如要訓練、進階訓練或評估處理器版本,必須使用加上標籤的文件資料集。
本頁面說明如何將處理器結構定義中的標籤套用至資料集內的匯入文件。
本頁假設您已建立支援訓練、進階訓練或評估的處理器。如果處理器支援這項功能,您現在會在 Google Cloud 控制台中看到「Train」(訓練) 分頁。此外,本文也假設您已建立資料集、匯入文件,並定義處理器結構定義。
生成式 AI 擷取作業的名稱欄位
欄位的命名方式會影響生成式 AI 擷取欄位的準確度。為欄位命名時,建議採取下列最佳做法:
以與文件中描述欄位時所用的語言命名欄位: 舉例來說,如果文件中的欄位描述為
Employer Address,則欄位名稱應為employer_address。請勿使用縮寫,例如emplr_addr。欄位名稱目前不支援空格:請使用
_,不要使用空格。舉例來說,First Name的 VCID 會命名為first_name。反覆修改名稱,提高準確度:Document AI 有一項限制,就是無法變更欄位名稱。如要測試不同名稱,請使用重新命名實體名稱工具,在資料集中將舊實體名稱更新為新名稱,匯入資料集,在處理器中啟用新實體,然後停用或刪除現有欄位。
零樣本和少量樣本學習
搭載 Gemini 的模型具備零樣本和少量樣本學習能力,因此即使沒有或只有少量訓練資料,也能建立高效能模型。
零樣本學習是機器學習的範例,預先訓練的模型在沒有任何後續訓練的情況下,學會辨識和分類測試期間未曾遇到的類別和實體。
