Teradata
El conector de Teradata te permite insertar, eliminar, actualizar y leer datos de la base de datos de Teradata.
Antes de empezar
Antes de usar el conector de Teradata, haz lo siguiente:
- En tu proyecto de Google Cloud:
- Asegúrate de que la conectividad de red esté configurada. Para obtener información sobre los patrones de red, consulta Conectividad de red.
- Concede el rol de gestión de identidades y accesos roles/connectors.admin al usuario que configure el conector.
- Concede los siguientes roles de gestión de identidades y accesos a la cuenta de servicio que quieras usar para el conector:
roles/secretmanager.viewerroles/secretmanager.secretAccessor
Una cuenta de servicio es un tipo especial de cuenta de Google diseñada para representar a un usuario no humano que necesita autenticarse y disponer de autorización para acceder a los datos de las APIs de Google. Si no tienes una cuenta de servicio, debes crearla. El conector y la cuenta de servicio deben pertenecer al mismo proyecto. Para obtener más información, consulta el artículo Crear una cuenta de servicio.
- Habilita los siguientes servicios:
secretmanager.googleapis.com(API Secret Manager)connectors.googleapis.com(API Connectors)
Para saber cómo habilitar servicios, consulta Habilitar servicios.
Si estos servicios o permisos no se han habilitado en tu proyecto anteriormente, se te pedirá que los habilites al configurar el conector.
Configuración de Teradata
Para crear una instancia de Teradata Vantage Express en una máquina virtual de Google Cloud, consulta Instalar Teradata en una máquina virtual de Google Cloud. Si esta VM está expuesta públicamente, su IP externa se puede usar como dirección de host al crear una conexión. Si la VM no está expuesta públicamente, crea una conectividad de servicio privada y usa la IP de adjunto de endpoint de red al crear una conexión.
Configurar el conector
Una conexión es específica de una fuente de datos. Esto significa que, si tiene muchas fuentes de datos, debe crear una conexión independiente para cada una de ellas. Para crear una conexión, sigue estos pasos:
- En la consola de Cloud, ve a la página Integration Connectors > Connections (Conectores de integración > Conexiones) y, a continuación, selecciona o crea un proyecto de Google Cloud.
- Haga clic en + Crear para abrir la página Crear conexión.
- En la sección Ubicación, elige la ubicación de la conexión.
- Región: selecciona una ubicación de la lista desplegable.
Para ver la lista de todas las regiones admitidas, consulta Ubicaciones.
- Haz clic en Siguiente.
- Región: selecciona una ubicación de la lista desplegable.
- En la sección Detalles de la conexión, haz lo siguiente:
- Conector: selecciona Teradata en la lista desplegable de conectores disponibles.
- Versión del conector: seleccione la versión del conector en la lista desplegable de versiones disponibles.
- En el campo Connection Name (Nombre de conexión), introduce un nombre para la instancia de conexión.
Los nombres de las conexiones deben cumplir los siguientes criterios:
- Los nombres de conexión pueden contener letras, números o guiones.
- Las letras deben estar en minúsculas.
- Los nombres de conexión deben empezar por una letra y terminar por una letra o un número.
- Los nombres de conexión no pueden tener más de 49 caracteres.
- Si quiere, puede introducir una Descripción para la instancia de conexión.
- También puedes habilitar Registro en la nube y, a continuación, seleccionar un nivel de registro. De forma predeterminada, el nivel de registro es
Error. - Cuenta de servicio: selecciona una cuenta de servicio que tenga los roles necesarios.
- Si quieres, configura los ajustes del nodo de conexión:
- Número mínimo de nodos: introduce el número mínimo de nodos de conexión.
- Número máximo de nodos: introduce el número máximo de nodos de conexión.
Un nodo es una unidad (o réplica) de una conexión que procesa transacciones. Se necesitan más nodos para procesar más transacciones en una conexión y, a la inversa, se necesitan menos nodos para procesar menos transacciones. Para saber cómo influyen los nodos en el precio de tu conector, consulta la sección Precios de los nodos de conexión. Si no introduces ningún valor, de forma predeterminada, el número mínimo de nodos se establece en 2 (para mejorar la disponibilidad) y el máximo en 50.
- Base de datos: la base de datos seleccionada como predeterminada cuando se abre una conexión de Teradata.
- Conjunto de caracteres: especifica el conjunto de caracteres de la sesión para codificar y decodificar los datos de caracteres transferidos a la base de datos de Teradata y desde ella. El valor predeterminado es ASCII.
- También puedes hacer clic en + Añadir etiqueta para añadir una etiqueta a la conexión en forma de par clave-valor.
- Haz clic en Siguiente.
- En la sección Destinations (Destinos), introduce los detalles del host remoto (sistema backend) al que quieras conectarte.
- Tipo de destino: selecciona un Tipo de destino.
- Para especificar el nombre de host o la dirección IP de destino, selecciona Dirección de host y introduce la dirección en el campo Host 1.
- Para establecer una conexión privada, selecciona Endpoint attachment (Endpoint adjunto) y elige el adjunto que quieras de la lista Endpoint Attachment (Endpoint adjunto).
Si quieres establecer una conexión pública con tus sistemas backend con seguridad adicional, puedes configurar direcciones IP de salida estáticas para tus conexiones y, a continuación, configurar las reglas de tu cortafuegos para que solo se permitan las direcciones IP estáticas específicas.
Para introducir más destinos, haz clic en +Añadir destino.
- Haz clic en Siguiente.
- Tipo de destino: selecciona un Tipo de destino.
-
En la sección Autenticación, introduce los detalles de autenticación.
- Seleccione un Tipo de autenticación e introduzca los detalles pertinentes.
La conexión de Teradata admite los siguientes tipos de autenticación:
- Nombre de usuario y contraseña
- Haz clic en Siguiente.
Para saber cómo configurar estos tipos de autenticación, consulta Configurar la autenticación.
- Seleccione un Tipo de autenticación e introduzca los detalles pertinentes.
- Revisar: revisa los detalles de la conexión y la autenticación.
- Haz clic en Crear.
Configurar la autenticación
Introduce los detalles en función de la autenticación que quieras usar.
-
Nombre de usuario y contraseña
- Nombre de usuario: nombre de usuario del conector.
- Contraseña: secreto de Secret Manager que contiene la contraseña asociada al conector.
Ejemplos de configuración de conexiones
En esta sección se proporcionan los valores de ejemplo de los distintos campos que se configuran al crear un conector de Teradata.
Autenticación básica: tipo de conexión
| Nombre del campo | Detalles |
|---|---|
| Ubicación | us-central1 |
| Conector | teradata |
| Versión del conector | 1 |
| Nombre de la conexión | teradata-vm-connection |
| Habilitar Cloud Logging | Sí |
| Cuenta de servicio | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| Base de datos | TERADATA_TESTDB |
| Conjunto de caracteres | ASCII |
| Número mínimo de nodos | 2 |
| Número máximo de nodos | 2 |
| Tipo de destino | Dirección del host |
| Anfitrión 1 | 203.0.113.255 |
| puerto 1 | 1025 |
| Nombre de usuario | NOMBRE DE USUARIO |
| Contraseña | CONTRASEÑA |
| Versión de secreto | 1 |
Entidades, operaciones y acciones
Todos los conectores de integración proporcionan una capa de abstracción para los objetos de la aplicación conectada. Solo puedes acceder a los objetos de una aplicación a través de esta abstracción. La abstracción se te muestra como entidades, operaciones y acciones.
- Entidad: una entidad se puede considerar como un objeto o un conjunto de propiedades en la aplicación o el servicio conectados. La definición de una entidad varía de un conector a otro. Por ejemplo, en un conector de base de datos, las tablas son las entidades; en un conector de servidor de archivos, las carpetas son las entidades; y en un conector de sistema de mensajería, las colas son las entidades.
Sin embargo, es posible que un conector no admita o no tenga ninguna entidad. En ese caso, la lista
Entitiesestará vacía. - Operación: una operación es la actividad que puedes realizar en una entidad. Puedes realizar cualquiera de las siguientes operaciones en una entidad:
Al seleccionar una entidad de la lista disponible, se genera una lista de operaciones disponibles para la entidad. Para ver una descripción detallada de las operaciones, consulta las operaciones de entidades de la tarea Connectors. Sin embargo, si un conector no admite ninguna de las operaciones de entidad, esas operaciones no admitidas no se mostrarán en la lista
Operations. - Acción: una acción es una función de primera clase que se pone a disposición de la integración
a través de la interfaz del conector. Una acción te permite hacer cambios en una o varias entidades y varía de un conector a otro. Normalmente, una acción tendrá algunos parámetros de entrada y un parámetro de salida. Sin embargo, es posible que un conector no admita ninguna acción, en cuyo caso la lista
Actionsestará vacía.
Acciones
Este conector admite la ejecución de las siguientes acciones:
- Procedimientos almacenados y funciones definidos por el usuario. Si tienes procedimientos y funciones almacenados en tu backend, se mostrarán en la columna
Actionsdel cuadro de diálogoConfigure connector task. - Consultas de SQL personalizadas. Para ejecutar consultas de SQL personalizadas, el conector proporciona la acción Ejecutar consulta personalizada.
Para crear una consulta personalizada, sigue estos pasos:
- Sigue las instrucciones detalladas para añadir una tarea de conectores.
- Cuando configure la tarea del conector, en el tipo de acción que quiera realizar, seleccione Acciones.
- En la lista Acción, selecciona Ejecutar consulta personalizada y, a continuación, haz clic en Hecho.
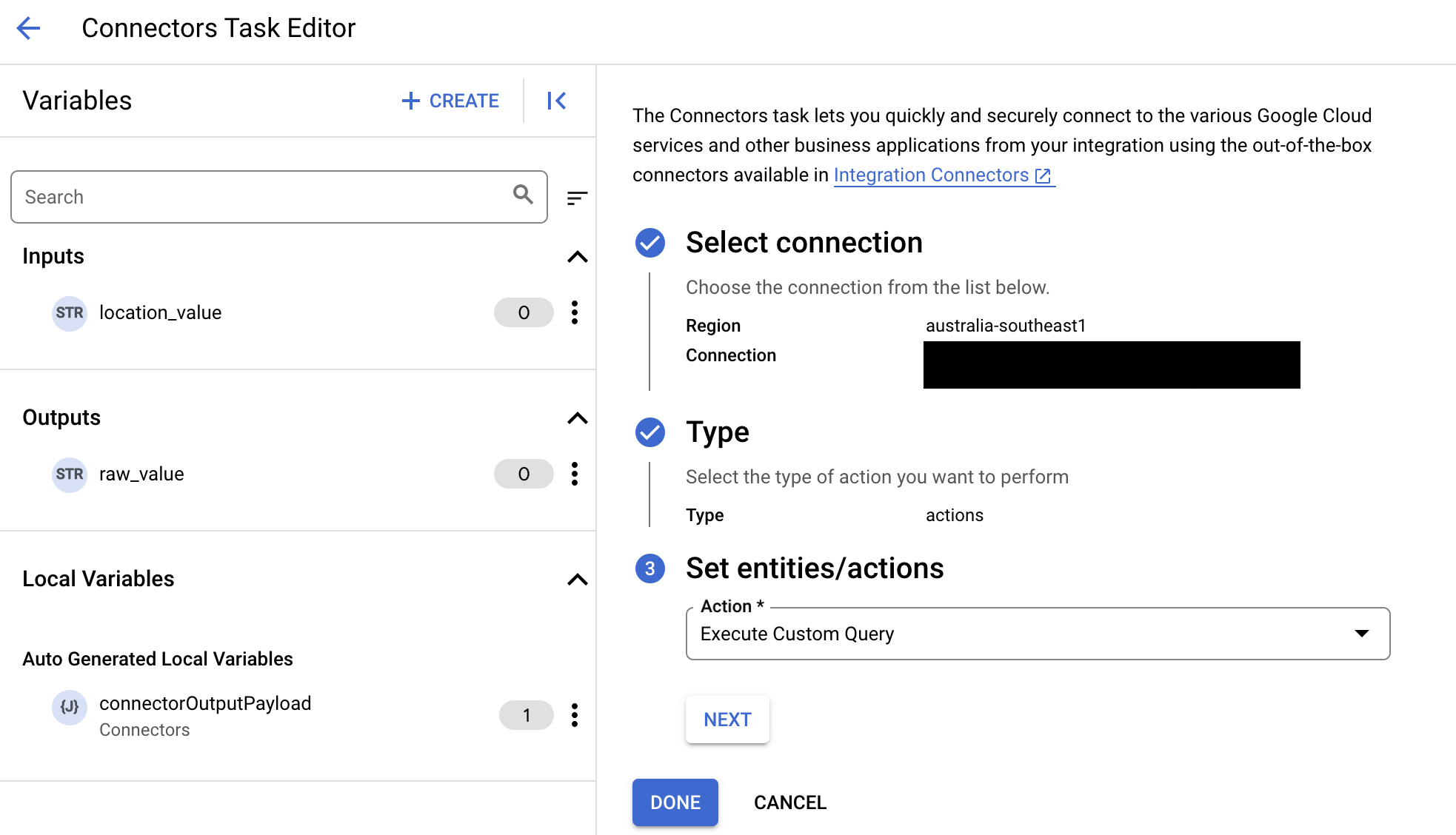
- Despliega la sección Entrada de la tarea y, a continuación, haz lo siguiente:
- En el campo Tiempo de espera tras, introduce el número de segundos que deben transcurrir hasta que se ejecute la consulta.
Valor predeterminado:
180segundos. - En el campo Número máximo de filas, introduzca el número máximo de filas que se devolverán de la base de datos.
Valor predeterminado:
25. - Para actualizar la consulta personalizada, haz clic en Editar secuencia de comandos personalizada. Se abrirá el cuadro de diálogo Editor de secuencias de comandos.
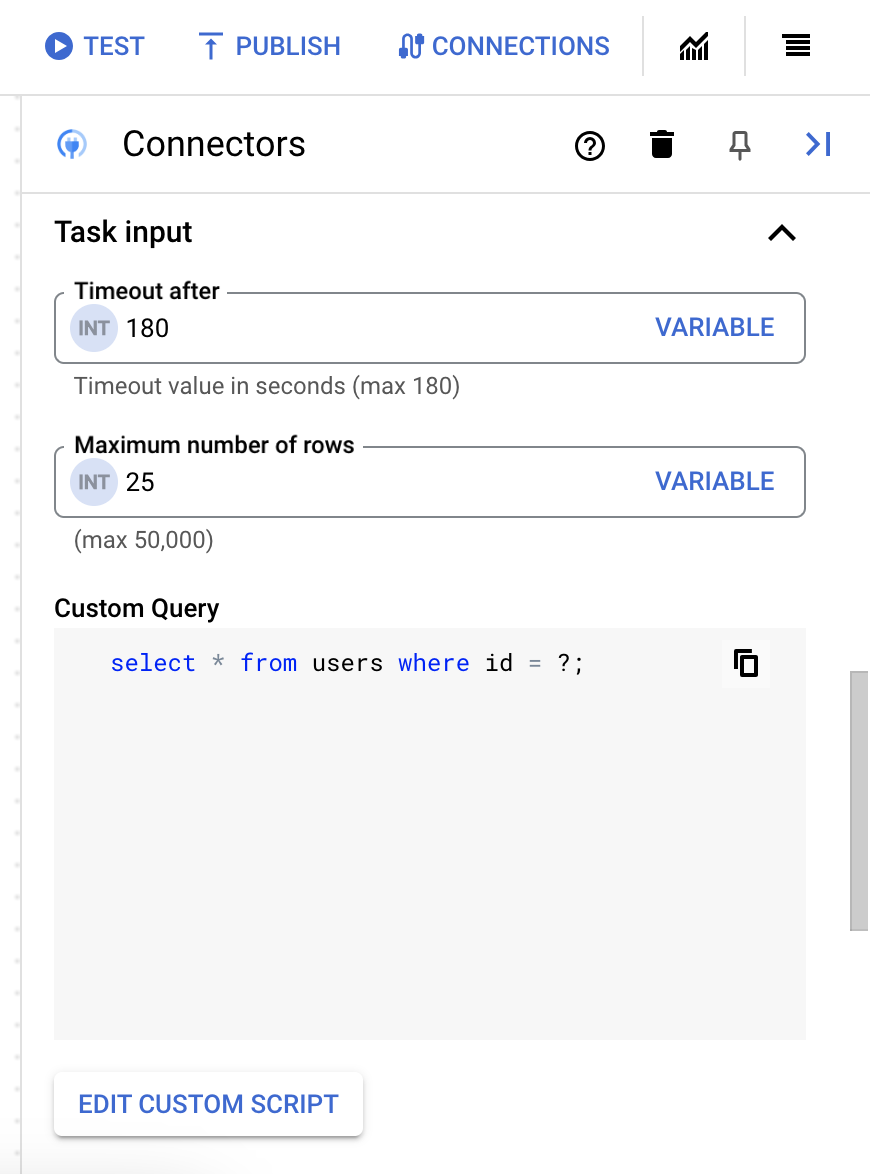
- En el cuadro de diálogo Editor de secuencias de comandos, introduce la consulta de SQL y haz clic en Guardar.
Puedes usar un signo de interrogación (?) en una instrucción SQL para representar un único parámetro que debe especificarse en la lista de parámetros de la consulta. Por ejemplo, la siguiente consulta SQL selecciona todas las filas de la tabla
Employeesque coinciden con los valores especificados en la columnaLastName:SELECT * FROM Employees where LastName=?
- Si has usado signos de interrogación en tu consulta SQL, debes añadir el parámetro haciendo clic en + Añadir nombre de parámetro por cada signo de interrogación. Durante la ejecución de la integración, estos parámetros sustituyen secuencialmente los signos de interrogación (?) de la consulta de SQL. Por ejemplo, si has añadido tres signos de interrogación (?), debes añadir tres parámetros en orden de secuencia.
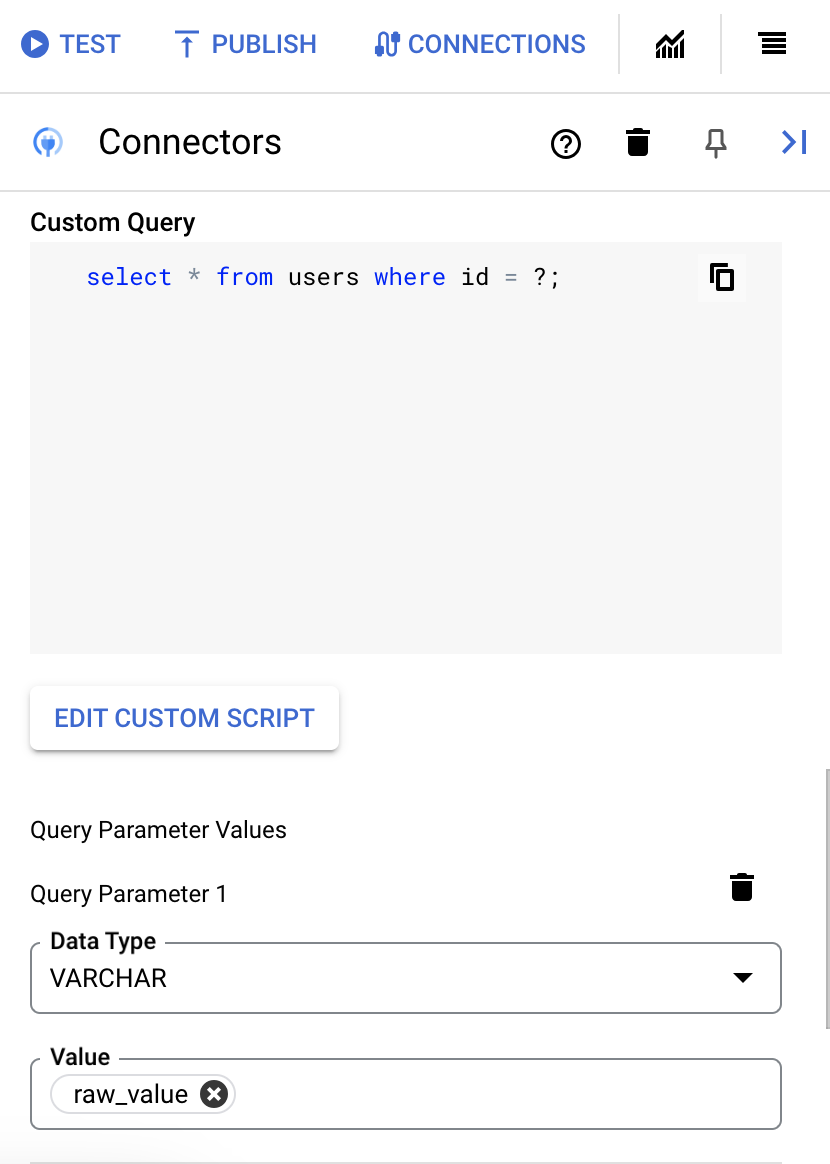
Para añadir parámetros de consulta, siga estos pasos:
- En la lista Tipo, seleccione el tipo de datos del parámetro.
