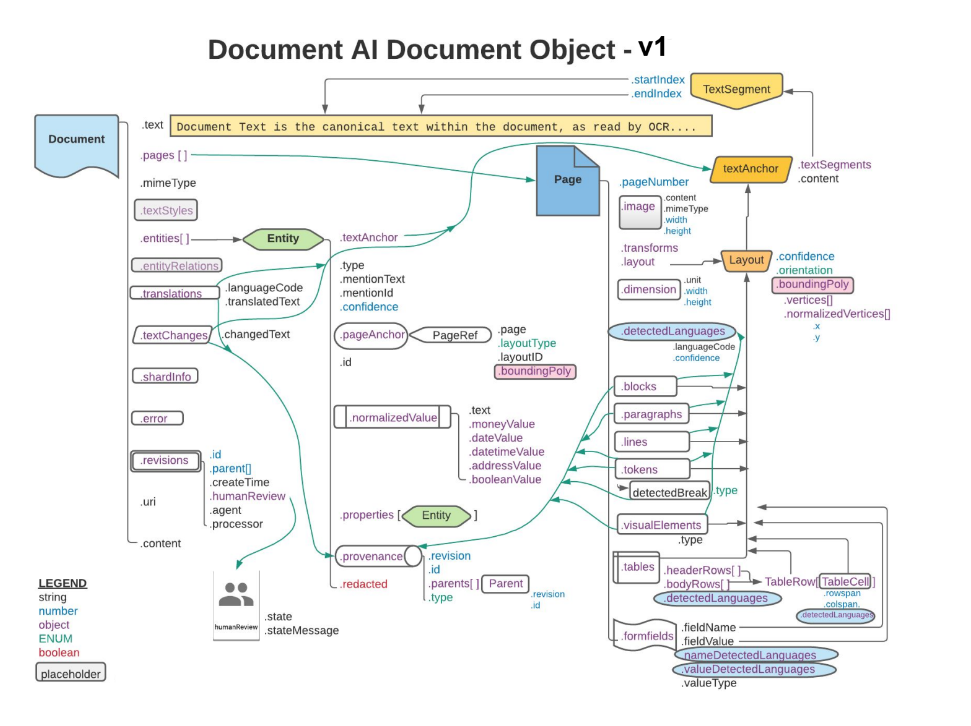
处理请求的响应中会包含一个 Document 对象,其中保存了所处理文档的所有已知信息,包括 Document AI 能够提取的所有结构化信息。
本页面介绍了 Document 对象的结构,提供了一些示例文档,并演示了如何将 OCR 结果的各个方面映射到 Document 对象 JSON 的特定元素中。此外,还提供了客户端库代码示例和 Document AI Toolbox SDK 代码示例。
这些代码示例使用在线处理,但 Document 对象解析在批处理中也同样适用。
橙色和蓝色矩形及箭头表示,关联对象的至少一个字段分别为 .layout 或 detectedLanguage。该图使用乌鸦脚表示法。
使用专门用于展开或收起元素的 JSON 查看器或编辑实用程序。在纯文本实用程序中查看原始 JSON 效率低下。
文字、布局和质量得分
以下是文本文件示例:

以下是 Enterprise Document OCR 处理器返回的完整文档对象:
由于 OCR 由处理器运行,因此该 OCR 输出也始终包含在 Document AI 处理器输出中。它使用现有的 OCR 数据,因此您可以使用内嵌文档选项将此类 JSON 数据输入到 Document AI 处理器中。
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
以下是一些重要字段:
原始文本
text 字段包含 Document AI 识别的文本。此文本不包含任何布局结构,空格、制表符和换行符除外。这是唯一一个用于存储文档文本信息的字段,也是文档文本的可信来源。其他字段可以通过位置(startIndex 和 endIndex)引用文本字段的各个部分。
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
页面大小和语言
文档对象中的每个 page 都对应于示例文档中的一个物理页面。示例 JSON 输出包含一个页面,因为它是单个 PNG 图片。
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
pages[].detectedLanguages[]字段包含在指定网页上检测到的语言以及置信度分数。
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
OCR 数据
Document AI OCR 可检测页面中具有各种粒度或组织结构的文本,例如文本块、段落、令牌和符号(如果配置为输出符号级数据,则符号级为可选)。这些都是页面对象的成员。
每个元素都有一个对应的 layout 来描述其位置和文本。非文本视觉元素(例如复选框)也位于页面级。
