Utiliser l'outil d'évaluation de l'adéquation
Migrate to Containers fournit un outil d'évaluation de l'adéquation qui s'exécute sur une charge de travail de VM pour déterminer si celle-ci est adaptée à la migration vers un conteneur. L'outil d'évaluation de l'adéquation vous fournit les éléments suivants :
- Possibilité d'obtenir les informations d'évaluation sur les VM VMware via une connexion directe à vCenter
- Rapport détaillé sur les règles d'évaluation applicables
- Un nouveau script de collecte et un nouvel outil d'évaluation,
mfit.
Le rapport d'évaluation généré décrit les problèmes à résoudre avant la migration, ainsi qu'une évaluation globale de l'adéquation des éléments suivants :
- Adéquation parfaite
- Bonne adéquation avec quelques résultats qui peuvent nécessiter votre attention
- Nombre minimal de tâches nécessaires avant la migration
- Nombre modéré de tâches nécessaires avant la migration
- Nombre important de tâches nécessaires avant la migration
- Inadéquation
- Données insuffisantes.
Consultez la section Opération d'évaluation pour découvrir comment l'outil détermine l'évaluation d'adéquation globale pour une VM.
Notes de version
Mises à jour de la version 1.11.1
- Corrections de bugs.
Mises à jour de la version 1.11.0
- Rapport récapitulatif : cette version inclut un nouveau type de rapport et une modification du comportement par défaut. Le nouveau rapport récapitulatif propose un aperçu de vos parcours de modernisation. De manière générale, le rapport trie vos parcours de modernisation en deux buckets distincts : faible effort et modernisation élevée. L'analyse de ces deux extrêmes, ainsi que des avantages et des efforts requis, devrait vous aider à prendre des décisions commerciales clés. En outre, le rapport inclut des sous-sections illustrant les limites techniques et pertinentes de la migration de VM (analyse de migration Lift and Shift), la refactorisation vers les conteneurs et la modernisation de VM sur site (via le changement ou l'association de VM aux clusters Anthos sur solution Bare Metal). Le type de rapport par défaut est le nouveau rapport récapitulatif. Dans les versions précédentes, le rapport par défaut était un rapport détaillé.
- Évaluez les charges de travail pour la migration vers Google Cloud VMware Engine : l'outil d'évaluation de l'adéquation a ajouté une nouvelle fonctionnalité d'évaluation pour évaluer les charges de travail pour la migration Lift and Shift vers Google Cloud VMware Engine.
Mises à jour de la version 1.10.0
L'outil d'évaluation de l'adéquation de la version 1.10.0 ajoute de nouvelles fonctionnalités, parmi lesquelles :
- Compatibilité avec l'évaluation Autopilot, Cloud Run et Compute Engine
- Règles Tomcat ajoutées pour l'évaluation de l'adéquation
- Possibilité d'acquérir des données vSphere à partir d'une exportation RVTools
- Vérification automatique des versions
- Configuration de l'outil d'évaluation d'adéquation
Fonctionnement de l'outil
L'outil d'évaluation de l'adéquation fonctionne en plusieurs phases distinctes :
Découverte et collecte des données : collectez des données concernant les VM à migrer. Vous pouvez collecter ces données de deux manières :
Découverte de données (VMware uniquement): exécutez l'outil
mfitpour effectuer une découverte d'inventaire:VMware : utilise l'API vSphere pour collecter des données sur les VM dans un vCenter. L'outil
mfitse connecte au vCenter distant à l'aide du nom d'utilisateur et du mot de passe transmis à l'outil.RVTools : si vous utilisez des outils RVTools pour créer des rapports sur votre vSphere, l'outil
mfitpeut importer le rapport XXXXX généré par RVTools.
La découverte vous permet de déterminer rapidement les caractéristiques des VM, telles que le type de système d'exploitation, l'espace de stockage, le nombre de cœurs et d'autres informations de base. Toutefois, pour une évaluation complète de l'adéquation, vous devez exécuter le script bash
mfit-linux-collect.shsur la VM.L'outil
mfitstocke les données d'évaluation et les informations de journal dans le répertoire~/.mfitde la machine hôte.Collecte : exécutez le script de collecte de données sur une VM à migrer afin de collecter les informations détaillées permettant de réaliser l'évaluation globale de l'adéquation de la VM avec la conteneurisation. Vous devez exécuter le script de collecte sur la VM pour pouvoir générer une évaluation complète de l'adéquation.
Le script collecte des données sur la VM et les écrit dans un fichier de sortie, un fichier tar (Linux) ou un fichier zip (Windows). Pour les VM Linux, une copie des données reste éventuellement sur le système de fichiers de la VM pour une utilisation ultérieure lors de la migration.
Vous pouvez exécuter le script localement sur la VM ou l'exécuter à distance à l'aide de
mfit. L'exécution à distance est compatible avecmfitpour les VM Linux et Windows déployées sur VMware et pour les VM Linux accessibles parmfitviassh.
Phase d'évaluation : Utilisez l'outil
mfitpour analyser les données de la phase de découverte et de collecte des données, appliquer un ensemble de règles et créer un score d'évaluation d'adéquation pour chaque VM évaluée.En règle générale, vous installez
mfitsur une seule machine Linux, puis importez les fichiers tar (Linux) ou zip (Windows) créés par les scripts de collecte sur cette machine pour évaluation.Phase de rapport : Utilisez l'outil
mfitpour produire un rapport détaillé décrivant l'évaluation pour chaque VM. Vous pouvez créer ce rapport sous forme de fichier HTML, JSON ou CSV.