- En el campo Valor, introduzca el valor del parámetro.
- Para añadir varios parámetros, haga clic en + Añadir parámetro de consulta.
La acción Ejecutar consulta personalizada no admite variables de matriz.
- En el campo Tiempo de espera tras, introduce el número de segundos que deben transcurrir hasta que se ejecute la consulta.
Limitaciones del sistema
El conector de Teradata puede procesar un máximo de 70 transacciones por segundo por nodo y limita las transacciones que superen este límite. De forma predeterminada, Integration Connectors asigna 2 nodos (para mejorar la disponibilidad) a una conexión.
Para obtener información sobre los límites aplicables a Integration Connectors, consulta Límites.
Tipos de datos admitidos
Estos son los tipos de datos admitidos por este conector:
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- FECHA
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- HORA
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Acciones
El conector de base de datos Oracle te permite ejecutar tus procedimientos almacenados, funciones y consultas SQL personalizadas en el formato compatible con tu base de datos Oracle. Para ejecutar consultas de SQL personalizadas, el conector proporciona la acción ExecuteCustomQuery.
Acción ExecuteCustomQuery
Esta acción te permite ejecutar consultas SQL personalizadas.
Parámetros de entrada de la acción ExecuteCustomQuery
| Nombre del parámetro | Tipo de datos | Obligatorio | Descripción |
|---|---|---|---|
| query | Cadena | Sí | Consulta que se va a ejecutar. |
| queryParameters | Matriz JSON con el siguiente formato:[{"value": "VALUE", "dataType": "DATA_TYPE"}]
|
No | Los parámetros de consulta |
| maxRows | Número | No | Número máximo de filas que se devolverán. |
| Tiempo de espera | Número | No | Número de segundos que se deben esperar hasta que se ejecute la consulta. |
Parámetros de salida de la acción ExecuteCustomQuery
Si se ejecuta correctamente, esta acción devuelve el estado 200 (OK) con un cuerpo de respuesta que contiene los resultados de la consulta.
Para ver un ejemplo de cómo configurar la acción ExecuteCustomQuery, consulta Ejemplos.
Para saber cómo usar la acción ExecuteCustomQuery, consulta los ejemplos de acciones.
Ejemplos de acciones
En esta sección se describe cómo realizar algunas de las acciones de este conector.
Ejemplo: ejecutar una consulta de agrupación
- En el cuadro de diálogo
Configure connector task, haz clic enActions. - Seleccione la acción
ExecuteCustomQueryy, a continuación, haga clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haz clic en
connectorInputPayloady, a continuación, introduce un valor similar al siguiente en el campoDefault Value:{ "query": "select E.EMPLOYEE_ID,E.EMPLOYEE_NAME,E.CITY from EMPLOYEES E LEFT JOIN EMPLOYEE_DEPARTMENT ED ON E.EMPLOYEE_ID=ED.ID where E.EMPLOYEE_NAME = 'John' Group by E.CITY,E.EMPLOYEE_ID,E.EMPLOYEE_NAME" }
En este ejemplo se seleccionan los registros de empleados de las tablas EMPLOYEES
y EMPLOYEE_DEPARTMENT. Si la acción se realiza correctamente, el parámetro de respuesta connectorOutputPayload de la tarea del conector tendrá el conjunto de resultados de la consulta.
Ejemplo: ejecutar una consulta con parámetros
- En el cuadro de diálogo
Configure connector task, haz clic enActions. - Seleccione la acción
ExecuteCustomQueryy, a continuación, haga clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haz clic en
connectorInputPayloady, a continuación, introduce un valor similar al siguiente en el campoDefault Value:{ "query": "select C.ID,C.NAME,C.CITY,C.O_DATE,E.EMPLOYEE_ID from customqueries C,Employees E where C.ID=E.Employee_id and C.NAME=?", "queryParameters": [{ "value": "John", "dataType": "VARCHAR" }], "timeout":10, "maxRows":3 }
En este ejemplo, se seleccionan los registros de los empleados cuyo nombre es John.
Observe que el nombre del empleado se parametriza mediante el parámetro queryParameters.
