Vous pouvez entraîner un modèle très performant avec seulement trois documents d'entraînement et trois documents de test pour les cas d'utilisation à mise en page fixe. Accélérez le développement et réduisez le temps de production pour les types de documents modèles tels que les formulaires W9, 1040, ACORD, les enquêtes et les questionnaires.
Configuration d'ensemble de données
Un ensemble de données de documents est requis pour entraîner, surentraîner ou évaluer une version du processeur. Les processeurs Document AI apprennent à partir d'exemples, tout comme les humains. L'ensemble de données alimente la stabilité du processeur en termes de performances.Ensemble de données d'entraînement
Pour améliorer le modèle et sa précision, entraînez un ensemble de données sur vos documents. Le modèle est constitué de documents avec vérité terrain. Vous devez disposer d'au moins trois documents pour entraîner un nouveau modèle.Ensemble de données de test
L'ensemble de données de test est ce que le modèle utilise pour générer un score F1 (précision). Il est composé de documents avec une vérité terrain. Pour savoir à quelle fréquence le modèle a raison, la vérité terrain est utilisée pour comparer les prédictions du modèle (champs extraits du modèle) aux bonnes réponses. L'ensemble de données de test doit comporter au moins trois documents.Avant de commencer
Si ce n'est pas déjà fait, activez :
