Molti clienti di Looker vogliono consentire ai propri utenti di andare oltre la generazione di report sui dati nel data warehouse per scrivere e aggiornare effettivamente il data warehouse.
Tramite l'API Action, Looker supporta questo caso d'uso per qualsiasi data warehouse o destinazione. Questa pagina di documentazione illustra ai clienti che utilizzano l'infrastruttura Google Cloud come eseguire il deployment di una soluzione sulle funzioni Cloud Run per scrivere di nuovo su BigQuery. Questa pagina tratta i seguenti argomenti:
Considerazioni sulle soluzioni
Utilizza questo elenco di considerazioni per verificare che questa soluzione sia in linea con le tue esigenze.
- Cloud Run Functions
- Perché Cloud Run Functions? In quanto offerta "serverless " di Google, Cloud Run Functions è un'ottima scelta per la facilità di operazioni e manutenzione. Un aspetto da tenere presente è che la latenza, in particolare per le chiamate a freddo, potrebbe essere più lunga rispetto a una soluzione che si basa su un server dedicato.
- Linguaggio e runtime Cloud Run Functions supporta più linguaggi e runtime. Questa pagina di documentazione si concentrerà su un esempio in JavaScript e Node.js. Tuttavia, i concetti sono direttamente traducibili nelle altre lingue e runtime supportati.
- BigQuery
- Perché BigQuery? Anche se questa pagina della documentazione presuppone che tu stia già utilizzando BigQuery, BigQuery è un'ottima scelta per un data warehouse in generale. Tieni presente le seguenti considerazioni:
- API BigQuery Storage Write:BigQuery offre più interfacce per aggiornare i dati nel data warehouse, tra cui, ad esempio, istruzioni Data Manipulation Language (DML) nei job basati su SQL. Tuttavia, l'opzione migliore per le scritture di volumi elevati è l'API BigQuery Storage Write.
- Accodamento anziché aggiornamento:anche se questa soluzione accoda solo le righe, non le aggiorna, puoi sempre derivare le tabelle "stato attuale" al momento della query da un log di solo accodamento, simulando così gli aggiornamenti.
- Perché BigQuery? Anche se questa pagina della documentazione presuppone che tu stia già utilizzando BigQuery, BigQuery è un'ottima scelta per un data warehouse in generale. Tieni presente le seguenti considerazioni:
- Servizi di supporto
- Secret Manager:Secret Manager contiene i valori dei secret per assicurarsi che non vengano archiviati in posizioni troppo accessibili, ad esempio direttamente nella configurazione della funzione.
- Identity and Access Management (IAM): IAM autorizza la funzione ad accedere al secret necessario in fase di runtime e a scrivere nella tabella BigQuery di destinazione.
- Cloud Build: anche se Cloud Build non verrà trattato in dettaglio in questa pagina, le funzioni Cloud Run lo utilizzano in background e puoi utilizzarlo per automatizzare gli aggiornamenti di deployment continuo delle tue funzioni dalle modifiche al codice sorgente in un repository Git.
- Autenticazione di azioni e utenti
- Account di servizio Cloud Run Il modo principale e più semplice per utilizzare le azioni di Looker per l'integrazione con le risorse e gli asset proprietari della tua organizzazione è autenticare le richieste come provenienti dalla tua istanza di Looker utilizzando il meccanismo di autenticazione basato su token dell'API Looker Action, quindi autorizzare la funzione ad aggiornare i dati in BigQuery utilizzando un account di servizio.
- OAuth:un'altra opzione, non trattata in questa pagina, è l'utilizzo della funzionalità OAuth dell'API Looker Action. Questo approccio è più complesso e in genere non è necessario, ma può essere utilizzato se devi definire l'accesso degli utenti finali in scrittura alla tabella utilizzando IAM, anziché il loro accesso in Looker o la logica ad hoc all'interno del codice della funzione.
Procedura dettagliata del codice demo
Abbiamo un unico file contenente tutta la logica dell'azione demo disponibile su GitHub. In questa sezione esamineremo gli elementi chiave del codice.