少量樣本學習是指模型學習辨識及分類新類別和實體,且每個類別只有少量訓練樣本。這項技術會運用從大型且標示清楚的資料集預先訓練模型所獲得的知識,提升少樣本任務的成效。
如果訓練資料集整齊且經過仔細標記,少樣本學習的成效會更出色。通常這表示您至少要有 10 個測試和 10 個訓練範例,供模型學習。
標籤選項
您可以透過下列方式為文件加上標籤:
手動:在 Google Cloud 控制台中手動標記文件
自動加上標籤:使用現有處理器版本產生標籤
匯入預先加上標籤的文件:如果您已有加上標籤的文件,可藉此節省時間
在 Google Cloud 控制台中手動加上標籤
在「Train」(訓練) 分頁中選取文件,開啟標籤工具。
在標籤工具左側的結構定義標籤清單中,選取「新增」符號,然後選取「外框」工具,醒目顯示文件中的實體,並將其指派給標籤。
在下方的螢幕截圖中,文件中的 EMPL_SSN EMPLR_ID_NUMBER、EMPLR_NAME_ADDRESS、FEDERAL_INCOME_TAX_WH、SS_TAX_WH、SS_WAGES 和 WAGES_TIPS_OTHER_COMP 欄位已指派標籤。
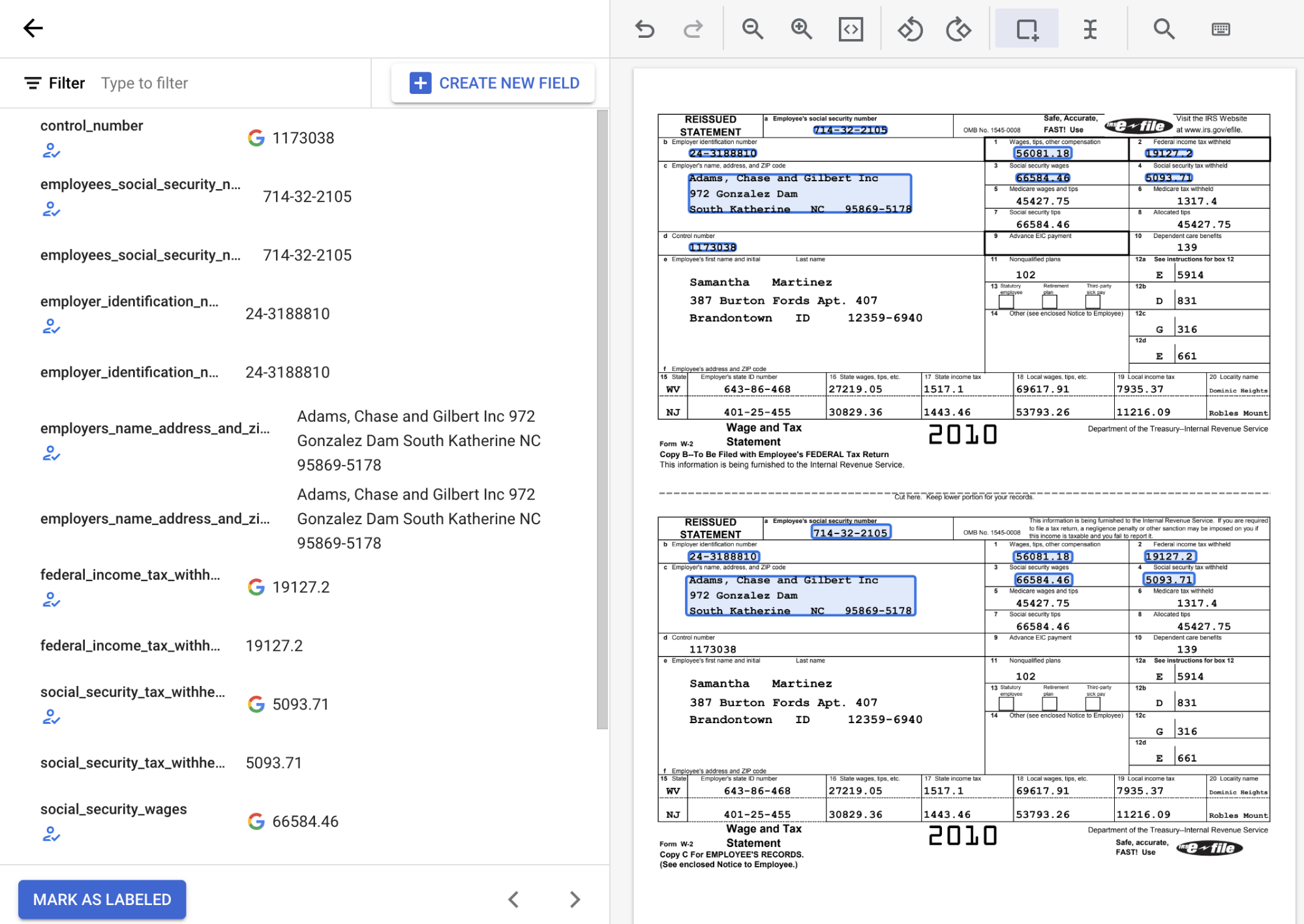
使用「Bounding box」(定界框) 工具選取核取方塊實體時,請只選取核取方塊本身,不要選取任何相關聯的文字。確認左側顯示的核取方塊實體已選取或取消選取,與文件中的狀態相符。

標記父項/子項實體時,請勿標記父項實體。父項實體只是子項實體的容器。只標記子實體。 系統會自動更新父項實體。
