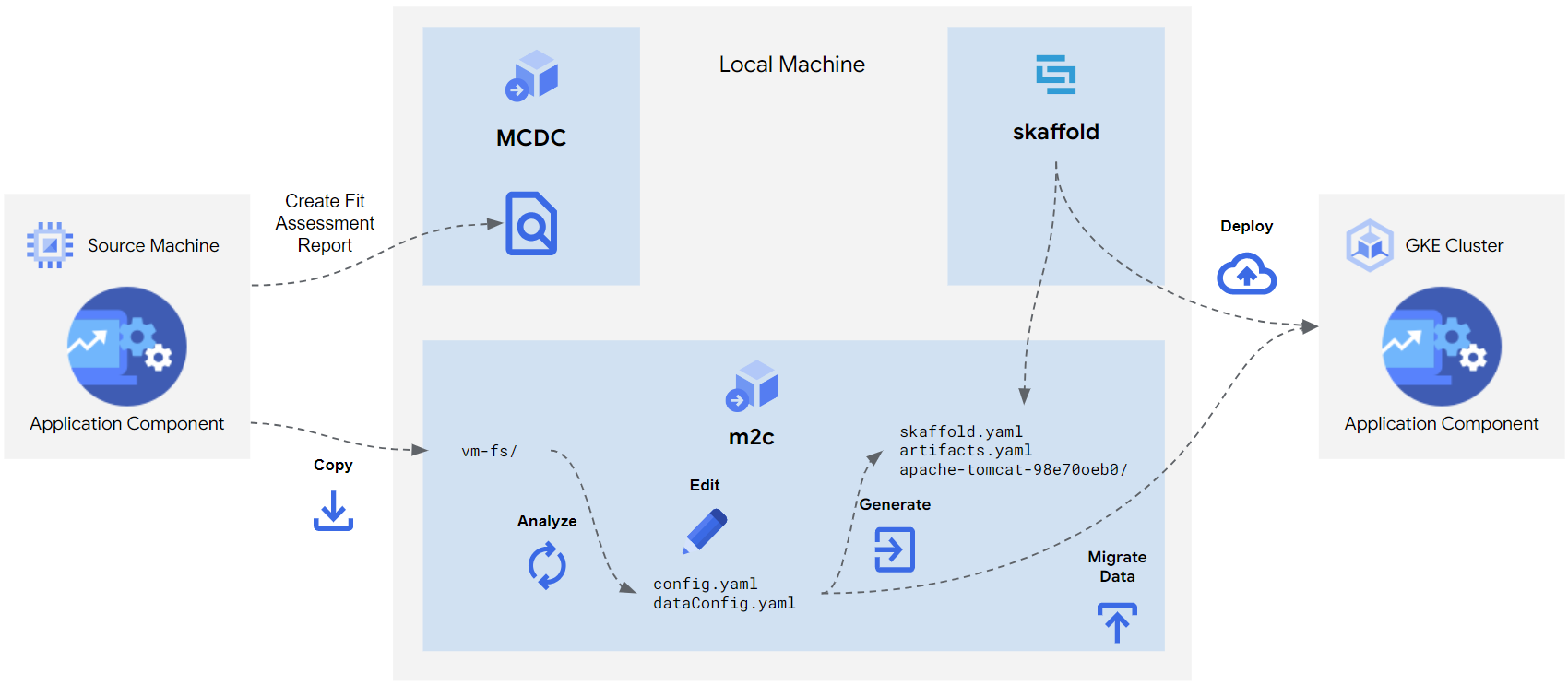
Transformation : la CLI Migrate to Containers est utilisée pour transformer un composant d'application basé sur une VM en composant d'application basé sur un conteneur prêt à être déployé. Cette opération se déroule en cinq phases :
- Copie : copiez le système de fichiers de la machine cible sur la machine locale.
- Analyse : analysez le système de fichiers pour créer un plan de migration.
- Modification : modifiez le plan pour adapter les sorties de migration en fonction de vos besoins.
- Génération : générez des artefacts tels que des fichiers Docker, des contextes Docker, des fichiers de déploiement Kubernetes et une configuration Skaffold.
- Migrer les données : copiez les fichiers de données dans des volumes persistants. Cette opération est facultative.
Déploiement des charges de travail : vous pouvez déployer les charges de travail de conteneurs migrés sur n'importe quel cluster GKE ou GKE Enterprise répondant aux exigences minimales. Les artefacts de migration peuvent inclure un ou plusieurs fichiers Dockerfile, une ou plusieurs spécifications de déploiement Kubernetes et un fichier de configuration Skaffold.
Maintenance : après avoir migré vos charges de travail de conteneurs, vous effectuez généralement des opérations d'optimisation et de maintenance. Le contenu de charge de travail extrait et le fichier Dockerfile généré peuvent être intégrés dans un pipeline CI/CD pour une maintenance efficace basée sur des images.
Étapes suivantes
- Découvrez comment examiner les systèmes d'exploitation, charges de travail et versions de Kubernetes compatibles.
- Découvrez comment découvrir, collecter et évaluer des VM VMware pour la migration.
- Découvrez comment migrer une VM.