Intégration à la migration de la charge de travail
Les données obtenues par l'outil d'évaluation de l'adéquation sur une VM source pendant la phase de collecte peuvent être utilisées par Migrate for Containers pour générer des parties du plan de migration pour la VM.
Par exemple, les données collectées par l'outil d'évaluation de l'adéquation utilisent des informations sur les points de terminaison de service exposés par une VM source. Par conséquent, si vous souhaitez renseigner automatiquement les informations sur les points de terminaison de service, vous devez exécuter l'outil sur une VM source. Pour en savoir plus, consultez la page Personnaliser les points de terminaison du service.
Parcours de modernisation
Le rapport d'évaluation d'adéquation utilise un parcours de description d'un ensemble de tâches de modernisation possibles. Les parcours courants définis dans l'outil sont les suivants:
- Aucune : aucun parcours de modernisation applicable n'est identifié pour la charge de travail.
- Shift | VM Compute Engine - Migrez une VM depuis VMware vers Compute Engine.
Shift | Google Cloud VMware Engine : migrez une VM depuis VMware vers Google Cloud VMware Engine.
Conteneuriser | Anthos et Google Kubernetes Engine - Migrez une VM ou une application sur une VM vers un conteneur s'exécutant avec des clusters Anthos ou sur GKE.
Conteneuriser | Google Kubernetes Engine Autopilot - Migrez une VM ou une application sur une VM vers Google Kubernetes Engine Autopilot.
Conteneuriser | Cloud Run : migrez une VM ou une application sur une VM vers Cloud Run.
Conteneuriser | Conteneur d'applications Tomcat - Migration des serveurs et applications Tomcat d'une VM vers un conteneur d'applications Pour plus d'informations sur la conteneurisation Tomcat, consultez la page Migrer des applications Tomcat.
Afficher le rapport d'évaluation de l'adéquation
Pour afficher le rapport détaillé généré par l'outil mfit, vous pouvez procéder comme suit :
Ouvrez le fichier HTML dans un navigateur. L'outil d'évaluation de l'adéquation fournit une sortie HTML améliorée qui facilite la visualisation des résultats de l'évaluation.
Importez le fichier JSON dans Google Cloud Console.
Importez le fichier CSV dans votre propre utilitaire de visualisation de données.
Afficher la sortie HTML détaillée
Ouvrez le fichier HTML dans un navigateur pour afficher le rapport. L'image suivante montre le rapport détaillé pour l'évaluation de 41 VM (seules les six premières lignes du tableau récapitulatif sont visibles) :

Où :
La première section contient des informations sur la personne qui a exécuté le rapport et quand.
Les sections Summary (Résumé), Journey Scores (Scores de transition) et OS Distributions (Distribution du système d'exploitation) vous donnent un aperçu général des résultats pour toutes les VM analysées.
La première ligne du tableau vous permet de spécifier des critères de recherche dans le rapport.
Le tableau contient une ligne pour chaque VM analysée et affiche :
- Nom de la VM : nom qui décrit le mieux la VM, en fonction de la source de la collection.
- ID de la VM de la plate-forme : identifiant de VM en fonction de la plate-forme. Sur vSphere, il s'agit du nom d'hôte vCenter et de MoRef. Sur AWS et Google Cloud, il s'agit de l'ID d'instance.
- Résultat d'adéquation : résultat d'adéquation pour un processus de modernisation recommandé. Cette valeur est déterminée par les résultats des règles testées en fonction du parcours de migration sélectionné. Ce champ définit le résultat qui nécessitera le plus d'efforts avant de pouvoir effectuer votre migration. Une adéquation excellente est le meilleur résultat, qui ne requiert aucun effort supplémentaire pour effectuer la migration.
- Parcours recommandé : parcours de modernisation recommandé selon la comparaison du score d'adéquation pour différents parcours ; choix du parcours ayant le meilleur score d'adéquation.
- Système d'exploitation : format long du nom du système d'exploitation.
- Type d'OS : système d'exploitation de la VM.
Développez chaque ligne du tableau pour afficher des informations sur une VM:
- Détection des informations telles que les applications, les ports d'écoute, les installations de disque, l'installation des outils invités et le chemin d'accès à la VM dans la console native de la plate-forme
- Une table des parcours évalués avec un résultat d'adéquation correspondant.
Développez chaque ligne du tableau des parcours évalués pour afficher la répartition des règles d'évaluation:
- Condition évaluée : condition technique testée sur la charge de travail de modernisation susceptible d'affecter un parcours de migration spécifique.
- ID de règle : identifiant unique d'une règle d'évaluation. Chaque règle vérifie une condition spécifique requise pour un parcours particulier.
- Résultat d'adéquation : valeur du résultat d'adéquation pour une règle d'évaluation spécifique. Cette valeur est déterminée par les efforts associés à la tâche recommandée nécessaires pour préparer la charge de travail pour la migration automatisée. Une adéquation excellente est le meilleur résultat, qui ne requiert aucun effort supplémentaire pour effectuer la migration.
