事前トレーニング済みプロセッサをアップトレーニングする
Invoice パーサー を使用すると、事前トレーニング済みプロセッサをアップトレーニングして精度を高めることができます。事前に作成されたモデルを使用して、このモデルを独自のデータでトレーニングし、カスタム フィールドを追加します。請求書の形式にはさまざまなものがあります。一般的な請求書パーサーをデータでアップトレーニングすることで、特定の形式の精度が向上し、パーサーは事前トレーニング済みモデルでサポートされていないフィールドを抽出できるようになります。サンプルデータが提供されていますが、独自のデータを使用して同じ手順を行うこともできます。
このタスクを Google Cloud コンソールで直接行う際の順を追ったガイダンスについては、「ガイドを表示」をクリックしてください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Google Cloud コンソールのナビゲーション メニューで [Document AI] を選択し、[プロセッサ ギャラリー] を選択します。
[プロセッサ ギャラリー] で、[Invoice パーサー] を
検索 して [作成] を選択します。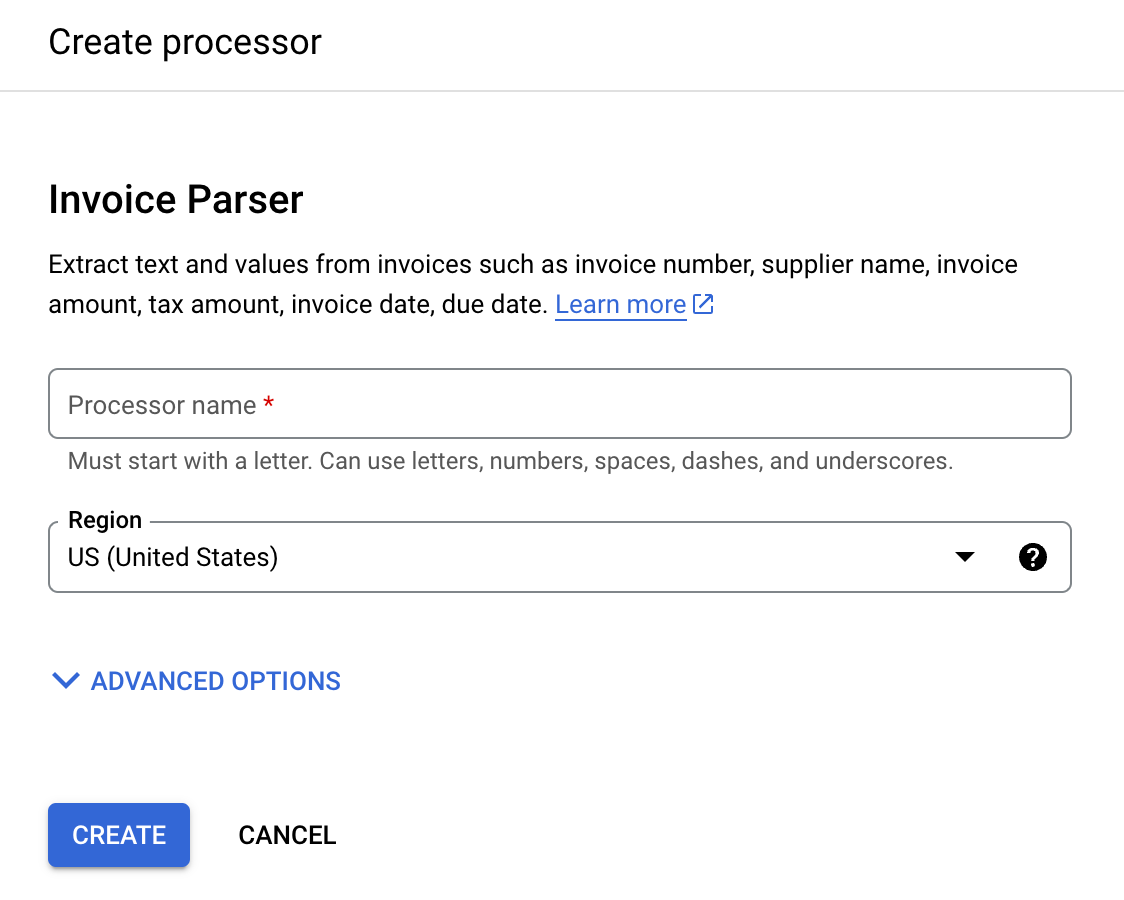
[プロセッサ名] を入力します(例:
invoice-parser-for-uptraining)。最も近いリージョンを選択します。
[作成] を選択します。[プロセッサの詳細] タブが表示されます。
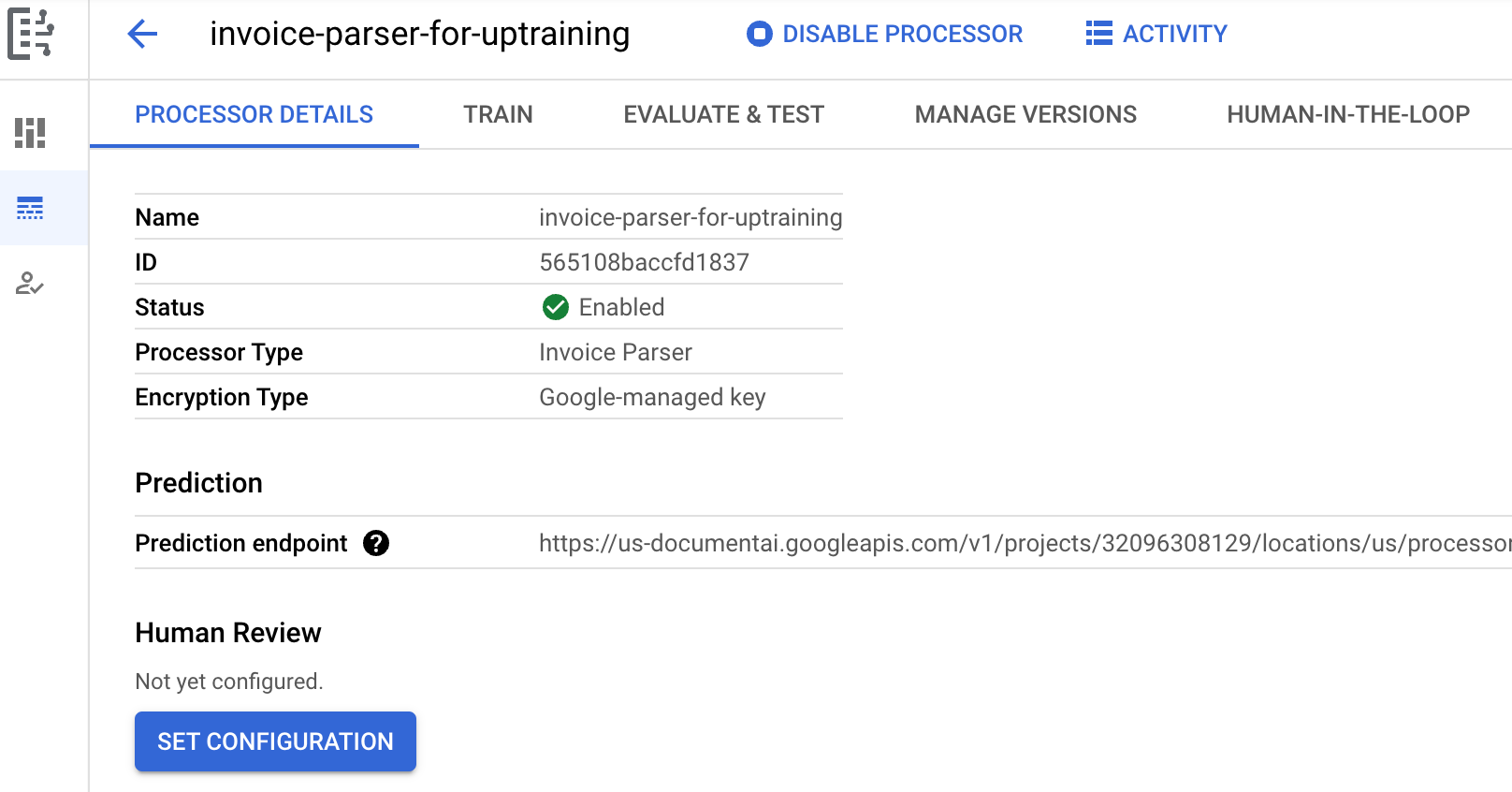
プロセッサの [
トレーニング ] タブに移動します。[
データセットのロケーションを設定 ] を選択します。空の Cloud Storage バケットまたはフォルダを選択または作成するように求められます。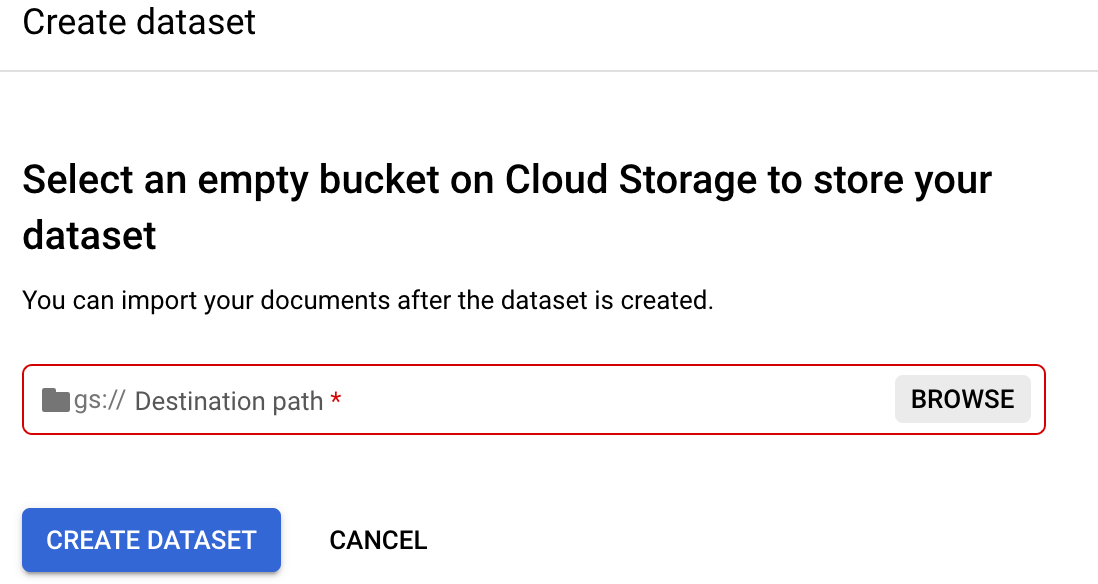
[
参照 ] を選択して、[フォルダを選択] を開きます。[
新しいバケットを作成 ] を選択し、画面の指示に沿って新しいバケットを作成します。Cloud Storage バケットの作成の詳細については、Cloud Storage バケットをご覧ください。注: バケットは最上位のストレージ エンティティであり、フォルダのネストが可能です。バケットを作成して選択する代わりに、既存のバケット内に空のフォルダを作成して選択することもできます。シミュレートされたフォルダを参照してください。
バケットを作成すると、そのバケットの [フォルダの選択] ページが表示されます。
バケットの [フォルダの選択] ページで、ダイアログの下部にある [
選択 ] を選択します。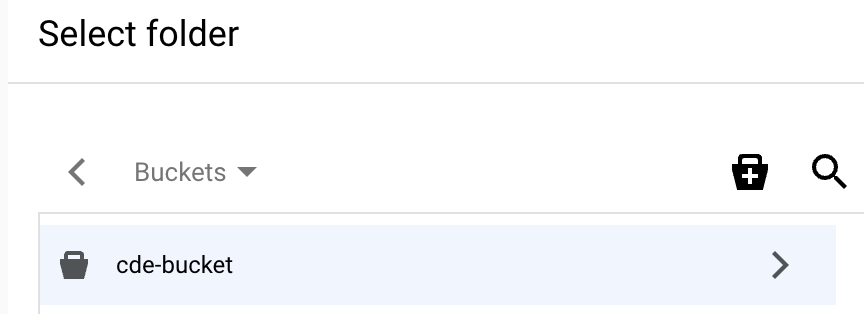
[宛先のパス] に選択したバケット名が入力されていることを確認します。[
データセットを作成 ] を選択します。データセットの作成には、数分かかることがあります。
アップトレーニングに直接進む: 事前にラベル付けされたデータをインポートするに進みます。サンプル ドキュメントをインポートする代わりに、ツールを使用してフィールドに手動でラベルを付け、ドキュメントをトレーニング データに追加します。
トレーニング セットにドキュメントを手動でラベル付けして追加する: アップトレーニングに進む前に、手動ラベル付け用のサンプル ドキュメントをインポートするに進み、手順を完了します。
[トレーニング] タブで、[
ドキュメントのインポート ] を選択します。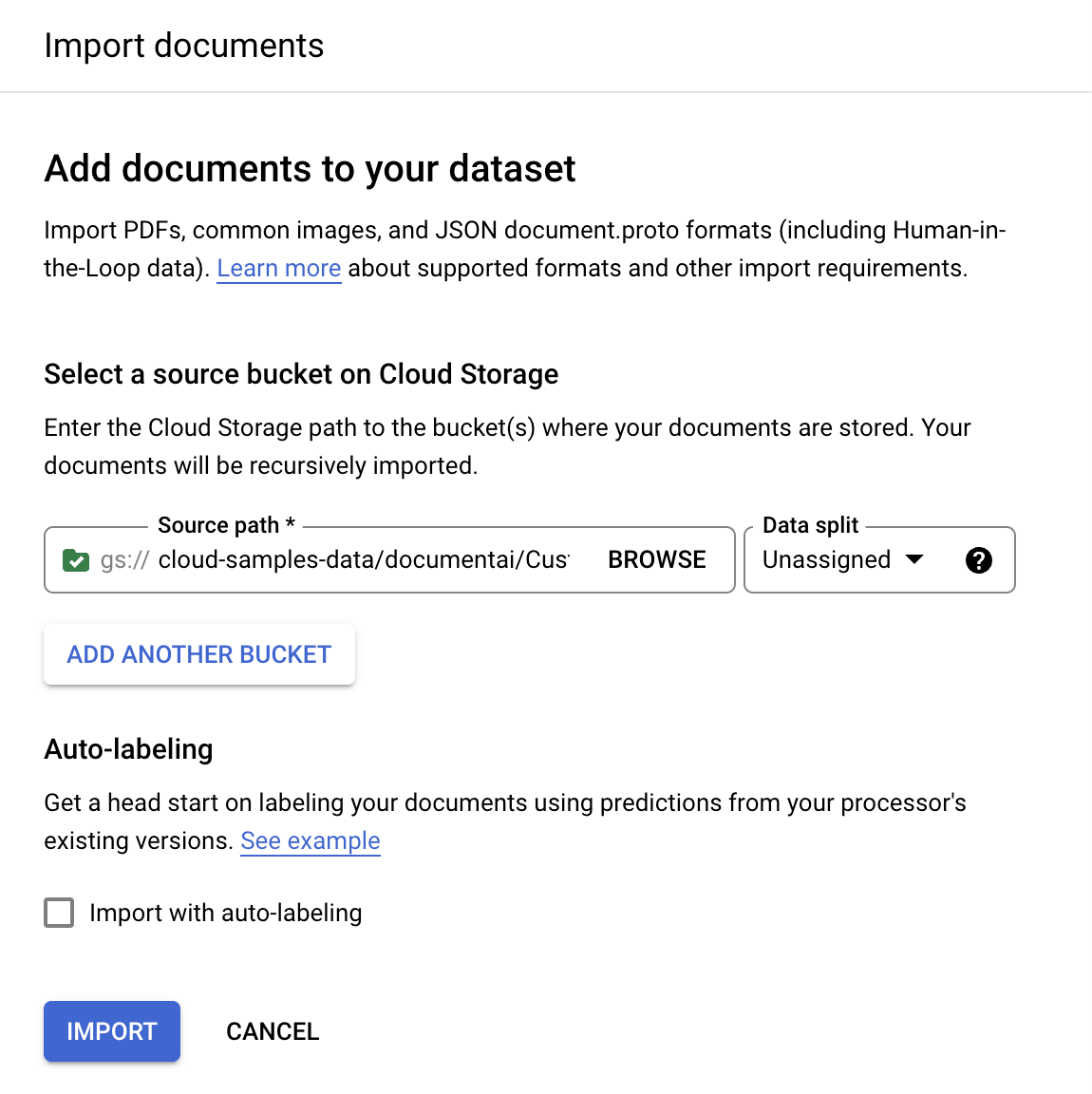
この例では、このバケット名を [
転送元のパス ] に入力します。これは 1 つのドキュメントに直接リンクしています。cloud-samples-data/documentai/codelabs/uptraining/pdfs[データ分割] で、[未割り当て] を選択します。このフォルダ内のドキュメントは、テストセットにもトレーニング セットにも割り当てられません。[自動ラベル付けを使用したインポート] をオフのままにします。
[インポート] を選択します。Document AI により、ドキュメントがバケットからデータセットに読み込まれます。インポート バケットの変更や、インポート完了後のバケットからの読み取りは行われません。
[トレーニング] タブで、左下の [
スキーマを編集 ] を選択します。[ラベルの管理] ページが開きます。未使用のラベルを無効にするには、次のリストにないフィールドの