標記子實體時,請先標記第一個子實體,然後將相關子實體與該行建立關聯。第一次標記這類實體時,您會在第二個子實體中發現這點。舉例來說,如果為發票標示「說明」,系統會將其視為其他實體。不過,如果標籤是數量,系統會提示你選取上層。
針對每個委刊項選取「New Parent Entity」,為每個新委刊項重複這個步驟。
系統支援最多三層巢狀結構的資料表父項/子項實體。 基礎模型支援三層欄位 (祖父項、父項、子項),因此子項實體可以有一層子項。如要進一步瞭解巢狀結構,請參閱三層巢狀結構。
快速表格
標記表格時,重複標記每個資料列可能會很麻煩。 這項工具非常實用,可複製資料列實體結構。請注意,這項功能僅適用於水平對齊的資料列。
- 首先,請照常標記第一列。
接著,將指標懸停在代表資料列的上層實體上。選取「新增更多資料列」。該列會成為範本,用於建立更多列。
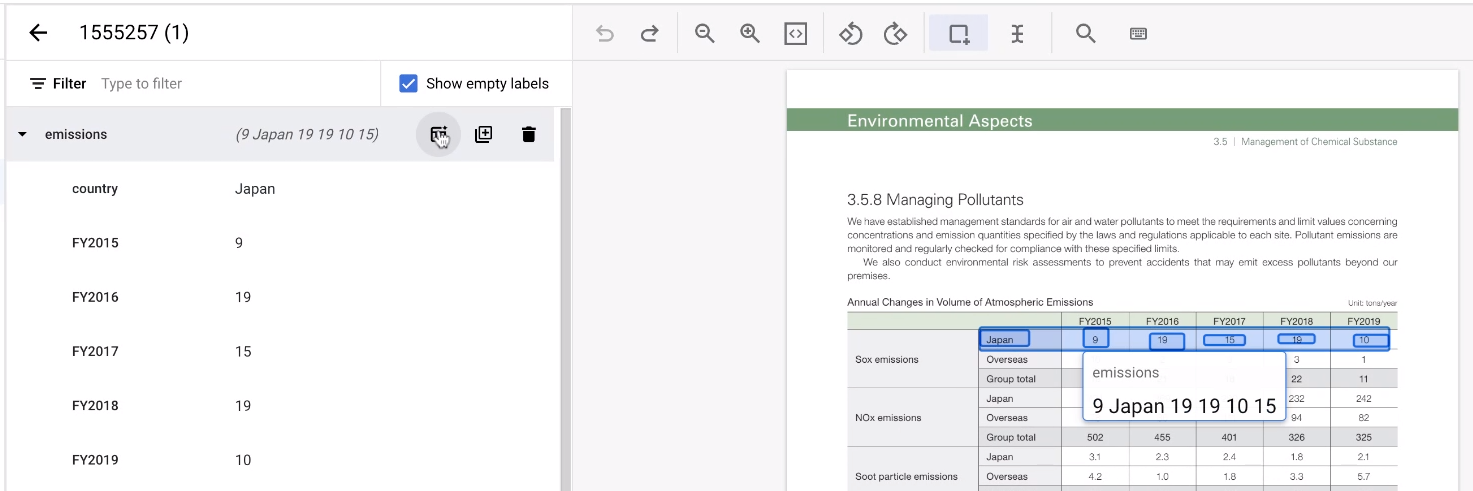
選取表格的其餘區域。
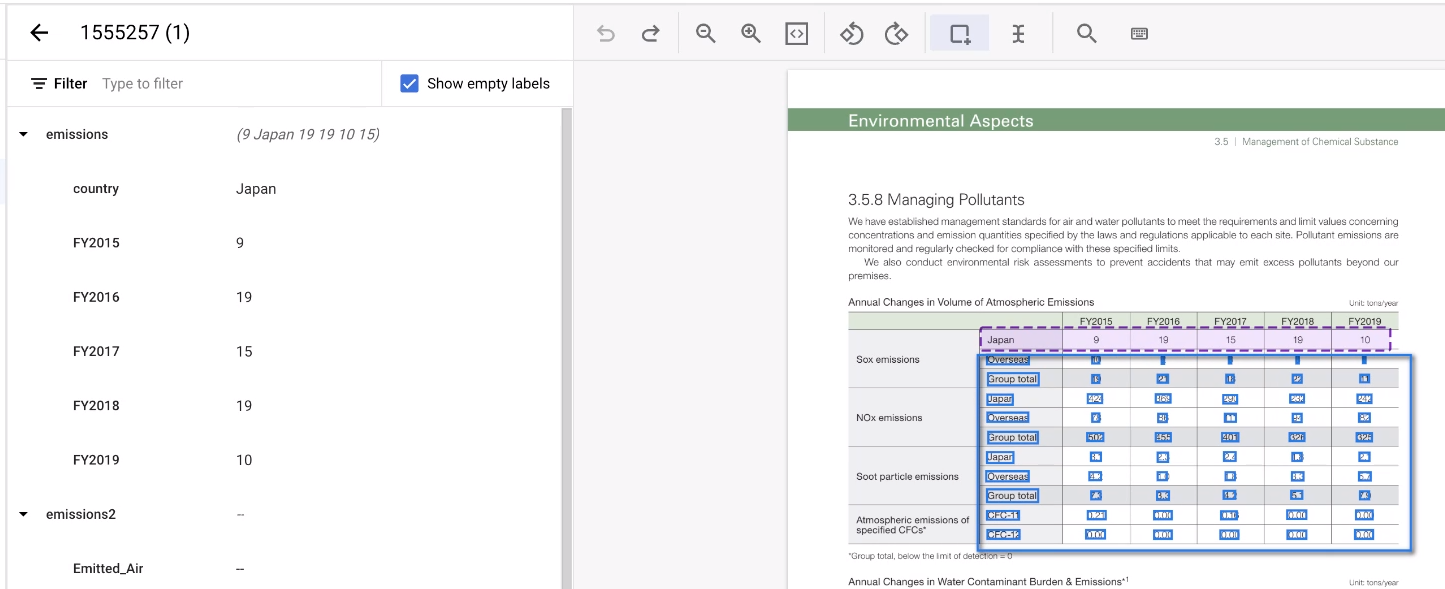
這項工具會猜測註解,通常都能順利運作。如果無法處理任何表格,請手動註解。
在控制台中使用鍵盤快速鍵
如要查看可用的鍵盤快速鍵,請選取標籤主控台右上方的 選單。畫面上會顯示鍵盤快速鍵清單,如下表所示。
| 動作 | 快速鍵 |
|---|---|
| 放大 | Alt + = (macOS 上的 Option + =) |
| 縮小 | Alt 鍵 + - (macOS 上的 Option 鍵 + -) |
