派生フィールドとシグネチャ検出
一般公開プレビューの派生フィールド機能を使用すると、Document AI のお客様は、テキストを直接抽出するのではなく、ドキュメントのコンテキストに基づいてインテリジェントな推論または生成によってフィールドに入力されるように構成できます。
このリリースでは、ドキュメント内の署名の有無を検出する別の機能も追加されています。新しい signature エンティティ タイプを使用すると、このようなエンティティのスキーマを指定できます。署名エンティティは、ドキュメントの視覚的な手がかりを使用して導出されます。
カスタム エクストラクタの派生フィールド
カスタム抽出ツールは、次のモデルの派生フィールドをサポートしています。
pretrained-foundation-model-v1.4-2025-02-05を一般提供 (GA)としてリリース- プレビューとして
pretrained-foundation-model-v1.5-2025-05-05 - プレビューとして
pretrained-foundation-model-v1.5-pro-2025-06-20
これらの機能は、ドキュメント スキーマでラベルを作成または編集するときに、コンソール UI で有効にできます。
派生フィールドは、ドキュメントに明示的に記述されていない情報を抽出できる強力な機能です。これにより、ドキュメントの全体的なコンテキストに基づいて、インテリジェントな推論または生成によってフィールドに入力されるように構成できます。これは、基本的なテキスト抽出を超えて、次のような高度なユースケースをサポートします。
- 住所から国を推測する。
- テーブル内のアイテムの総数をカウントします。
- ID カードが「Real ID」かどうかを検出します。
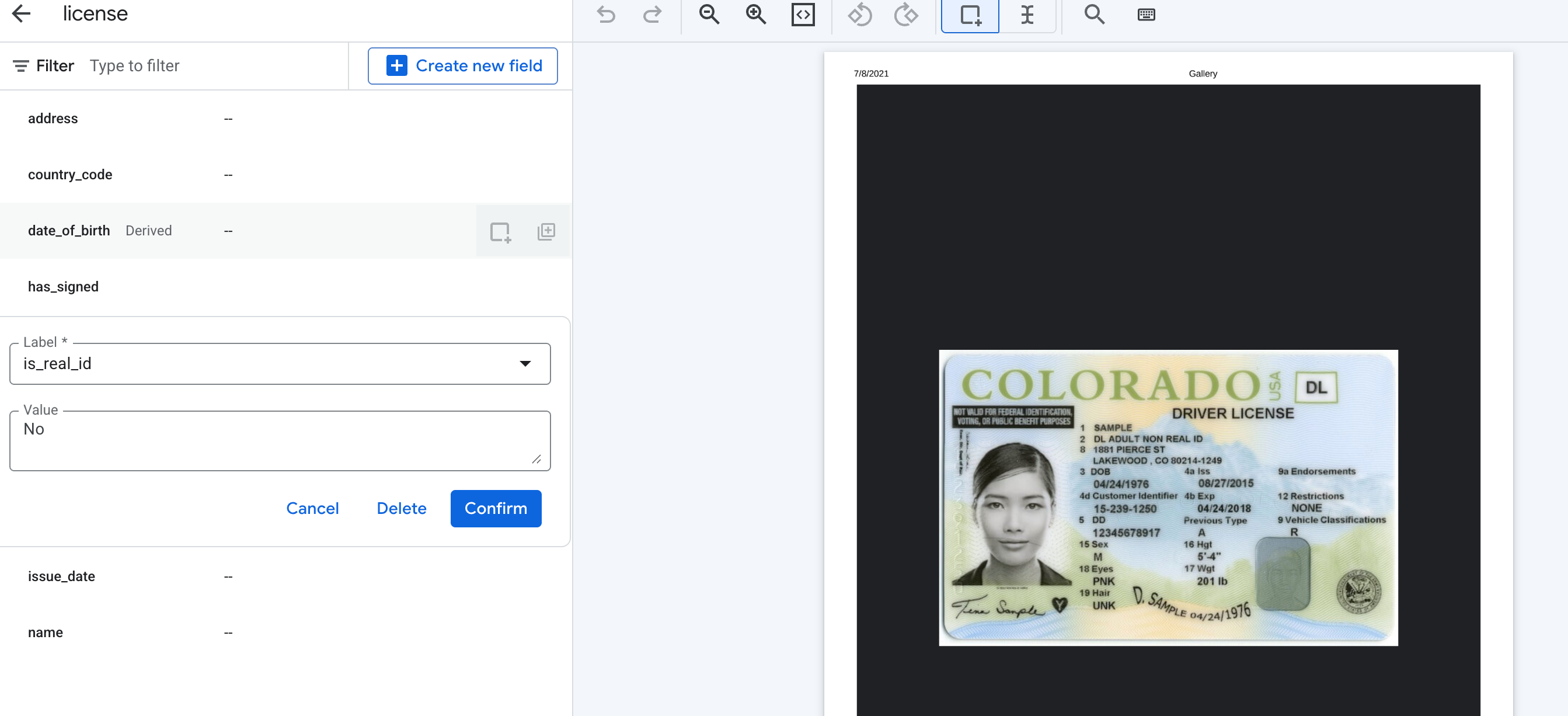
スキーマ作成の例
次に、このようなユースケースの派生フィールドのスキーマを作成する例と、米国の運転免許証を使用した想定される出力を示します。
スキーマ要素を作成するときに
Derivedメソッドを選択します。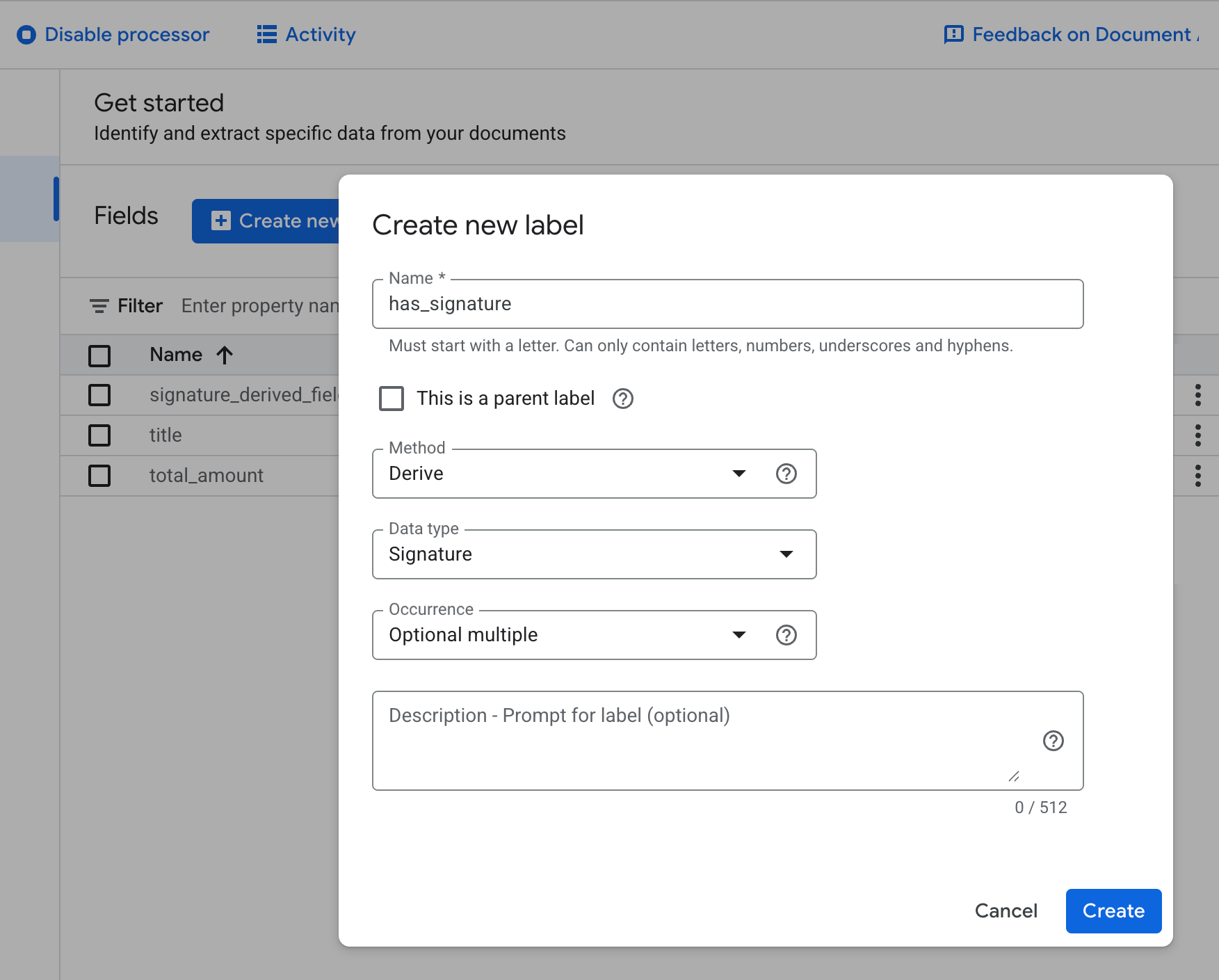
説明的なラベルを追加して、パフォーマンスを向上させます。
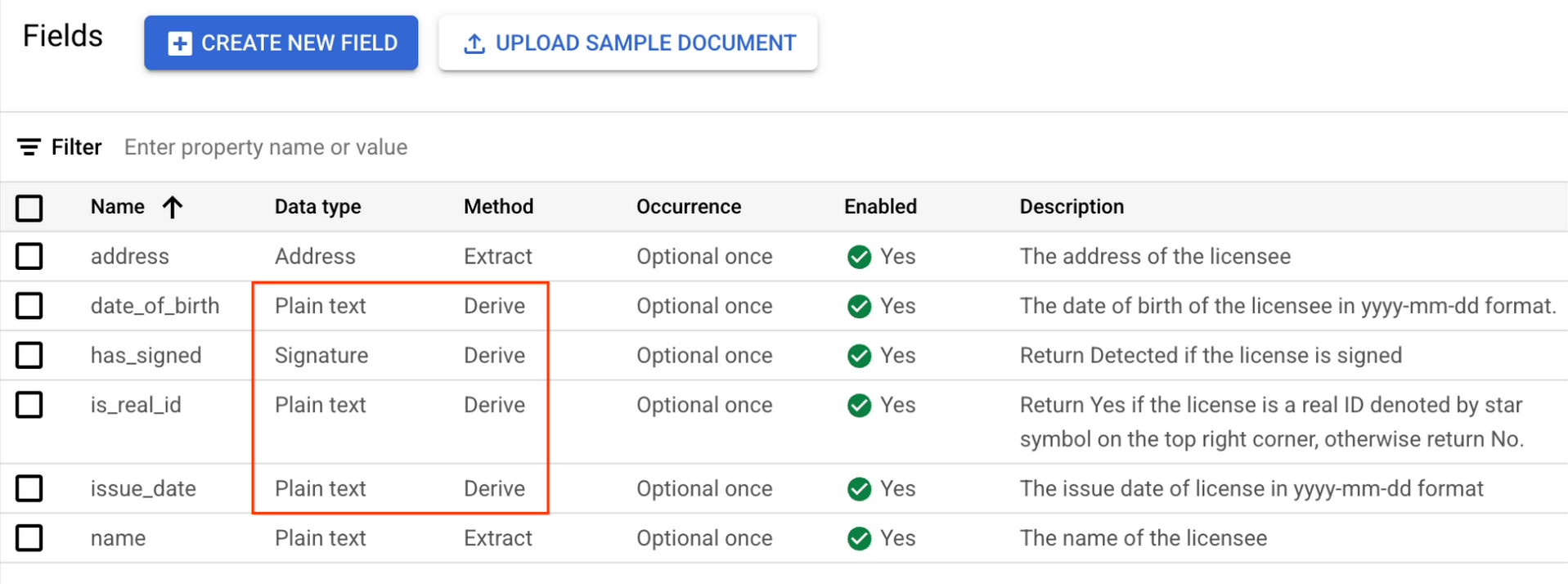
署名などの派生フィールドでは、ドキュメントにラベルを付けるときにバウンディング ボックスを設定する必要はありません。[値] で [検出] を選択します。
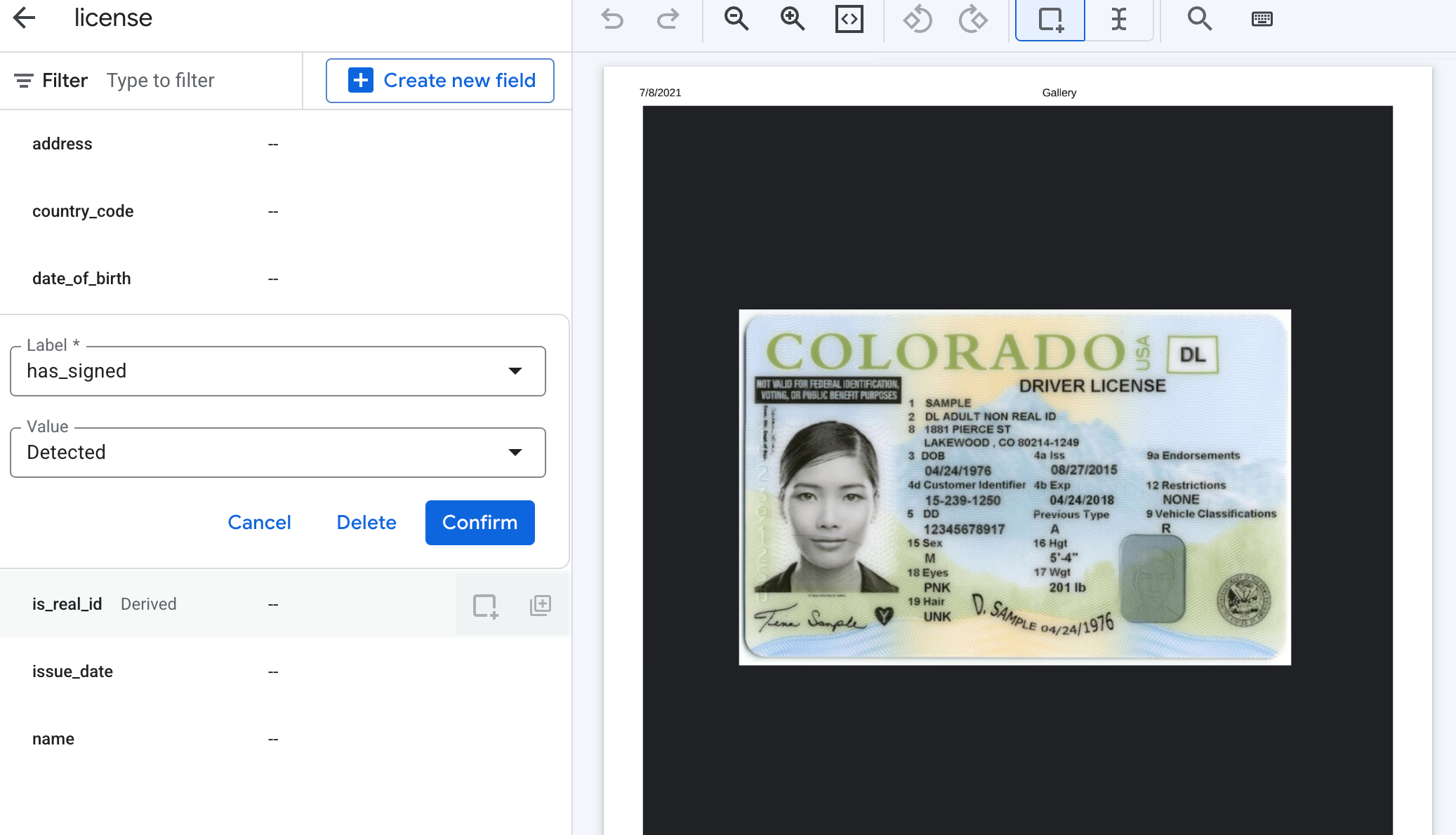
シグネチャ以外の派生フィールドでは、ラベル付けの一部として任意の値を入力して、可能な出力を定義できます。
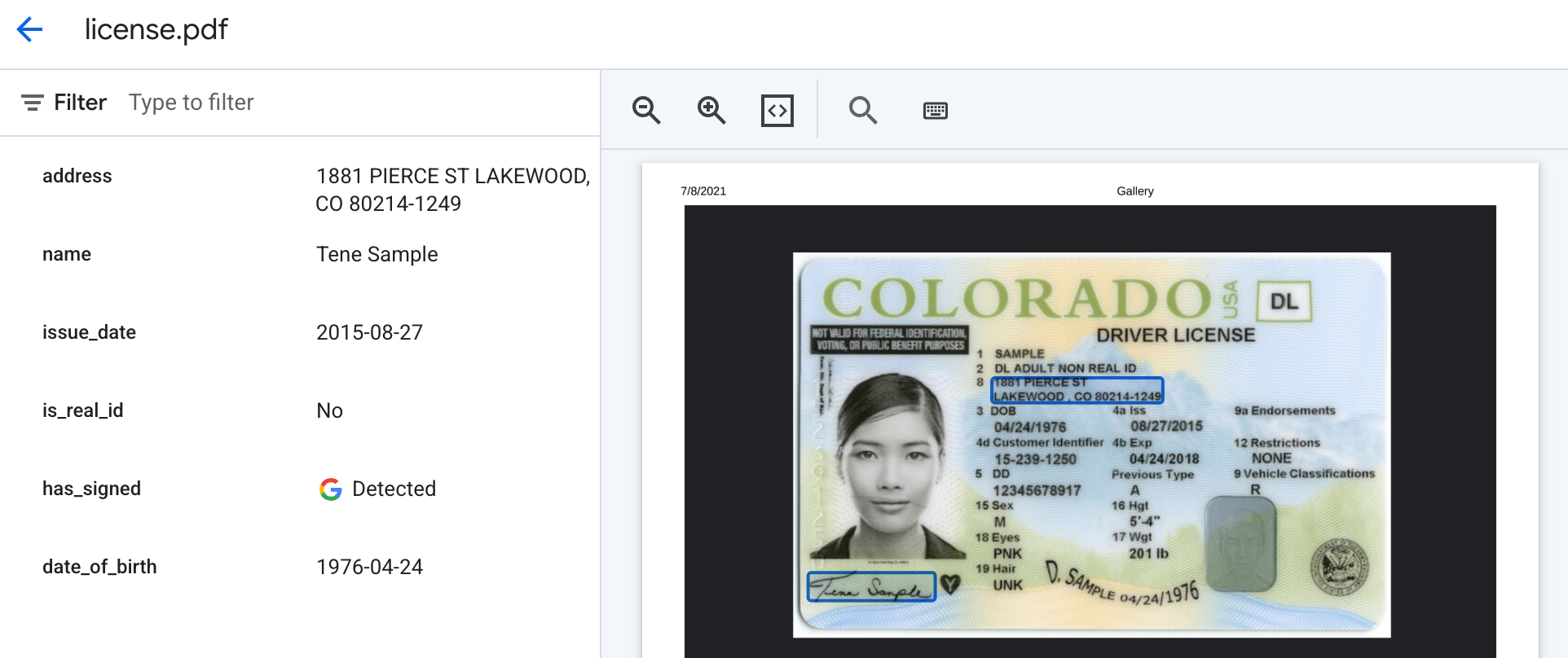