チェックボックス をオンにして、[無効にする] をクリックします。次のフィールドは有効のままにしておく必要があります。invoice_date line_item amount description receiver_address receiver_name supplier_address supplier_name total_amount注: ラベルは削除できないため、使用しないラベルは無効にしてください。
ラベルが完成したら、[
保存 ] を選択します。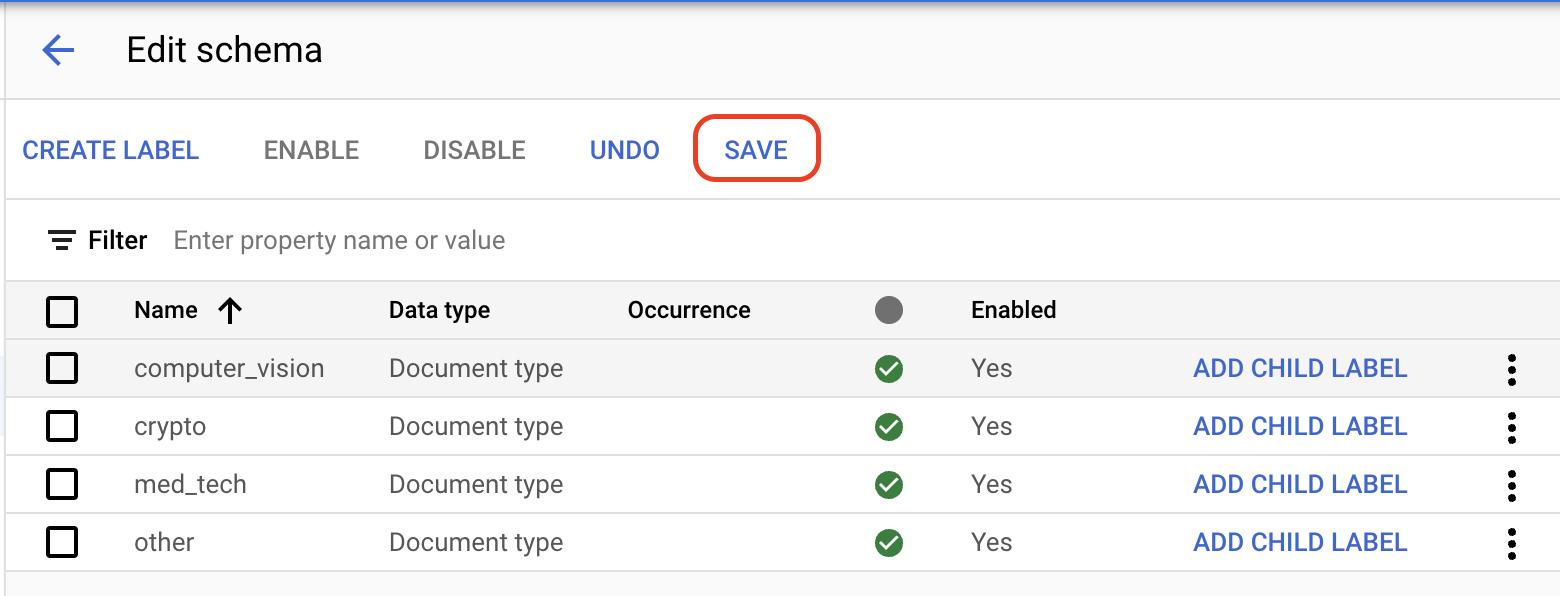
戻る矢印 をクリックして [トレーニング] ページに戻ります。[トレーニング] タブに戻り、[
ドキュメント ] を選択して [ラベル管理] コンソールを開きます。次に、左側のパネルで、アノテーションを付ける値に対応するスキーマラベルを選択して、ラベルを適用します。
デフォルトで [
境界ボックス ] ツールを使用するか、複数行値の場合は [テキスト選択 ] ツールを使用して、コンテンツを選択し、ラベルを適用します。たとえば、この請求書では、「McWilliam Piping International Piping Company」というテキストに
supplier_nameというラベルが割り当てられます。テキスト フィルタでラベル名を検索することもできます。注: [テキスト選択] ツールはすべてのテキスト値に対して機能するわけではないため、必要に応じて [境界ボックス] を使用します。[境界ボックス] ツールを使用して、チェックボックスなどのテキスト以外のフィールドを選択することもできます。
検出されたテキスト値を確認して、ドキュメント内の正しいテキストが反映されていることを確認します。
ラベルに対応するテキストを選択する場合は、関連するテキストのみを含めるようにしてください。たとえば、
invoice_idラベルには、数値の前に付くことの多い#などの文字を含めないでください。$などの通貨記号は含めないでください。- エンティティのすべてのインスタンスにアノテーションを付けるようにします。たとえば、
supplier_nameやinvoice_idはドキュメント内で複数回出現する可能性があるため、各インスタンスにアノテーションを付ける必要があります。