Codice di configurazione
La prima sezione contiene alcune costanti demo che identificano la tabella in cui verrà scritto il risultato dell'azione. Nella sezione Guida all'implementazione più avanti in questa pagina, ti verrà chiesto di sostituire l'ID progetto con il tuo, che sarà l'unica modifica necessaria al codice.
/*** Demo constants */
const projectId = "your-project-id"
const datasetId = "demo_dataset"
const tableId = "demo_table"
La sezione successiva dichiara e inizializza alcune dipendenze del codice che verranno utilizzate dall'azione. Forniamo un esempio che accede a Secret Manager "nel codice" utilizzando il modulo Node.js di Secret Manager. Tuttavia, puoi anche eliminare questa dipendenza dal codice utilizzando la funzionalità integrata delle funzioni Cloud Run per recuperare un secret durante l'inizializzazione.
/*** Code Dependencies ***/
const crypto = require("crypto")
const {SecretManagerServiceClient} = require('@google-cloud/secret-manager')
const secrets = new SecretManagerServiceClient()
const BigqueryStorage = require('@google-cloud/bigquery-storage')
const BQSManagedWriter = BigqueryStorage.managedwriter
Tieni presente che le dipendenze @google-cloud a cui viene fatto riferimento sono dichiarate anche nel nostro file package.json per consentire il precaricamento e la disponibilità per il nostro runtime Node.js. crypto è un modulo Node.js integrato e non è dichiarato in package.json.
Gestione e routing delle richieste HTTP
L'interfaccia principale che il tuo codice espone al runtime di Cloud Run Functions è una funzione JavaScript esportata che segue le convenzioni del web server Node.js Express. In particolare, la funzione riceve due argomenti: il primo rappresenta la richiesta HTTP, da cui puoi leggere vari parametri e valori della richiesta; il secondo rappresenta un oggetto risposta, a cui invii i dati di risposta. Anche se il nome della funzione può essere qualsiasi, dovrai fornirlo alle funzioni Cloud Run in un secondo momento, come descritto nella sezione Guida al deployment.
/*** Entry-point for requests ***/
exports.httpHandler = async function httpHandler(req,res) {
La prima sezione della funzione httpHandler dichiara le varie route che la nostra azione riconoscerà, rispecchiando da vicino gli endpoint richiesti dall'API Actions per una singola azione e le funzioni che gestiranno ogni route, definite più avanti nel file.
Mentre alcuni esempi di azioni + funzioni Cloud Run eseguono il deployment di una funzione separata per ogni route per allinearsi uno a uno con il routing predefinito di Cloud Run Functions, le funzioni sono in grado di applicare un "sub-routing " aggiuntivo all'interno del codice, come illustrato qui. Si tratta in definitiva di una questione di preferenza, ma questo routing aggiuntivo nel codice riduce al minimo il numero di funzioni da implementare e ci aiuta a mantenere un unico stato del codice coerente in tutti gli endpoint delle azioni.
const routes = {
"/": [hubListing],
"/status": [hubStatus], // Debugging endpoint. Not required.
"/action-0/form": [
requireInstanceAuth,
action0Form
],
"/action-0/execute": [
requireInstanceAuth,
processRequestBody,
action0Execute
]
}
Il resto della funzione del gestore HTTP implementa la gestione della richiesta HTTP in base alle dichiarazioni di route precedenti e collega i valori restituiti da questi gestori all'oggetto risposta.
try {
const routeHandlerSequence = routes[req.path] || [routeNotFound]
for(let handler of routeHandlerSequence) {
let handlerResponse = await handler(req)
if (!handlerResponse) continue
return res
.status(handlerResponse.status || 200)
.json(handlerResponse.body || handlerResponse)
}
}
catch(err) {
console.error(err)
res.status(500).json("Unhandled error. See logs for details.")
}
}
Una volta completate le dichiarazioni del gestore HTTP e della route, esamineremo i tre endpoint di azione principali che dobbiamo implementare:
Endpoint dell'elenco delle azioni
Quando un amministratore di Looker collega per la prima volta un'istanza di Looker a un server Azioni, Looker chiama l'URL fornito, denominato "endpoint Elenco azioni", per ottenere informazioni sulle azioni disponibili tramite il server.
