Cloud Spanner
Cloud Spanner コネクタを使用すると、Google Cloud Spanner データベースに対して、挿入、削除、更新、読み取りオペレーションを実行できます。
準備
Cloud Spanner コネクタを使用する前に、次の作業を行います。
- Google Cloud プロジェクトで次の操作を行います。
- ネットワーク接続が設定されていることを確認します。ネットワーク パターンの詳細については、Network Connectivity をご覧ください。
- コネクタを構成するユーザーに roles/connectors.admin IAM ロールを付与します。
- コネクタに使用するサービス アカウントに、次の IAM ロールを付与します。
roles/spanner.databaseUser
サービス アカウントは特別なタイプの Google アカウントで、Google API のデータにアクセスするのに認証を受ける必要がある人間以外のユーザーを表します。サービス アカウントがない場合は、サービス アカウントを作成する必要があります。コネクタとサービス アカウントは同じプロジェクトに属している必要があります。詳細については、サービス アカウントを作成するをご覧ください。
- 次のサービスを有効にします。
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
サービスを有効にする方法については、サービスを有効にするをご覧ください。
以前にプロジェクトでこうしたサービスを有効にしていない場合は、コネクタを構成するときにそれを有効にすることを求められます。
コネクタを構成する
接続はデータソースに特有です。つまり、多数のデータソースがある場合は、データソースごとに別々の接続を作成する必要があります。接続を作成する手順は次のとおりです。
- Cloud コンソールで、[Integration Connectors] > [接続] ページに移動し、Google Cloud プロジェクトを選択または作成します。
- [+ 新規作成] をクリックして [接続の作成] ページを開きます。
- [ロケーション] セクションで、接続のロケーションを選択します。
- リージョン: プルダウン リストからロケーションを選択します
サポートされているすべてのリージョンの一覧については、ロケーションをご覧ください。
- [NEXT] をクリックします。
- リージョン: プルダウン リストからロケーションを選択します
- [接続の詳細] セクションで、次の操作を行います。
