Google Cloud Managed Service for Apache Kafka is a Google Cloud service that helps you run Apache Kafka. Managed Service for Apache Kafka lets you focus on building event-driven systems and streaming data pipeline, rather than managing the infrastructure.
For more information about Apache Kafka, see the Apache Kafka website.
Why choose Managed Service for Apache Kafka?
Managed Service for Apache Kafka helps run a secure, highly available Apache Kafka cluster on Google Cloud. You can migrate existing Kafka applications to Google Cloud as well as develop new ones. Managed Service for Apache Kafka offers the following features:
Runs open source Apache Kafka compatible with your existing deployments.
Automates cluster management, scaling, upgrades, and maintenance, reducing operational overhead and letting you focus on your applications.
Integrates with other Google Cloud services, such as Cloud Monitoring, BigQuery, Dataflow, and Cloud Logging to simplify data pipelines.
Manages multiple clusters using a centralized management API.
Simplifies cluster scaling by requiring you to only specify total cluster vCPU count and RAM volume. Storage and broker sizing are managed automatically.
Sets up secure cross-project and cross-VPC connections to clusters.
Without Managed Service for Apache Kafka, you'd need to manage all these aspects manually, using environments such as Google Kubernetes Engine(GKE), which requires significant time and expertise. Managed Service for Apache Kafka simplifies the process, letting you focus on your core applications.
Managed Service for Apache Kafka architecture
The Managed Service for Apache Kafka service helps set up and run an Apache Kafka cluster on the Google Cloud platform. This section discusses some important terms associated with Managed Service for Apache Kafka.
A Managed Service for Apache Kafka cluster is a managed set of brokers that is useful for implementing queues and publish-subscribe messaging.
A broker is the core server responsible for handling message streams and client interactions.
A message can represent any serializable data. Examples of messages include a database record, a system log entry, or an application event.
A topic is a named collection of messages that are divided among partitions.
Each partition is an ordered log of a subset of those messages. Messages in a partition are immutable. Newer messages are appended to the topic partition as they are published.
Producers are applications that create messages and send these messages to the Managed Service for Apache Kafka cluster.
Consumers are applications that read those messages.
A consumer group is a way to organize multiple consumer application instances to read messages from a topic. It ensures each message is processed only once within the group by assigning partitions to specific consumers and tracking their progress. When consumer instances join or leave, the group rebalances, redistributing partition assignments to maintain efficient and reliable message consumption.
The following image is an architectural representation of how messages flow in the Managed Service for Apache Kafka service. In this example, a single producer application publishes messages 1 and 2 to the Managed Service for Apache Kafka cluster. Decoupled from the producer application, two consumer applications consume these messages from the Managed Service for Apache Kafka cluster.