- Récapitulatif : récapitulatif de la règle lorsque ses conditions sont remplies.
- Recommandations et résultats : modification recommandée pour permettre la migration automatisée et les résultats des données capturées par la découverte d'évaluation d'adéquation.
Importer le fichier JSON dans Google Cloud Console
Pour afficher le rapport dans Google Cloud Console, procédez comme suit :
Ouvrez la page "Migrate to Containers" dans la console Google Cloud.
Sélectionnez l'onglet Évaluation de l'adéquation.
Sélectionnez Parcourir, puis choisissez le fichier JSON à importer.
Sélectionnez Ouvrir pour afficher le rapport.
Celui-ci affiche les éléments suivants :
- Les champs Préparé par, Date d'évaluation et Outil d'évaluation de l'adéquation contiennent des informations récapitulatives sur le rapport.
- La zone Répartition du parcours de migration affiche les éléments suivants :
- Nombre total de VM analysées.
- Nombre de VM prêtes pour la migration ou mention Conteneuriser.
- Nombre de VM pas prêtes pour la migration.
- Une ligne pour chaque VM analysée, y compris une évaluation de l'adéquation de la VM.
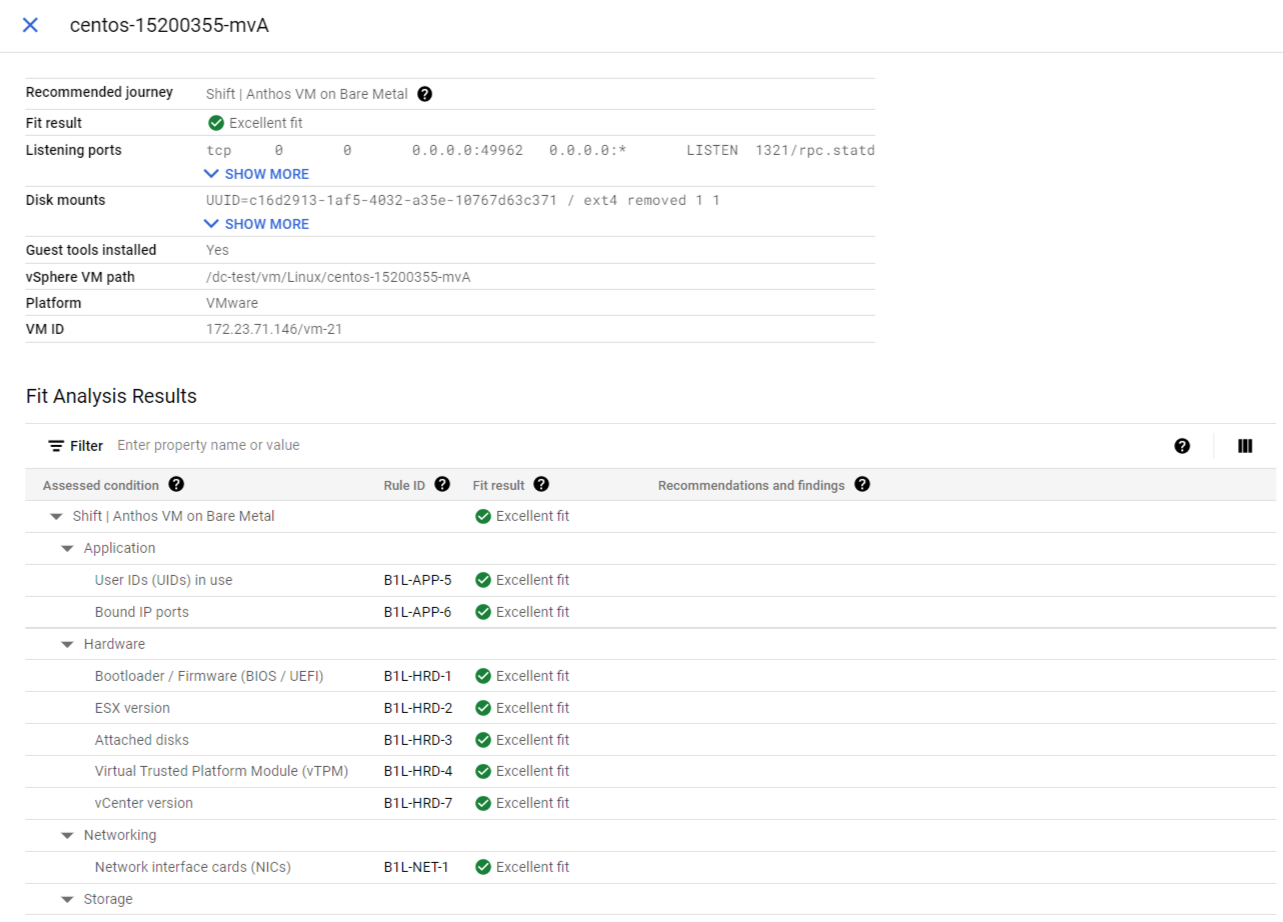
Dans le tableau VM évaluées, sélectionnez le nom d'une VM pour afficher ses détails, y compris des informations telles que les ports d'écoute, les points d'installation, les points d'installation NFS et d'autres informations.
