このページでは、VMware 用 Google Distributed Cloud(ソフトウェアのみ)の高可用性オプションについて説明します。
コア機能
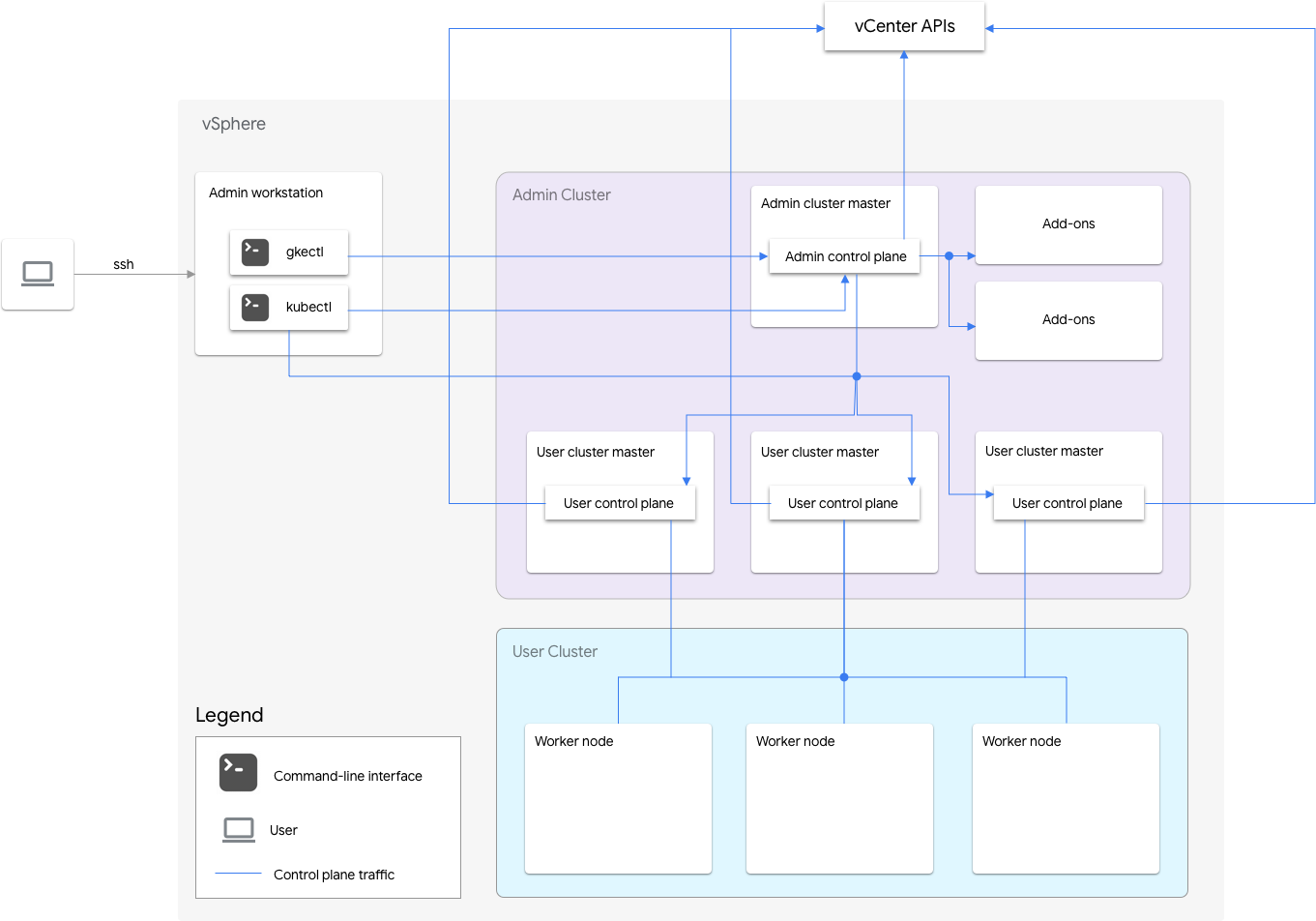
VMware 用 Google Distributed Cloud(ソフトウェアのみ)のインストールには、管理クラスタと 1 つ以上のユーザー クラスタが含まれます。
管理クラスタは、ユーザー クラスタのライフサイクル(ユーザー クラスタの作成、更新、アップグレード、削除など)を管理します。管理クラスタでは、管理マスターが管理ワーカーノードを管理します。管理ワーカーノードには、ユーザー マスター(管理対象ユーザー クラスタのコントロール プレーンを実行するワーカーノード)とアドオンノード(アドオン コンポーネントを実行して管理クラスタの機能をサポートするノード)が含まれています。
ユーザー クラスタごとに、管理クラスタの 1 つの非 HA ノードまたは 3 つの HA ノードでコントロール プレーンが実行されます。コントロール プレーンには、Kubernetes API サーバー、Kubernetes スケジューラ、Kubernetes コントローラ マネージャー、ユーザー クラスタの重要なコントローラが含まれています。
ユーザー クラスタのコントロール プレーンの可用性は、ワークロードの作成、スケールアップとスケールダウン、終了などのワークロード オペレーションにとってきわめて重要です。つまり、コントロール プレーンが停止しても、実行中のワークロードは影響を受けませんが、既存のワークロードはコントロール プレーンを失うため、Kubernetes API サーバーによる管理機能を利用できなくなります。
コンテナ化されたワークロードとサービスは、ユーザー クラスタのワーカーノードにデプロイされます。複数のワーカーノード間でスケジュールされた冗長 Pod でアプリケーションをデプロイされていれば、1 つのワーカーノードがアプリケーションの可用性に重大な影響を及ぼすことはありません。
高可用性の有効化
vSphere と Google Distributed Cloud では、高可用性(HA)に役立つ多くの機能を利用できます。
vSphere HA と vMotion
Google Distributed Cloud クラスタをホストする vCenter クラスタで次の 2 つの機能を有効にすることをおすすめします。
これらの機能によって、ESXi ホストで発生する障害に対して可用性と復元性が向上します。
vCenter HA は、クラスタとして構成された複数の ESXi ホストを使用して、仮想マシンで稼働するアプリケーションに対し、停止からの迅速な復旧と費用対効果の高い HA を可能にします。追加のホストを使用して vCenter クラスタをプロビジョニングし、Host Failure Response を Restart VMs に設定して vSphere HA ホスト モニタリングを有効にすることをおすすめします。そうすると、ESXi ホストで障害が発生した場合、VM は他の利用可能なホストで自動的に再起動されます。
vMotion を使用すると、ダウンタイムなしで ESXi ホスト間での VM のライブ マイグレーションが可能になります。計画されたホスト メンテナンスに対しては、vMotion ライブ マイグレーションを使用してアプリケーションのダウンタイムを完全に回避し、ビジネスの継続性を確保できます。
管理クラスタ