| 縮放至適當大小 | Alt + 0 鍵 (macOS 為 Option + 0 鍵) |
| 捲動縮放 | Alt + 捲動 (macOS 上的 Option + 捲動) |
| 平移 | 捲動 |
| 反向平移 | Shift + 捲動 |
| 拖曳平移 | 空格鍵 + 拖曳滑鼠 |
| 復原 | Ctrl + Z (macOS 上的 Control + Z) |
| 重做 | Ctrl + Shift + Z (macOS 上的 Control + Shift + Z) |
自動加上標籤
如果可以使用的話,您可以使用現有版本的處理器開始加上標籤。
您可以在匯入期間啟動自動標記功能。所有文件都會使用指定的處理器版本加上註解。
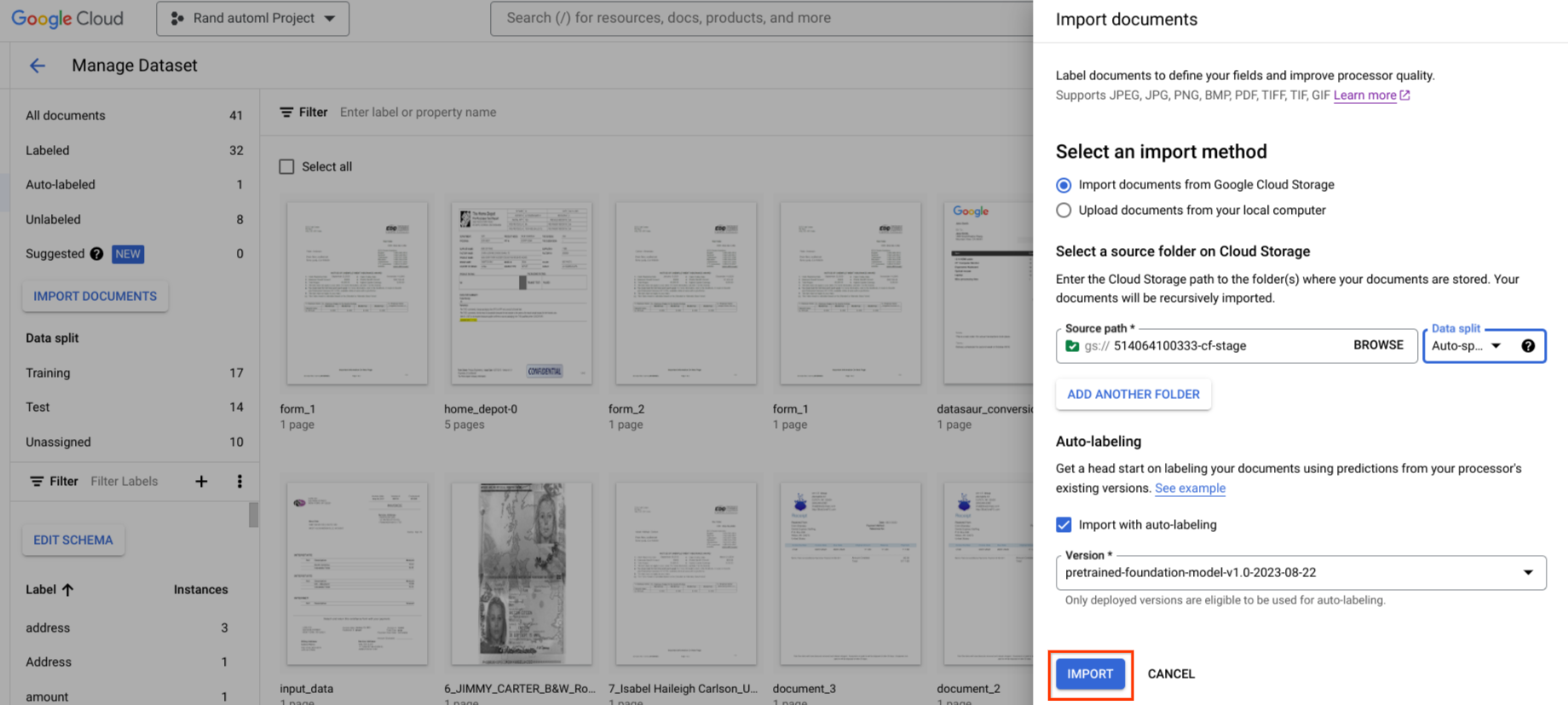
匯入未加上標籤或已自動加上標籤的文件後,即可啟動自動加上標籤功能。系統會使用指定的處理器版本,為所有選取的文件加上註解。
如未將自動加上標籤的文件標示為已加上標籤,則無法使用該文件進行訓練或進階訓練,也無法將該文件用於測試集。手動檢查並修正自動標記的註解,然後選取「標示為已標記」儲存修正內容。然後視需要指派文件。
匯入預先加上標籤的文件
您可以匯入 JSON Document 檔案。如果文件中的 entity 與處理器結構定義中的標籤相符,匯入工具會將 entity 轉換為標籤例項。取得 JSON 文件檔案的方式有幾種:
標記文件的最佳做法
