L'entraînement et l'extraction de l'IA générative vous permettent :
- Utilisez la technologie zero-shot et few-shot pour obtenir un modèle très performant avec peu ou pas de données d'entraînement à l'aide du modèle de fondation.
- Utilisez le réglage fin pour améliorer encore la précision à mesure que vous fournissez de plus en plus de données d'entraînement.
Méthodes d'entraînement de l'IA générative
La méthode d'entraînement que vous choisissez dépend du nombre de documents dont vous disposez et de l'effort que vous êtes prêt à consacrer à l'entraînement de votre modèle. Il existe trois façons d'entraîner un modèle d'IA générative :
| Méthode d'entraînement | Zero-shot | Few-shot | Affinage |
|---|---|---|---|
| Justesse | Moyenne | Moyenne à élevée | Élevée |
| Effort | Faible | Faible | Moyenne |
| Nombre recommandé de documents d'entraînement | 0 | 5 à 10 | 10 à 50 ou plus |
Versions des modèles d'extracteur personnalisé
Les modèles suivants sont disponibles pour l'extracteur personnalisé. Pour modifier les versions de modèle, consultez Gérer les versions de l'outil de traitement.
Les versions 1.3, 1.4, 1.5 et 1.5 Pro sont compatibles avec les scores de confiance, contrairement à la version 1.2.
| Version de modèle | Description | Version disponible | Traitement ML aux États-Unis et dans l'UE | Affinage aux États-Unis et dans l'UE | Date de disponibilité |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
Modèle disponible dans le commerce, optimisé par le LLM Gemini 2.0 Flash. Inclut également des fonctionnalités avancées de reconnaissance optique des caractères, comme la détection des cases à cocher. | Stable | Oui | États-Unis, Europe | 5 février 2025 |
pretrained-foundation-model-v1.5-2025-05-05 |
Candidat prêt pour la production, optimisé par le LLM Gemini 2.5 Flash. Recommandé pour ceux qui souhaitent tester les nouveaux modèles. | Stable | Oui | États-Unis, UE (preview) | 5 mai 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Modèle prêt pour la production, optimisé par le LLM Gemini 2.5 Pro. Il accepte un quota de 30 pages par minute pour les requêtes de traitement en ligne. Ce modèle offre une qualité améliorée par rapport à la version 1.5 et peut présenter une latence plus élevée. | Stable | Oui | Non | 20 juin 2025 |
Pour modifier la version du processeur dans votre projet, consultez Gérer les versions de l'outil de traitement.
Pour effectuer une demande d'augmentation de quota (DAQ) pour le quota de processeurs par défaut, suivez les étapes décrites dans Gérer votre quota.
Configuration initiale
Si vous ne l'avez pas déjà fait, activez la facturation et les API Document AI.
Créer et évaluer un modèle d'IA générative
Créez un processeur et définissez les champs que vous souhaitez extraire en suivant les bonnes pratiques. C'est important, car cela a un impact sur la qualité de l'extraction.
- Accédez à Workbench > Extracteur personnalisé > Créer un processeur > Attribuer un nom.

- Accédez à Commencer > Créer un champ.

Importer des documents
- Importez des documents avec l'étiquetage automatique et attribuez-les aux ensembles d'entraînement et de test.
- Pour le zero-shot, seul le schéma est requis. Pour évaluer la précision du modèle, seul un ensemble de test est nécessaire.
- Pour le few-shot, nous recommandons cinq documents d'entraînement.
- Le nombre de documents de test nécessaires dépend du cas d'utilisation. En règle générale, plus vous disposez de documents de test, mieux c'est.
- Confirmez ou modifiez les libellés dans le document.
Entraîner le modèle :
- Sélectionnez Compiler, puis Créer une version.
- Saisissez un nom, puis sélectionnez Créer.

Évaluation :
- Accédez à Évaluer et tester, sélectionnez la version que vous venez d'entraîner, puis cliquez sur Afficher l'évaluation complète.

