建立、使用及管理自訂文件分類器
您可以使用自訂分類器將文件分類。使用自己的文件和自訂類別,從頭開始建構。其生成式 AI 面向可進行少量樣本學習和微調。這些功能可以減少樣本數,並透過疊代型自動標籤功能修正錯誤,進而提高準確率。
自訂分類器涵蓋這三種一般用途。
- 預先訓練模型:使用預先訓練的生成式 AI 基礎模型,依據您提供的標籤快速將文件分類。
- 微調:使用您的資料和標籤訓練生成式 AI 基礎模型,提高準確率。
- 訓練自訂模型:使用您的資料和標籤,訓練非生成式 AI 自訂擷取器。
自訂分類器模型版本
| 模型版本 | 說明 | 發布管道 | 在美國/歐盟境內的機器學習處理作業 | 在美國/歐盟境內的微調作業 | 發布日期 |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-05-16 |
搭載 Gemini 2.0 Flash LLM 的候選版,也包含進階 OCR 功能。 | 候選版 | 是 | 美國、歐盟 (預先發布版) | 2025 年 5 月 16 日 |
pretrained-classifier-v1.5-2025-08-05 |
搭載 Gemini 2.5 Flash LLM 的候選版,也包含進階 OCR 功能。 | 候選版 | 是 | 美國、歐盟 (預先發布版) | 2025 年 8 月 5 日 |
自訂分類器模型不支援信賴度分數。
在 Google Cloud 控制台建立自訂分類器
您可以建立文件專屬的自訂分類器,並使用資料訓練及評估。這個處理器會根據使用者定義的類別集找出文件類別。完成訓練後,您可以使用該處理器分類其他文件。您通常會對不同類型的文件使用自訂分類器,識別完成後,將文件交由擷取處理器擷取實體。
如要瞭解建立及使用處理器的一般程序,請參閱「如何使用」一節。
您可以根據自己的工作流程自訂設定。
如要直接在 Google Cloud 控制台按照逐步指南操作,請按一下「Guide me」(逐步引導):
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 針對「custom document classifier」(自訂文件分類器),選取
「Create processor」(建立處理器) 。
在「Create processor」(建立處理器) 選單中,輸入處理器名稱,例如
my-custom-document-classifier。
請選取最近的區域。
選取 [Create] (建立)。系統會隨即顯示「Processor Details」(處理器詳細資料) 分頁。
- 如要使用 Cloud Storage,請選取「Google-managed storage」(Google 代管的儲存空間)。
- 如要使用自己的儲存空間,以便使用客戶自行管理的加密金鑰 (CMEK),請選取「I'll specify my own storage location」(自行指定儲存空間位置),然後按照「建立資料集」中的程序操作。
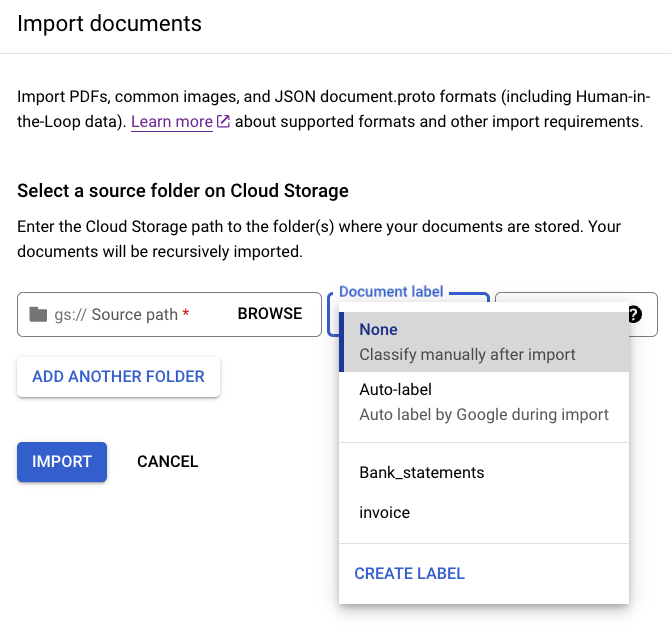
在「Build」(建構) 分頁中,點選
「Import documents」(匯入文件) 。
選擇使用儲存空間 bucket 時,必須輸入 bucket 的「Source path」(來源路徑)。就這個訓練範例而言,請在