- コネクタ: 使用可能なコネクタのプルダウン リストから [Cloud Spanner] を選択します。
- コネクタのバージョン: 使用可能なバージョンのプルダウン リストからコネクタのバージョンを選択します。
- [接続名] フィールドに、接続インスタンスの名前を入力します。
接続名は次の条件を満たす必要があります。
- 接続名には英字、数字、ハイフンを使用できます。
- 文字は小文字のみを使用できます。
- 接続名の先頭には英字を設定し、末尾には英字または数字を設定する必要があります。
- 接続名は 49 文字以内で指定してください。
- 必要に応じて、接続インスタンスの [説明] を入力します。
- 必要に応じて、Cloud Logging を有効にして、ログレベルを選択します。デフォルトのログレベルは
Errorに設定されています。 - サービス アカウント: 必要なロールを持つサービス アカウントを選択します。
- 必要に応じて、接続ノードの設定を構成します。
- ノードの最小数: 接続ノードの最小数を入力します。
- ノードの最大数: 接続ノードの最大数を入力します。
ノードは、トランザクションを処理する接続の単位(またはレプリカ)です。1 つの接続でより多くのトランザクションを処理するには、より多くのノードが必要になります。逆に、より少ないトランザクションを処理するには、より少ないノードが必要になります。ノードがコネクタの料金に与える影響については、接続ノードの料金をご覧ください。値を入力しない場合は、デフォルトで最小ノード数は 2 に設定され(可用性を高めるため)、最大ノード数は 50 に設定されます。
- プロジェクト ID: Spanner インスタンスが存在する Google Cloud プロジェクトの ID。
- データベース リージョン: Spanner インスタンスが存在するリージョンの名前。
- インスタンス ID: 接続先の Spanner インスタンスの ID。
- データベース名: 接続先の Spanner データベースの名前。
- 必要に応じて、[+ ラベルを追加] をクリックして Key-Value ペアの形式でラベルを接続に追加します。
- [NEXT] をクリックします。
-
[認証] セクションで、認証の詳細を入力します。
- Cloud Spanner 接続に認証は必要ありません。
- [NEXT] をクリックします。
- Review: 接続と認証の詳細を確認します。
- [作成] をクリックします。
エンティティ、オペレーション、アクション