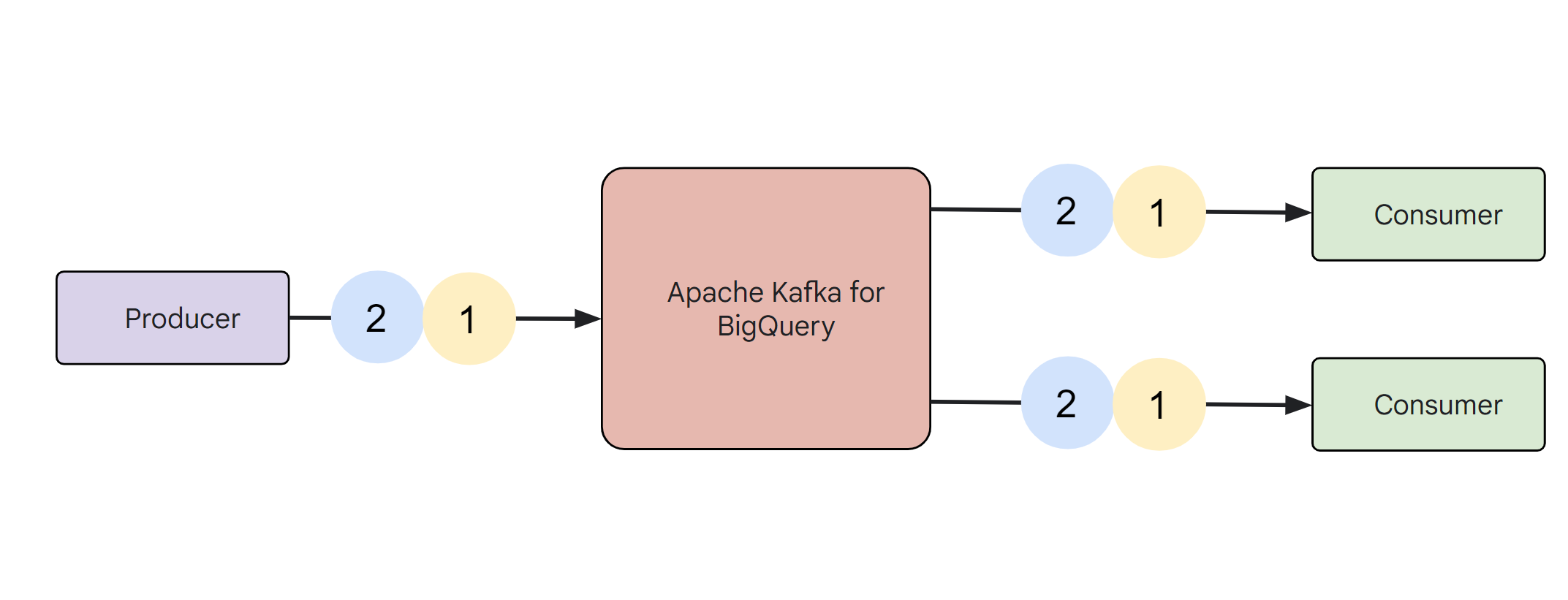
A producer application is typically a part of a larger application, such as a web frontend, that emits its log activity to Managed Service for Apache Kafka. It can also be an independent service that retrieves data from one system and sends it to Managed Service for Apache Kafka. This is a common arrangement in change data capture from databases.
Consumer applications can receive these messages with low latency, as they are published. Examples of consumer applications include streaming data pipelines that send application log data to BigQuery or a data lake. These applications can also take action on the data, rather than just storing it. Multiple consumer applications can read the same messages from the Managed Service for Apache Kafka cluster. This relieves the producer application of the responsibility of managing individual integrations with the consumer applications.
Each consumer application receives the same set of messages in the same order. You can add new consumer applications and shut down existing ones without any coordination with the producer application.
Managed Service for Apache Kafka features
Managed Service for Apache Kafka provides instances of open source Apache Kafka. Generally, you would expect it to work as any other Kafka installation. However, Managed Service for Apache Kafka handles several aspects of the cluster for you including scaling and storage and you don't have the ability to alter these broker-level configurations. This section discuss some important Managed Service for Apache Kafka features.
Scaling and provisioning model
The performance and rate at which an Apache Kafka cluster can process messages is determined by the number of virtual machines and the size of each machine. A broker typically maps to a single virtual machine. The virtual machine size is determined by the number of vCPUs, the amount of RAM it has, and the type and size of disks attached to the machine.
Managed Service for Apache Kafka simplifies this model, exposing only a notion of the number of vCPUs and amount of RAM needed for the entire cluster. Managed Service for Apache Kafka automatically determines the broker shape for you. You only must specify the total vCPU count and RAM size across all the brokers. Storage and machine size are configured automatically.
The open source Apache Kafka cluster requires you to provision and scale the number of brokers for the cluster. Additionally, you are also required to manage the vCPU, RAM and storage size for each individual broker.
However, as a user of Managed Service for Apache Kafka, your main focus is on monitoring the cluster's overall vCPU and RAM usage. Simply adjust these resources as needed for optimal performance. Managed Service for Apache Kafka manages the disk size for brokers.
The system automatically handles broker creation and management. In most cases, you don't need to worry about individual broker sizes.
One exception is when downscaling large clusters. Always ensure each broker in
every zone retains at least one vCPU. When you increase vCPUs, existing brokers
are scaled up accordingly. To know more about the number of brokers
in your cluster, run the open source kafka-metadata-shell.sh command.
Each broker has a maximum limit of 15 vCPUs. After this limit is reached, a new broker is automatically created.