如要訓練高品質的處理器,必須保持標籤一致。建議您採取下列做法:
建立標籤操作說明:操作說明應包含常見和極端案例的範例。以下提供一些訣竅供您參考:
- 說明應註解哪些欄位,以及如何確保標籤一致。舉例來說,標示「金額」時,請指定是否應標示貨幣符號。如果標籤不一致,處理器品質就會降低。
- 為實體的所有出現位置加上標籤,即使標籤類型為
REQUIRED_ONCE或OPTIONAL_ONCE也是如此。舉例來說,如果invoice_id在文件中出現兩次,請為所有出現的項目加上標籤。 - 一般來說,建議先使用預設的邊框工具標記。如果失敗,請使用選取文字工具。
- 如果 OCR 未正確偵測到標籤值,請勿手動修正值。這樣一來,模型就無法用於訓練。
以下是標籤指示範例:
- 訓練註解者:確保註解者瞭解並遵循規範,不會發生任何系統性錯誤。其中一種做法是讓不同的受訓人員為同一組文件加上註解。訓練人員接著可以檢查每位受訓人員的註解工作品質。您可能需要重複這個程序,直到受訓人員達到基準準確度為止。
- 初步審查:新標註者為用途標註的前幾份 (約 10 份) 文件應先經過審查,再標註大量文件,以免出現大量錯誤需要修正。
- 註解品質審查:註解工作相當費力,即使是受過訓練的註解者也可能出錯。建議至少再由一位受過訓練的註解者檢查註解。
新增說明提示
在自訂擷取器和自訂分類器中將標籤新增至結構定義時,可以為標籤新增說明。這有助於訓練處理器,方法是提供提示,讓處理器識別標籤。為測試回覆品質,請試著微調用詞。例如「總金額」、「應付憑據總金額」或「應付憑據的總金額」。
