BigQuery 與 Document AI 整合,有助於建構文件分析和生成式 AI 用途。隨著數位轉型加速,機構產生了大量文字和其他文件資料,這些資料都蘊藏著巨大的洞察潛力,並可支援新穎的生成式 AI 用途。為協助您運用這類資料,我們很高興宣布 BigQuery 和 Document AI 整合功能,讓您從文件資料中擷取洞察資訊,並建構新的大型語言模型 (LLM) 應用程式。
總覽
BigQuery 客戶現在可以建立由 Google 尖端基礎模型支援的 Document AI 自訂擷取器,並根據自己的文件和中繼資料進行自訂。接著,您就能從 BigQuery 叫用這些自訂模型,以安全且受控的方式從文件中擷取結構化資料,並運用 SQL 的簡便性和強大功能。 整合前,部分客戶嘗試建構獨立的 Document AI 管道,這需要手動管理擷取邏輯和結構定義。由於缺乏內建整合功能,他們必須開發專屬基礎架構,才能同步處理資料並維持一致性。這使得每個文件分析專案都成為一項重大工程,需要大量投資。現在,透過這項整合功能,客戶可以在 BigQuery 中為 Document AI 的自訂擷取器建立遠端模型,並使用這些模型大規模執行文件分析和生成式 AI 作業,開啟資料驅動洞察和創新技術的新時代。
從資料到 AI 的統合治理體驗
您可以在 Document AI 中透過三個步驟建立自訂擷取器:
- 定義要從文件中擷取的資料。這稱為
document schema,會與每個版本的自訂擷取器一併儲存,並可從 BigQuery 存取。 - 視需要提供附有註解的額外文件,做為擷取作業的範例。
- 根據 Document AI 提供的基礎模型,訓練自訂擷取工具的模型。
除了需要手動訓練的自訂擷取器,Document AI 也提供現成可用的擷取器,適用於費用、收據、發票、稅務表單、政府核發的身分證件,以及處理器庫中的多種其他情境。
自訂擷取器準備就緒後,即可前往 BigQuery Studio,按照下列四個步驟使用 SQL 分析文件:
- 使用 SQL 為擷取器註冊 BigQuery 遠端模型。模型可以瞭解文件結構 (如上建立),叫用自訂擷取器,並剖析結果。
- 使用 SQL 為儲存在 Cloud Storage 中的文件建立物件資料表。您可以設定資料列層級的存取權政策,控管資料表中的非結構化資料,限制使用者存取特定文件,藉此限制 AI 功能,確保隱私權和安全性。
- 在物件表格上使用
ML.PROCESS_DOCUMENT函式,對 API 端點進行推論呼叫,藉此擷取相關欄位。您也可以使用函式外的WHERE子句,篩除要擷取的檔案。函式會傳回結構化資料表,每個資料欄都是擷取的欄位。 - 將擷取的資料與其他 BigQuery 資料表彙整,結合結構化與非結構化資料,產生業務價值。
以下範例說明使用者體驗:
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
結果表格
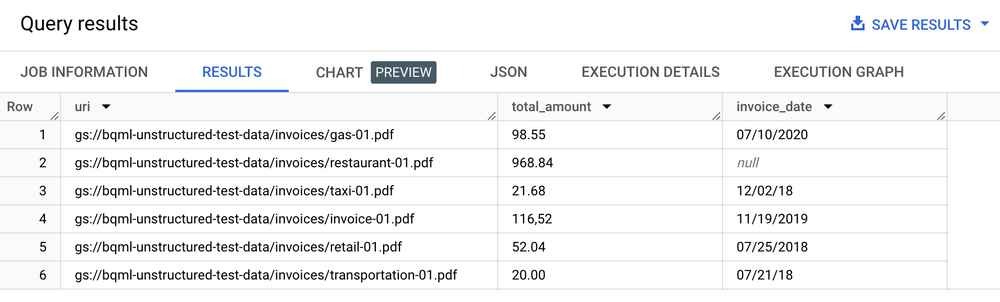
文字分析、摘要和其他文件分析用途
從文件擷取文字後,您可以透過幾種方式執行文件分析:
- 使用 BigQuery ML 執行文字分析:BigQuery ML 支援以各種方式訓練及部署嵌入模型。舉例來說,您可以使用 BigQuery ML 識別支援通話中的顧客情緒,或將產品意見回饋分類。如果您是 Python 使用者,也可以使用 BigQuery DataFrames for pandas,以及類似 scikit-learn 的 API,對資料進行文字分析。
- 使用
text-embedding-004LLM 從分塊文件生成嵌入: BigQuery 有個ML.GENERATE_EMBEDDING函式,可呼叫text-embedding-004模型生成嵌入。舉例來說,您可以使用 Document AI 擷取顧客意見回饋,並透過 PaLM 2 摘要意見回饋,所有作業都可透過 BigQuery SQL 完成。 - 將文件的中繼資料與儲存在 BigQuery 資料表中的其他結構化資料彙整:
舉例來說,您可以根據分塊文件生成嵌入,並用於向量搜尋。
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
實作搜尋和生成式 AI 用途
從文件擷取結構化文字後,您就能建立經過最佳化的索引,以便執行大海撈針查詢。這項功能得益於 BigQuery 的搜尋和索引功能,可解鎖強大的搜尋功能。這項整合功能也有助於解鎖新的生成式 LLM 應用程式,例如使用 SQL 和自訂 Document AI 模型執行文字檔處理作業,進行隱私權篩選、內容安全檢查和權杖分塊。擷取的文字和其他中繼資料結合後,可簡化訓練語料庫的策劃作業,進而微調大型語言模型。此外,您還能運用 BigQuery 的嵌入項目生成和向量索引管理功能,以受控管的企業資料為基礎,建構 LLM 用途。將這個索引與 Vertex AI 同步處理,即可實作檢索增強生成用途,打造更受控且簡化的 AI 體驗。
應用程式範例
使用 Document AI 連接器的範例端對端應用程式: