Molte organizzazioni eseguono il deployment di data warehouse cloud per archiviare informazioni sensibili in modo da poter analizzare i dati per una serie di scopi aziendali. Questo documento descrive come implementare il framework dei controlli chiave delle funzionalità di gestione dei dati cloud (CDMC), gestito dall'Enterprise Data Management Council, in un data warehouse BigQuery.
Il framework CDMC Key Controls è stato pubblicato principalmente per i fornitori di servizi cloud e i fornitori di tecnologia. Il framework descrive 14 controlli chiave che i provider possono implementare per consentire ai propri clienti di gestire e governare in modo efficace i dati sensibili nel cloud. I controlli sono stati scritti dal gruppo di lavoro CDMC, con la partecipazione di oltre 300 professionisti di più di 100 aziende. Durante la stesura del framework, il gruppo di lavoro CDMC ha preso in considerazione molti dei requisiti legali e normativi esistenti.
Questa architettura di riferimento di BigQuery e Data Catalog è stata valutata e certificata in base al framework CDMC Key Controls come soluzione cloud certificata CDMC. L'architettura di riferimento utilizza vari servizi e funzionalità Google Cloud , nonché librerie pubbliche per implementare i controlli chiave CDMC e l'automazione consigliata. Questo documento spiega come implementare i controlli chiave per proteggere i dati sensibili in un data warehouse BigQuery.
Architettura
La seguente architettura di riferimento Google Cloud è in linea con le specifiche di test del framework Key Controls di CDMC v1.1.1. I numeri nel diagramma rappresentano i controlli chiave gestiti con i servizi Google Cloud .

L'architettura di riferimento si basa sul progetto base del data warehouse protetto, che fornisce un'architettura che ti aiuta a proteggere un data warehouse BigQuery che include informazioni sensibili. Nel diagramma precedente, i progetti nella parte superiore (in grigio) fanno parte del progetto di data warehouse protetto, mentre il progetto di governance dei dati (in blu) include i servizi aggiunti per soddisfare i requisiti del framework CDMC Key Controls. Per implementare il framework CDMC Key Controls, l'architettura estende il progetto di governance dei dati. Il progetto di governance dei dati fornisce controlli come classificazione, gestione del ciclo di vita e gestione della qualità dei dati. Il progetto fornisce anche un modo per controllare l'architettura e generare report sui risultati.
Per maggiori informazioni su come implementare questa architettura di riferimento, consulta l'architettura di riferimento CDMC su GitHub.Google Cloud
Panoramica del framework dei controlli chiave del CDMC
La seguente tabella riepiloga il framework CDMC Key Controls.
| # | Controllo delle chiavi CDMC | Requisito di controllo CDMC |
|---|---|---|
| 1 | Conformità al controllo dei dati | I casi aziendali di gestione dei dati nel cloud sono definiti e regolati. Tutti gli asset di dati che contengono dati sensibili devono essere monitorati per verificare la conformità ai controlli chiave del CDMC, utilizzando metriche e notifiche automatiche. |
| 2 | La proprietà dei dati è stabilita sia per i dati migrati sia per quelli generati nel cloud | Il campo Proprietà di un catalogo di dati deve essere compilato per tutti i dati sensibili o altrimenti segnalato a un flusso di lavoro definito. |
| 3 | L'origine e il consumo dei dati sono regolati e supportati dall'automazione | Un registro delle origini dati autorevoli e dei punti di provisioning deve essere compilato per tutti gli asset di dati che contengono dati sensibili o che altrimenti devono essere segnalati a un flusso di lavoro definito. |
| 4 | La sovranità dei dati e il trasferimento transfrontaliero dei dati vengono gestiti | La sovranità dei dati e il movimento transfrontaliero di dati sensibili devono essere registrati, controllati e controllati in base a criteri definiti. |
