Cette page explique comment enregistrer des données utilisateur à l'aide de l'API Consent Management.
Les éléments de données sont enregistrés auprès de l'API Consent Management et connectés aux autorisations à l'aide des mappages de données utilisateur. Les données utilisateur ne sont jamais stockées dans l'API Consent Management.
Les mappages de données utilisateur, représentés par des ressources UserDataMappings, comprennent les éléments suivants :
- Un ID utilisateur qui identifie l'utilisateur. Cet ID correspond à l'ID fourni par l'application à l'API Consent Management lors de l'enregistrement de l'autorisation.
- Un ID de données qui identifie les données utilisateur stockées ailleurs, par exemple surGoogle Cloud ou sur site. L'ID de données peut être un ID opaque, une URL ou tout autre identifiant.
- Les attributs de ressource, qui décrivent les caractéristiques des données utilisateur à l'aide des valeurs d'attributs de ressource configurées pour le magasin d'autorisations, à l'aide de définitions d'attributs. Par exemple, les données peuvent inclure
attribute_definition_iddata_identifiableavec la valeurde-identified.
Le schéma suivant illustre le flux de données utilisé pour créer des mappages de données utilisateur :
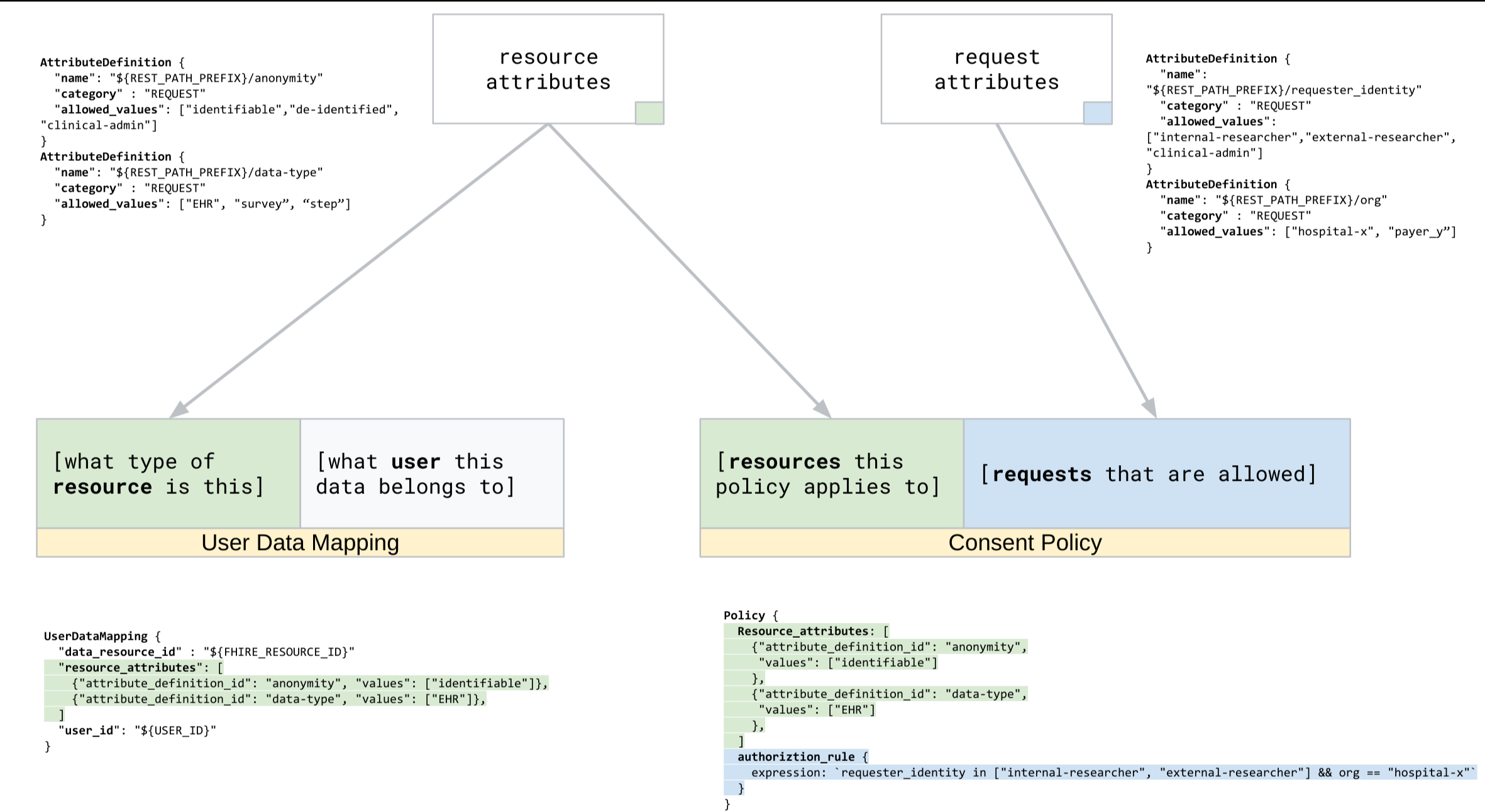
Enregistrer des mappages de données utilisateur
Pour créer un mappage de données utilisateur, utilisez la méthode projects.locations.datasets.consentStores.userDataMappings.create. Effectuez une requête POST et spécifiez les informations suivantes dans la requête :
- Nom du magasin d'autorisations parent
- Une valeur
userIDunique et opaque représentant l'utilisateur auquel l'élément de données est associé - Un identifiant pour la ressource de données utilisateur, tel que le chemin REST vers une ressource unique
- Un ensemble d'attributs
RESOURCEdécrivant l'élément de données - Un jeton d'accès
curl
L'exemple suivant montre une requête POST utilisant curl :
curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/consent+json; charset=utf-8" \ --data "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" \ "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings"
Si la requête aboutit, le serveur affiche une réponse semblable à l'exemple suivant au format JSON :
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
PowerShell
L'exemple suivant montre une requête POST utilisant Windows PowerShell :