Bonnes pratiques concernant l'étiquetage en mode modèle
Un étiquetage approprié est l'une des étapes les plus importantes pour obtenir une grande précision. Le mode Modèle utilise une méthodologie d'étiquetage unique qui diffère des autres modes d'entraînement :
- Dessinez des cadres de délimitation autour de toute la zone où vous vous attendez à ce que les données se trouvent (par libellé) dans un document, même si le libellé est vide dans le document d'entraînement que vous libellez.
- Vous pouvez libeller des champs vides pour l'entraînement basé sur un modèle. Ne libellez pas les champs vides pour l'entraînement basé sur un modèle.
Créer et évaluer un extracteur personnalisé avec le mode modèle
Créez un extracteur personnalisé. Créez un processeur et définissez les champs que vous souhaitez extraire en suivant les bonnes pratiques. C'est important, car cela a un impact sur la qualité de l'extraction.
Définissez l'emplacement de l'ensemble de données. Sélectionnez le dossier d'option par défaut (géré par Google). Cela peut se faire automatiquement peu de temps après la création du processeur.
Accédez à l'onglet Compiler, puis sélectionnez Importer des documents avec l'étiquetage automatique activé. Ajouter plus de documents que le minimum de trois requis n'améliore généralement pas la qualité de l'entraînement basé sur des modèles. Au lieu d'en ajouter d'autres, concentrez-vous sur l'étiquetage d'un petit ensemble de données avec une grande précision.
Étendez les cadres de délimitation. Ces zones pour le mode modèle doivent ressembler aux exemples précédents. Élargissez les cadres de sélection en suivant les bonnes pratiques pour obtenir un résultat optimal.
Entraîner le modèle
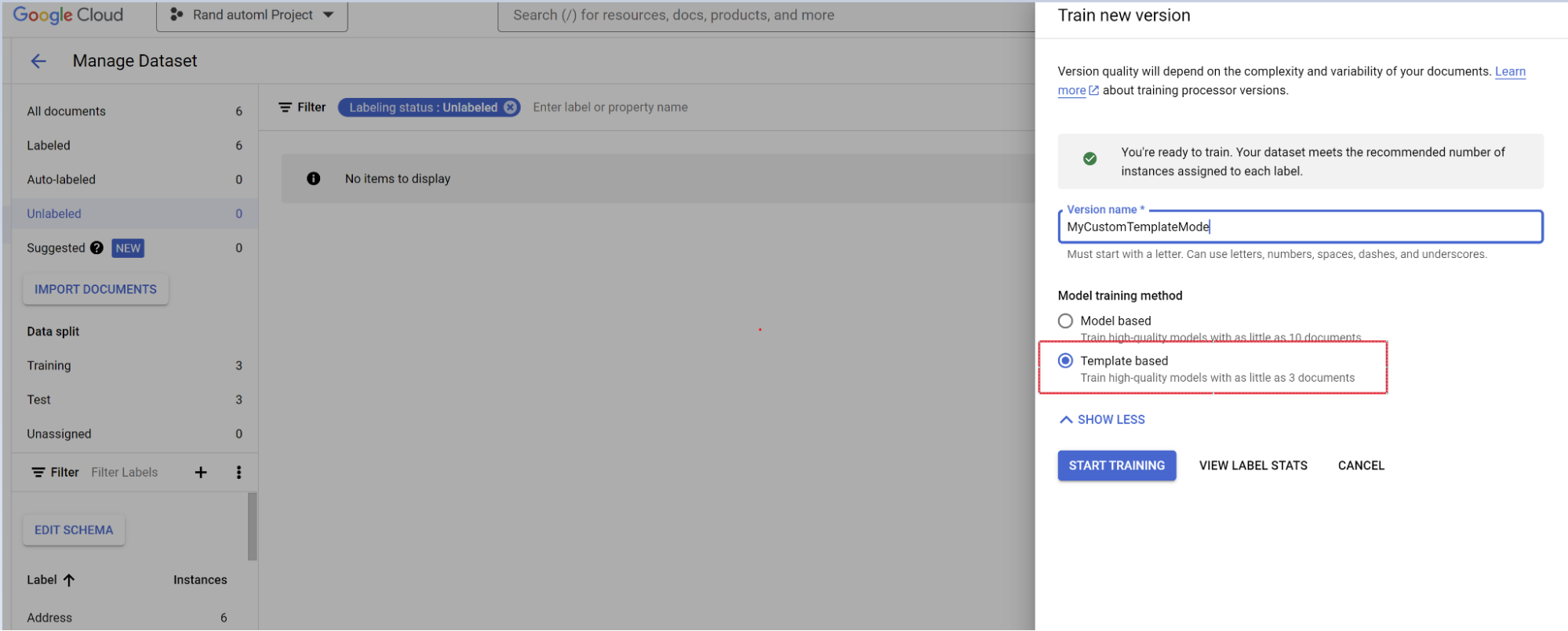
- Sélectionnez Entraîner une nouvelle version.
- Nommez la version du processeur.
- Accédez à Afficher les options avancées, puis sélectionnez l'approche basée sur les modèles.
Évaluation.
- Accédez à Évaluer et tester.
- Sélectionnez la version que vous venez d'entraîner, puis Afficher l'évaluation complète.
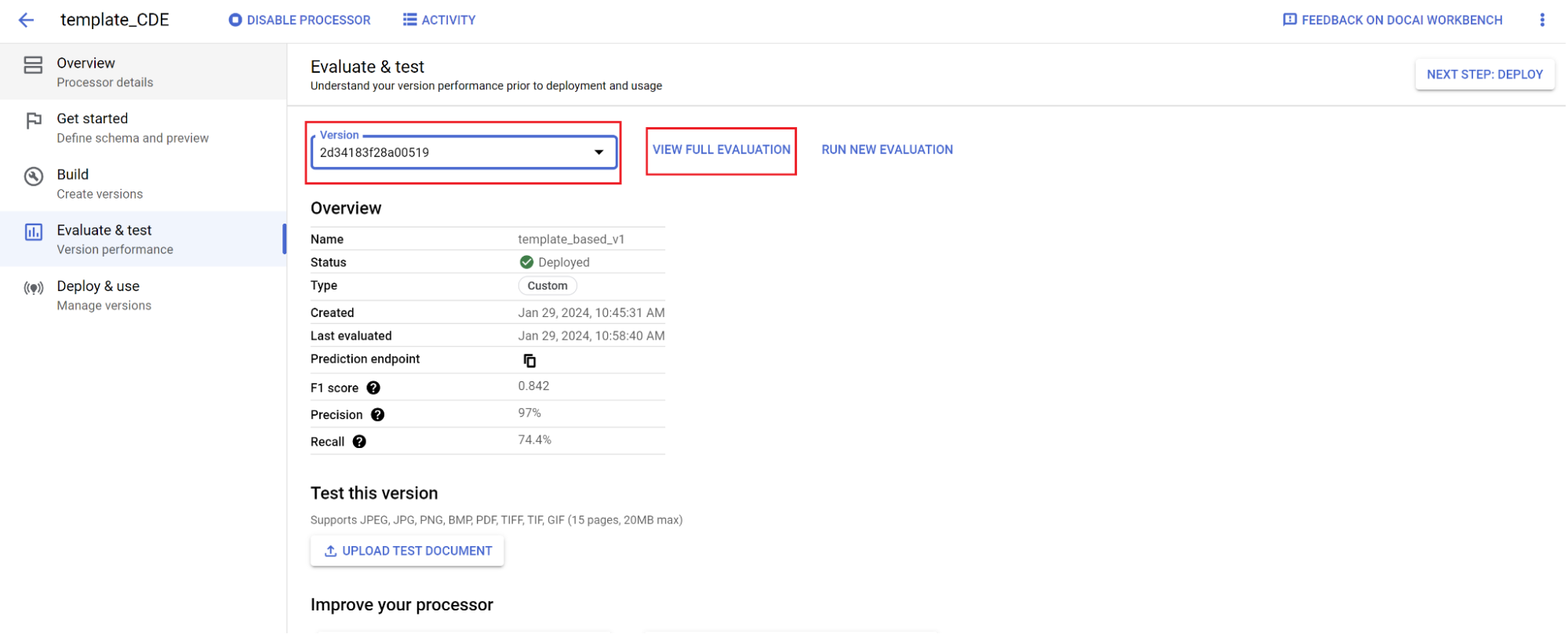
Vous pouvez désormais consulter des métriques telles que le score F1, la précision et le rappel pour l'ensemble du document et pour chaque champ. 1. Déterminez si les performances répondent à vos objectifs de production. Si ce n'est pas le cas, réévaluez les ensembles d'entraînement et de test.
Définissez une nouvelle version par défaut.
- Accédez à Gérer les versions.
- Sélectionnez pour afficher le menu des paramètres, puis cochez Définir comme paramètre par défaut.
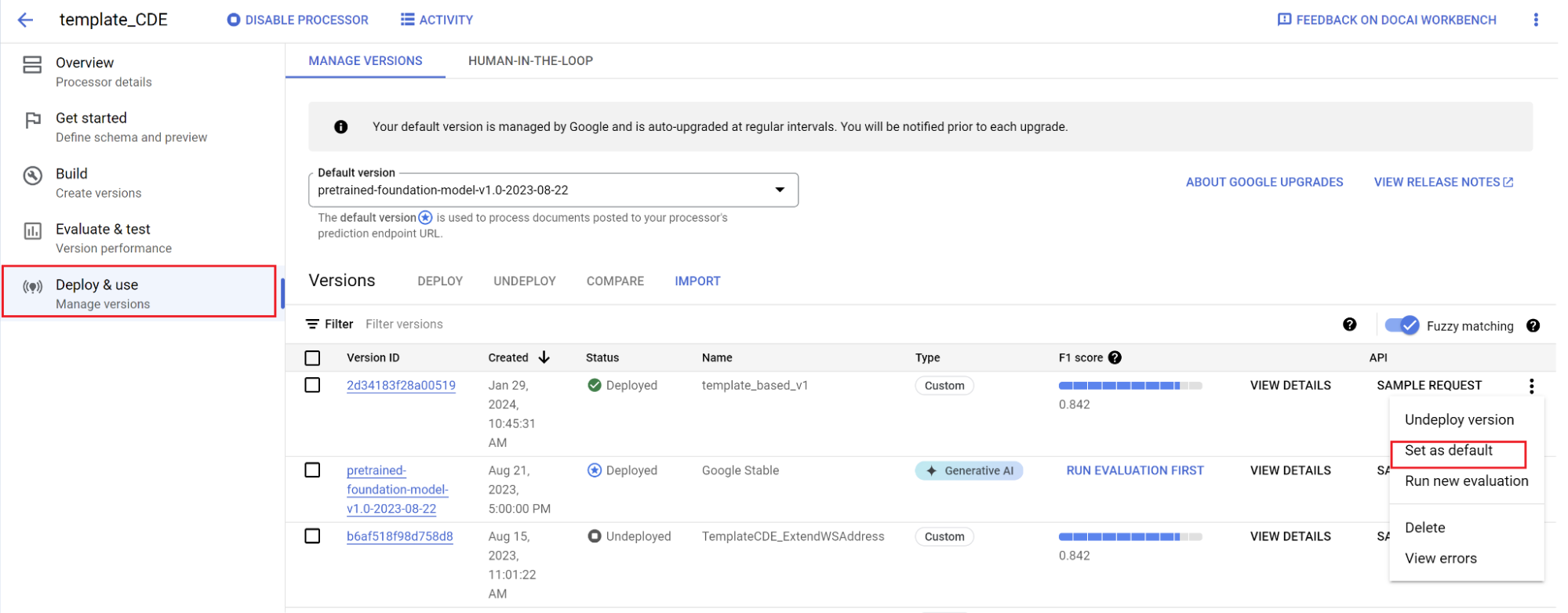
Votre modèle est désormais déployé et les documents envoyés à ce processeur utilisent votre version personnalisée. Vous souhaitez évaluer les performances du modèle (en savoir plus) pour vérifier s'il nécessite un entraînement supplémentaire.