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
原始文本在 textAnchor 对象中引用,该对象通过 startIndex 和 endIndex 编入主文本字符串的索引。
对于
boundingPoly,页面的左上角是原点(0,0)。正 X 值表示向右,正 Y 值表示向下。vertices对象使用与原始图片相同的坐标,而normalizedVertices的范围为[0,1]。有一个转换矩阵,用于指示图像归一化的倾斜校正措施和其他属性。
- 如需绘制
boundingPoly,请绘制从一个顶点到下一个顶点的线段。 然后,从最后一个顶点向第一个顶点绘制一条线段,以闭合多边形。布局的 orientation 元素用于指明文本是否已相对于页面旋转。
为了帮助您直观了解文档的结构,以下图片为 page.paragraphs、page.lines、page.tokens 绘制了边界多边形。
段落数

行数

令牌

区块

企业文档 OCR 处理器可以根据文档的可读性对其进行质量评估。
- 您必须将字段
processOptions.ocrConfig.enableImageQualityScores设置为true,才能在 API 响应中获取此数据。
此质量评估结果是一个介于 [0, 1] 之间的质量得分,其中 1 表示质量完美。
质量得分在 Page.imageQualityScores 字段中返回。所有检测到的缺陷均以 quality/defect_* 形式列出,并按置信度值降序排序。
以下 PDF 文件太暗且模糊,无法舒适地阅读:
以下是 Enterprise Document OCR 处理器返回的文档质量信息:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
代码示例
以下代码示例演示了如何发送处理请求,然后读取字段并将其打印到终端:
Java
如需了解详情,请参阅 Document AI Java API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解详情,请参阅 Document AI Node.js API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
表单和表格
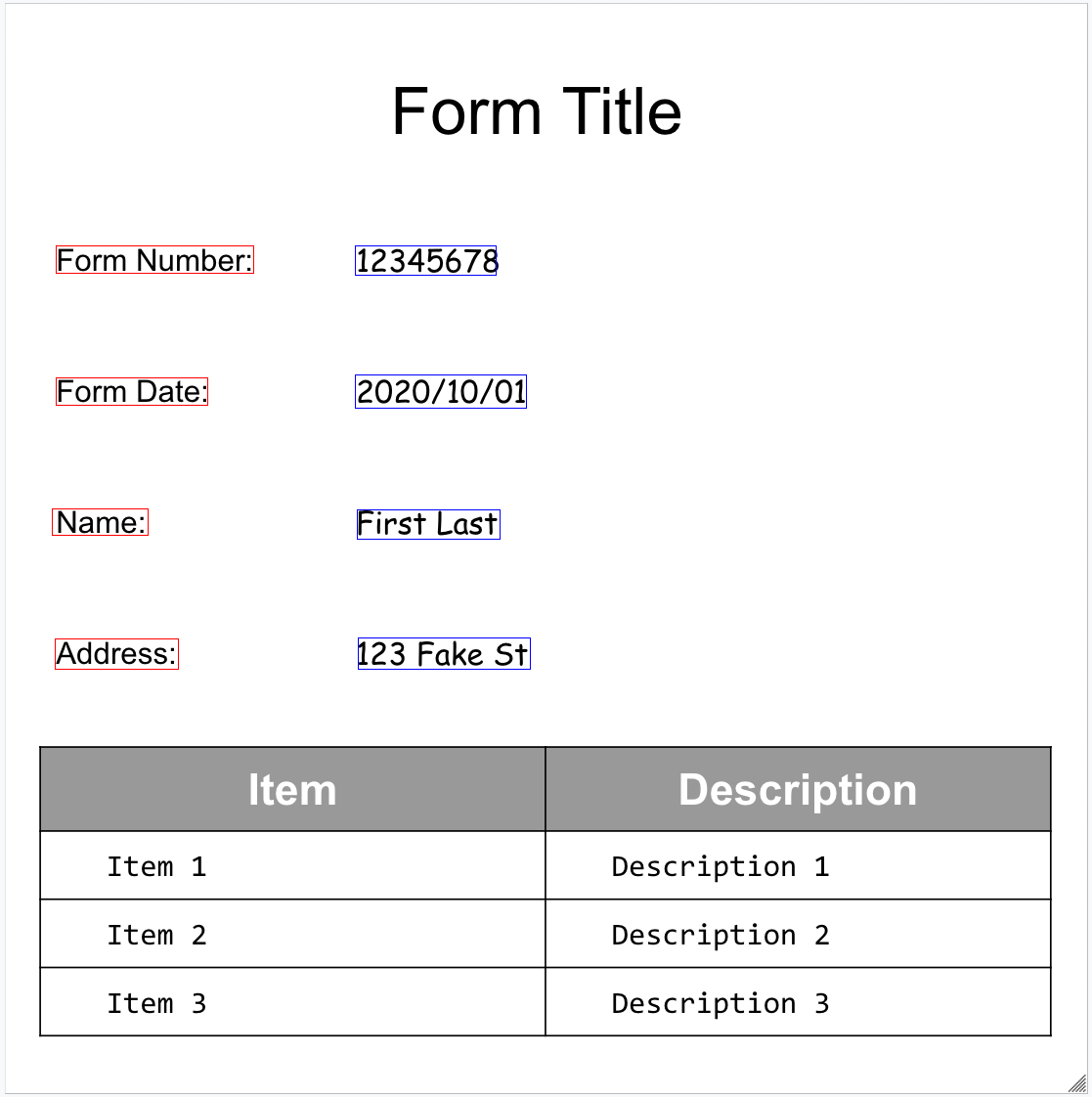
以下是我们的示例表单:
以下是 Form Parser 返回的完整文档对象:
以下是一些重要字段:
表单解析器能够检测到网页中的 FormFields。每个表单字段都有一个名称和一个值。这些数据也称为键值对 (KVP)。请注意,KVP 与其他提取器中的(架构)实体不同:
实体名称已配置。KVP 中的键实际上就是文档中的键文本。
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI 还可以检测页面中的
Tables。
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
表单解析器中的表格提取功能仅识别常规表格,即不包含跨行或跨列的单元格的表格。因此,rowSpan 和 colSpan 始终为 1。
从处理器版本
pretrained-form-parser-v2.0-2022-11-10开始,Form Parser 还可以识别通用实体。如需了解详情,请参阅表单解析器。为了帮助您直观呈现文档的结构,以下图片绘制了
page.formFields和page.tables的边界多边形。表格中的复选框。Form Parser 能够将图片和 PDF 中的复选框数字化为 KVP。以键值对形式提供复选框数字化的示例。
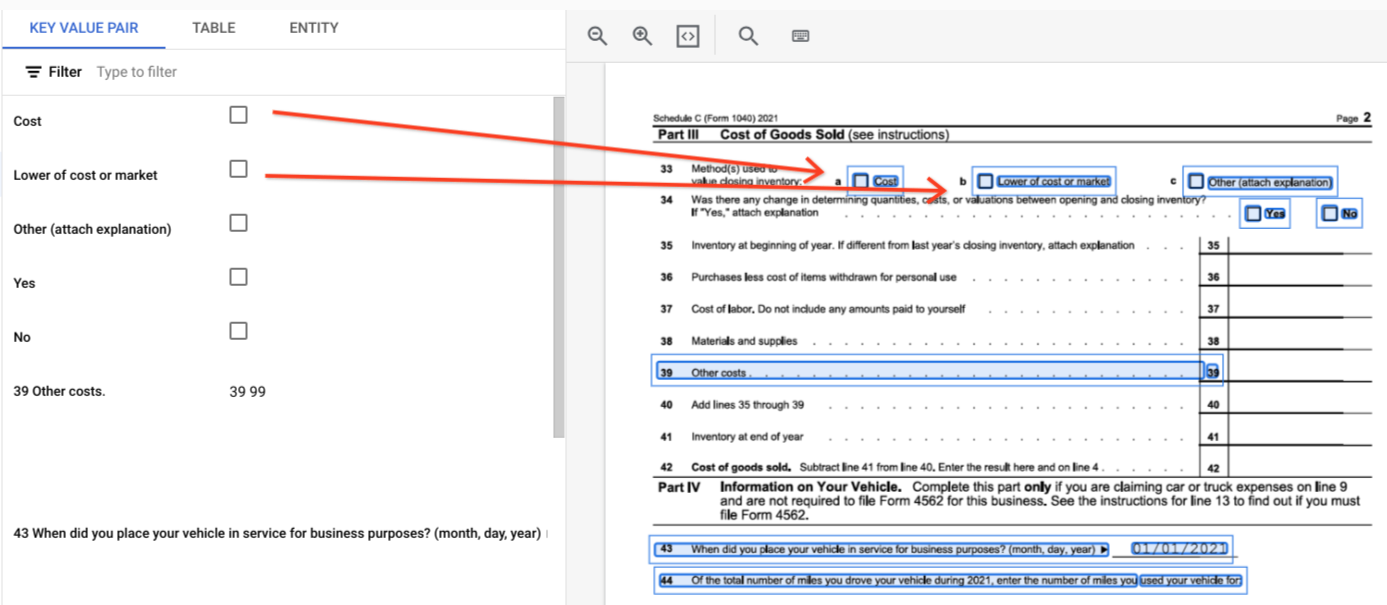
在表格之外,复选框在表单解析器中以视觉元素的形式表示。 突出显示界面上带有对勾标记的方框以及 JSON 中的 Unicode 字符 ✓。
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
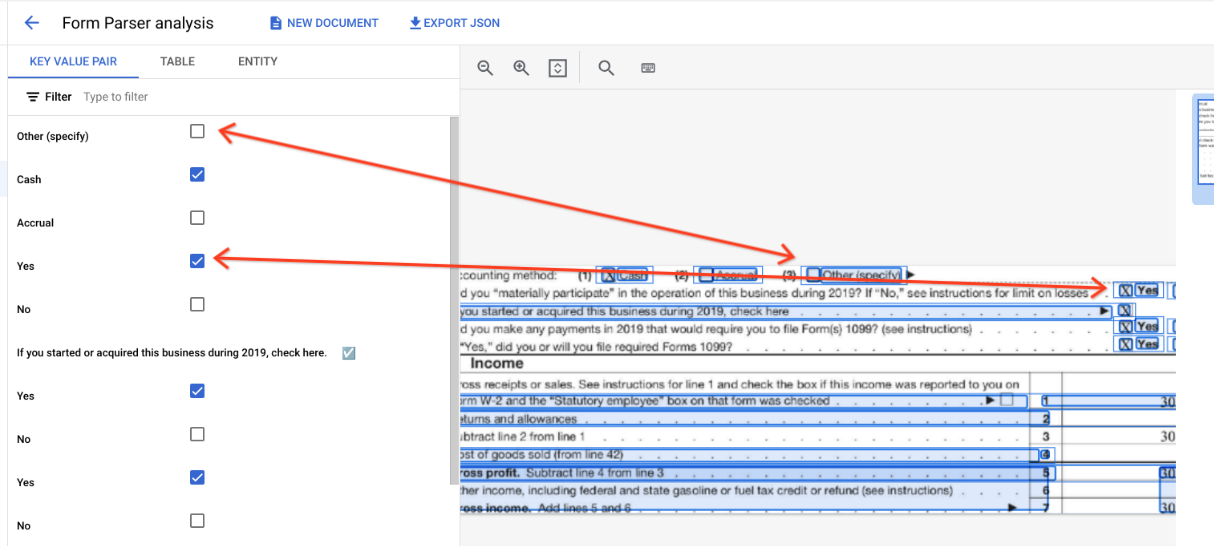
在表格中,复选框会显示为 Unicode 字符,例如 ✓(选中)或 ☐(未选中)。
已勾选的复选框的值为 filled_checkbox:under pages > x > formFields > x > fieldValue > valueType.。未勾选的复选框的值为 unfilled_checkbox。
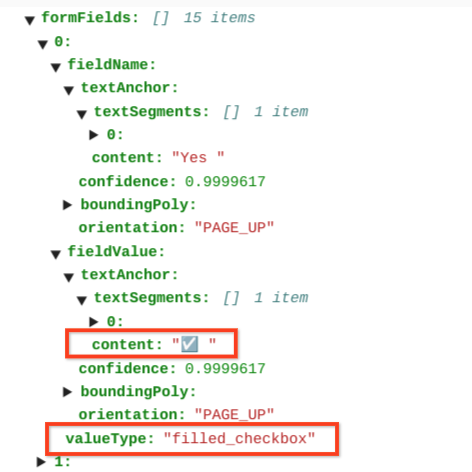
内容字段会在路径 pages>formFields>x>fieldValue>textAnchor>content 中显示复选框内容值,并以突出显示的 ✓ 表示。
为了帮助您直观了解文档的结构,以下图片绘制了 page.formFields 和 page.tables 的边界多边形。
表单字段
表
代码示例
以下代码示例演示了如何发送处理请求,然后读取字段并将其打印到终端:
Java
如需了解详情,请参阅 Document AI Java API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解详情,请参阅 Document AI Node.js API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