$cred = gcloud auth application-default print-access-token $headers = @{ Authorization = "Bearer $cred" } Invoke-WebRequest ` -Method Post ` -Headers $headers ` -ContentType: "application/consent+json; charset=utf-8" ` -Body "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" ` -Uri "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings" | Select-Object -Expand Content
Si la requête aboutit, le serveur affiche une réponse semblable à l'exemple suivant au format JSON :
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
Configurer des ID de données
Le champ data_id de la ressource de mappage de données utilisateur contient une chaîne spécifiée par le client qui décrit les données auxquelles la ressource de mappage de données utilisateur fait référence. Toutes les chaînes sont autorisées, par exemple un ID ou un URI opaque.
Les ID de données peuvent être aussi précis que requis par votre application. Si les données que vous enregistrez peuvent être décrites au niveau de la table ou du bucket, définissez data_id comme chemin REST vers cette ressource.
Si les données que vous enregistrez nécessitent davantage de précision, vous pouvez spécifier des lignes ou des cellules spécifiques. Si votre application utilise des ressources conceptuelles, telles que des actions ou des classes de données autorisées, vous devez définir data_id avec une convention qui supporte ces cas d'utilisation.
Voici quelques exemples de data_id décrivant des données stockées dans différents services et à différents niveaux de précision :
Objet Google Cloud Storage
'data_id' : 'gs://BUCKET_NAME/OBJECT_NAME'
Objet Amazon S3
'data_id' : 'https://BUCKET_NAME.s3.REGION.amazonaws.com/OBJECT_NAME'
Table BigQuery
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID'
Ligne BigQuery (Il n'existe pas de chemin REST pour une ligne BigQuery. Votre propre identifiant est donc nécessaire. Vous trouverez ci-dessous une approche possible)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID'
Cellule BigQuery (Il n'existe pas de chemin REST pour une ligne BigQuery. Votre propre identifiant est donc nécessaire. Vous trouverez ci-dessous une approche possible)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID/myColumns/COLUMN_ID'
Ressource FHIR
'data_id' : 'https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/fhirStores/FHIR_STORE_ID/fhir/Patient/PATIENT_ID'
Représentation conceptuelle
'data_id' : 'wearables/fitness/step_count/daily_sum'