Uneven load distribution across partitions can overload individual brokers. If this happens, rebalance partitions within Managed Service for Apache Kafka or adjust how your producers assign keys for a more balanced distribution.
For more information about how to rebalance a cluster, see Edit a cluster.
Replication and availability
Managed Service for Apache Kafka supports only high availability configurations. Each cluster is distributed across three availability zones in a region and can withstand a failure of a single zone. By default, all topics are configured to have three replicas. You can, however, override the configuration for specific topics to have fewer replicas.
You cannot choose specific zones where brokers are located.
Networking and tenant projects
When you create a Managed Service for Apache Kafka cluster, it's not directly deployed in your project. Instead, Google Cloud automatically creates a dedicated tenant project. This tenant project hosts all the clusters that you create within your project. A tenant project offers isolation and security for your cluster resources from other users' cluster resources. Each tenant project has its own set of permissions and access controls.
To access the Managed Service for Apache Kafka, you must specify one or more Virtual Private Cloud (VPC) networks in projects within your organization. These VPC networks can be in the same project as the Managed Service for Apache Kafka cluster, or a different project. Managed Service for Apache Kafka automatically creates Private Service Connect (PSC) endpoints within your VPC networks that connect to the Kafka brokers running within the tenant project. These endpoints have local IP addresses within your VPC network, making it appear as if the Kafka brokers are running within your network.
The following image shows three projects, project 0, project 1t, and project 2, each with its own VPC and subnet.
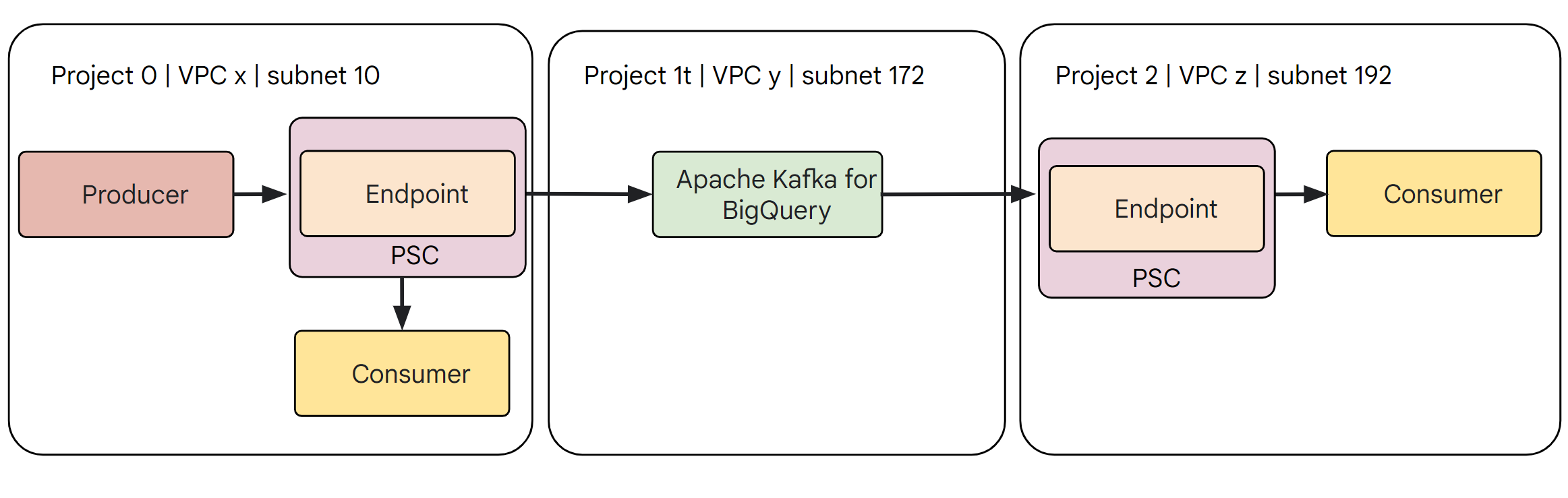
Project 0 is the project that you own or create, where you specify the Managed Service for Apache Kafka cluster. In the backend, the Managed Service for Apache Kafka cluster is actually created in a tenant project 1t. The VPC network in project 2 can connect to the Managed Service for Apache Kafka cluster. Additionally, the image shows how producers and consumers connect to the Managed Service for Apache Kafka cluster through their respective endpoints.