Référence d'évaluation
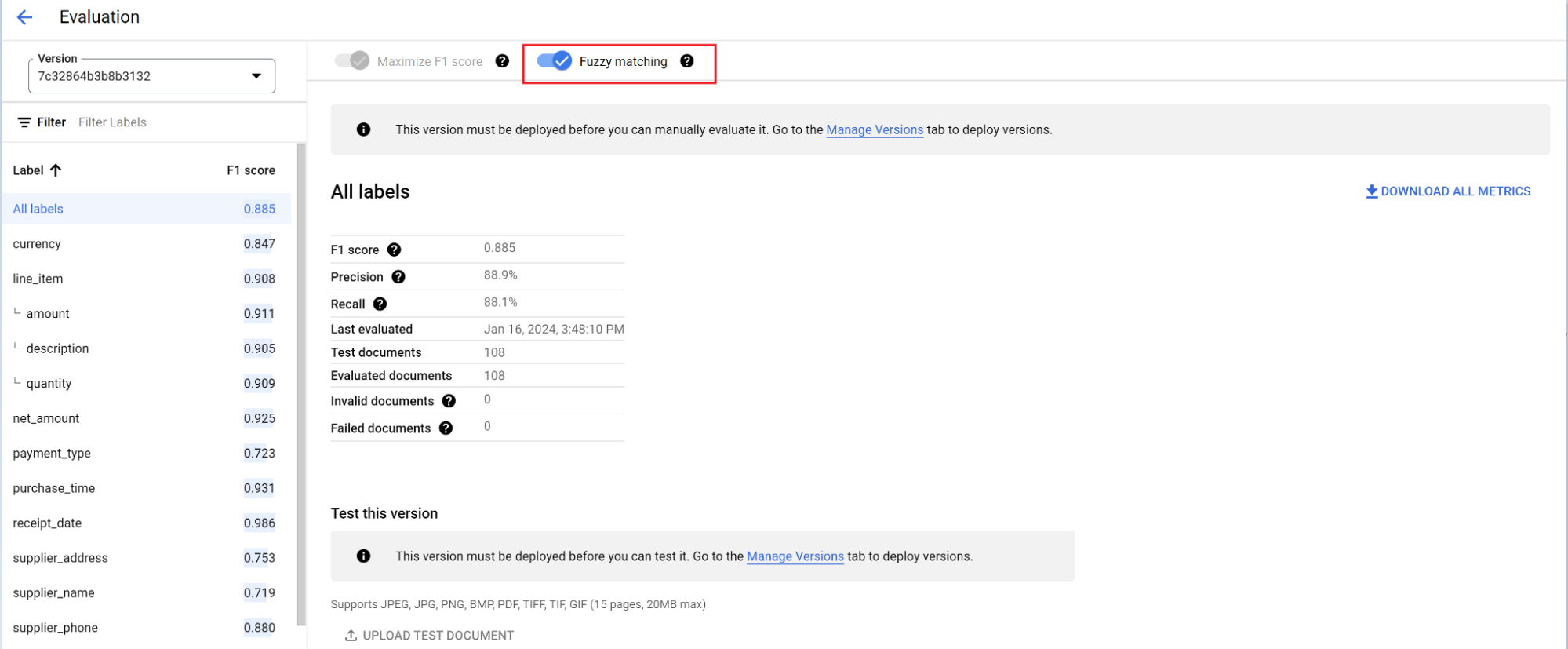
Le moteur d'évaluation peut effectuer une correspondance exacte ou approximative. Pour une correspondance exacte, la valeur extraite doit correspondre exactement à la vérité terrain. Dans le cas contraire, elle est considérée comme une erreur.