Si la acción se realiza correctamente, el parámetro connectorOutputPayload de la respuesta de la tarea del conector tendrá un valor similar al siguiente:
[{ "NAME": "John", "O_DATE": "2023-06-01 00:00:00.0", "EMPLOYEE_ID": 1.0 }, { "NAME": "John", "O_DATE": "2021-07-01 00:00:00.0", "EMPLOYEE_ID": 3.0 }, { "NAME": "John", "O_DATE": "2022-09-01 00:00:00.0", "EMPLOYEE_ID": 4.0 }]
Ejemplo: insertar un registro mediante un valor de secuencia
- En el cuadro de diálogo
Configure connector task, haz clic enActions. - Seleccione la acción
ExecuteCustomQueryy, a continuación, haga clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haz clic en
connectorInputPayloady, a continuación, introduce un valor similar al siguiente en el campoDefault Value:{ "query": "INSERT INTO AUTHOR(id,title) VALUES(author_table_id_seq.NEXTVAL,'Sample_book_title')" }
En este ejemplo se inserta un registro en la tabla AUTHOR mediante un objeto de secuencia author_table_id_seq ya creado. Si la acción se realiza correctamente, el parámetro connectorOutputPayload de la respuesta de la tarea del conector tendrá un valor similar al siguiente:
[{ }]
Ejemplo: ejecutar una consulta con una función de agregación
- En el cuadro de diálogo
Configure connector task, haz clic enActions. - Seleccione la acción
ExecuteCustomQueryy, a continuación, haga clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haz clic en
connectorInputPayloady, a continuación, introduce un valor similar al siguiente en el campoDefault Value:{ "query": "SELECT SUM(SALARY) as Total FROM EMPLOYEES" }
En este ejemplo se calcula el valor agregado de los salarios de la tabla EMPLOYEES. Si la acción se realiza correctamente, el parámetro connectorOutputPayload de la respuesta de la tarea del conector tendrá un valor similar al siguiente:
[{ "TOTAL": 13000.0 }]
Ejemplo: crear una tabla
- En el cuadro de diálogo
Configure connector task, haz clic enActions. - Seleccione la acción
ExecuteCustomQueryy, a continuación, haga clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haz clic en
connectorInputPayloady, a continuación, introduce un valor similar al siguiente en el campoDefault Value:{ "query": "CREATE TABLE TEST1 (ID INT, NAME VARCHAR(40),DEPT VARCHAR(20),CITY VARCHAR(10))" }
En este ejemplo se crea la tabla TEST1. Si la acción se realiza correctamente, el parámetro connectorOutputPayload de la respuesta de la tarea del conector tendrá un valor similar al siguiente:
[{ }]
Ejemplos de operaciones de entidades
Ejemplo: listar todos los empleados
En este ejemplo se enumeran todos los empleados de la entidad Employee.
- En el cuadro de diálogo
Configure connector task, haz clic enEntities. - Selecciona
Employeeen la listaEntity. - Selecciona la operación
Listy, a continuación, haz clic en Hecho. - Opcionalmente, en la sección Entrada de tarea de la tarea Conectores, puedes filtrar el conjunto de resultados especificando una cláusula de filtro.
Ejemplo: obtener los detalles de un empleado
En este ejemplo se obtienen los detalles del empleado con el ID especificado de la entidad Employee.
- En el cuadro de diálogo
Configure connector task, haz clic enEntities. - Selecciona
Employeeen la listaEntity. - Selecciona la operación
Gety, a continuación, haz clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haga clic en EntityId y, a continuación, introduzca
45en el campo Valor predeterminado.En este caso,
45es el valor de clave principal de la entidadEmployee.
Ejemplo: crear un registro de empleado
En este ejemplo se añade un nuevo registro de empleado en la entidad Employee.
- En el cuadro de diálogo
Configure connector task, haz clic enEntities. - Selecciona
Employeeen la listaEntity. - Selecciona la operación
Createy, a continuación, haz clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haz clic en
connectorInputPayloady, a continuación, introduce un valor similar al siguiente en el campoDefault Value:{ "EMPLOYEE_ID": 69.0, "EMPLOYEE_NAME": "John", "CITY": "Bangalore" }
Si la integración se realiza correctamente, el campo
connectorOutputPayloadde la tarea del conector tendrá un valor similar al siguiente:{ "ROWID": "AAAoU0AABAAAc3hAAF" }
Ejemplo: Actualizar un registro de empleado
En este ejemplo se actualiza el registro del empleado cuyo ID es 69 en la entidad Employee.
- En el cuadro de diálogo
Configure connector task, haz clic enEntities. - Selecciona
Employeeen la listaEntity. - Selecciona la operación
Updatey, a continuación, haz clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haz clic en
connectorInputPayloady, a continuación, introduce un valor similar al siguiente en el campoDefault Value:{ "EMPLOYEE_NAME": "John", "CITY": "Mumbai" }
- Haga clic en entityId y, a continuación, introduzca
69en el campo Valor predeterminado.También puede definir filterClause como
69en lugar de especificar entityId.Si la integración se realiza correctamente, el campo
connectorOutputPayloadde la tarea del conector tendrá un valor similar al siguiente:{ }
Ejemplo: eliminar un registro de empleado
En este ejemplo se elimina el registro del empleado con el ID especificado en la entidad Employee.