- Vous voyez maintenant des métriques telles que f1, la précision et le rappel pour l'ensemble du document et pour chaque champ.
- Déterminez si les performances répondent à vos objectifs de production. Si ce n'est pas le cas, réévaluez les ensembles d'entraînement et de test.
Définissez une nouvelle version par défaut :
- Accédez à Gérer les versions.
- Développez les options, puis sélectionnez Définir comme valeur par défaut.

Votre modèle est désormais déployé. Les documents envoyés à ce processeur utilisent votre version personnalisée. Vous pouvez évaluer les performances du modèle pour vérifier s'il nécessite un entraînement supplémentaire.
Référence d'évaluation
Le moteur d'évaluation peut effectuer une correspondance exacte ou approximative. Pour une correspondance exacte, la valeur extraite doit correspondre exactement à la vérité terrain. Dans le cas contraire, elle est considérée comme une erreur.
Les extractions par correspondance approximative qui présentent de légères différences, comme des différences de casse, sont toujours considérées comme des correspondances. Vous pouvez le modifier sur l'écran Évaluation.

Affinage
Avec l'ajustement, vous utilisez des centaines ou des milliers de documents pour votre entraînement.
Créez un processeur et définissez les champs que vous souhaitez extraire en suivant les bonnes pratiques. C'est important, car cela a un impact sur la qualité de l'extraction.
Importez des documents avec l'étiquetage automatique, puis attribuez-les à l'ensemble d'entraînement et à l'ensemble de test.
Confirmez ou modifiez les libellés dans le document.
Entraîner le modèle
- Sélectionnez l'onglet Créer, puis Créer une version dans la section Finetuning.
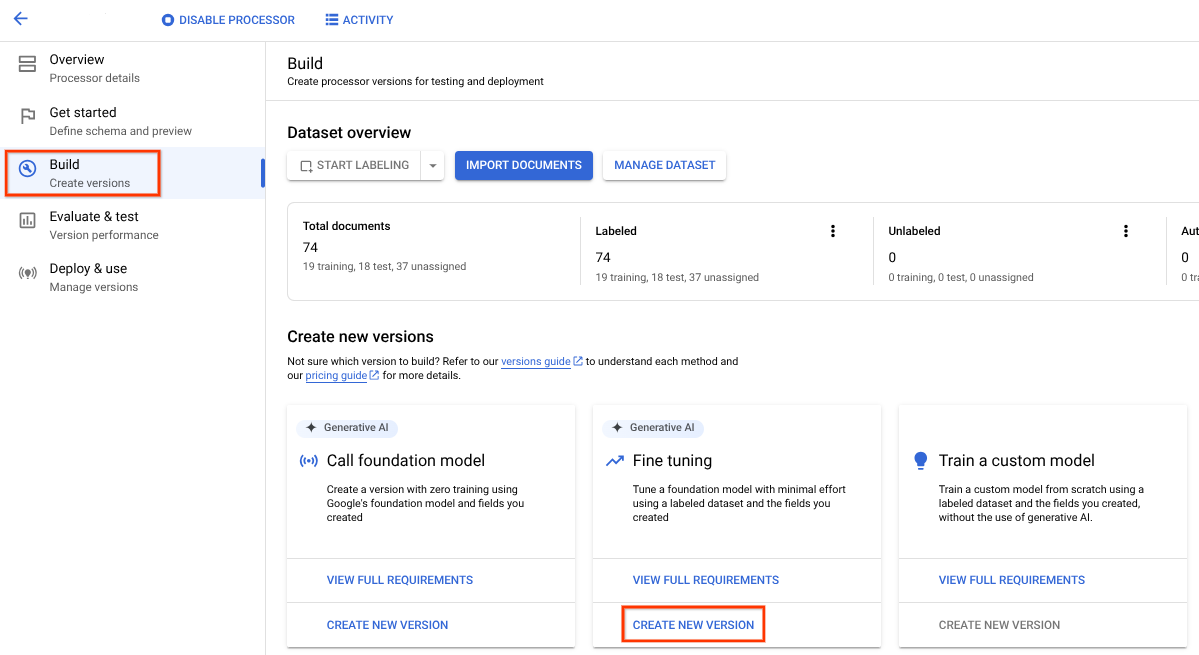
Essayez les paramètres ou les valeurs d'entraînement par défaut fournis. Si les résultats ne vous conviennent pas, essayez ces options avancées :
Étapes d'entraînement (entre 100 et 400) : contrôlent la fréquence à laquelle les pondérations sont optimisées sur un lot de données pendant l'ajustement.
- Si elle est trop faible, l'entraînement risque de se terminer avant la convergence (sous-apprentissage).
- Si elle est trop élevée, le modèle peut voir le même lot de données plusieurs fois au cours de l'entraînement, ce qui peut entraîner un surapprentissage.
- Moins il y a d'étapes, plus l'entraînement est rapide. Un nombre plus élevé peut être utile pour les documents avec peu de variations de modèle (et un nombre plus faible pour ceux avec plus de variations).
Multiplicateur du taux d'apprentissage (entre 0,1 et 10) : contrôle la vitesse à laquelle les paramètres du modèle sont optimisés sur les données d'entraînement. Elle correspond approximativement à la taille de chaque étape d'entraînement.
- Les taux faibles signifient de petites modifications des pondérations du modèle à chaque étape de l'entraînement. Si elle est trop faible, le modèle risque de ne pas converger vers une solution stable.
- Des taux élevés indiquent des changements importants. S'ils sont trop élevés, le modèle peut dépasser la solution optimale et converger vers une solution sous-optimale.
- Le temps d'entraînement n'est pas affecté par le choix du taux d'apprentissage.
Attribuez un nom, sélectionnez la version de processeur de base requise, puis cliquez sur Créer.