For more information, see the following:
Administrative APIs and other Google Cloud interfaces
You can manage Managed Service for Apache Kafka clusters using Apache Kafka APIs and tools or Google Cloud interfaces. Some tasks can be accomplished with only one or the other set of interfaces and some tools or interfaces are more convenient for your situation.
Manage your cluster using Managed Service for Apache Kafka APIs. After the cluster is up and running, you can use all the standard open source Apache Kafka APIs and tools. Managed Service for Apache Kafka APIs also provide some additional management features.
For example, you can use the bin/kafka-topics.sh command line tool to
create topics in the Managed Service for Apache Kafka cluster. You
can, however, choose to do the same with the Google Cloud CLI,
Google Cloud console, or a Terraform configuration.
To use the Apache Kafka CLI, ensure that the machine where the CLI client runs has access to the VPC network that is granted access to the Managed Service for Apache Kafka cluster. One way to configure this is to set up a bastion host. Bastion hosts provide an external facing point of entry into a network containing private network instances. Another method is to run the clients on a virtual machine within the same project and VPC network that is granted access to the Managed Service for Apache Kafka cluster.
In addition to the standard Apache Kafka tools, Managed Service for Apache Kafka service also offers Managed Service for Apache Kafka APIs for managing topics and consumer groups within a cluster. These APIs come with clients that include the Google Cloud console, gcloud CLI, and client libraries that support multiple languages, including Terraform. The advantage of using these APIs is that they provide a secure access model that is consistent with all other Managed Service for Apache Kafka resources.