「Source path」(來源路徑) 中輸入這個 bucket 名稱。這樣就會直接連結至某份文件。cloud-samples-data/documentai/Custom/Patents/PDF/computer_vision_20.pdf在「Data split」(資料分割)部分選取「Unassigned」(未指派) 。這個資料夾中的文件不會指派給測試集或訓練集。取消勾選「Import with auto-labeling」(使用自動加上標籤功能匯入)。
選取「Import」(匯入)。Document AI 會將值區中的文件讀取到資料集,但不會修改匯入 bucket,也不會在匯入完成後從 bucket 讀取資料。
選用:如要刪除匯入的文件,請前往「Build」(建構) 分頁,依序點選「Manage dataset」(管理資料集) > 選取文件 > 點選「Delete」(刪除)。
在「Build」(建構) 分頁中,依序選取「Manage Dataset」(管理資料集) >「Edit Schema」(編輯結構定義)。「Edit Schema」(編輯結構定義) 頁面隨即開啟。
點選
「Create label」(建立標籤) 。輸入標籤名稱。
選取 [Create] (建立)。如需建立與編輯結構定義的詳細操作說明,請參閱「定義處理器結構定義」。
為處理器結構定義建立下列每個標籤。
computer_visioncryptomed_techother
標籤完成後,請點選
「Save」(儲存) 。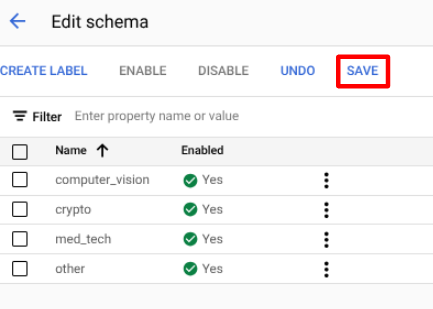
回到「Build」(建構) 分頁,然後選取
某個文件 ,即可開啟「Manage Dataset」(管理資料集) 控制台。從
選項 中選取適用的文件標籤。如果您使用的是我們提供的範例文件,請選取「computer_vision」。加上標籤後,文件應如下所示:

完成文件註解後,請點選
「Mark as Labeled」(標示為已加上標籤) 。在「Manage Dataset」(管理資料集) 分頁,「Document」(文件) 面板會顯示一份文件已加上標籤。
在「Manage Dataset」(管理資料集) 分頁中,勾選
「Select All」(全選) 核取方塊。在
「Assign to Set」(指派給資料集) 清單中,選取「Training」(訓練)。點選
「Import documents」(匯入文件) 。在
「Source path」(來源路徑) 中輸入下列路徑。這個值區包含以 Document JSON 格式預先加上標籤的文件。cloud-samples-data/documentai/Custom/Patents/JSON/Classification-InventionType在「Data split」(資料分割) 清單中,選取「Auto-split」(自動分割)。這樣系統就會自動將文件分割為 80% 給訓練集和 20% 給測試集。忽略「Apply labels」(套用標籤) 區塊。
選取「Import」(匯入)。匯入作業可能需要幾分鐘才能完成。
點選
「Import documents」(匯入文件) 。在
「Source path」(來源路徑) 中輸入下列路徑。這個 bucket 含有未加上標籤的文件 (PDF 格式)。cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabel在「Data split」(資料分割) 清單中,選取「Auto-split」(自動分割)。這樣系統就會自動將文件分割為訓練集的 80% 和測試集的 20%。