- En el cuadro de diálogo
Configure connector task, haz clic enEntities. - Selecciona
Employeeen la listaEntity. - Selecciona la operación
Deletey, a continuación, haz clic en Hecho. - En la sección Entrada de tarea de la tarea Conectores, haga clic en entityId y, a continuación, introduzca
35en el campo Valor predeterminado.
Crear conexiones con Terraform
Puedes usar el recurso de Terraform para crear una conexión.
Para saber cómo aplicar o quitar una configuración de Terraform, consulta Comandos básicos de Terraform.
Para ver una plantilla de Terraform de ejemplo para crear una conexión, consulta la plantilla de ejemplo.
Cuando crees esta conexión con Terraform, debes definir las siguientes variables en el archivo de configuración de Terraform:
| Nombre del parámetro | Tipo de datos | Obligatorio | Descripción |
|---|---|---|---|
| client_charset | STRING | Verdadero | Especifica el conjunto de caracteres de Java para codificar y decodificar los datos de caracteres transferidos a la base de datos de Teradata y desde ella. |
| base de datos | STRING | Verdadero | La base de datos seleccionada como predeterminada cuando se abre una conexión de Teradata. |
| cuenta | STRING | Falso | Especifica una cadena de cuenta para anular la cadena de cuenta predeterminada definida para el usuario de la base de datos de Teradata. |
| Conjunto de caracteres | STRING | Verdadero | Especifica el conjunto de caracteres de la sesión para codificar y decodificar los datos de caracteres transferidos a la base de datos de Teradata y desde ella. El valor predeterminado es ASCII. |
| column_name | INTEGER | Verdadero | Controla el comportamiento de los métodos getColumnName y getColumnLabel de ResultSetMetaData. |
| connect_failure_ttl | STRING | Falso | Esta opción permite que el proveedor CData ADO.NET para Teradata recuerde la hora del último error de conexión de cada combinación de dirección IP y puerto. Además, el proveedor CData ADO.NET para Teradata omite los intentos de conexión a esa dirección IP o puerto durante los inicios de sesión posteriores durante el número de segundos especificado por el valor del tiempo de vida de error de conexión (CONNECTFAILURETTL). |
| connect_function | STRING | Falso | Especifica si la base de datos de Teradata debe asignar un número de secuencia de inicio de sesión (LSN) a esta sesión o asociar esta sesión a un LSN ya asignado. |
| policía | STRING | Falso | Especifica si se realiza la detección de COP. |
| cop_last | STRING | Falso | Especifica cómo determina Detección de COP el último nombre de host de COP. |
| ddstats | ENUM | Falso | Especifica el valor de DDSTATS. Los valores admitidos son ON y OFF. |
| disable_auto_commit_in_batch | BOOLEAN | Verdadero | Especifica si se debe inhabilitar la confirmación automática al ejecutar la operación por lotes. |
| encrypt_data | ENUM | Falso | Especifica el valor de EncryptData, ON u OFF. Los valores posibles son ON y OFF. |
| error_query_count | STRING | Falso | Especifica el número máximo de veces que JDBC FastLoad intentará consultar la tabla de errores de FastLoad 1 después de una operación de JDBC FastLoad. |
| error_query_interval | STRING | Falso | Especifica el número de milisegundos que JDBC FastLoad esperará entre los intentos de consultar la tabla de errores de FastLoad 1 después de una operación de JDBC FastLoad. |
| error_table1_suffix | STRING | Falso | Especifica el sufijo del nombre de la tabla de errores de FastLoad 1 creada por JDBC FastLoad y JDBC FastLoad CSV. |
| error_table2_suffix | STRING | Falso | Especifica el sufijo del nombre de la tabla de errores de FastLoad 2 creada por JDBC FastLoad y JDBC FastLoad CSV. |
| error_table_database | STRING | Falso | Especifica el nombre de la base de datos de las tablas de errores de FastLoad creadas por JDBC FastLoad y JDBC FastLoad CSV. |
| field_sep | STRING | Falso | Especifica un separador de campos para usarlo solo con JDBC FastLoad CSV. El separador predeterminado es "," (coma). |
| finalize_auto_close | STRING | Falso | Especifica el valor de FinalizeAutoClose (ON u OFF). |
| geturl_credentials | STRING | Falso | Especifica el valor de GeturlCredentials (ON u OFF). |
| regir | STRING | Falso | Especifica el valor GOVERN, ON u OFF. |
| literal_underscore | STRING | Falso | Escapa automáticamente los patrones de predicado LIKE en las llamadas de DatabaseMetaData, como schemPattern y tableNamePattern. |
| lob_support | STRING | Falso | Especifica el valor de LobSupport (ON u OFF). |
| lob_temp_table | STRING | Falso | Especifica el nombre de una tabla con las siguientes columnas: id integer, bval blob y cval clob. |
| log | STRING | Falso | Especifica el nivel de registro (nivel de detalle) de una conexión. El registro siempre está habilitado. Los niveles de registro se muestran en orden de menor a mayor cantidad de información. |