- エンティティのすべてのインスタンスにアノテーションを付けるようにします。たとえば、
ラベルを付けるフィールドごとに繰り返します。
ドキュメントのアノテーションが完成したら、[
ラベル付きとしてマーク ] を選択します。[トレーニング] タブの左側のパネルで、1 つのドキュメントにラベルが付けられています。
[トレーニング] タブで、[
すべて選択 ] チェックボックスをオンにします。[
セットに割り当て ] リストから [トレーニング] を選択します。[
ドキュメントをインポート ] を選択します。[
ソースパス ] に次のパスを入力します。このバケットには、事前にラベル付けされたドキュメントが Document JSON 形式で含まれています。cloud-samples-data/documentai/Custom/Invoices/JSON[データ分割] リストから [自動分割] を選択します。これにより、トレーニング セットが 80%、テストセットが 20% になるようにドキュメントが自動的に分割されます。[自動ラベル付けを使用したインポート] をオフのままにします。
[インポート] を選択します。インポートには数分かかることがあります。その後、[トレーニング] タブにドキュメントが表示されます。
[トレーニング] ページで、[
ドキュメントをインポート ] をクリックします。次の Cloud Storage パスをコピーして貼り付けます。このディレクトリには、ラベルのない請求書の PDF が 5 つ含まれています。[データ分割] プルダウン リストから [トレーニング] を選択します。
cloud-samples-data/documentai/Custom/Invoices/PDF_Unlabeled[自動ラベル付け] セクションで、[
自動ラベル付けを使用したインポート ] チェックボックスをオンにします。ドキュメントのラベル付けを行う既存のプロセッサ バージョンを選択します。
- 例:
pretrained-invoice-v1.3-2022-07-15
- 例:
[インポート] を選択して、ドキュメントがインポートされるのを待ちます。このページを閉じて、後で戻ることができます。
- 完了すると、ドキュメントは [トレーニング] ページの [自動的にラベル付け] セクションに表示されます。