Nelle dichiarazioni di route che abbiamo mostrato in precedenza, abbiamo reso disponibile questo endpoint nel percorso principale (/) nell'URL della nostra funzione e abbiamo indicato che sarebbe stato gestito dalla funzione hubListing.
Come puoi vedere dalla seguente definizione di funzione, non c'è molto "codice" da scrivere: restituisce sempre gli stessi dati JSON. Una cosa da notare è che include dinamicamente il proprio URL in alcuni campi, consentendo all'istanza di Looker di inviare richieste successive alla stessa funzione.
async function hubListing(req){
return {
integrations: [
{
name: "demo-bq-insert",
label: "Demo BigQuery Insert",
supported_action_types: ["cell", "query", "dashboard"],
form_url:`${process.env.CALLBACK_URL_PREFIX}/action-0/form`,
url: `${process.env.CALLBACK_URL_PREFIX}/action-0/execute`,
icon_data_uri: "data:image/png;base64,...",
supported_formats:["inline_json"],
supported_formattings:["unformatted"],
required_fields:[
// You can use this to make your action available
// for specific queries/fields
// {tag:"user_id"}
],
params: [
// You can use this to require parameters, either
// from the Action's administrative configuration,
// or from the invoking user's user attributes.
// A common use case might be to have the Looker
// instance pass along the user's identification to
// allow you to conditionally authorize the action:
{name: "email", label: "Email", user_attribute_name: "email", required: true}
]
}
]
}
}
A scopo dimostrativo, il nostro codice non ha richiesto l'autenticazione per recuperare questa scheda. Tuttavia, se consideri sensibili i metadati delle azioni, puoi anche richiedere l'autenticazione per questa route, come mostrato nella sezione successiva.
Tieni presente inoltre che la nostra funzione Cloud Run potrebbe esporre e gestire più azioni, il che spiega la nostra convenzione di route /action-X/.... Tuttavia, la nostra funzione demo Cloud Run implementerà una sola azione.
Endpoint del modulo di azione
Sebbene non tutti i casi d'uso richiedano un modulo, averne uno si adatta bene al caso d'uso dei writeback del database, in quanto gli utenti possono esaminare i dati in Looker e poi fornire i valori da inserire nel database. Poiché il nostro elenco di azioni fornisce un parametro form_url, Looker richiamerà questo endpoint del modulo di azione quando un utente inizia a interagire con l'azione, per determinare quali dati aggiuntivi acquisire dall'utente.
Nelle nostre dichiarazioni di route, abbiamo reso disponibile questo endpoint nel percorso /action-0/form e abbiamo associato due gestori: requireInstanceAuth e action0Form.
Abbiamo configurato le dichiarazioni di route per consentire più gestori come questo perché alcune logiche possono essere riutilizzate per più endpoint.
Ad esempio, possiamo vedere che requireInstanceAuth viene utilizzato per più itinerari. Utilizziamo questo gestore ovunque vogliamo richiedere che una richiesta provenga dalla nostra istanza di Looker. Il gestore recupera il valore del token previsto del secret da Secret Manager e rifiuta tutte le richieste che non hanno il valore del token previsto.
async function requireInstanceAuth(req) {
const lookerSecret = await getLookerSecret()
if(!lookerSecret){return}
const expectedAuthHeader = `Token token="${lookerSecret}"`
if(!timingSafeEqual(req.headers.authorization,expectedAuthHeader)){
return {
status:401,
body: {error: "Looker instance authentication is required"}
}
}
return
function timingSafeEqual(a, b) {
if(typeof a !== "string"){return}
if(typeof b !== "string"){return}
var aLen = Buffer.byteLength(a)
var bLen = Buffer.byteLength(b)
const bufA = Buffer.allocUnsafe(aLen)
bufA.write(a)
const bufB = Buffer.allocUnsafe(aLen) //Yes, aLen
bufB.write(b)
return crypto.timingSafeEqual(bufA, bufB) && aLen === bLen;
}
}
Tieni presente che utilizziamo un'implementazione timingSafeEqual anziché il controllo di uguaglianza standard (==) per impedire la divulgazione di informazioni temporali del canale laterale che consentirebbero a un malintenzionato di scoprire rapidamente il valore del nostro segreto.