| log_data | STRING | Falso | Especifica los datos adicionales que necesita un mecanismo de inicio de sesión, como un token seguro, un nombre distintivo o un nombre de dominio o de reino. |
| log_mech | STRING | Falso | Especifica el mecanismo de inicio de sesión, que determina las funciones de autenticación y cifrado de la conexión. |
| logon_sequence_number | STRING | Falso | Especifica un número de secuencia de inicio de sesión (LSN) que ya exista para asociar esta sesión. |
| max_message_body | STRING | Falso | Especifica el tamaño máximo del mensaje de respuesta en bytes. |
| maybe_null | STRING | Falso | Controla el comportamiento del método ResultSetMetaData.isNullable. |
| new_password | STRING | Falso | Este parámetro de conexión permite que una aplicación cambie una contraseña caducada automáticamente. |
| partición | STRING | Falso | Especifica la partición de la base de datos de Teradata de la conexión. |
| prep_support | STRING | Falso | Especifica si la base de datos de Teradata realiza una operación de preparación cuando se crea un objeto PreparedStatement o CallableStatement. |
| reconnect_count | STRING | Falso | Habilita la reconexión de sesiones de Teradata. Especifica el número máximo de veces que el controlador JDBC de Teradata intentará volver a conectar la sesión. |
| reconnect_interval | STRING | Falso | Habilita la reconexión de sesiones de Teradata. Especifica el número de segundos que el controlador JDBC de Teradata esperará entre los intentos de reconexión de la sesión. |
| redrive | STRING | Falso | Habilita la reconexión de sesiones de Teradata y también la repetición automática de solicitudes SQL interrumpidas por el reinicio de la base de datos. |
| run_startup | STRING | Falso | Especifica el valor de RunStartup, ON u OFF. |
| sessions | STRING | Falso | Especifica el número de conexiones FastLoad o FastExport que se van a crear, donde 1 <= número de conexiones FastLoad o FastExport <= número de AMPs. |
| sip_support | STRING | Falso | Controla si Teradata Database y el controlador JDBC de Teradata usan el paquete StatementInfo (SIP) para transmitir metadatos. |
| slob_receive_threshold | STRING | Falso | Controla el tamaño de los valores LOB que se reciben de la base de datos de Teradata. Los valores de LOB pequeños se preobtiene de la base de datos de Teradata antes de que la aplicación lea explícitamente los datos de los objetos Blob o Clob. |
| slob_transmit_threshold | STRING | Falso | Controla cómo se transmiten los valores LOB pequeños a la base de datos de Teradata. |
| sp_spl | STRING | Falso | Especifica el comportamiento para crear o sustituir procedimientos almacenados de Teradata. |
| strict_encode | STRING | Falso | Especifica el comportamiento de la codificación de datos de caracteres para transmitirlos a la base de datos de Teradata. |
| tmode | STRING | Falso | Especifica el modo de transacción de la conexión. |
| tnano | STRING | Falso | Especifica la precisión de los segundos fraccionarios de todos los valores de java.sql.Time enlazados a un objeto PreparedStatement o CallableStatement y transmitidos a la base de datos de Teradata como valores de TIME o TIME WITH TIME ZONE. |
| tsnano | STRING | Falso | Especifica la precisión de los segundos fraccionarios de todos los valores de java.sql.Timestamp vinculados a un objeto PreparedStatement o CallableStatement y transmitidos a la base de datos de Teradata como valores de TIMESTAMP o TIMESTAMP WITH TIME ZONE. |
| tcp | STRING | Falso | Especifica uno o varios ajustes de sockets TCP separados por signos más (). |
| trusted_sql | STRING | Falso | Especifica el valor de TrustedSql. |
| tipo | STRING | Falso | Especifica el tipo de protocolo que se va a usar con la base de datos de Teradata para las instrucciones SQL. |
| upper_case_identifiers | BOOLEAN | Falso | Esta propiedad informa de todos los identificadores en mayúsculas. Este es el valor predeterminado de las bases de datos de Oracle y, por lo tanto, permite una mejor integración con las herramientas de Oracle, como Oracle Database Gateway. |
| use_xviews | STRING | Falso | Especifica qué vistas del diccionario de datos se deben consultar para devolver conjuntos de resultados de los métodos de DatabaseMetaData. |
Usar la conexión de Teradata en una integración
Una vez que hayas creado la conexión, estará disponible tanto en Apigee Integration como en Application Integration. Puedes usar la conexión en una integración a través de la tarea Conectores.
- Para saber cómo crear y usar la tarea Conectores en la integración de Apigee, consulta Tarea Conectores.
- Para saber cómo crear y usar la tarea Conectores en Application Integration, consulta Tarea Conectores.
Obtener ayuda de la comunidad de Google Cloud
Puedes publicar tus preguntas y hablar sobre este conector en la comunidad de Google Cloud, en los foros de Cloud.Siguientes pasos
- Consulta cómo suspender y reanudar una conexión.
- Consulta cómo monitorizar el uso de los conectores.
- Consulta cómo ver los registros de conectores.