Pour la VM sélectionnée, vous voyez également chaque description et ID de règle, ainsi que le résultat de l'application de la règle à la VM :
Installer l'outil d'évaluation de l'adéquation
Installez mfit et les scripts de collecte :
mfit : téléchargez l'outil
mfitsur une machine Linux centrale. Vous importez ensuite les données générées par les scripts de collecte sur cette machine pour les analyser.mfit-linux-collect.sh (Linux) : téléchargez le script de collecte sur une VM Linux pour effectuer la collecte des données.
mfit-windows-collect.ps1 (Windows) : téléchargez le script de collecte sur une VM Windows pour effectuer la collecte de données.
Au lieu de télécharger le script de collecte localement sur chaque VM, vous pouvez éventuellement utiliser l'outil mfit pour exécuter les scripts de collecte de données à distance.
Cette option est compatible avec les VM s'exécutant sur VMware ou avec les VM Linux qui autorisent une connexion ssh distante à partir de la machine hébergeant mfit.
Prérequis
Pour effectuer une évaluation de l'adéquation, vous devez remplir les conditions préalables suivantes :
mfitL'outil d'évaluation d'adéquation
mfits'exécute sur les versions 2.6.23 ou ultérieures du noyau Linux.Pour collecter des données à l'aide de VMware Discovery avec
mfit, procédez comme suit :La machine Linux exécutant
mfitdoit pouvoir se connecter à votre vCenter. Cela inclut l'ouverture de tous les ports nécessaires dans les règles de pare-feu et l'établissement d'une connectivité réseau entre la machine de collecte d'outils mFit et le serveur vCenter cible.La version du serveur vSphere vCenter doit être 5.5 ou ultérieure.
Le nom d'utilisateur transmis à l'outil doit disposer de droits d'accès en lecture sur une ou plusieurs VM. L'outil ne peut découvrir que les informations concernant les VM accessibles à l'utilisateur spécifié. Le privilège de lecture est généralement attribué à tous les rôles, à l'exception de
No Access.Le nom d'utilisateur transmis à l'outil doit disposer de droits de lecture sur l'hôte ESX. S'il existe plusieurs serveurs ESX, des droits de lecture sont requis pour chaque serveur ESX qui héberge une VM découverte.
L'utilisateur exécutant mFit doit disposer de privilèges de lecture, d'écriture et d'exécution sur la machine exécutant mFit.
Pour utiliser
mfitafin d'exécuter les scripts de collecte à distance pour des VM VMware :Vous devez disposer des autorisations décrites ci-dessus pour exécuter VMware Discovery.
Le nom d'utilisateur transmis à l'outil pour la connexion à vSphere doit disposer des droits suivants sur la VM :
Guest operation modifications,Guest operation program executionetGuest operation queries.Les identifiants utilisateur de VM utilisés par
mfitpour exécuter le script doivent disposer de droits d'administrateur sur la machine invitée cible pour la VM Windows.
Pour utiliser
mfitafin d'exécuter les scripts de collecte à distance à l'aide de SSH :- La machine Linux hébergeant
mfitdoit disposer d'un accèssshà la VM Linux source (les VM Windows ne sont pas compatibles).
- La machine Linux hébergeant
Scripts de collecte
mfit-linux-collect.sh(Linux) s'exécute sur toutes les versions de Linux.mfit-windows-collect.ps1(Windows) nécessite PowerShell 2.0 ou une version ultérieure (pas PowerShell Core), et une interface système avec GUI (pas Server Core) ou le framework .Net en version 4.5 ou ultérieure. Toutes les versions de Windows ultérieures ou égales à Windows 8 et Windows Server 2012 sont compatibles avec ces exigences, de même que la majorité des machines Windows 7 et Windows Server 2008r2.
Installation
Les procédures suivantes décrivent comment installer mfit et les scripts de collecte.
Pour installer mfit, procédez comme suit :
Créez un répertoire pour l'outil
mfitsur une VM Linux :mkdir m4a cd m4aTéléchargez l'outil d'évaluation et rendez-le exécutable :
curl -O "https://mfit-release.storage.googleapis.com/$(curl -s https://mfit-release.storage.googleapis.com/latest)/mfit" chmod +x mfitPour afficher les informations d'aide d'une commande
mfit, utilisez l'option--help. Exemple :./mfit --helpPour afficher l'aide d'une commande spécifique, utilisez l'option
--helpavec cette commande. Exemple :./mfit discover import --help
Pour installer mfit-linux-collect.sh, procédez comme suit :
Connectez-vous à la VM.
Créez un répertoire pour le script de collecte :
mkdir m4a cd m4aTéléchargez le script collecté sur la VM et rendez-le exécutable :
curl -O "https://mfit-release.storage.googleapis.com/$(curl -s https://mfit-release.storage.googleapis.com/latest)/mfit-linux-collect.sh" chmod +x mfit-linux-collect.sh
Pour installer mfit-windows-collect.ps1 :
Connectez-vous à votre VM.
Ouvrez PowerShell à l'aide de l'option Exécuter en tant qu'administrateur.