Évaluation : accédez à Évaluer et tester, puis sélectionnez la version que vous venez d'entraîner et Afficher l'évaluation complète.
- Vous voyez maintenant des métriques telles que f1, la précision et le rappel pour l'ensemble du document et pour chaque champ.
- Déterminez si les performances répondent à vos objectifs de production. Si ce n'est pas le cas, des documents de formation supplémentaires peuvent être nécessaires.
Définissez une nouvelle version par défaut :
- Accédez à Gérer les versions.
- Sélectionnez l'option Définir comme paramètre par défaut.
Votre modèle est désormais déployé et les documents envoyés à ce processeur utilisent désormais votre version personnalisée. Vous souhaitez évaluer les performances du modèle pour vérifier s'il nécessite un entraînement supplémentaire.
Étiquetage automatique avec le modèle de fondation
Le modèle de fondation peut extraire avec précision des champs à partir de types de documents divers, mais vous pouvez également fournir des données d'entraînement supplémentaires afin d'améliorer sa précision pour des structures de documents spécifiques.
Document AI utilise les noms d'étiquettes que vous avez définis et les annotations précédentes pour faciliter et accélérer l'étiquetage des documents à grande échelle grâce à l'étiquetage automatique.
- Une fois que vous avez créé un processeur personnalisé, accédez à l'onglet Premiers pas.
- Sélectionnez Créer un champ.
Attribuez au libellé un nom descriptif et distinct. Choisissez Extraire pour les valeurs directement issues du document ou Dériver pour les valeurs inférées par le système. Cela améliore la précision et les performances du modèle de fondation.

Pour améliorer la précision et les performances de l'extraction, ajoutez une description (par exemple, un contexte, des insights et des connaissances préalables pour chaque entité) pour les types d'entités qu'il doit identifier.

Accédez à l'onglet Compiler, puis sélectionnez Importer des documents.

Sélectionnez le chemin d'accès aux documents et l'ensemble dans lequel ils doivent être importés. Cochez l'option d'étiquetage automatique et sélectionnez le modèle de fondation.
Dans l'onglet Compiler, sélectionnez Gérer l'ensemble de données.
Lorsque vous voyez vos documents importés, sélectionnez-en un.