すべての Integration Connectors が、接続されたアプリケーションのオブジェクトを抽象化するレイヤを提供します。アプリケーションのオブジェクトには、この抽象化を通じてのみアクセスできます。抽象化は、エンティティ、オペレーション、アクションとして公開されます。
- エンティティ: エンティティは、接続されているアプリケーションやサービスのオブジェクト、またはプロパティのコレクションと考えることができます。エンティティの定義は、コネクタによって異なります。たとえば、データベース コネクタでは、テーブルがエンティティであり、ファイル サーバー コネクタでは、フォルダがエンティティです。また、メッセージング システム コネクタでは、キューがエンティティです。
ただし、コネクタでいずれのエンティティもサポートされていない、またはエンティティが存在しない可能性があります。その場合、
Entitiesリストは空になります。 - オペレーション: エンティティに対して行うことができるアクティビティです。エンティティに対して次のいずれかのオペレーションを行うことができます。
使用可能なリストからエンティティを選択すると、そのエンティティで使用可能なオペレーションのリストが生成されます。オペレーションの詳細については、コネクタタスクのエンティティ オペレーションをご覧ください。ただし、コネクタがいずれかのエンティティ オペレーションをサポートしていない場合、サポートされていないオペレーションは
Operationsリストに含まれません。 - アクション: コネクタ インターフェースを介して統合で使用できる主要な関数の一つです。アクションを使用すると、1 つまたは複数のエンティティに対して変更を加えることができます。また、使用できるアクションはコネクタごとに異なります。通常、アクションには入力パラメータと出力パラメータがあります。ただし、コネクタがどのアクションもサポートしていない可能性があります。その場合は、
Actionsリストが空になります。
アクション
このコネクタは、次のアクションの実行をサポートしています。
- ユーザー定義のストアド プロシージャと関数。バックエンドにストアド プロシージャと関数がある場合、それらは
Configure connector taskダイアログのActions列に表示されます。 - カスタム SQL クエリ。カスタム SQL クエリを実行するため、コネクタは [カスタムクエリを実行する] アクションを備えています。
カスタムクエリを作成する手順は次のとおりです。
- 詳細な手順に沿って、コネクタタスクを追加します。