Not all Apache Kafka features are available through Managed Service for Apache Kafka APIs. An example is the ability to create authorization rules specific to a single topic. The Managed Service for Apache Kafka APIs authorization works only at the cluster level.
The following figure shows how different tools and APIs, both from open source and Managed Service for Apache Kafka are used to configure a Managed Service for Apache Kafka cluster.
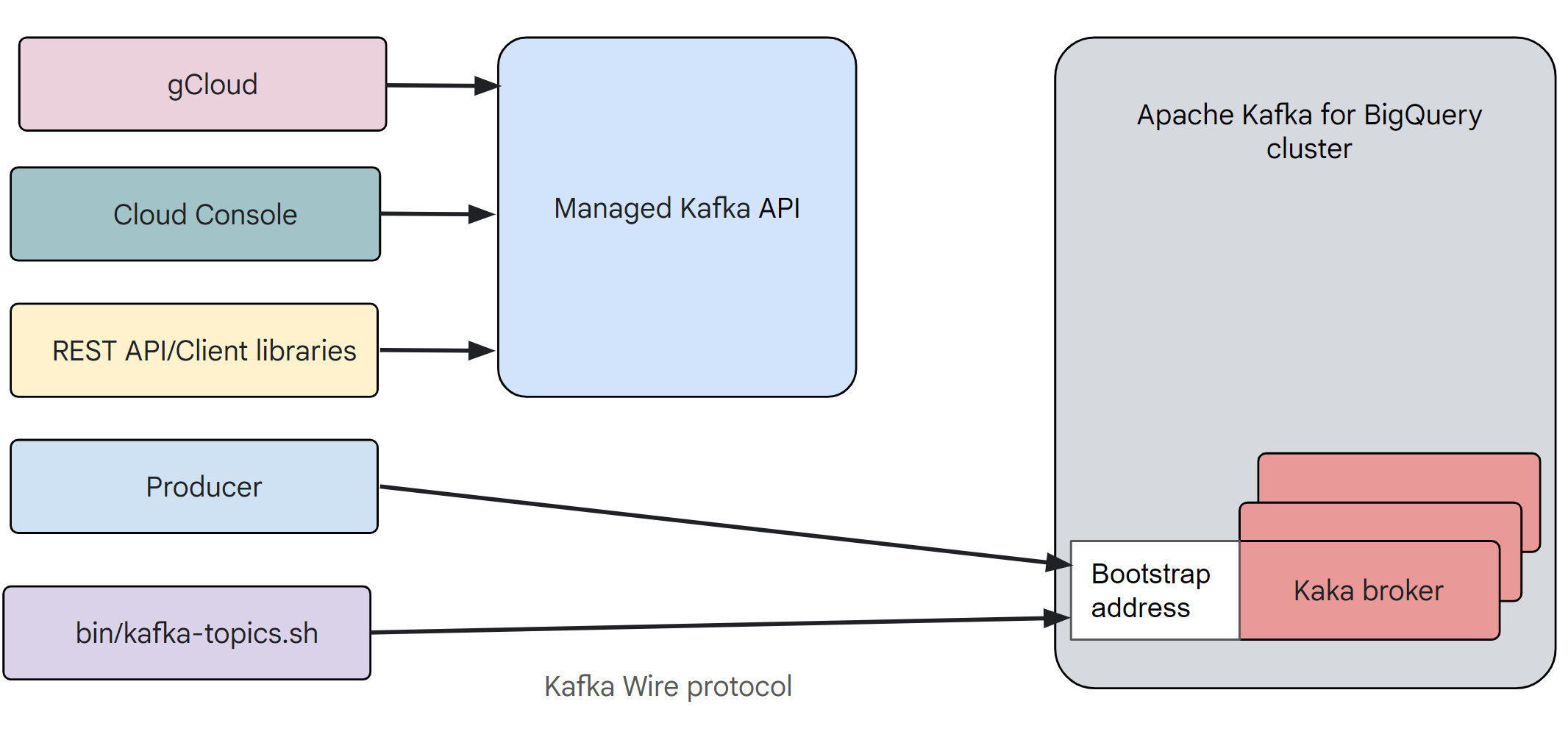
As shown in the figure, gcloud CLI, the Google Cloud console, the REST APIs and the client libraries all use the Managed Service for Apache Kafka API at the backend to configure a Managed Service for Apache Kafka cluster.
Authentication and authorization
You can use the open source Apache Kafka APIs or the Managed Service for Apache Kafka API for resource management within Managed Service for Apache Kafka clusters. Both APIs have different requirements for authentication and authorization.
Managed Service for Apache Kafka API
Calls made through the Managed Kafka API are authorized just as any other Google Cloud API request. If you use the Managed Kafka API to manage the cluster, then you are using IAM permissions.
For more information on how to use the Managed Kafka API, see Authenticate to the Managed Kafka API.
The following image shows how the Managed Kafka API lets applications interact with a Managed Service for Apache Kafka cluster by using Google Cloud tools and APIs.
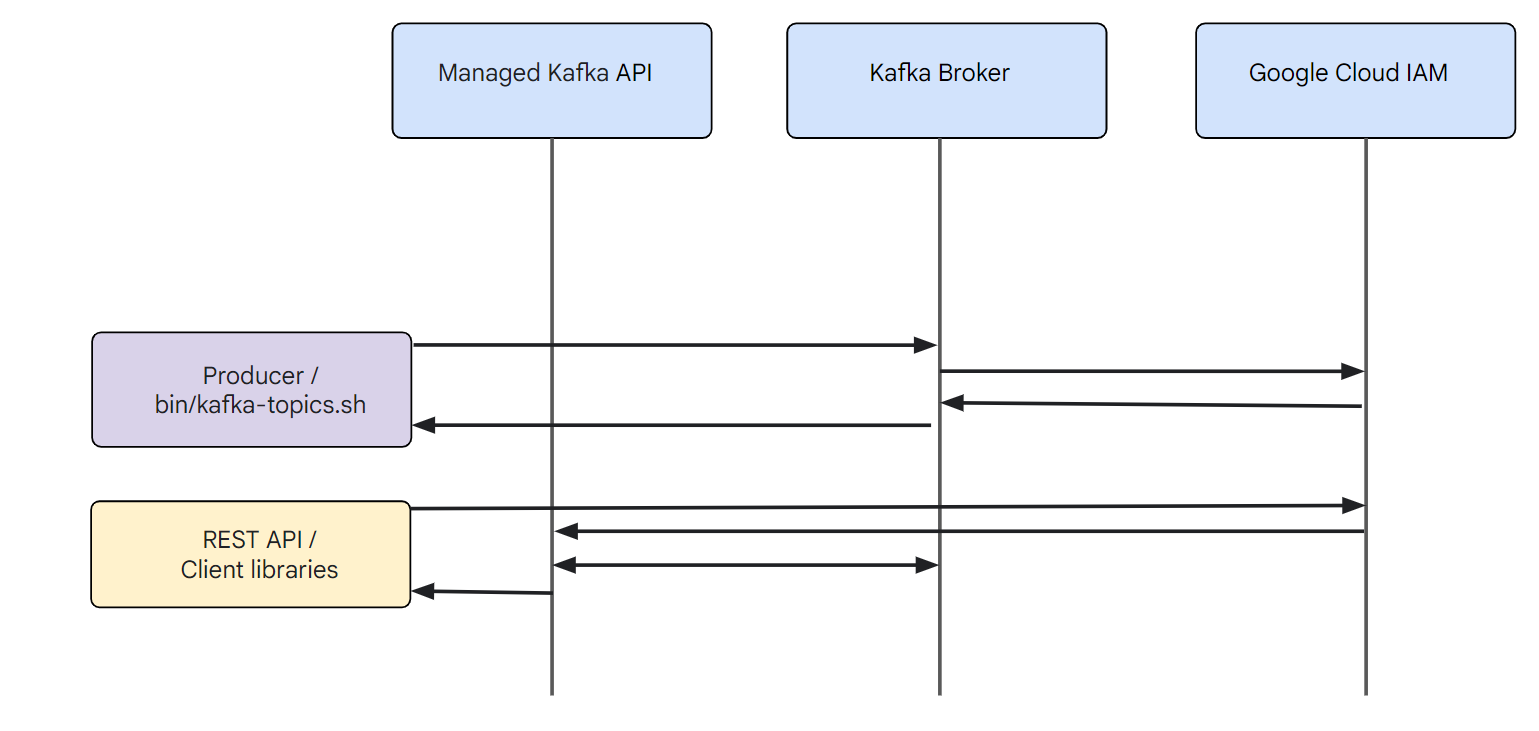
Open source Apache Kafka API
Applications that directly communicate with the
Managed Service for Apache Kafka brokers using open source Apache Kafka APIs must communicate
over TLS using the credentials of a user-managed service account that has the
role roles/managedkafka.client on
the cluster. At the start of each client-broker TCP connection,
Kafka brokers running in Managed Service for Apache Kafka rely on IAM
to authenticate and authorize the client connection.