Créez un répertoire pour le script de collecte :
mkdir ~\m4a cd ~\m4aTéléchargez le script de collecte à l'aide de PowerShell:
$version = Invoke-WebRequest -UseBasicParsing https://mfit-release.storage.googleapis.com/latest $WebClient = New-Object System.Net.WebClient $WebClient.DownloadFile("https://mfit-release.storage.googleapis.com/"+$version+"/mfit-windows-collect.ps1", (Get-Location).Path + "\mfit-windows-collect.ps1")
Effectuer une évaluation
Effectuez une évaluation en réalisant toutes les phases d'évaluation suivantes :
Découvrir et collecter les données
Recueillir les données par :
Découverte (VMware uniquement): exécutez l'outil
mfitpour effectuer une découverte d'inventaire:VMware : utilise l'API vSphere pour collecter des données sur toutes les VM d'un vCenter visibles par l'utilisateur exécutant l'outil. L'outil
mfitse connecte à un vCenter distant à l'aide d'un nom d'utilisateur et d'un mot de passe transmis à l'outil. Ces identifiants sont requis avant de pouvoir exécuter l'évaluation.RVTools : l'outil d'évaluation d'adéquation est désormais compatible avec l'analyse des fichiers de rapport RVTools.xls à partir d'un seul VMware vCenter. Avec la source de données RVTools, vous pouvez générer des rapports d'évaluation d'adéquation détaillés basés sur vos exportations RVTools existantes en exécutant la commande suivante :
$./mfit discover rvtools name.xlsx.Collecte : exécutez le script de collecte de données sur une VM à migrer. Le script collecte des données sur la VM et les écrit dans un fichier tar (Linux) ou un fichier zip (Windows). Importez le fichier sur une machine centrale pour l'évaluer à l'aide de l'outil
mfit.Vous pouvez exécuter le script localement sur la VM ou l'exécuter à distance à l'aide de
mfit. L'exécution à distance est compatible avecmfitpour les VM Linux et Windows déployées sur VMware et pour les VM Linux accessibles parmfitviassh.
Dans les sections suivantes, nous décrivons comment effectuer une découverte (VMware uniquement) et comment exécuter les scripts de collecte :
- Effectuer une découverte (VMware uniquement)
- Limiter une découverte à un champ d'application
- Collecter les données à distance à l'aide des outils VMware
- Collecter les données à distance via SSH
- Collecter les données sur une VM Linux individuelle
- Collecter les données sur une VM Windows individuelle
Effectuer une découverte (VMware uniquement)
Accédez au répertoire
m4a:cd ~/m4aExécutez la commande suivante pour effectuer la découverte :
./mfit discover vsphere -u USERNAME --url https://VSPHERE_URLSaisissez le mot de passe vCenter lorsque vous y êtes invité.
Après avoir téléchargé et importé le fichier tar à l'aide de
mfit discover import, vous pouvez évaluer les données collectées, comme décrit ci-dessous.
Limiter une découverte à un champ d'application
Exécutez la commande suivante pour effectuer la découverte à la racine :
./mfit discover vsphere --url https://VSPHERE_URL -u USERNAME --path /
Exécutez la commande suivante pour effectuer la découverte dans un dossier spécifique :
./mfit discover vsphere --url https://VSPHERE_URL -u USERNAME --path datacenter/vm/folder
Exécutez la commande suivante pour effectuer la découverte sur un cluster spécifique :
./mfit discover vsphere --url https://VSPHERE_URL -u USERNAME --path datacenter/host/cluster
Exécutez la commande suivante pour effectuer la découverte dans un centre de données spécifique :
./mfit discover vsphere --url https://VSPHERE_URL -u USERNAME --path datacenter
Après avoir exécuté
mfit discover import, vous pourrez évaluer les données collectées, comme décrit dans la section suivante.
Collecter les données à distance à l'aide des outils VMware
Pour les VM hébergées sur vSphere, mfit peut utiliser les outils VMware pour déployer et exécuter les scripts de collecte à distance sur des VM Linux et Windows. Lorsque vous utilisez les outils VMware, l'outil mfit :
- importe le script de collecte sur la VM ;
- exécute le script sur la VM ;
- télécharge et importe les résultats.
Vous avez besoin de deux jeux d'identifiants pour collecter les données à distance :
Le nom d'utilisateur du serveur vCenter, transmis à l'outil pour la connexion à vSphere, doit disposer des droits suivants sur la VM :
Guest operation modifications,Guest operation program executionetGuest operation queries.Identifiants utilisateur pour la VM :
- Sous Windows, vous devez disposer des droits d'administrateur.
- Sous Linux, l'accès racine n'est pas nécessaire, mais il garantit que mfit peut collecter toutes les données d'évaluation d'adéquation.
Pour collecter des données à l'aide des outils VMware :
Connectez-vous à votre VM Linux hébergeant
mfit.Accédez au répertoire
m4a:cd ~/m4a
Assurez-vous que la VM est sous tension et transmettez l'utilisateur du serveur vCenter, les identifiants de l'utilisateur de VM et le VM_ID (le nom de la VM ou MOREF) à la commande :
mfit discover vsphere guest --url https://VSPHERE_URL \ -u VCENTER_USER --vm-user VM_USER VM_ID
Vous êtes invité à saisir les mots de passe des utilisateurs VCENTER_USER et VM_USER.
Si votre cluster vSphere comporte plusieurs centres de données, vous devez utiliser l'option
--dcpour spécifier le nom du centre de données :mfit discover vsphere guest --url https://VSPHERE_URL --dc DATACENTER_NAME \ -u VCENTER_USER --vm-user VM_USER VM_ID
Collecter les données à distance via SSH
Si la machine Linux hébergeant mfit dispose d'un accès ssh à la VM Linux source (les VM Windows ne sont pas compatibles), mfit peut se connecter à la VM distante via ssh pour collecter des données.