在「Apply labels」(套用標籤) 區段中,選取「Choose label」(選擇標籤)。
針對這些範例文件,請選取「
other」。選取「Import」(匯入),然後等待作業完成。您可以先離開這個頁面,稍後再返回查看。 完成後,套用標籤的文件就會顯示在「Manage Dataset」(管理資料集) 分頁中。
- 點選
「Train New Version」(訓練新版本) 。 在
「Version name」(版本名稱) 欄位中輸入這個處理器版本的名稱,例如my-cdc-version-1。選用:選取「View Label Stats」(查看標籤統計資料),即可查看文件標籤的相關資訊,有助於判斷涵蓋範圍。接著點選「Close」(關閉) ,返回訓練設定頁面。
選取
「Start training」(開始訓練) 。您可以在側邊面板中查看狀態。訓練完成後,請前往
「Manage Versions」(管理版本) 分頁。您可以查看剛才訓練的版本詳細資料。找到要部署的版本,然後選取旁邊的
,並選取「Deploy version」(部署版本)。 在對話方塊視窗中選取
「Deploy」(部署) 。部署需要幾分鐘才會完成。
部署作業完成後,請前往
「Evaluate & Test」(評估與測試) 分頁。在這個頁面中,您可以查看整份文件和個別標籤的評估指標,包括 F1 分數、精確度和召回率。如要進一步瞭解評估和統計資料,請參閱「評估處理器」。
下載未加入先前訓練或測試的文件,以便用於評估處理器版本。如果您是使用自己的資料,可以針對這個用途保留文件。
點選
「Upload Test Document」(上傳測試文件) ,然後選取剛才下載的文件。系統會開啟「Custom Document Classifier analysis」(自訂文件分類器分析) 頁面。輸出內容會顯示文件分類的精細程度。
您也可以針對其他測試集或處理器版本重新執行評估作業。
在「Manage Dataset」(管理資料集) 頁面上,按一下
「Import documents」(匯入文件) 。複製及貼上下列 Cloud Storage 路徑。這個目錄包含 5 個未加上標籤的專利 PDF。在「Data split」(資料分割) 下拉式清單中選取「Training」(訓練)。
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-AutoLabel在「Apply labels」(套用標籤) 區段中,選取「Auto-labeling」(自動加上標籤)。
選取現有的處理器版本來為文件加上標籤。
- 例如:
2af620b2fd4d1fcf
- 例如:
選取「Import」(匯入),然後等待作業完成。您可以先離開這個頁面,稍後再返回查看。完成後,文件就會出現在「Manage Dataset」(管理資料集) 頁面的「Auto-labeled」(已自動加上標籤) 部分。
您不得將自動加上標籤的文件用於訓練或測試,除非您將其標示為已加上標籤。如要查看已自動加上標籤的文件,請前往
「Auto-labeled」(已自動加上標籤) 專區。選取第一份文件即可進入標籤控制台。
確認標籤正確無誤。如果不正確,請加以調整。
完成後,請選取
「Mark as Labeled」(標示為已加上標籤) 。為每個自動加上標籤的文件重複執行標籤驗證,然後返回「Manage Dataset」(管理資料集) 頁面來指派這些資料進行訓練。