Supponendo che una richiesta superi il controllo di autenticazione dell'istanza, viene gestita dal gestore action0Form.
async function action0Form(req){
return [
{name: "choice", label: "Choose", type:"select", options:[
{name:"Yes", label:"Yes"},
{name:"No", label:"No"},
{name:"Maybe", label:"Maybe"}
]},
{name: "note", label: "Note", type: "textarea"}
]
}
Sebbene il nostro esempio di demo sia molto statico, il codice del modulo può essere più interattivo per determinati casi d'uso. Ad esempio, a seconda della selezione di un utente in un menu a discesa iniziale, possono essere visualizzati campi diversi.
Endpoint di esecuzione dell'azione
L'endpoint Esegui azione è il punto in cui risiede la maggior parte della logica di qualsiasi azione e in cui esamineremo la logica specifica per lo scenario di utilizzo dell'inserimento BigQuery.
Nelle nostre dichiarazioni di route, abbiamo reso disponibile questo endpoint nel percorso /action-0/execute e abbiamo associato tre gestori: requireInstanceAuth, processRequestBody e action0Execute.
Abbiamo già trattato requireInstanceAuth e il gestore processRequestBody fornisce un pre-elaborazione per lo più non interessante per trasformare determinati campi scomodi nel corpo della richiesta di Looker in un formato più comodo, ma puoi farvi riferimento nel file di codice completo.
La funzione action0Execute inizia mostrando esempi di estrazione di informazioni da diverse parti della richiesta di azione che potrebbero essere utili. In pratica, tieni presente che gli elementi della richiesta a cui il nostro codice fa riferimento come formParams e actionParams possono contenere campi diversi, a seconda di ciò che dichiari negli endpoint Elenco e Modulo.
async function action0Execute (req){
try{
// Prepare some data that we will insert
const scheduledPlanId = req.body.scheduled_plan && req.body.scheduled_plan.scheduled_plan_id
const formParams = req.body.form_params || {}
const actionParams = req.body.data || {}
const queryData = req.body.attachment.data //If using a standard "push" action
/*In case any fields require datatype-specific preparation, check this example:
https://github.com/googleapis/nodejs-bigquery-storage/blob/main/samples/append_rows_proto2.js
*/
const newRow = {
invoked_at: new Date(),
invoked_by: actionParams.email,
scheduled_plan_id: scheduledPlanId || null,
query_result_size: queryData.length,
choice: formParams.choice,
note: formParams.note,
}
Il codice passa quindi a un codice BigQuery standard per inserire effettivamente i dati. Tieni presente che le API BigQuery Storage Write offrono altre varianti più complesse più adatte a una connessione di streaming persistente o a inserimenti collettivi di molti record. Tuttavia, per rispondere alle interazioni dei singoli utenti nel contesto di una funzione Cloud Run, questa è la variante più diretta.
await bigqueryConnectAndAppend(newRow)
...
async function bigqueryConnectAndAppend(row){
let writerClient
try{
const destinationTablePath = `projects/${projectId}/datasets/${datasetId}/tables/${tableId}`
const streamId = `${destinationTablePath}/streams/_default`
writerClient = new BQSManagedWriter.WriterClient({projectId})
const writeMetadata = await writerClient.getWriteStream({
streamId,
view: 'FULL',
})
const protoDescriptor = BigqueryStorage.adapt.convertStorageSchemaToProto2Descriptor(
writeMetadata.tableSchema,
'root'
)
const connection = await writerClient.createStreamConnection({
streamId,
destinationTablePath,
})
const writer = new BQSManagedWriter.JSONWriter({
streamId,
connection,
protoDescriptor,
})
let result
if(row){
// The API expects an array of rows, so wrap the single row in an array
const rowsToAppend = [row]
result = await writer.appendRows(rowsToAppend).getResult()
}
return {
streamId: connection.getStreamId(),
protoDescriptor,
result
}
}
catch (e) {throw e}
finally{
if(writerClient){writerClient.close()}
}
}
Il codice demo include anche un endpoint "status" per la risoluzione dei problemi, ma questo endpoint non è necessario per l'integrazione dell'API Actions.