For more information about these TCP connections, see the documentation about the Kafka Wire protocol.
For a Managed Service for Apache Kafka client that uses an Apache Kafka API, follow the instructions in Authentication to the Apache Kafka API.
Version and upgrades
Managed Service for Apache Kafka clusters run on a version of Apache Kafka that is typically within six months of the latest release. The service automatically upgrades the Apache Kafka servers running on the cluster, ensuring you benefit from the latest features and security improvements.
Cluster configuration
Managed Service for Apache Kafka always runs in KRaft mode, as Apache Kafka is migrating away from Apache ZooKeeper. The KRaft configuration is managed completely by Managed Service for Apache Kafka and is an implementation detail that does not affect how you interact with the Managed Service for Apache Kafka cluster.
Managed Service for Apache Kafka clusters are designed for high availability. Each cluster consists of at least 3 brokers. If a topic is created with the default replication factor of 3, each topic partition has a leader and 2 followers, to ensure fault tolerance. If the leader fails, one of the followers automatically takes over, minimizing downtime and ensuring continuous operation.
Managed Service for Apache Kafka also utilizes tiered storage, a cost-effective approach that combines local storage on the brokers with long-term storage in Google Cloud. Generally, the leader for any given partition is responsible for writing the data to long-term storage. However, any broker can read data from long-term storage. This approach introduces a slightly higher latency for reading older data compared to local-only storage. However, tiered storage also offers significant cost savings and scalability advantages.
The following image shows a Managed Service for Apache Kafka cluster with a leader broker and two follower brokers.