予想される出力は次のようになります。シグネチャの存在は「Detected」または「」として返され、派生フィールドはラベルの説明プロンプト リクエストとしてテキストで返されます。
抽出と派生の概要
プロセッサ スキーマでエンティティを定義するときに、その値の入力方法を選択できます。
抽出: これはデフォルトの方法です。これは、エンティティの値をドキュメント テキストから直接抽出する必要がある場合に機能します。システムはテキストを識別し、
textAnchorやpageAnchorなどのフィールドに入力して、その場所を表示します。Derived: エンティティの値をドキュメントのコンテンツから推測する必要がある場合に使用されます。値がテキストに直接含まれていないため、
textAnchorフィールドとpageAnchorフィールドには値が入力されません。
ユースケースの例: 通貨コードの検索
ドキュメント内の取引の通貨コード(USD、CAD、EUR など)を特定する必要があるとします。
Extractを使用する場合: ドキュメントに「USD」や「€」などの通貨記号やコードが明確に一貫して含まれている場合は、Extractメソッドを使用して、そのテキストを正確に検索して抽出します。Derivedを使用する場合: ドキュメントで「$」のような曖昧な記号(米ドル、カナダドル、オーストラリアドルなどを指す可能性がある)が使用されている場合や、記号がまったく使用されていない場合は、Derivedメソッドを使用します。モデルは、請求先住所や会社の所在地などのドキュメントのコンテキストを分析して、正しい ISO 4217 通貨コードを推測します。
構成のベスト プラクティス
派生フィールドで最良の結果を得るには、ラベリング時にスキーマのプロパティに対して明確な指示を含む description を記述することを強くおすすめします。これにより、モデルの導出タスクをガイドできます。
通貨コードの例では、currency_code という名前のフィールドを作成し、「通貨記号や住所など、ドキュメント内のコンテキスト シグナルを使用して、ドキュメント内の金額値の ISO 4217 通貨コードを見つけます。」という説明を指定できます。
制限事項
派生フィールドはページごとに生成されます。つまり、複数のページにまたがる情報を必要とするユースケースは完全にサポートされていません。たとえば、ドキュメントを要約するように派生フィールドを構成すると、ドキュメント全体をまとめた 1 つの要約ではなく、個々のページごとに別の要約が生成されます。この制限は、ページ間の情報を使用して値を導出する必要があるすべてのフィールドに適用されます。
カスタム エクストラクタでのシグネチャ検出