重新同步處理資料集
重新同步可讓資料集的 Cloud Storage 資料夾與 Document AI 的中繼資料內部索引保持一致。如果您不小心變更了 Cloud Storage 資料夾,並想同步處理資料,這個方法就非常實用。
如要重新同步:
在「處理器詳細資料」分頁中,選取「儲存位置」資料列旁的 ,然後選取「重新同步資料集」。
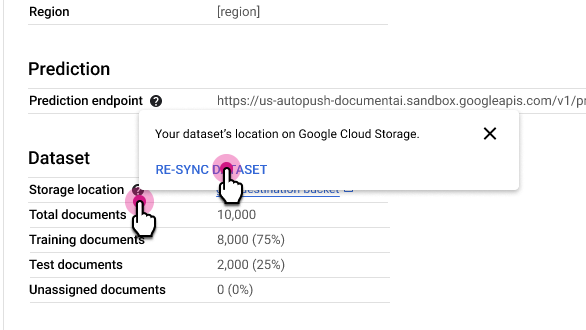
使用須知:
- 如果從 Cloud Storage 資料夾刪除文件,重新同步會將該文件從資料集中移除。
- 如果您將文件新增至 Cloud Storage 資料夾,重新同步作業不會將文件新增至資料集。如要新增文件,請匯入文件。
- 如果修改 Cloud Storage 資料夾中的文件標籤,重新同步會更新資料集中的文件標籤。
遷移資料集
匯入和匯出功能可讓您將資料集中的所有文件從一個處理器移至另一個處理器。如果您在不同區域或 Google Cloud 專案中有處理器、有不同的處理器用於測試和正式環境,或是用於一般離線使用,這項功能就非常實用。
請注意,系統只會匯出文件和標籤,資料集的中繼資料 (例如處理器結構定義、文件指派 (訓練/測試/未指派) 和文件標籤狀態 (已加上標籤、未加上標籤、自動加上標籤) 不會匯出。
複製及匯入資料集,然後訓練目標處理器,與訓練來源處理器並不完全相同。這是因為訓練程序一開始會使用隨機值。使用 importProcessorVersion API 呼叫,在專案之間匯入及遷移完全相同的模型。如果政策允許,建議您採用這種做法,將處理器遷移至較高的環境 (例如從開發環境遷移至測試環境,再遷移至正式環境)。