Les prédictions du modèle sont désormais mises en évidence en violet.
- Examinez chaque libellé prédit par le modèle et vérifiez qu'il est correct.
S'il manque des champs, ajoutez-les également.

Une fois le document examiné, sélectionnez Marquer comme étiqueté. Le document est maintenant prêt à être utilisé par le modèle.
Assurez-vous que le document se trouve dans l'ensemble de test ou d'entraînement.
Imbrication à trois niveaux
L'extracteur personnalisé propose désormais trois niveaux d'imbrication. Cette fonctionnalité permet une meilleure extraction des tableaux complexes.
Vous pouvez déterminer le type de modèle à l'aide des appels d'API suivants :
La réponse est un ProcessorVersion, qui contient le champ modelType dans l'aperçu v1beta3.
Procédure et exemple
Nous utilisons cet exemple :

Sélectionnez Commencer, puis créez un champ :
- Créez le niveau supérieur.
- Dans cet exemple,
officer_appointmentsest utilisé. - Sélectionnez Il s'agit d'une étiquette parente.
- Sélectionnez Occurrence :
Optional multiple.



Sélectionnez Ajouter un champ enfant. Vous pouvez maintenant créer le libellé de deuxième niveau :
- Pour ce libellé de niveau, créez
officer. - Sélectionnez Il s'agit d'une étiquette parente.
- Sélectionnez Occurrence :
Optional multiple.


- Pour ce libellé de niveau, créez
Sélectionnez Ajouter un champ enfant à partir du deuxième niveau
officer. Créez des libellés enfants pour le troisième niveau d'imbrication.
Une fois votre schéma défini, vous pouvez obtenir des prédictions à partir de documents comportant trois niveaux d'imbrication à l'aide de l'étiquetage automatique.


Libeller les entités imbriquées sur plusieurs pages
Le processeur pretrained-foundation-model-v1.5-2025-05-05 accepte l'imbrication sur trois niveaux sur les pages.
Attribuez un libellé à une entité normalement sur une page. Remarque : L'entité libellée ne sera visible que sur la page où elle est libellée. La barre de navigation change d'une page à l'autre. En épinglant l'entité parente, cette barre de navigation persiste.
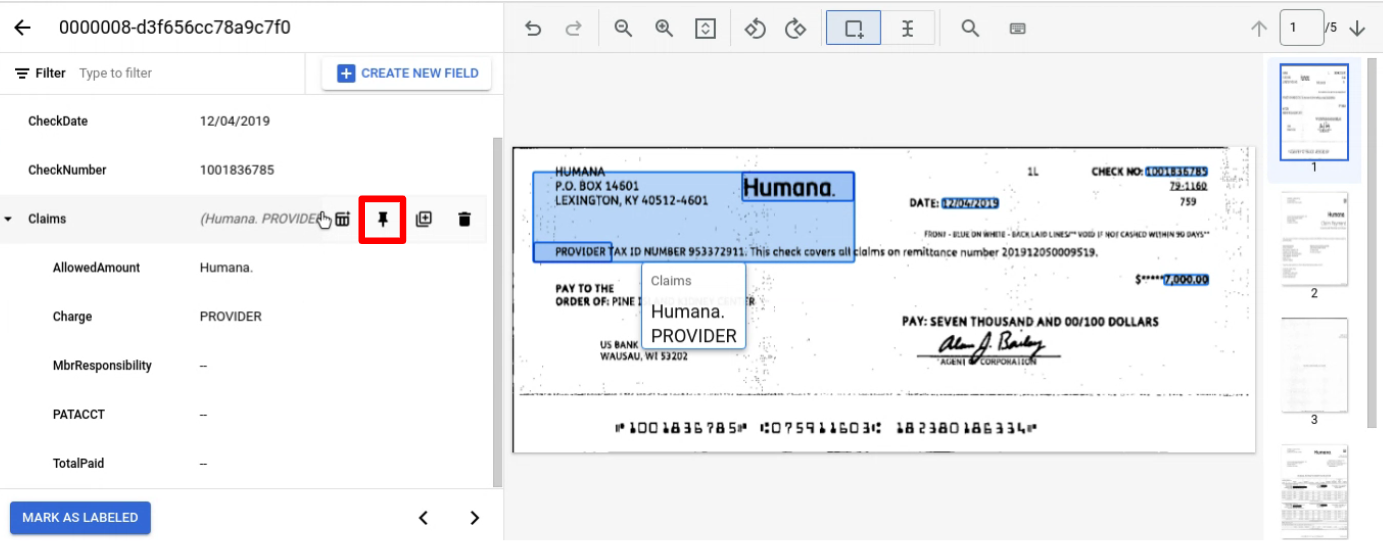
Épinglez l'entité parente avec les enfants que vous souhaitez étiqueter sur plusieurs pages.