实体、嵌套实体和归一化值
许多专用处理器会提取基于明确定义的架构的结构化数据。例如,账单解析器可检测到 invoice_date 和 supplier_name 等特定字段。以下是账单示例:
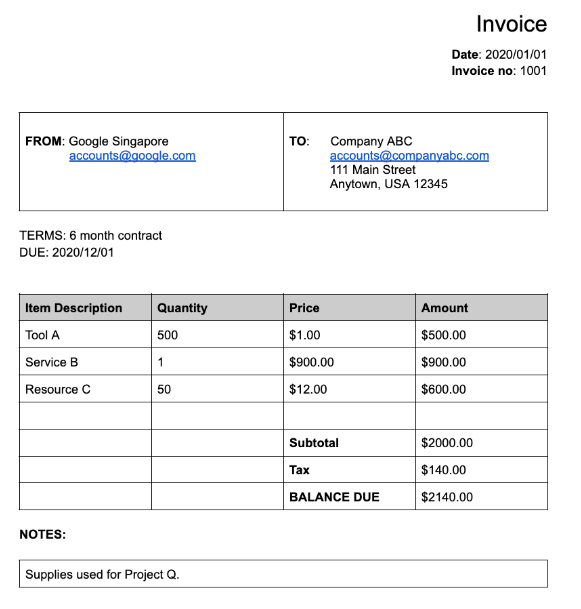
以下是 Invoice 解析器返回的完整文档对象:
以下是 document 对象的一些重要部分:
检测到的字段:
Entities包含处理器能够检测到的字段,例如invoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }对于某些字段,处理器还会对值进行归一化。在此示例中,日期已从
2020/01/01规范化为2020-01-01。归一化:对于许多特定的受支持字段,处理器还会对值进行归一化,并返回
entity。normalizedValue字段会添加到通过每个实体的textAnchor获取的原始提取字段中。因此,它会对字面文本进行归一化处理,通常会将文本值分解为子字段。例如,2024 年 9 月 1 日这样的日期将表示为:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
在此示例中,日期已从 2020/01/01 归一化为 2020-01-01,这是一种标准化格式,可减少后处理并实现向所选格式的转换。
地址也经常会进行标准化处理,即将地址的各个元素分解为单独的字段。通过将整数或浮点数作为 normalizedValue 来对数字进行归一化处理。
- 丰富化:某些处理器和字段还支持丰富化。
例如,文档
Google Singapore中的原始supplier_name已根据 Enterprise Knowledge Graph 归一化为Google Asia Pacific, Singapore。 另请注意,由于 Enterprise Knowledge Graph 包含有关 Google 的信息,因此 Document AI 会推断出supplier_address,即使该实体不在示例文档中也是如此。
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
嵌套字段:您可以先将某个实体声明为父实体,然后在该父实体下创建子实体,从而创建嵌套架构(字段)。父级的解析响应包含父级字段的
properties元素中的子字段。在以下示例中,line_item是一个包含两个子字段(line_item/description和line_item/quantity)的父字段。{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
以下解析器遵循此规则:
- 提取(自定义提取器)
- 旧版