在 Google Cloud 控制台導覽選單中,依序選取「Document AI」和「My Processors」(我的處理器)。
找到要刪除的處理器,然後點選該列中的
「More actions」(更多動作) 。選取「Delete processor」(刪除處理器),輸入處理器名稱,然後再次選取「Delete」(刪除) 來確認操作。
- 詳情請參閱指南。
- 查看處理器清單。
- 使用版面配置剖析器將文件分隔成可閱讀的區塊。
- 使用 Enterprise Document OCR 偵測及擷取文字。
建立處理器
操作步驟如下。
設定資料集
為了訓練這個新處理器,您必須建立具有訓練和測試資料的資料集,以協助處理器識別您要分割和分類的文件。這個資料集需要新的位置。這可以是空白的 Cloud Storage bucket 或資料夾,也可以是內部代管位置。
顯示「Processor Details」(處理器詳細資料) 分頁後,您可以執行下列操作:

將文件匯入資料集
接下來,請將文件匯入資料集。
匯入文件時,可以選擇在匯入時就將文件指派至訓練集或測試集,也可以等到之後再指派。
如要進一步瞭解如何準備資料以進行匯入,請參閱「資料準備指南」。
定義處理器結構定義
您可以在將文件匯入資料集之前或之後建立處理器結構定義。結構定義提供用來為文件加上註解的標籤。
為文件加上標籤
在文件中選取文字及套用標籤的程序稱為「註解」。
將加註的文件指派給訓練集
為這份範例文件加上標籤後,現在已可將其指派給訓練集。
在「Documents」(文件) 面板中,您會發現有一份文件已指派給訓練集。
將預先加上標籤的資料匯入訓練集和測試集
在這份指南中,系統會提供預先加上標籤的資料。如果您是處理自有專案,則必須決定如何為資料加上標籤。詳情請參閱「標籤選項」。
如要為每個文件類型加上標籤,Document AI 自訂處理器在訓練集和測試集中至少需要各一份文件。為求最佳成效,建議每個標籤至少須準備 10 份文件。如果有 5 個標籤,需準備 50 份文件用於訓練,50 份用於測試。訓練資料越多,準確率通常就會越高。
匯入完畢後,「Manage Dataset」(管理資料集) 分頁中就會顯示這些文件。
匯入時以批次處理的方式為文件加上標籤
或者,結構定義設定完成後,您可以對匯入特定目錄的所有文件加上標籤,利用標籤節省時間。
訓練處理器
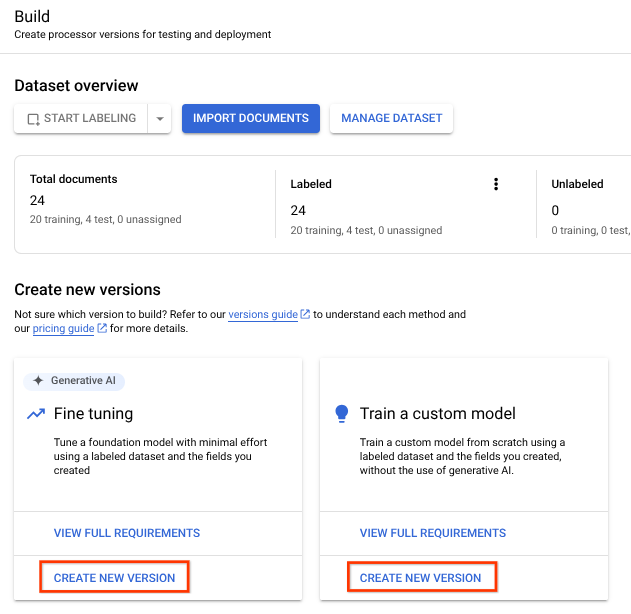
現在您已經匯入訓練和測試資料,接著可以訓練處理器。 由於訓練可能需要數小時,因此在開始訓練前,請務必先確認您已使用適當的資料和標籤完成處理器設定。
您可以使用加上標籤的資料,訓練微調模型和自訂模型。經過微調的模型會使用生成式 AI。自訂模型會使用加上標籤的資料,訓練專屬的大型語言模型。結構定義中至少須有兩個標籤,建議提供 10 份訓練文件和 10 份測試文件 (最少各 1 份)。
部署處理器版本
評估及測試處理器
自動為新匯入的文件加上標籤
部署經過訓練的處理器版本後,您可以在匯入新文件時使用自動加上標籤功能,節省標籤時間。
使用處理器
您可以管理自訂訓練的處理器版本,就像其他處理器版本一樣。詳情請參閱「管理處理器版本」。
您也可以傳送處理要求至自訂處理器,然後比照其他分類器處理器以同樣的方式處理回應。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本頁所用資源的費用,請按照下列步驟操作。