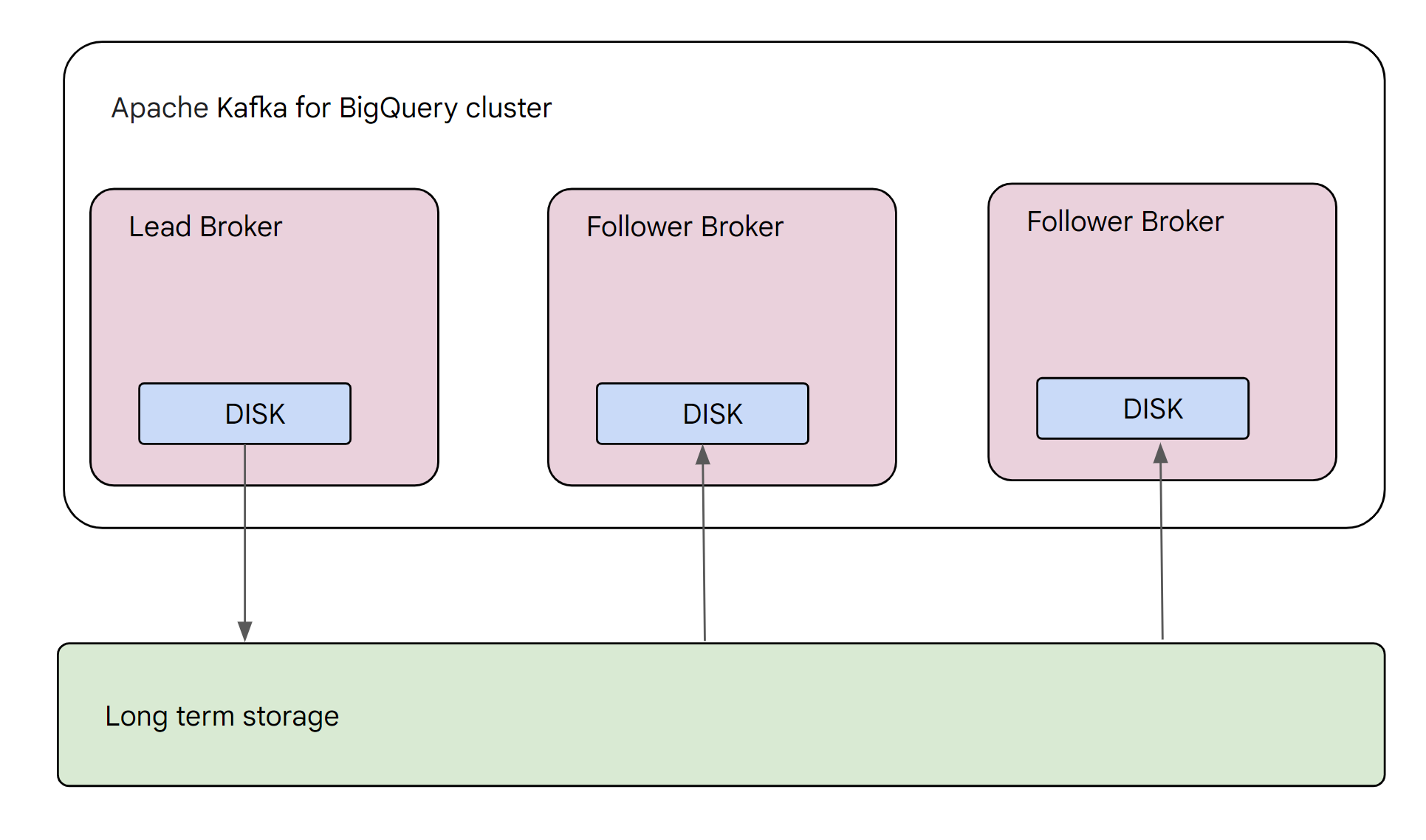
This mechanism lets Managed Service for Apache Kafka support virtually unlimited topic storage volume.
Limitations
Managed Service for Apache Kafka requires each cluster to have equal resources in each of the three zones. Single-zone or two-zone Managed Service for Apache Kafka clusters are not supported.
You cannot choose the zones when you create the cluster.
You cannot configure the volume of local storage on a cluster.
Managed Service for Apache Kafka runs in the KRaft mode. Zookeeper mode is not supported.