Lorsque vous utilisez ssh, l'outil mfit :
- importe le script de collecte sur la VM ;
- exécute le script sur la VM avec les identifiants utilisateur de la VM transmis à
mfit. Bien que les identifiants utilisateur de la VM ne nécessitent pas d'accès root, disposer d'un accès root garantit quemfitpourra collecter toutes les données d'évaluation de l'adéquation ; - télécharge et importe les résultats.
Vous pouvez utiliser l'un des deux modes suivants pour exécuter ssh :
Natif (par défaut) : utilise le binaire
sshet les configurations de la machinemfit. Le mode natif peut utiliser les fichiers de configuration SSH locaux par défaut, tels que~/.ssh/configet~/.ssh/known_hosts, du poste de travail qui l'héberge.Saisissez le mot de passe lorsque vous y êtes invité, ou utilisez sshpass pour transmettre le mot de passe ou la phrase secrète du fichier de clé privée sur la ligne de commande. Exemple :
sshpass -p password mfit discover ssh IP-ADDRESSIntégré : utilise la bibliothèque
sshintégrée. Ce mode vous permet d'utiliser le clientsshintégré si le mode natif cesse de fonctionner dans votre environnement. Toutefois, il n'utilise pas les fichiers de configuration SSH locaux par défaut. Vous pouvez utiliser l'option-ipour spécifier un fichier de clé privée SSH.
Pour collecter des données via ssh, procédez comme suit :
Connectez-vous à la VM Linux hébergeant
mfit.Accédez au répertoire
m4a:cd ~/m4a
Exécutez
mfit:Utilisez le mode natif (par défaut) pour collecter les données :
mfit discover ssh VM_IP_HOSTNAME
Le fichier de clé privée SSH de l'utilisateur appelant
mfitest utilisé pour l'authentification SSH.Lorsque vous y êtes invité, saisissez le nom d'utilisateur d'un compte sur la VM Linux. Le script de collecte s'exécute en utilisant ces identifiants. Vous êtes également invité à saisir un mot de passe si la clé privée SSH de l'utilisateur appelant
mfitne parvient pas à s'authentifier auprès de la VM avec le nom d'utilisateur.Spécifiez l'utilisateur de la VM en mode natif :
mfit discover ssh -u USER VM_IP_HOSTNAME
Saisissez le mot de passe de l'utilisateur lorsque vous y êtes invité.
Utilisez l'option
-vpour spécifier le mode détaillé :mfit discover ssh -u USER -v VM_IP_HOSTNAME
Utilisez l'option
-ipour spécifier le fichier de clé privée SSH. Par exemple, pour spécifier.ssh/my_private_key, procédez comme suit :mfit discover ssh -i ~/.ssh/my_private_key -u USER VM_IP_HOSTNAME
Utilisez le mode intégré pour spécifier le mot de passe sur la ligne de commande :
mfit discover ssh --ssh-client embedded -u USER --password PASSWORD VM_IP_HOSTNAME
Comme la forme intégrée de la commande n'utilise pas les fichiers de configuration SSH locaux par défaut, l'utilisateur USER spécifié dans la commande doit pouvoir accéder à la VM via
sshet disposer de privilèges sur la VM lui permettant d'exécuter le script de collecte.Utilisez l'option
-ien mode intégré :mfit discover ssh --ssh-client embedded -i ~/.ssh/id_rsa -u USER --password PASSWORD VM_IP_HOSTNAME
La commande
mfitvous permet de spécifier la plupart des optionsssh. Ces options sont ensuite transmises à la commandesshà l'aide de l'option-a/--ssh-args. Par exemple, pour utiliser un proxy socks :mfit discover ssh -u USER \ -a '-o' -a 'ProxyCommand=nc -X 5 -x 127.0.0.1:proxy port %h %p' VM_IP_HOSTNAME
Collecter les données sur une VM Linux individuelle
Vous pouvez exécuter le script mfit-linux-collect sur une VM pour collecter des données sur cette VM.
Vous pouvez ensuite l'importer en téléchargeant le fichier tar sur la machine sur laquelle mfit est installé et en exécutant mfit discover import path-to-tar. Vous exécutez généralement le script en spécifiant l'option sudo. Vous pouvez éventuellement exécuter le script en utilisant les droits de l'utilisateur qui exécute l'outil. Cependant, le script pourrait ne pas être en mesure de collecter toutes les données d'évaluation.
Connectez-vous à votre VM.
Accédez au répertoire
m4a:cd ~/m4a
Exécutez le script de collecte sur la VM :
sudo ./mfit-linux-collect.sh
Le script génère un fichier tar nommé
m4a-collect-MACHINE_NAME-TIMESTAMP.tardans le répertoire actuel et dans/var/m4a/m4a-collect-TIMESTAMP.tar. L'horodatage est au formatYYYY-MM-DD-hh-mm. Pour obtenir une description du format de fichier tar, consultez la section Opération de collecte de script.Vous pouvez transmettre les arguments facultatifs au script :
--userpour exécuter ce script en utilisant les privilèges de l'utilisateur qui exécute l'outil (n'incluez passudosi vous utilisez cette option). L'exécution avec--usersignifie que certaines données nécessitant un accèssudopeuvent ne pas être collectées, ce qui peut réduire la qualité de l'évaluation de l'adéquation.--readonlypour ne pas écrire la sortie dans/var/m4a/m4a-collect-TIMESTAMP.tar. Notez que certaines fonctionnalités de Migrate to Containers s'appuient sur ces informations. Pour en savoir plus, consultez la page Intégration à la migration de la charge de travail.--output: pour enregistrer le fichier tar sous le chemin spécifié.