Google Distributed Cloud は、高可用性(HA)管理クラスタの作成をサポートしています。HA 管理クラスタには、コントロール プレーン コンポーネントを実行する 3 つのノードがあります。要件と制限事項については、高可用性管理クラスタをご覧ください。
管理クラスタ コントロール プレーンが使用不能になっても、既存のユーザー クラスタ機能やユーザー クラスタで実行中のワークロードには影響しません。
管理クラスタには 2 つのアドオンノードがあります。1 つが停止しても、もう一方で管理クラスタの操作を実行できます。冗長性を確保するため、Google Distributed Cloud では kube-dns などの重要なアドオン サービスが両方のアドオンノードに分散されます。
管理クラスタの構成ファイルで、true を antiAffinityGroups.enabled に設定すると、Google Distributed Cloud は、アドオン用に vSphere DRS アンチアフィニティ ルールを自動的に作成します。これにより、HA 用の 2 つの物理ホストにそれぞれが分散されます。
ユーザー クラスタ
ユーザー クラスタの構成ファイルで masterNode.replicas を 3 に設定すると、ユーザー クラスタの HA を有効にできます。ユーザー クラスタで Controlplane V2 が有効になっている場合(推奨)は、3 つのコントロール プレーン ノードがユーザー クラスタで実行されます。Controlplane V2 が有効になっていない以前の HA ユーザー クラスタは、管理クラスタ内の 3 つのコントロール プレーン ノードを実行します。各コントロール プレーン ノードは、etcd レプリカも実行します。1 つのコントロール プレーンと etcd クォーラムが存在する限り、ユーザー クラスタは引き続き機能します。etcd のクォーラムでは、3 つの etcd レプリカのうち 2 つが機能している必要があります。
管理クラスタの構成ファイルで、true を antiAffinityGroups.enabled に設定した場合、Google Distributed Cloud は、それら 3 つのノード用に、ユーザー クラスタ コントロール プレーンを実行する vSphere DRS 反アフィニティ ルールを自動作成します。これにより、それらの VM は 3 つの物理ホストに分散されます。
また、Google Distributed Cloud は、ユーザー クラスタ内のワーカーノード用に vSphere DRS アンチアフィニティ ルールを作成します。これにより、これらのノードが少なくとも 3 つの物理ホストに分散されます。ノード数に基づいて、ユーザー クラスタ ノードプールごとに複数の DRS 反アフィニティ ルールが使用されます。これにより、ホストの数が、ユーザー クラスタのノードプール内の VM の数より少ない場合でも、ワーカーノードが実行先のホストを見つけることができます。vCenter クラスタに追加の物理ホストを含めることをおすすめします。また、ホストが使用不能になった場合、DRS が VM のアンチアフィニティ ルールに違反することなく、使用可能な他のホスト上の VM を自動的に再起動できるように、DRS が完全に自動化されるように構成します。