Guida al deployment
Infine, forniremo una guida passo passo per il deployment della demo, che illustrerà i prerequisiti, il deployment della funzione Cloud Run, la configurazione di BigQuery e la configurazione di Looker.
Prerequisiti per progetti e servizi
Prima di iniziare a configurare dettagli specifici, esamina questo elenco per comprendere i servizi e le norme di cui avrà bisogno la soluzione:
- Un nuovo progetto:avrai bisogno di un nuovo progetto per ospitare le risorse del nostro esempio.
- Servizi:quando utilizzi per la prima volta le funzioni BigQuery e Cloud Run nella UI della console Google Cloud, ti verrà chiesto di attivare le API richieste per i servizi necessari, tra cui BigQuery, Artifact Registry, Cloud Build, Cloud Functions, Cloud Logging, Pub/Sub, Cloud Run Admin e Secret Manager.
- Policy per le chiamate non autenticate:questo caso d'uso richiede di eseguire il deployment di Cloud Run Functions che "consentono le chiamate non autenticate", poiché gestiamo l'autenticazione per le richieste in entrata nel nostro codice in base all'API Actions, anziché utilizzare IAM. Anche se questa operazione è consentita per impostazione predefinita, spesso le policy dell'organizzazione ne limitano l'utilizzo. Nello specifico, il criterio
constraints/iam.allowedPolicyMemberDomainslimita a chi possono essere concesse le autorizzazioni IAM e potrebbe essere necessario modificarlo per consentire l'entitàallUsersper l'accesso non autenticato. Se non riesci a consentire le chiamate non autenticate, consulta questa guida: Come creare servizi Cloud Run pubblici quando è applicata la condivisione con limitazioni del dominio. - Altre norme:tieni presente che anche altri Google Cloud vincoli delle norme dell'organizzazione possono impedire il deployment di servizi altrimenti consentiti per impostazione predefinita.
Deployment della funzione Cloud Run
Dopo aver creato un nuovo progetto, segui questi passaggi per eseguire il deployment della funzione Cloud Run
- In Cloud Run Functions, fai clic su Crea funzione.
- Scegli un nome qualsiasi per la funzione (ad esempio "demo-bq-insert-action").
- Nelle impostazioni Trigger:
- Il tipo di attivatore deve essere già "HTTPS".
- Imposta Autenticazione su Consenti chiamate non autenticate.
- Copia il valore URL negli appunti.
- Nelle impostazioni Runtime > Variabili di ambiente runtime:
- Fai clic su Aggiungi variabile.
- Imposta il nome della variabile su
CALLBACK_URL_PREFIX. - Incolla l'URL del passaggio precedente come valore.
- Fai clic su Avanti.
- Fai clic sul file
package.jsone incolla i contenuti. - Fai clic sul file
index.jse incolla i contenuti. - Assegna alla variabile
projectIdnella parte superiore del file il tuo ID progetto. - Imposta il punto di ingresso su
httpHandler. - Fai clic su Esegui il deployment.
- Concedi le autorizzazioni richieste (se presenti) al service account di build.
- Attendi il completamento del deployment.
- Se, in uno dei passaggi futuri, visualizzi un errore che ti invita a esaminare i Google Cloud log, tieni presente che puoi accedere ai log di questa funzione dalla scheda Log di questa pagina.
- Prima di uscire dalla pagina della funzione Cloud Run, nella scheda Dettagli, individua e annota l'account di servizio della funzione. Lo utilizzeremo nei passaggi successivi per assicurarci che la funzione disponga delle autorizzazioni necessarie.
- Testa il deployment della funzione direttamente nel browser visitando l'URL. Dovresti visualizzare una risposta JSON contenente l'elenco delle integrazioni.
- Se ricevi un errore 403, il tentativo di impostare Consenti chiamate non autenticate potrebbe non essere andato a buon fine a causa di una norma dell'organizzazione. Controlla se la tua funzione consente chiamate non autenticate, esamina l'impostazione dei criteri dell'organizzazione e prova ad aggiornare l'impostazione.