Vous pouvez maintenant évaluer les données collectées, comme décrit ci-dessous.
Collecter les données sur une VM Windows individuelle
Connectez-vous à votre VM.
Ouvrez PowerShell à l'aide de l'option Exécuter en tant qu'administrateur.
Accédez au répertoire
m4a:cd ~/m4a
Exécutez le script de collecte sur la VM :
powershell -ExecutionPolicy ByPass -File .\mfit-windows-collect.ps1
Le script génère un fichier zip nommé
m4a-collect-MACHINE_NAME-TIMESTAMP.zipvers le répertoire actuel. Incluez un chemin de sortie pour spécifier un emplacement différent :.\mfit-windows-collect.ps1 \path\to\output\file.zip
Vous pouvez maintenant évaluer les données collectées, comme décrit ci-dessous.
Évaluer les données collectées
Pour effectuer une évaluation, exécutez mfit sur les données collectées lors de la phase de collecte.
Pour effectuer une évaluation :
Effectuez l'évaluation :
./mfit assess
La plate-forme cible
GCPest évaluée par défaut.Spécifiez
target-platform../mfit assess --target-platform TARGET-PLATFORM
Les options disponibles sont les suivantes: gcp, anthos, anthosbm et all. Chaque option spécifie un ensemble différent de parcours à évaluer:
gcpévalue les parcours de migration vers Compute Engine, Google Cloud VMware Engine et de conteneurisation vers Google Kubernetes Engine, Google Kubernetes Engine Autopilot et Cloud Run.anthosévalue les parcours de transition et d'associer les parcours d'Anthos sur solution Bare Metal et de la conteneurisation à Google Kubernetes Engine et Cloud Run.anthosbmest équivalent àanthos.allévalue tous les parcours possibles.
Consultez une sélection détaillée de parcours par plate-forme cible:
Nom du parcours Compute Engine Anthos/Anthos sur solution Bare Metal All Shift | VM Compute Engine Incluses Exclues Incluses Shift | Google Cloud VMware Engine Incluses Exclues Incluses Shift | VM Anthos sur solution Bare Metal Exclues Incluses Incluses Associer | VM Anthos sur solution Bare Metal Exclues Incluses Incluses Conteneuriser | Anthos et GKE Incluses Incluses Incluses Conteneuriser | Autopilot Incluses Exclues Incluses Conteneuriser | Cloud Run Incluses Incluses Incluses Conteneuriser | Conteneur d'applications Tomcat Incluses Incluses Incluses Vous pouvez maintenant générer un rapport pour afficher les résultats de l'évaluation.
Générer un rapport
Utilisez l'outil mfit pour générer un rapport récapitulatif ou détaillé. Un rapport récapitulatif est généré par défaut. Pour exécuter un rapport détaillé, ajoutez l'option --full. Vous pouvez générer le rapport au format HTML, JSON ou CSV.
Pour exécuter un rapport :
Accédez au répertoire
m4a:cd ~/m4aPour générer un rapport HTML de l'évaluation, procédez comme suit :
Exécutez la commande suivante :
./mfit report --format html > REPORT_NAME.htmlVous pouvez également exécuter la commande suivante pour obtenir un rapport détaillé :
./mfit report --format html --full > REPORT_NAME.htmlL'outil génère dans le répertoire actuel un fichier HTML nommé REPORT_NAME.html.
Ouvrez REPORT_NAME.html dans un navigateur pour afficher le rapport. Pour obtenir une description du format de fichier du rapport détaillé, consultez la section Contenu du rapport.
Pour générer un rapport JSON de l'évaluation :
Exécutez la commande suivante :
./mfit report --format json > REPORT_NAME.jsonL'outil génère un fichier JSON nommé REPORT_NAME.json dans le répertoire actuel.
Importez le fichier JSON dans Google Cloud Console.
Les fichiers de sortie contiennent des informations sur l'évaluation, y compris l'évaluation d'adéquation. Pour en savoir plus, consultez Contenu du rapport.
Pour générer un rapport d'évaluation au format CSV :
Exécutez la commande suivante :
./mfit report --format csv > REPORT_NAME.csvL'outil génère un fichier CSV nommé REPORT_NAME.csv dans le répertoire actuel.
Importez le rapport CSV dans votre outil de visualisation de données.
Les fichiers de sortie contiennent des informations sur l'évaluation, y compris l'évaluation d'adéquation. Pour en savoir plus, consultez Contenu du rapport.
Fonctionnement du script de collecte
Le script de collecte exécute une série de commandes Linux pour collecter des informations sur la VM source, ainsi que des informations provenant de plusieurs fichiers sur cette VM.