- コネクタタスクを構成するときに、実行するアクションの種類で [Actions] を選択します。
- [Actions] リストで [Execute custom query] を選択し、[Done] をクリックします。
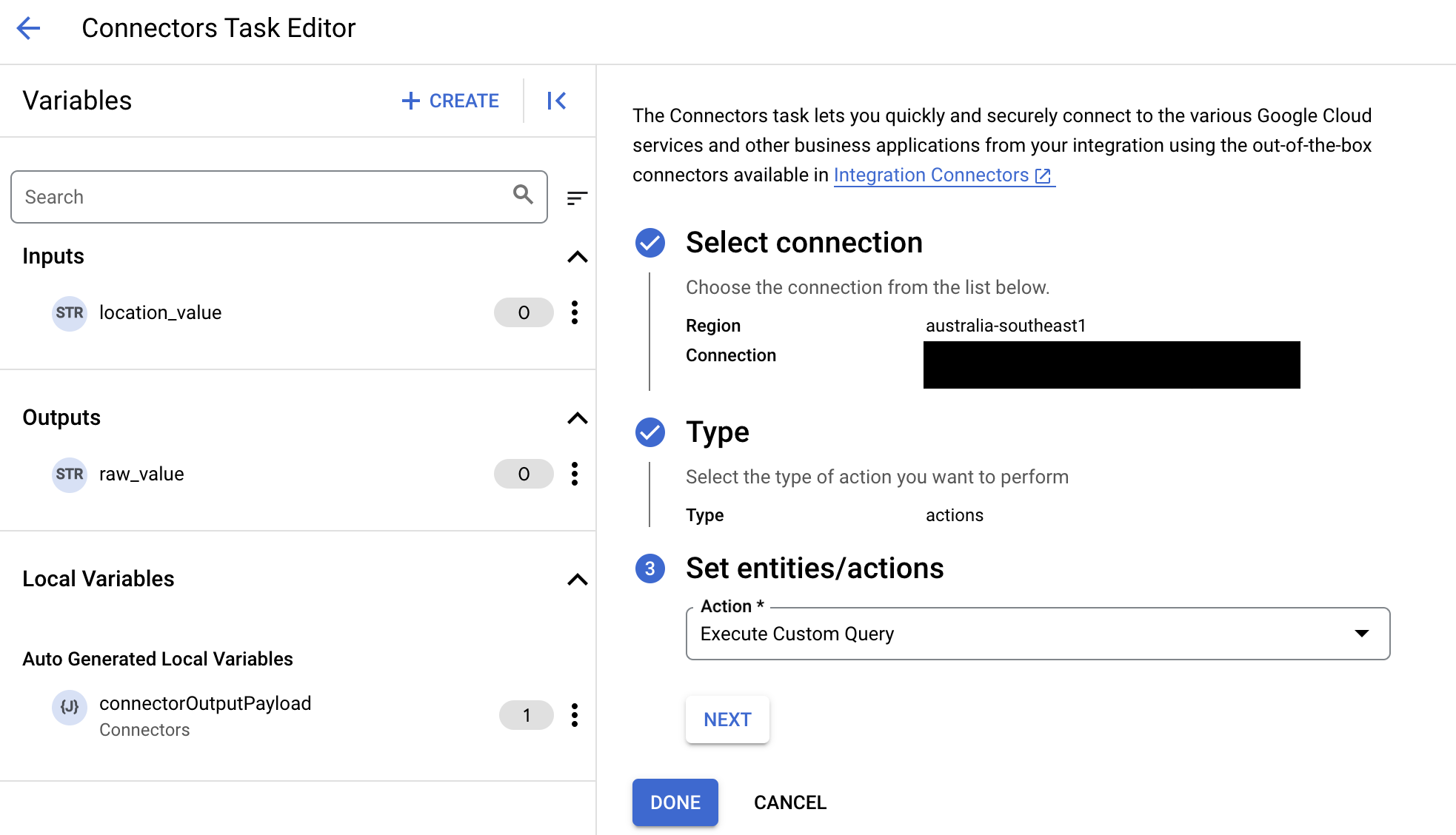
- [Task input] セクションを開き、次の操作を行います。
- [タイムアウト後] フィールドに、クエリが実行されるまで待機する秒数を入力します。
デフォルト値:
180秒 - [Maximum number of rows] フィールドに、データベースから返される最大行数を入力します。
デフォルト値:
25。 - カスタムクエリを更新するには、[Edit Custom Script] をクリックします。[Script editor] ダイアログが開きます。
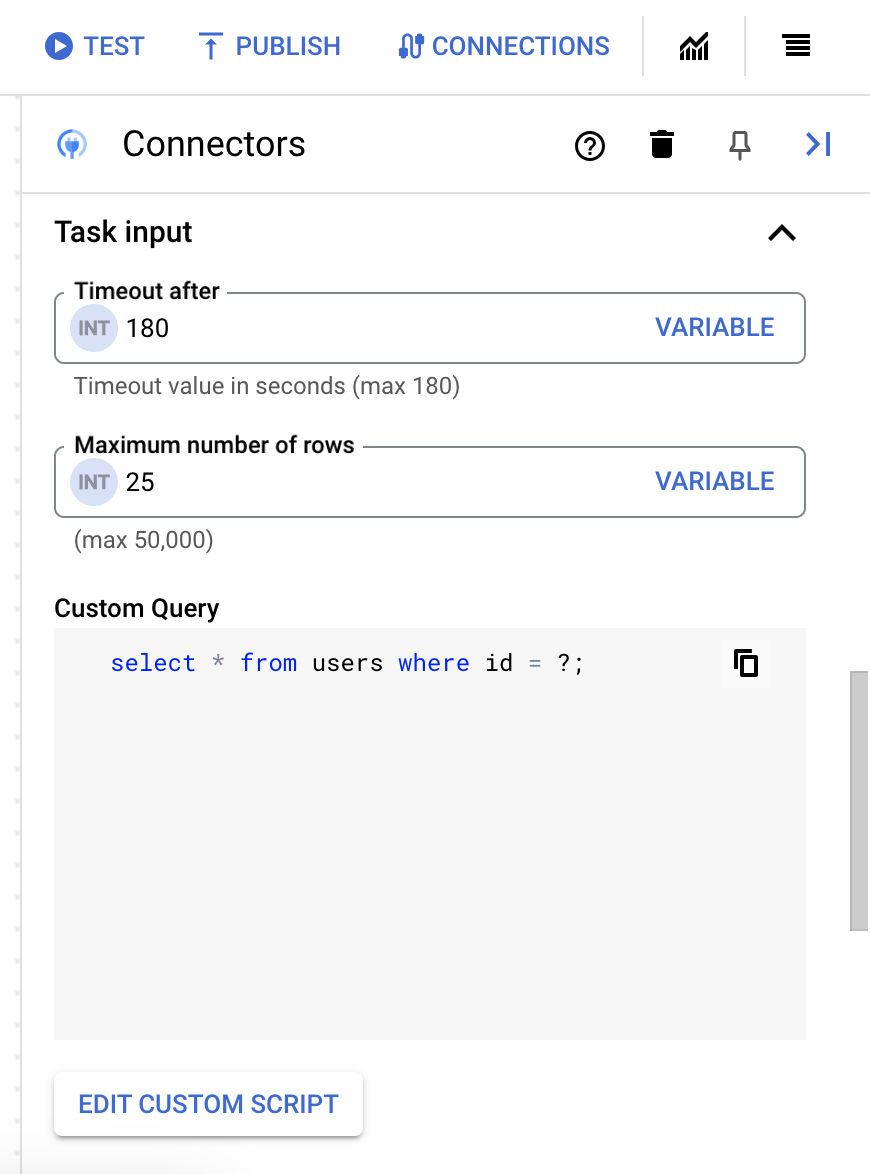
- [Script editor] ダイアログで、SQL クエリを入力して [Save] をクリックします。
SQL ステートメントで疑問符(?)を使用して、クエリ パラメータ リストで指定する必要がある 1 つのパラメータを表すことができます。たとえば、次の SQL クエリは、
LastName列に指定された値と一致するEmployeesテーブルからすべての行を選択します。SELECT * FROM Employees where LastName=?
- SQL クエリで疑問符を使用した場合は、各疑問符の [+ パラメータ名を追加] をクリックして、パラメータを追加する必要があります。統合の実行中に、これらのパラメータにより SQL クエリ内の疑問符(?)が順番に置き換わります。たとえば、3 つの疑問符(?)を追加した場合、3 つのパラメータを順番に追加する必要があります。
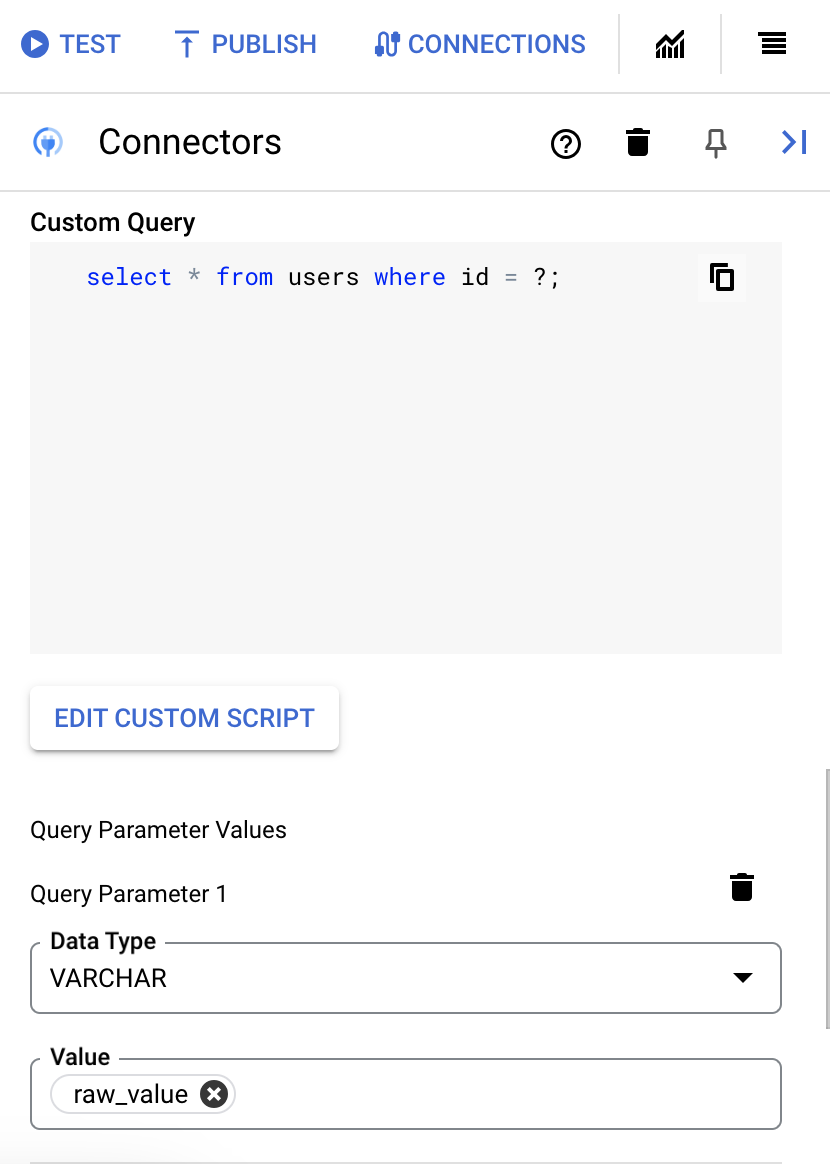
クエリ パラメータを追加する手順は次のとおりです。
- [Type] リストから、パラメータのデータ型を選択します。
- [Value] フィールドに、パラメータの値を入力します。
- 複数のパラメータを追加するには、[+ クエリ パラメータを追加] をクリックします。
カスタムクエリの実行アクションは、配列変数をサポートしていません。
- [タイムアウト後] フィールドに、クエリが実行されるまで待機する秒数を入力します。
サポートされるデータ型
このコネクタでサポートされているデータ型は次のとおりです。