ラベル付きとマークしないと、トレーニングやテストに自動ラベル付きドキュメントを使用できません。[
自動的にラベル付け ] セクションに移動して、自動的にラベル付けされたドキュメントを表示します。最初のドキュメントを選択してラベル付けされているコンソールを開きます。
ラベルを検証して正しいことを確認します。正しくない場合は調整します。
完了したら、[
ラベル付きとしてマーク ] を選択します。自動的にラベル付けされたドキュメントごとにラベルの確認を繰り返します。その後、[トレーニング] ページに戻り、そのデータをトレーニングに使用します。
[
新しいバージョンをアップトレーニング ] を選択します。[
バージョン名 ] フィールドに、このプロセッサ バージョンの名前(invoice-uptrain-1など)を入力します。(省略可)[ラベルの統計データを表示] を選択して、ドキュメント ラベルに関する情報を確認します。これにより、対応範囲を判断できます。[閉じる] を選択してトレーニングの設定に戻ります。
[
トレーニングを開始 ] を選択します。ステータスは右側のパネルで確認できます。[Dataset management] ページが開きます。右側にトレーニングのステータスが表示されます。データセットのサイズによっては、トレーニングに数時間かかります。このページを離れて、後で戻ってくることもできます。
トレーニングが完了したら、[
バージョンの管理 ] タブに移動します。トレーニングしたバージョンの詳細を表示できます。デプロイするバージョンの右側にある [
その他アイコン ] を選択し、[バージョンをデプロイ] を選択します。ポップアップ ウィンドウで [
デプロイ ] を選択します。デプロイが完了するまで数分かかります。
デプロイが完了したら、[
評価とテスト ] タブに移動します。このページでは、ドキュメント全体の F1 スコア、ドキュメント全体の適合率と再現率、個々のラベルなどの評価指標を表示できます。評価と統計情報について詳しくは、プロセッサを評価するをご覧ください。
プロセッサのバージョンを評価するために使用できるように、これまでトレーニングやテストに関与していないドキュメントをダウンロードします。独自のデータを使用している場合は、この目的のために用意されたドキュメントを使用します。
[