Les sections suivantes décrivent l'opération du script. Vous pouvez également examiner le script dans un éditeur de texte pour afficher des informations plus détaillées.
Commandes de script
Le script exécute les commandes Linux suivantes :
| Commande | Description |
|---|---|
netstat -tlnp |
Répertorie tous les ports d'écoute actifs. |
ps -o pid,user,%mem,comm,args -e |
Répertorie tous les processus utilisateur en cours d'exécution. |
dpkg -l |
Répertorie les packages installés (basés sur Debian). |
rpm -qa |
Répertorie les packages installés (basés sur rpm). |
sestatus |
Obtient l'état SELinux. |
lsmod |
Obtient les modules du noyau chargés. |
systemctl |
Répertorie les services en cours d'exécution (basés sur Systemd). |
service --status-all |
Répertorie les services en cours d'exécution (basés sur Init.d/Upstart) |
lsof /dev / |
Répertorie les handles ouverts vers des fichiers et des appareils périphériques |
docker ps |
Répertorie les conteneurs Docker en cours d'exécution. |
ip addr |
Répertorie les adresses IP attribuées aux cartes d'interface réseau |
ifconfig |
Affiche les configurations des cartes d'interface réseau et les adresses IP attribuées |
blkid |
Répertorie les attributs des appareils de stockage en mode bloc |
lsblk --json -p --output NAME,PARTFLAGS,PARTTYPE,UUID,LABEL,FSTYPE" |
Répertorie les appareils de stockage en mode bloc |
Fichiers collectés
Le script copie les fichiers suivants dans le fichier tar généré :
| Chemin | Description |
|---|---|
/etc/fstab |
Liste des montages à installer au démarrage |
/etc/hosts
|
Alias d'hôtes et de données DNS |
/etc/issue
|
Nom de la distribution Linux |
/etc/network/interfaces
|
Interfaces configurées |
/proc/cpuinfo |
Informations sur le processeur |
/proc/meminfo |
Utilisation/total de la mémoire actuelle sur la VM |
/proc/self/mounts |
Appareils actuellement installés |
/etc/exports |
Liste des exportations NFS |
/opt/IBM/WebSphere/AppServer/properties/version/installed.xml |
Version de WebSphere (lorsqu'il est installé par défaut) |
/opt/IBM/WebSphere/AppServer/properties/version/WAS.product |
Informations sur WebSphere (lorsqu'il est installé par défaut) |
/sys/class/net/* |
Informations sur la carte d'interface réseau |
Répertoires examinés
Le script recherche les répertoires suivants jusqu'à une profondeur de deux afin de localiser les répertoires des utilitaires et logiciels installés :
/opt//usr/share//etc//usr/sbin//usr/local/bin/
Collecter le format du fichier tar
Le script m4a-fit-collect.sh génère un fichier tar nommé m4a-collect-machinename-timestamp.tar dans le répertoire actuel et dans /var/m4a/m4a-collect-timestamp.tar.
Bien que cela ne soit pas obligatoire, vous pouvez éventuellement développer le fichier tar à l'aide de la commande suivante :
tar xvf m4a-collect-machinename-timestamp.tar
Le fichier tar a le format suivant :
collect.log # Log output of the script files # Directory containing files with their full path from root. For example: |- etc/fstab |- etc/hostname |- etc/network/interfaces |- ... commands # Output of commands run by the script: |- dpkg |- netstat |- ps |- ... found_paths # Text file with the list of installation directories machinename # Text file with machine name ostype # Text file with operating system type (Linux) timestamp # Text file with collection timestamp version # Text file with version number of the script
Réaliser une évaluation rapide
Les artefacts créés par le script de collecte peuvent être utilisés pour effectuer une évaluation rapide.
Pour effectuer une évaluation rapide :
Accédez au répertoire
m4a:cd ~/m4a
Effectuez l'évaluation :
./mfit assess sample /path/to/mfit-linux-collect-results.tar
Cela revient à exécuter les commandes suivantes sur une base de données temporaire :
./mfit discover import /path/to/mfit-linux-collect-results.tar --db /tmp/db ./mfit assess --db /tmp/db ./mfit report --db /tmp/db
Examinez le rapport généré.
Pour obtenir une description de chaque règle, consultez la section Ajuster les règles d'évaluation.
Vérification automatique des versions
Par défaut, l'outil d'évaluation de l'adéquation effectue un contrôle des versions. Pour que la vérification de version fonctionne, une connexion Internet est requise. Lorsque mfit est exécutée et qu'une nouvelle version est disponible, un message d'alerte s'affiche.
Si un proxy est nécessaire pour accéder à Internet, définissez-le en exécutant la commande suivante:
mfit config set proxy PROXY
Pour désactiver la vérification automatique des versions, définissez l'option disable_version_checking:
mfit config set disable_version_checking true
Configurations de l'outil d'évaluation d'adéquation
L'outil d'évaluation d'adéquation possède des propriétés de configuration, qui peuvent être gérées à l'aide de la commande "config".
Pour imprimer toutes les propriétés de configuration et leurs valeurs, exécutez la commande:
mfit config list
Pour imprimer la valeur d'une propriété de configuration:
mfit config get proxy
Pour définir une propriété de configuration, procédez comme suit:
mfit config set proxy PROXY
Pour rétablir la valeur par défaut d'une propriété de configuration:
mfit config unset proxy