Accesso alla tabella di destinazione BigQuery
In pratica, la tabella di destinazione da inserire può risiedere in un progetto Google Cloud diverso, ma a scopo dimostrativo creeremo una nuova tabella di destinazione nello stesso progetto. In entrambi i casi, devi assicurarti che il service account della funzione Cloud Run disponga delle autorizzazioni per scrivere nella tabella.
- Vai alla console BigQuery.
Crea la tabella demo:
- Nella barra Explorer, utilizza il menu con i tre puntini accanto al progetto e seleziona Crea set di dati.
- Assegna al set di dati l'ID
demo_datasete fai clic su Crea set di dati. - Utilizza il menu con i tre puntini sul set di dati appena creato e seleziona Crea tabella.
- Assegna alla tabella il nome
demo_table. In Schema, seleziona Modifica come testo, utilizza lo schema seguente e poi fai clic su Crea tabella.
[ {"name":"invoked_at","type":"TIMESTAMP"}, {"name":"invoked_by","type":"STRING"}, {"name":"scheduled_plan_id","type":"STRING"}, {"name":"query_result_size","type":"INTEGER"}, {"name":"choice","type":"STRING"}, {"name":"note","type":"STRING"} ]
Assegnare le autorizzazioni:
- Nella barra Explorer, fai clic sul set di dati.
- Nella pagina Set di dati, fai clic su Condivisione > Autorizzazioni.
- Fai clic su Aggiungi entità.
- Imposta Nuova entità sull'account di servizio per la tua funzione, annotato in precedenza in questa pagina.
- Assegna il ruolo Editor dati BigQuery.
- Fai clic su Salva.
Connessione a Looker
Ora che la funzione è stata implementata, collegheremo Looker.
- Per autenticare le richieste provenienti dalla tua istanza di Looker, avremo bisogno di un segreto condiviso per la tua azione. Genera una lunga stringa casuale e mantienila al sicuro. Lo utilizzeremo nei passaggi successivi come valore di Looker secret.
- Nella console Google Cloud, vai a Secret Manager.
- Fai clic su Crea secret.
- Imposta Nome su
LOOKER_SECRET. (Questo valore è codificato nel codice di questa demo, ma puoi scegliere qualsiasi nome quando lavori con il tuo codice.) - Imposta il Valore secret sul valore secret che hai generato.
- Fai clic su Crea secret.
- Nella pagina Secret, fai clic sulla scheda Autorizzazioni.
- Fai clic su Concedi l'accesso.
- Imposta Nuove entità sul service account per la tua funzione, annotato in precedenza.
- Assegna il ruolo Funzione di accesso ai secret di Secret Manager.
- Fai clic su Salva.
- Puoi verificare che la tua funzione acceda correttamente al secret visitando la route
/statusaggiunta all'URL della funzione.
- Nella tua istanza di Looker:
- Vai ad Amministratore > Piattaforma > Azioni.
- Vai in fondo alla pagina per fare clic su Aggiungi hub delle azioni.
- Fornisci l'URL della tua funzione (ad esempio https://your-region-your-project.cloudfunctions.net/demo-bq-insert-action) e conferma facendo clic su Aggiungi Action Hub.
- Ora dovresti visualizzare una nuova voce in Action Hub con un'azione denominata Demo BigQuery Insert.
- Nella voce Action Hub, fai clic su Configura autorizzazione.
- Inserisci il segreto di Looker generato nel campo Token di autorizzazione e fai clic su Aggiorna token.
- Nell'azione Demo BigQuery Insert, fai clic su Abilita.
- Attiva l'opzione Attivata.
- Verrà eseguito automaticamente un test dell'azione, che confermerà che la funzione accetta la richiesta di Looker e risponde correttamente all'endpoint del modulo.
- Fai clic su Salva.