テスト ドキュメントをアップロード ] を選択し、ダウンロードしたドキュメントを選択します。[Invoice パーサー分析] ページが開きます。画面出力に、ドキュメントがどの程度適切に分類されたかが表示されます。
別のテストセットまたは別のプロセッサ バージョンに対して評価を再実行することもできます。
Google Cloud コンソールのナビゲーション メニューで [Document AI] を選択し、[マイプロセッサ] を選択します。
削除するプロセッサと同じ行にある [
その他の操作 ] を選択します。[プロセッサを削除] を選択し、プロセッサ名を入力して、もう一度 [削除] を選択して確定します。
プロセッサの作成
データセット用の Cloud Storage バケットを作成する
この新しいプロセッサをトレーニングするには、抽出したいエンティティをプロセッサが識別できるように、トレーニング データとテストデータを含むデータセットを作成する必要があります。
このデータセットには新しい Cloud Storage バケットが必要です。ドキュメントが保存されているバケットと同じバケットは使用しないでください。
手動ラベリング用のサンプル ドキュメントをインポートする
次に、サンプルの請求書の PDF ファイルをデータセットにインポートします。この後のアップトレーニング プロセスに役立つように、このドキュメントのフィールドにラベルを付けます。
このガイドでは、サンプル ドキュメントとなる代表的なファイルが提供されます。
ドキュメントを読み込む際、必要に応じて、インポート時に設定されたトレーニングまたはテストのセットにドキュメントを割り当てたり、後で割り当てを待つこともできます。
ドキュメントまたはインポートしたドキュメントを削除するには、[トレーニング] タブでそれらのドキュメントを選択し、[削除] を選択します。
インポートするデータの準備について詳しくは、データ準備ガイドをご覧ください。
プロセッサ スキーマを定義する
データセットには、Invoice パーサーでサポートされているラベルがすべて含まれていない可能性があります。
その場合は、トレーニングを開始する前に、使用しないラベルを Inactive としてマークする必要があります。アップトレーニングを開始する前に、1 つ以上のカスタムラベルを追加することもできます。