Google Distributed Cloud は、特別なノードラベル onprem.gke.io/failure-domain-name を保持しています。このラベルの値は、基になる ESXi ホスト名に設定されます。高可用性を必要とするユーザー アプリケーションでは、topologyKey としてこのラベルを使用して podAntiAffinity ルールを設定し、アプリケーション Pod が複数の VM と物理ホストに分散されるようにします。異なるデータストアと特別なノードラベルを使用してユーザー クラスタに複数のノードプールを構成することもできます。同様に、特別なノードラベルで podAntiAffinity ルールを topologyKey として設定すると、データストアで障害が発生した場合に高可用性を実現できます。
ユーザー ワークロードに対して高可用性を確保するには、ユーザー クラスタが nodePools.replicas の配下に十分な数のレプリカを持つようにします。これにより、実行中のユーザー クラスタ ワーカーノードの数が適切な状態で維持されます。
管理クラスタとユーザー クラスタに別々のデータストアを使用して、障害を隔離できます。
ロードバランサ
高可用性を確保するために使用できるロードバランサには次の 2 種類があります。
バンドルされた MetalLB ロードバランサ
バンドルされた MetalLB ロードバランサでは、enableLoadBalancer: true に複数のノードを使用することで HA を実現します。
MetalLB はサービスをロードバランサ ノードに分散しますが、単一のサービスの場合、そのサービスのすべてのトラフィックを処理するリーダーノードは 1 つだけです。
クラスタのアップグレード中は、ロードバランサ ノードがアップグレードされると、ダウンタイムが発生することがあります。ロードバランサ ノードの数が増えると、MetalLB のフェイルオーバーの中断期間が長くなります。5 ノード未満であれば、中断は 10 秒以内です。
手動ロード バランシング
手動ロード バランシングでは、F5 BIG-IP や Citrix など、任意のロードバランサを使用するように Google Distributed Cloud を構成します。高可用性は、Google Distributed Cloud ではなく、ロードバランサで構成します。
障害復旧に複数のクラスタを使用する
複数の vCenter サーバーにまたがって複数のクラスタにアプリケーションをデプロイすると、全体としての可用性が向上し、サービス停止時の影響範囲を狭めることができます。
この設定では、新しいクラスタを設定するのではなく、セカンダリ データセンターにある既存のクラスタを使用して障害復旧を行います。手順の概要は次のとおりです。
セカンダリ データセンターに別の管理クラスタとユーザー クラスタを作成します。このマルチクラスタ アーキテクチャでは、各データセンターに 2 つの管理クラスタを用意し、各管理クラスタでユーザー クラスタを実行する必要があります。
セカンダリ ユーザー クラスタには最小限のワーカーノード(3 つ)があり、ホット スタンバイ(常時稼働)の状態です。
アプリケーションのデプロイは、Config Sync を使用して 2 つの vCenter 間でレプリケートできます。または、既存のアプリケーション DevOps(CI / CD、Spinnaker)ツールチェーンの使用をおすすめします。
大規模障害が発生した場合、ユーザー クラスタをそのノード数に変更できます。
また、クラスタ間でのトラフィックをセカンダリ データセンターに転送するために、DNS のスイッチオーバーも必要です。