Test end-to-end
Ora dovremmo essere in grado di utilizzare la nostra nuova azione. Questa azione è configurata per funzionare con qualsiasi query, quindi scegli un'esplorazione (ad esempio, un'esplorazione dell'attività di sistema integrata), aggiungi alcuni campi a una nuova query, eseguila e poi scegli Invia dal menu a forma di ingranaggio. Dovresti visualizzare l'azione come una delle destinazioni disponibili e ti verrà chiesto di inserire alcuni campi:
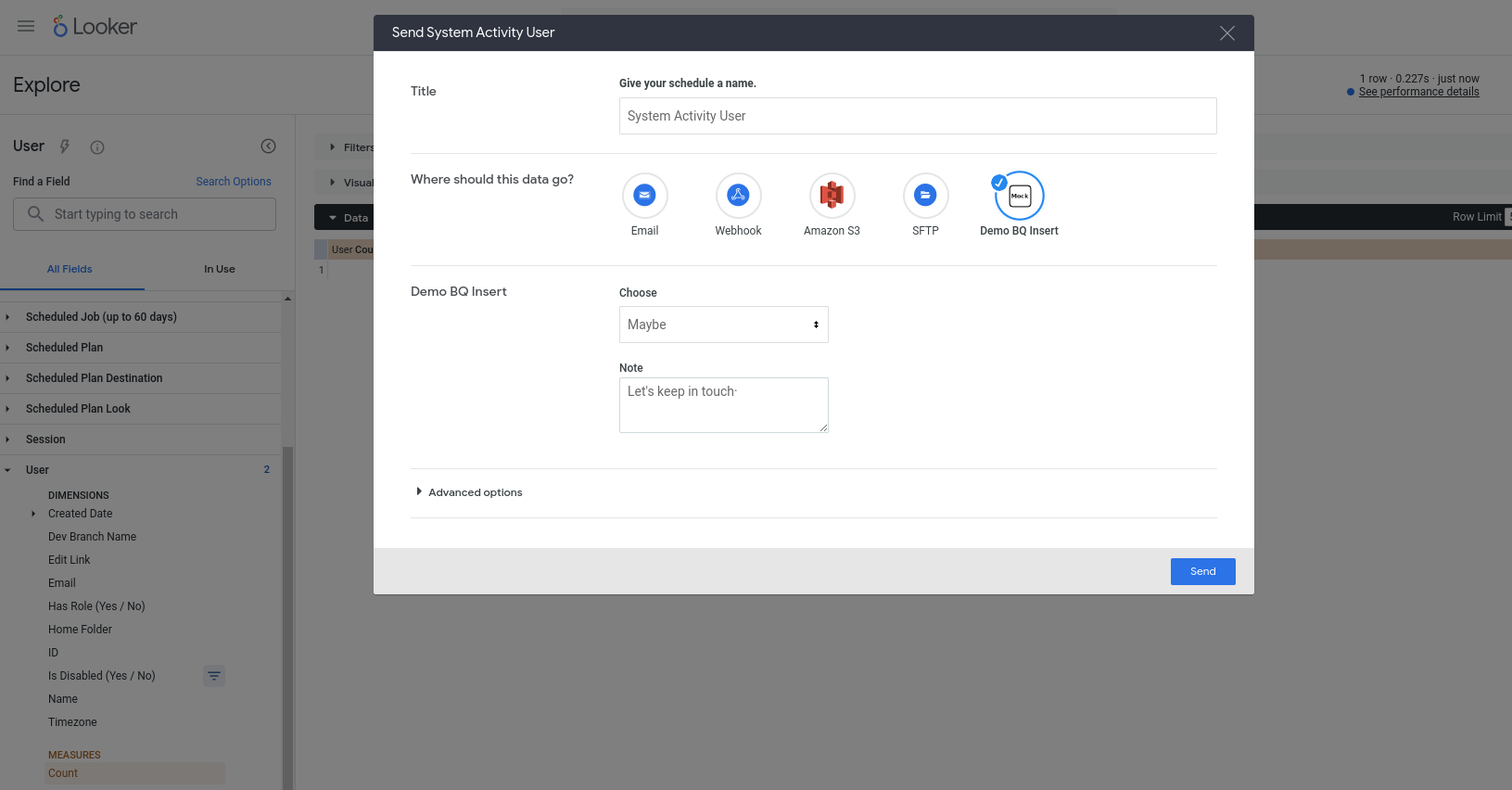
Dopo aver premuto Invia, nella tabella BigQuery dovrebbe essere inserita una nuova riga (e l'email del tuo account utente Looker dovrebbe essere identificata nella colonna invoked_by).