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Terraform を使用して接続を作成する
Terraform リソースを使用して、新しい接続を作成できます。
Terraform 構成を適用または削除する方法については、基本的な Terraform コマンドをご覧ください。
接続作成用の Terraform テンプレートのサンプルを表示するには、サンプル テンプレートをご覧ください。
Terraform を使用してこの接続を作成する場合は、Terraform 構成ファイルで次の変数を設定する必要があります。
| パラメータ名 | データ型 | 必須 | 説明 |
|---|---|---|---|
| project_id | STRING | True | Spanner インスタンスが存在する Google Cloud プロジェクトの ID。 |
| database_region | STRING | True | Spanner インスタンスが存在するリージョンの名前。 |
| instance_id | STRING | True | 接続先の Spanner インスタンスの ID。 |
| database_name | STRING | True | 接続先の Spanner データベースの名前。 |
| database_dialect | ENUM | True | Spanner データベースのデータベース言語の種類を指定します。サポートされている値: GoogleStandardSQL、PostgreSQL |
統合で Cloud Spanner 接続を使用する
接続を作成すると、Apigee Integration と Application Integration の両方で使用できるようになります。この接続は、コネクタタスクを介して統合で使用できます。
- Apigee Integration で Connectors タスクを作成して使用する方法については、Connectors タスクをご覧ください。
- Application Integration で Connectors タスクを作成して使用する方法については、Connectors タスクをご覧ください。
Google Cloud コミュニティの助けを借りる
Google Cloud コミュニティの Cloud フォーラムで質問を投稿したり、このコネクタについてディスカッションしたりできます。次のステップ
- 接続を一時停止して再開する方法を確認する。
- コネクタの使用状況をモニタリングする方法を確認する。
- コネクタログを表示する方法を確認する。