Accédez à la page contenant la ou les entités enfants à libeller.
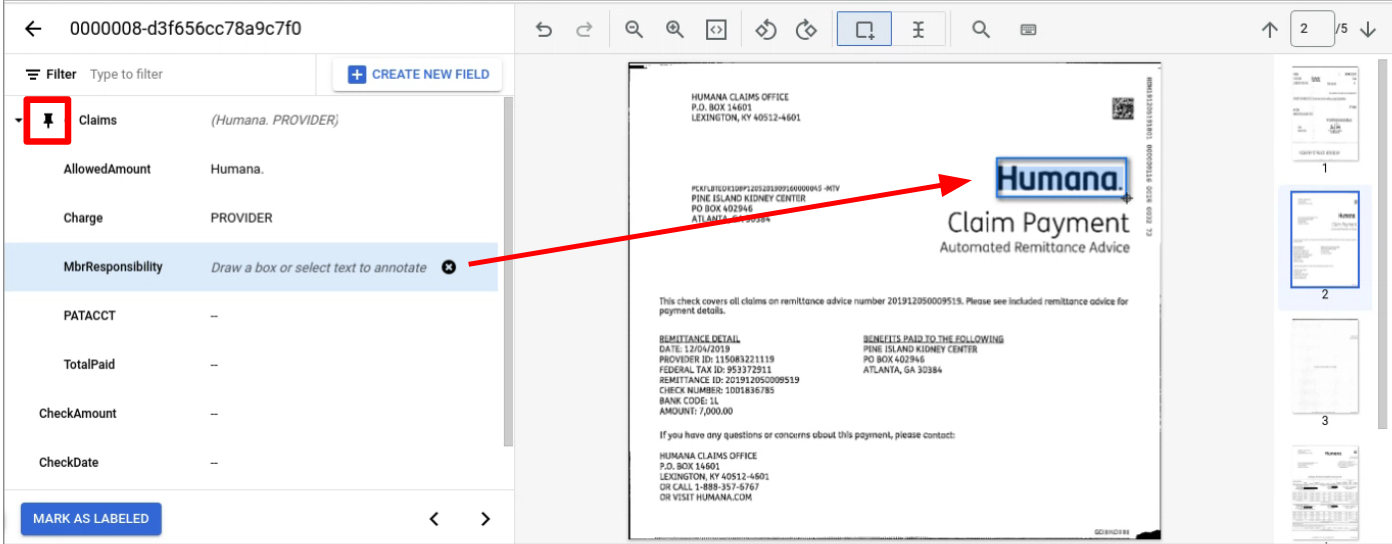
Configuration d'ensemble de données
Un ensemble de données de documents est requis pour entraîner, surentraîner ou évaluer une version du processeur. Les processeurs Document AI apprennent à partir d'exemples, tout comme les humains. L'ensemble de données alimente la stabilité du processeur en termes de performances.Ensemble de données d'entraînement
Pour améliorer le modèle et sa précision, entraînez un ensemble de données sur vos documents. Le modèle est constitué de documents avec vérité terrain.- Pour l'affinage, vous avez besoin d'au moins un document pour entraîner un nouveau modèle avec la version
pretrained-foundation-model-v1.2-2024-05-10etpretrained-foundation-model-v1.3-2024-08-31. - Pour un few-shot, nous recommandons cinq documents.
- Pour le zero-shot, seul un schéma est requis.
Ensemble de données de test
L'ensemble de données de test est ce que le modèle utilise pour générer un score F1 (précision). Il est composé de documents avec une vérité terrain. Pour savoir à quelle fréquence le modèle a raison, la vérité terrain est utilisée pour comparer les prédictions du modèle (champs extraits du modèle) aux bonnes réponses. L'ensemble de données de test doit contenir au moins un document pourpretrained-foundation-model-v1.2-2024-05-10 et pretrained-foundation-model-v1.3-2024-08-31.
Extracteur personnalisé avec descriptions de propriétés
Les descriptions de propriétés vous permettent d'entraîner un modèle en décrivant les champs étiquetés. Vous pouvez fournir du contexte et des insights supplémentaires pour chaque entité. Cela permet au modèle de s'entraîner en faisant correspondre les champs qui correspondent à la description que vous fournissez et d'améliorer la précision de l'extraction. Les descriptions de propriétés peuvent être spécifiées pour les entités parent et enfant.
De bons exemples de descriptions de propriétés incluent des informations sur la localisation et des modèles de texte des valeurs de propriété, qui aident à lever les ambiguïtés potentielles dans le document. Des descriptions de propriétés claires et précises guident le modèle avec des règles qui favorisent des extractions plus fiables et cohérentes, quelle que soit la structure spécifique du document ou les variations de contenu.
Mettre à jour le schéma de document pour un processeur
Pour savoir comment définir les descriptions des propriétés, consultez Mettre à jour le schéma du document.
Envoyer une demande de traitement avec des descriptions de propriétés