匯出資料集
如要將所有文件匯出為 JSON Document 檔案至 Cloud Storage 資料夾,請選取「Export Dataset」(匯出資料集)。
請注意以下幾項重點:
匯出時,系統會建立三個子資料夾:「Test」、「Train」和「Unassigned」。系統會將文件放入對應的子資料夾。
文件的標籤狀態不會匯出。如果之後匯入文件,系統不會將其標示為「自動標示」。
如果 Cloud Storage 位於其他 Google Cloud 專案,請務必授予存取權,允許 Document AI 將檔案寫入該位置。具體來說,您必須將儲存空間物件建立者角色授予 Document AI 的核心服務代理程式
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com。詳情請參閱服務代理程式。
匯入資料集
程序與匯入文件相同。
選擇性標籤使用指南
選擇性標籤功能可提供建議,協助您判斷要為哪些文件加上標籤。您可以建立多元的訓練和測試資料集,訓練出具代表性的模型。每次執行選擇性標記時,系統會從資料集中選取最多 30 份最多樣化的文件。
取得建議的文件
建立 CDE 處理器並匯入文件。
- 訓練集至少要有 100 個,測試集則至少要有 25 個。
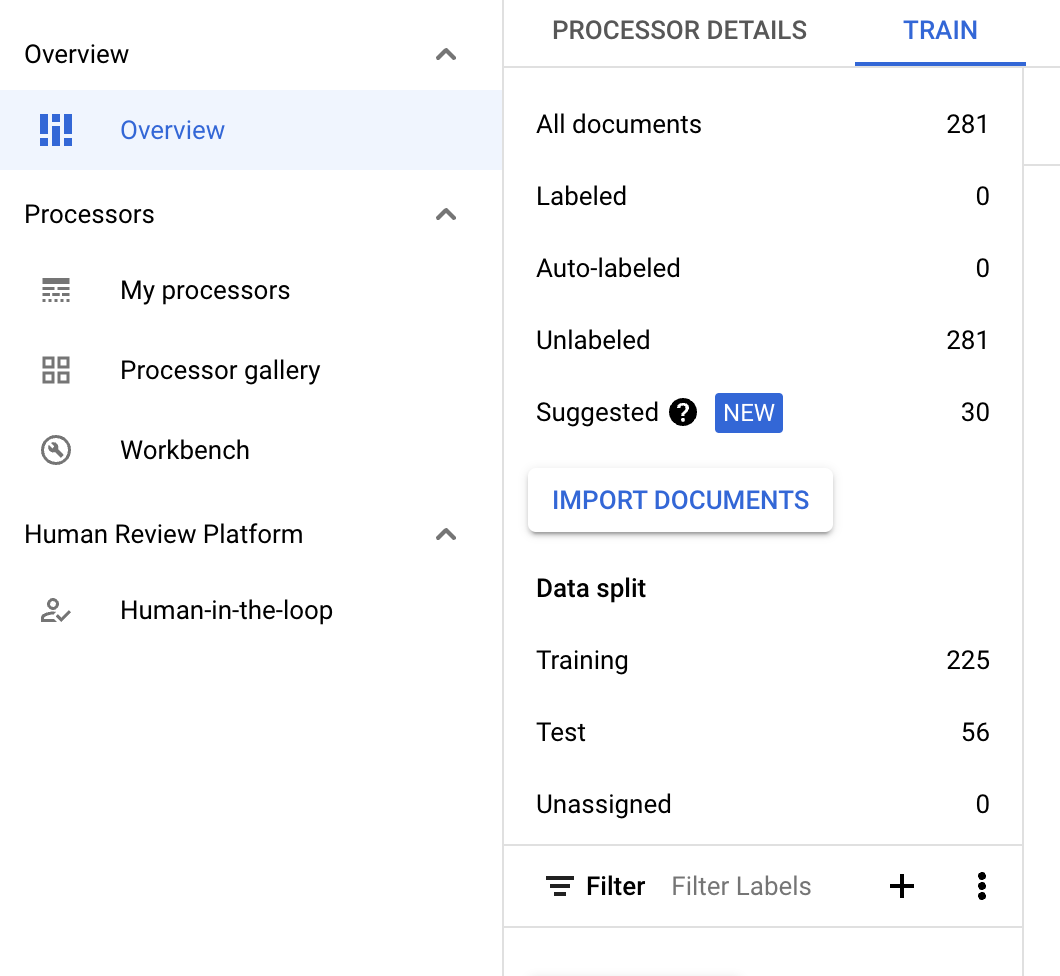