ドキュメントにラベルを付ける
ドキュメント内のテキストを選択してラベルを適用するプロセスを「アノテーション」と呼びます。
以下に、対応するテキストとラベルの完全なセットの例を示します。
| ラベル名 | テキスト |
|---|---|
supplier_name |
McWilliam Piping International Piping Company |
supplier_address |
14368 Pipeline Ave Chino, CA 91710 |
invoice_id |
10001 |
due_date |
2020-01-02 |
line_item/description |
ナックル カプラー |
line_item/quantity |
9 |
line_item/unit_price |
74.43 |
line_item/amount |
669.87 |
line_item/description |
PVC パイプ 12 インチ |
line_item/quantity |
7 |
line_item/unit_price |
15.90 |
line_item/amount |
111.30 |
line_item/description |
Copper パイプ |
line_item/quantity |
7 |
line_item/unit_price |
91.20 |
line_item/amount |
638.40 |
net_amount |
1,419.57 |
total_tax_amount |
113.57 |
total_amount |
1,533.14 |
currency |
$ |
アノテーション付きドキュメントをトレーニング セットに割り当てる
このサンプル ドキュメントにラベルを付けるのが完了したので、これをトレーニング セットに割り当てることができます。
左側のパネルで、1 つのドキュメントがトレーニング セットに割り当てられていることがわかります。
事前にラベル付けされたデータをトレーニング セットとテストセットにインポートする
Document AI のアップトレーニングでは、トレーニング セットとテストセットの両方で少なくとも 10 個のドキュメントと、各セットのラベルごとに 10 個のインスタンスが必要です。