Les extractions par correspondance approximative qui présentent de légères différences, comme des différences de casse, sont toujours considérées comme des correspondances. Vous pouvez le modifier sur l'écran Évaluation.
Étiquetage automatique avec le modèle de fondation
Le modèle de fondation peut extraire avec précision des champs à partir de types de documents divers, mais vous pouvez également fournir des données d'entraînement supplémentaires afin d'améliorer sa précision pour des structures de documents spécifiques.
Document AI utilise les noms d'étiquettes que vous avez définis et les annotations précédentes pour faciliter et accélérer l'étiquetage des documents à grande échelle grâce à l'étiquetage automatique.
- Après avoir créé un processeur personnalisé, accédez à l'onglet Commencer.
Sélectionnez Créer un champ.
Accédez à l'onglet Compiler, puis sélectionnez Importer des documents.
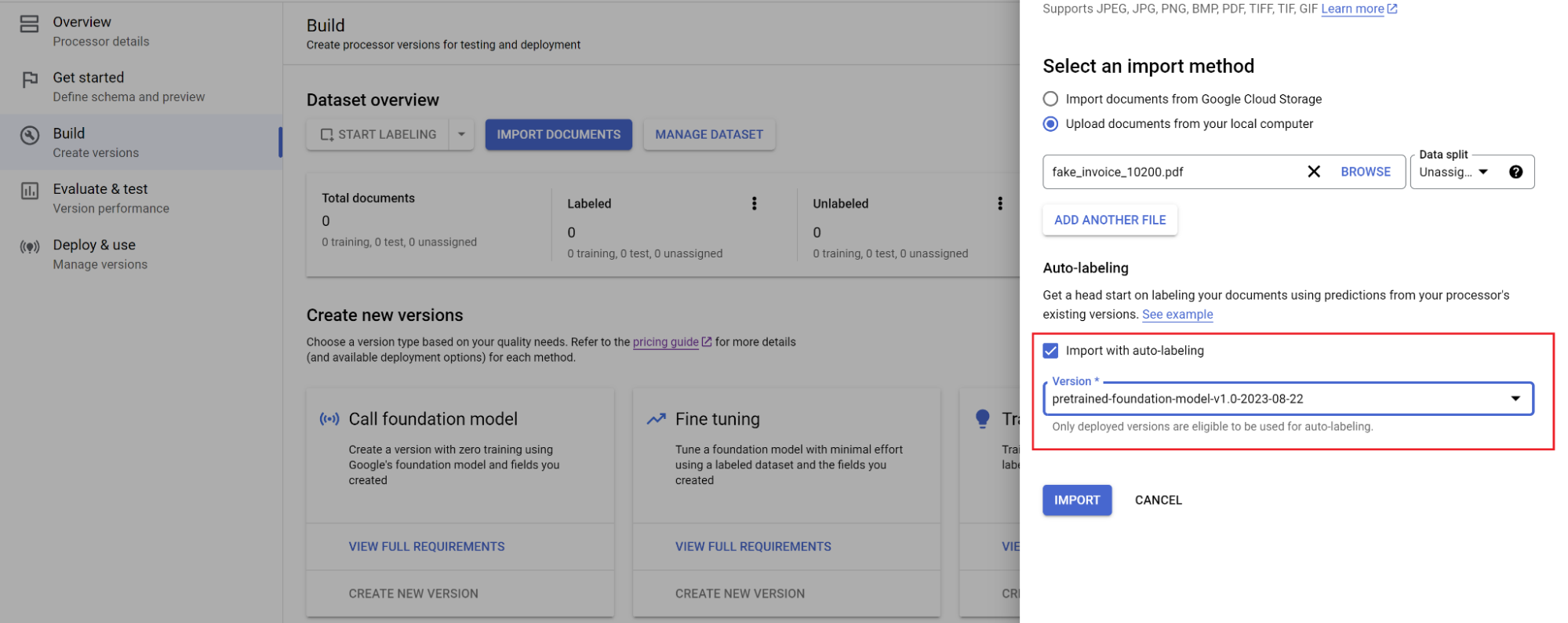
Sélectionnez le chemin d'accès aux documents et l'ensemble dans lequel ils doivent être importés. Cochez la case "Étiquetage automatique" et sélectionnez le modèle de fondation.