- 银行对账单解析器
- 费用解析器
- 账单解析器
- 工资单解析器
- W2 解析器
代码示例
以下代码示例演示了如何发送处理请求,然后从专用处理器读取字段并将其打印到终端:
Java
如需了解详情,请参阅 Document AI Java API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解详情,请参阅 Document AI Node.js API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
自定义文档提取器
自定义文档提取器处理器可以从没有预训练处理器的文档中提取自定义实体。为此,您可以训练自定义模型,也可以使用生成式 AI 基础模型来提取命名实体,而无需进行任何训练。如需了解详情,请参阅在控制台中创建自定义文档提取器。
- 如果您训练自定义模型,则可以使用该处理器,其使用方式与预训练的实体提取处理器完全相同。
- 如果您使用基础模型,则可以创建处理器版本,以便为每个请求提取特定实体,也可以按请求进行配置。
如需了解输出结构,请参阅实体、嵌套实体和归一化值。
代码示例
如果您使用的是自定义模型,或者使用基础模型创建了处理器版本,请使用实体提取代码示例。
以下代码示例演示了如何针对基础模型自定义文档提取器,以按请求为基础配置特定实体,并打印提取的实体:
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
摘要
摘要器处理器使用生成式 AI 基础模型来汇总从文档中提取的文本。您可以通过以下方式自定义回答的长度和格式:
- 长度
BRIEF:一两句话的简短摘要MODERATE:一段式摘要COMPREHENSIVE:最长的可用选项
- 格式
您可以为特定长度和格式创建处理器版本,也可以按请求进行配置。
总结后的文字会显示在 Document.entities.normalizedValue.text 中。您可以在处理器输出示例中找到完整的输出 JSON 文件示例。
如需了解详情,请参阅在控制台中构建文档摘要器。
代码示例
以下代码示例演示了如何在处理请求中配置特定长度和格式,并打印总结的文本:
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
拆分和分类
以下是一个包含不同类型文档和表单的 10 页 PDF 复合文档:
以下是贷款文档分割器和分类器返回的完整文档对象:
拆分器检测到的每个文档都由一个 entity 表示。例如:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchor表示相应证件有 2 页。请注意,pageRefs[].page从零开始,是document.pages[]字段的索引。Entity.type指定相应文档为 1040 Schedule SE 表单。如需查看可识别的文档类型的完整列表,请参阅处理器文档中的可识别的文档类型。