Document AI のカスタム エクストラクタは、カスタム エクストラクタ モデル pretrained-foundation-model-v1.4-2025-02-05 と pretrained-foundation-model-v1.5-2025-05-05 で署名検出をサポートしています。この機能は、ドキュメント スキーマでラベルを作成または編集するときに、コンソール UI で有効にできます。
署名検出は、ドキュメントに署名が存在するかどうかを判断できる機能です。この機能は、テキストを抽出するのではなく、視覚的な手がかりを分析して署名が存在することを確認します。
シグネチャ検出の仕組み
この機能を有効にするには、プロセッサ スキーマを定義するときに signature データ型を使用できます。プロセッサの動作は、ドキュメント内で署名が検出されたかどうかによって異なります。
署名が見つかった場合、抽出ツールはレスポンスで署名エンティティを返します。has_signed という名前のフィールドの場合、レスポンス オブジェクトの構造は次のようになります。
"has_signed": {
"mention_text": "Detected",
"confidence": <confidence_score_between 0 to 1>,
"normalized_value": {
"text": "Detected",
"signature_value": true
}
}
署名が見つからない場合、エンティティはプロセッサのレスポンスで返されません。
鍵の要件を構成して設定する
シグネチャ検出を設定するには:
- スキーマを定義する: プロセッサ スキーマで、検出するシグネチャの新しいエンティティを追加します。
- データ型を設定する: この新しいエンティティのデータ型として [Signature] を選択します。
- メソッドを derived に設定する:
signatureデータ型のエンティティは、Derivedメソッドのみを使用できます。モデルは署名の存在を視覚的に推測するため、テキスト値を抽出することはありません。そのため、シグネチャ エンティティにはtextAnchorやpageAnchorなどのフィールドは入力されません。
使用例
契約を処理していて、契約書に署名されていることを確認する必要があるとします。is_contract_signed という名前のスキーマ フィールドを作成し、そのデータ型を signature に設定できます。署名付き契約を処理すると、レスポンスに is_contract_signed エンティティが含まれ、署名が存在することが確認されます。署名がない場合、このエンティティはレスポンスに含まれません。これにより、署名されていないドキュメントをすばやくレビュー用にマークできます。
次のステップ
専用プロセッサのアップトレーニングについて学習する。