- 匯入足夠的文件並完成選擇性標記後,資訊列就會顯示。
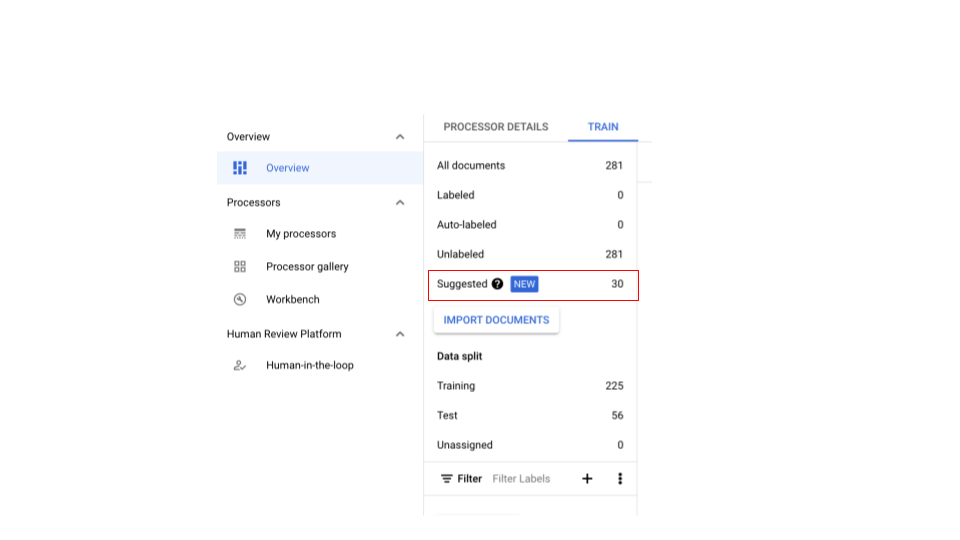
如果 CDE 處理器沒有建議的文件,請匯入更多文件,確保任一分割區都有足夠的文件可供取樣。
- 這應該會啟用「建議」類別中的建議文件。您應該可以手動要求建議的文件。
- 頂端新增了篩選器,可篩除建議的文件。
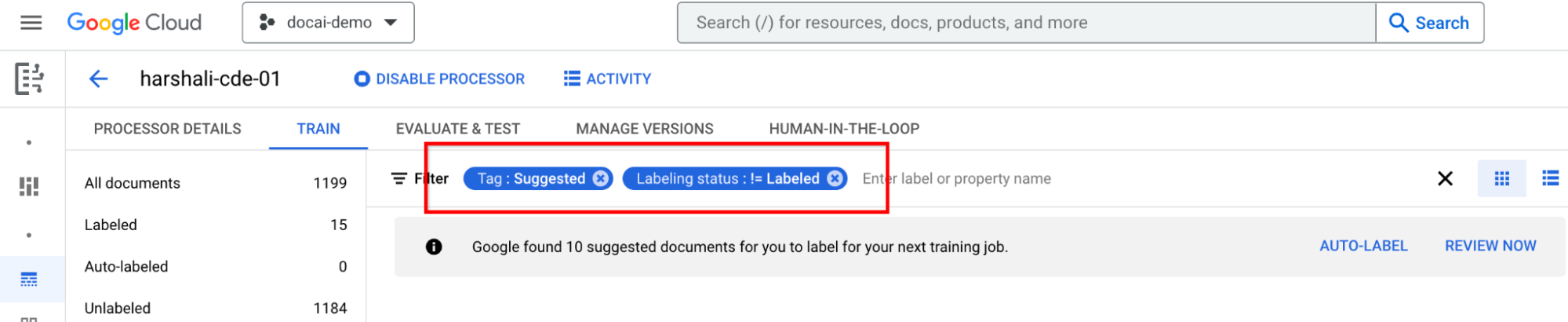
為建議的文件加上標籤
前往左側標籤清單面板中的「建議類別」。開始為這些文件加上標籤。
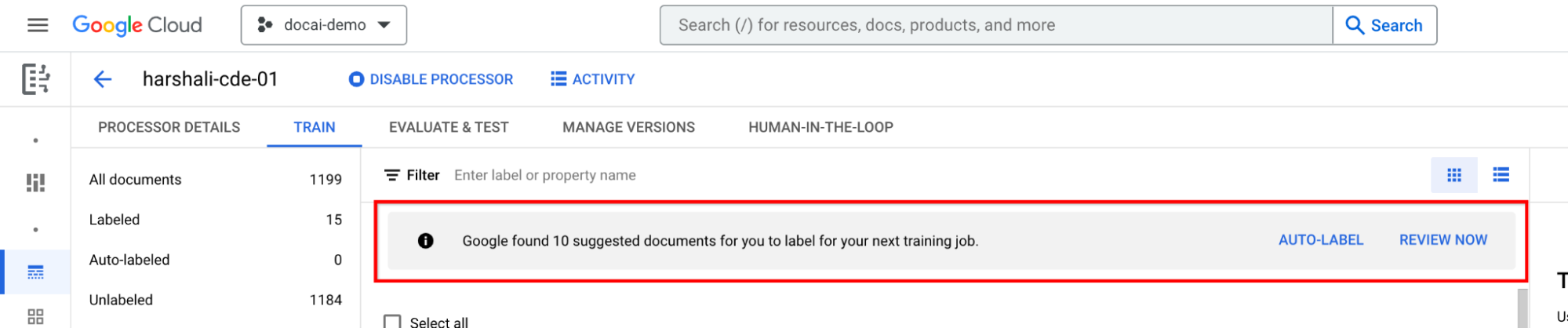
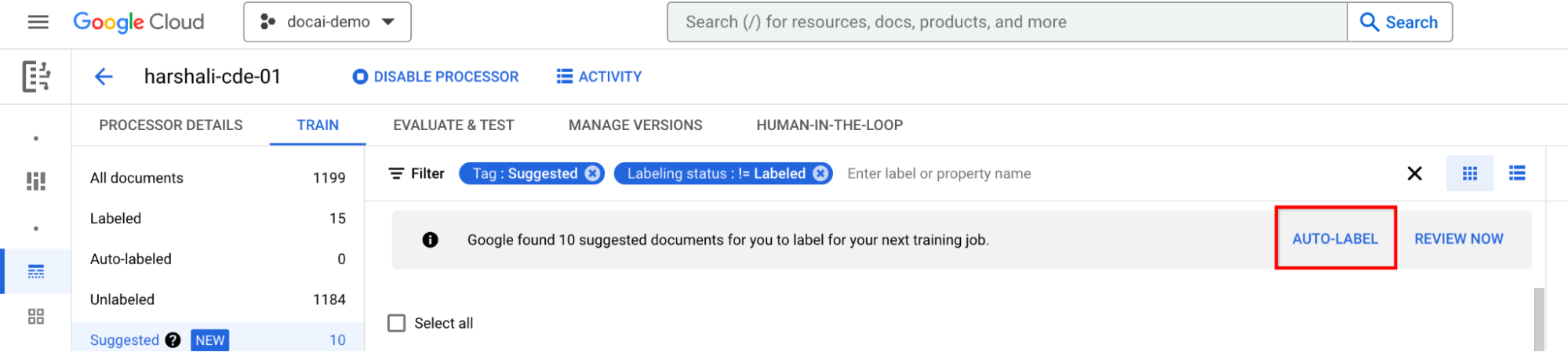
如果處理器已完成訓練,請選取資訊列上的「自動標記」。 為建議的文件加上標籤。
然後選取資訊列上的「立即查看」,即可前往處理器中建議的文件。請務必檢查所有自動加上標籤的文件是否正確。開始查看。
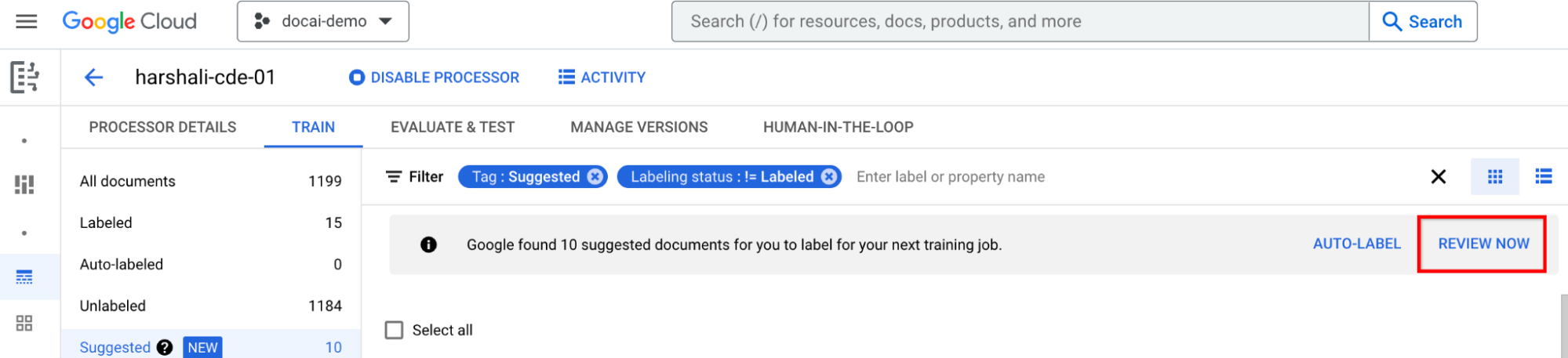
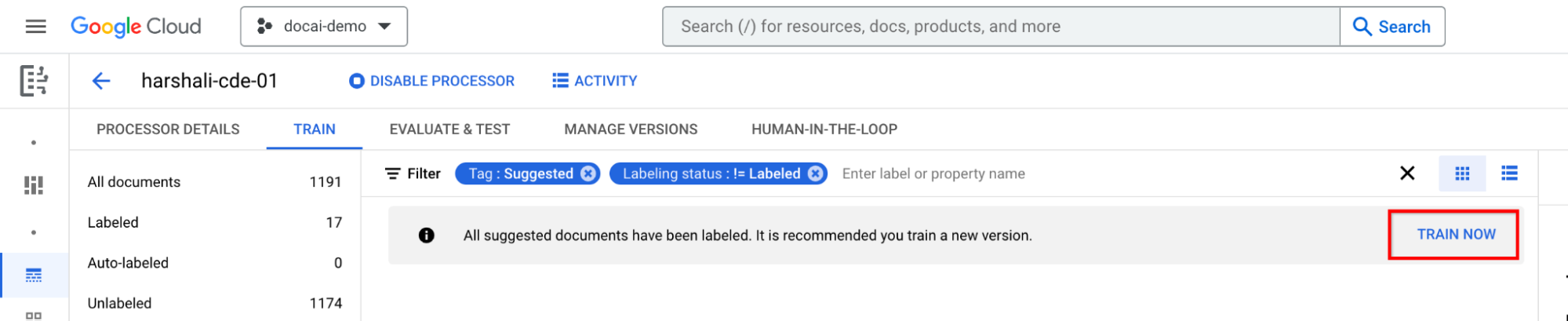
為所有建議的文件加上標籤後再訓練
移至資訊列中的「立即訓練」。建議文件加上標籤後,您應該會看到下列資訊列,建議您進行訓練。
支援的功能和限制
| 功能 | 說明 | 支援 |
|---|---|---|
| 支援舊版處理器 | 如果處理器較舊,且先前已匯入資料集,可能無法順利運作 |