如需了解详情,请参阅文档拆分器行为。
代码示例
拆分器可识别页面边界,但不会实际拆分输入文档。您可以使用 Document AI 工具箱,通过页面边界来实际拆分 PDF 文件。 以下代码示例会打印指定页范围,而不会拆分 PDF:
Java
如需了解详情,请参阅 Document AI Java API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解详情,请参阅 Document AI Node.js API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Document 中的页面边界拆分 PDF 文件。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Document AI 工具箱
Document AI Toolbox 是一款适用于 Python 的 SDK,可提供实用函数来管理、操控和提取文档响应中的信息。它会从 Cloud Storage 中的 JSON 文件、本地 JSON 文件或直接从 process_document() 方法输出的处理后的文档响应中创建“封装”文档对象。
它可以执行以下操作:
- 将批处理中的碎片化
DocumentJSON 文件合并为单个“封装”文档。 - 将分片导出为统一的
Document。 -
从以下位置获取
Document输出: - 无需处理
Layout信息,即可访问Pages、Lines、Paragraphs、FormFields和Tables中的文本。 - 搜索包含目标字符串或与正则表达式匹配的
Pages。 - 按名称搜索
FormFields。 - 按类型搜索
Entities。 - 将
Tables转换为 Pandas DataFrame 或 CSV。 - 将
Entities和FormFields插入到 BigQuery 表中。 - 根据 Splitter/Classifier 处理器的输出拆分 PDF 文件。
- 从
Document边界框中提取图片Entities。 -
将
Documents转换为常用格式,以及从常用格式转换为Documents:- Cloud Vision API
AnnotateFileResponse - hOCR
- 第三方文档处理格式
- Cloud Vision API
- 从 Cloud Storage 文件夹创建批次文档以进行处理。
代码示例
以下代码示例演示了如何使用 Document AI Toolbox。