Si le schéma du document comporte déjà des descriptions, vous pouvez envoyer une demande de traitement en suivant les instructions de la section Envoyer une demande de traitement.
Affiner un processeur avec des descriptions de propriétés
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- LOCATION : emplacement de votre processeur, par exemple :
us: États-Uniseu: Union européenne
- PROJECT_ID : ID de votre projet Google Cloud .
- PROCESSOR_ID : ID de votre processeur personnalisé.
- DISPLAY_NAME : nom à afficher du processeur.
- PRETRAINED_PROCESSOR_VERSION : identifiant de la version du processeur. Pour en savoir plus, consultez Sélectionner une version de l'outil de traitement. Par exemple :
- .
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS : étapes d'entraînement pour l'affinage du modèle.
- LEARN_RATE_MULTIPLIER : multiplicateur du taux d'apprentissage pour l'affinage du modèle.
- DOCUMENT_SCHEMA : schéma du processeur. Consultez la représentation DocumentSchema.
Méthode HTTP et URL :
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Corps JSON de la requête :
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Extracteur personnalisé avec détection de signature
(Version Preview publique) L'extracteur personnalisé est compatible avec la détection de signatures. Cette fonctionnalité vous permet de détecter la présence de signatures dans les documents. La détection de signature n'est disponible qu'avec le type de méthode derived. Vous pouvez spécifier un schéma avec le type d'entité signature pour ces entités. Les entités de signature sont dérivées à l'aide d'indices visuels du document.
Pour obtenir des exemples et des instructions de configuration, cliquez sur Extracteur personnalisé avec champ dérivé et détection de signature.
Extracteur personnalisé avec champs dérivés
L'extracteur personnalisé est compatible avec les champs dérivés. Il vous permet de configurer un champ à remplir par inférence ou génération intelligente en fonction du contexte du document, plutôt que par extraction directe du texte. Vous pouvez l'utiliser dans des cas d'utilisation tels que la déduction du pays à partir d'une adresse, la synthèse d'un document, le décompte des éléments d'un tableau ou la détection de l'authenticité d'une pièce d'identité, sans que la valeur soit explicitement présente dans le texte.
Pour obtenir des exemples et des instructions de configuration, cliquez sur Extracteur personnalisé avec champ dérivé et détection de signature.
Étapes suivantes
Découvrez l'extracteur personnalisé avec champ dérivé et détection de signature.