Dans l'onglet Compiler, sélectionnez Gérer l'ensemble de données. Vos documents importés devraient s'afficher. Sélectionnez l'un de vos documents.
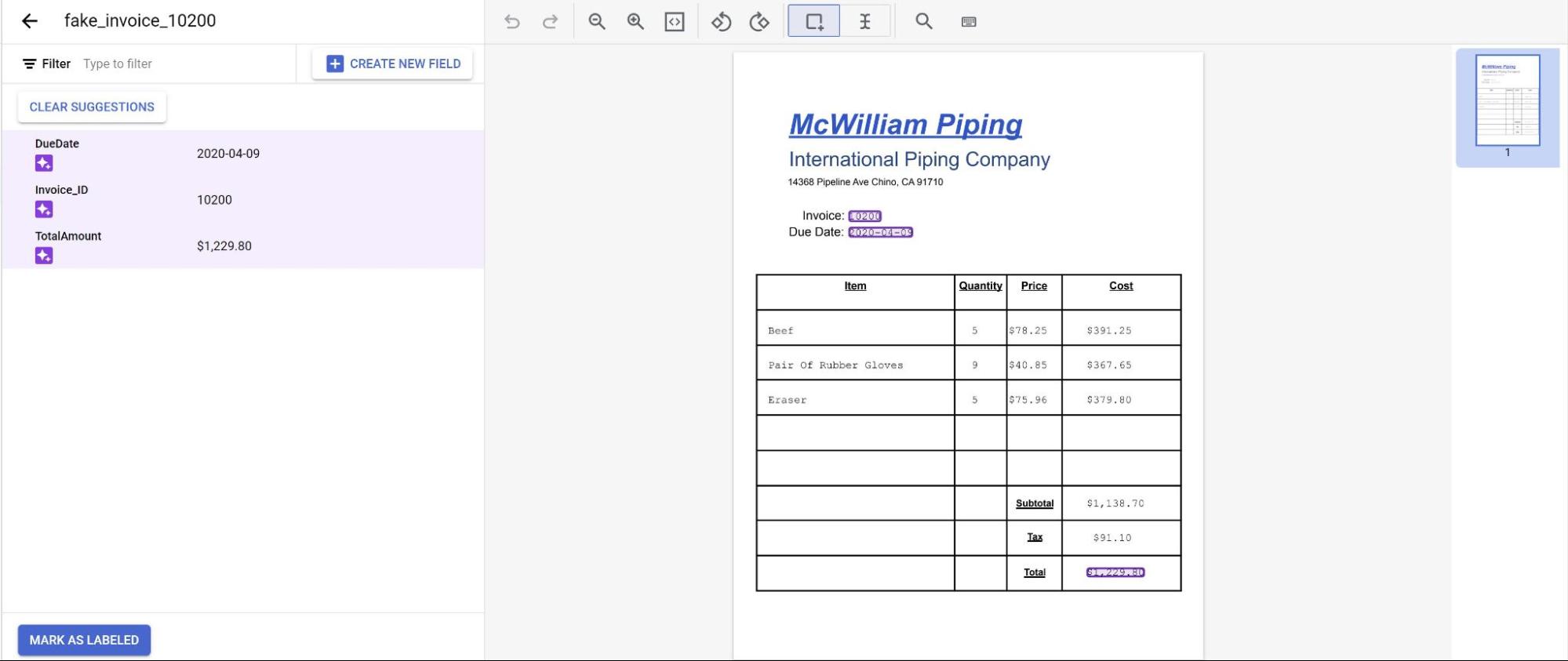
Les prédictions du modèle sont mises en évidence en violet. Vous devez examiner chaque étiquette prédite par le modèle et vous assurer qu'elle est correcte. Si des champs sont manquants, vous devez également les ajouter.
.
Une fois le document examiné, sélectionnez Marquer comme étiqueté.
Le document est maintenant prêt à être utilisé par le modèle. Assurez-vous que le document se trouve dans l'ensemble de test ou d'entraînement.