最適なパフォーマンスを得るには、各セットに 50 個以上のドキュメントと、各ラベルに 50 個のインスタンスを含めることをおすすめします。一般的に、トレーニング データが多いほど精度が高くなります。
このガイドでは、あらかじめラベル付けされたデータが用意されています。独自のプロジェクトで作業する場合は、データのラベル付けの方法を決定する必要があります。ラベル付けの方法をご確認ください。
省略可: 新しくインポートしたドキュメントに自動的にラベルを付ける
すでにデプロイされているプロセッサ バージョンでラベルなしドキュメントをインポートする場合は、自動ラベル付けを使用してラベル付けの時間を短縮できます。
プロセッサをトレーニングする
トレーニング データとテストデータがインポートされたので、プロセッサをトレーニングできるようになりました。トレーニングには数時間かかる場合があるため、トレーニングを開始する前に、適切なデータとラベルがプロセッサに設定されていることを確認してください。
プロセッサ バージョンをデプロイする
プロセッサの評価とテストを行う
プロセッサを使用する
Invoice パーサー プロセッサを作成してアップトレーニングできました。
カスタム トレーニング済みのプロセッサ バージョンは、他のプロセッサ バージョンと同様に管理できます。たとえば、プロセッサが非推奨になったときに新しいプロセッサに移行する場合などです。 詳細については、プロセッサ バージョンの管理をご覧ください。
カスタム プロセッサに処理リクエストを送信できます。また、レスポンスは他のエンティティ抽出プロセッサと同じ方法で処理できます。
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の手順を実施します。
不要な Google Cloud 料金が発生しないようにするには、 Google Cloud consoleを使用して、不要なプロセッサやプロジェクトを削除します。
Document AI の学習用に新しいプロジェクトを作成し、そのプロジェクトが不要になった場合は、[プロジェクトを削除][delete-project]します。
既存の Google Cloud プロジェクトを使用した場合は、作成したリソースを削除して、アカウントに課金されないようにします。