| 5 | I cataloghi di dati vengono implementati, utilizzati e sono interoperabili | La catalogazione deve essere automatizzata per tutti i dati al momento della creazione o dell'importazione, con coerenza in tutti gli ambienti. |
| 6 | Le classificazioni dei dati vengono definite e utilizzate | La classificazione deve essere automatizzata per tutti i dati al momento della creazione o dell'importazione e deve essere sempre attiva. La classificazione è
automatica per i seguenti elementi:
|
| 7 | I diritti sui dati vengono gestiti, applicati e monitorati | Questo controllo richiede quanto segue:
|
| 8 | L'accesso, l'utilizzo e i risultati etici dei dati vengono gestiti | Lo scopo del consumo dei dati deve essere fornito per tutti gli accordi di condivisione dei dati che coinvolgono dati sensibili. Lo scopo deve specificare il tipo di dati richiesti e, per le organizzazioni globali, l'ambito del paese o della persona giuridica. |
| 9 | I dati sono protetti e i controlli sono documentati | Questo controllo richiede quanto segue:
|
| 10 | È definito e operativo un framework per la privacy dei dati | Le valutazioni di impatto sulla protezione dei dati devono essere attivate automaticamente per tutti i dati personali in base alla giurisdizione. |
| 11 | Il ciclo di vita dei dati è pianificato e gestito | La conservazione, l'archiviazione e l'eliminazione dei dati devono essere gestite in base a un programma di conservazione definito. |
| 12 | La qualità dei dati è gestita | La misurazione della qualità dei dati deve essere attivata per i dati sensibili con metriche distribuite quando disponibili. |
| 13 | I principi di gestione dei costi sono stabiliti e applicati | I principi di progettazione tecnica sono stabiliti e applicati. Le metriche relative ai costi direttamente associate all'utilizzo, all'archiviazione e allo spostamento dei dati devono essere disponibili nel catalogo. |
| 14 | La provenienza e la derivazione dei dati sono comprese | Le informazioni sulla derivazione dei dati devono essere disponibili per tutti i dati sensibili. Queste informazioni devono includere almeno l'origine da cui sono stati importati i dati o in cui sono stati creati in un ambiente cloud. |
1. Conformità al controllo dei dati
Questo controllo richiede di verificare che tutti i dati sensibili vengano monitorati per la conformità a questo framework utilizzando le metriche.
L'architettura utilizza metriche che mostrano in che misura ciascuno dei controlli chiave è operativo. L'architettura include anche dashboard che indicano quando le metriche non soddisfano le soglie definite.
L'architettura include rilevatori che pubblicano risultati e consigli di correzione quando gli asset di dati non soddisfano un controllo chiave. Questi risultati e consigli sono in formato JSON e vengono pubblicati in un argomento Pub/Sub per la distribuzione agli abbonati. Puoi integrare il tuo service desk interno o gli strumenti di gestione dei servizi con l'argomento Pub/Sub in modo che gli incidenti vengano creati automaticamente nel tuo sistema di gestione dei ticket.
L'architettura utilizza Dataflow per creare un abbonato di esempio agli eventi dei risultati, che vengono poi archiviati in un'istanza BigQuery eseguita nel progetto di governance dei dati. Utilizzando una serie di visualizzazioni fornite, puoi eseguire query sui dati utilizzando BigQuery Studio nella console Google Cloud . Puoi anche creare report utilizzando Looker Studio o altri strumenti di business intelligence compatibili con BigQuery. I report che puoi visualizzare includono i seguenti:
- Riepilogo dei risultati dell'ultima esecuzione
- Dettagli dei risultati dell'ultima esecuzione
- Metadati dell'ultima esecuzione
- Asset di dati dell'ultima esecuzione nell'ambito
- Statistiche del set di dati dell'ultima esecuzione
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Pub/Sub pubblica i risultati.
- Dataflow carica i risultati in un'istanza BigQuery.
- BigQuery archivia i dati dei risultati e fornisce viste riepilogative.
- Looker Studio fornisce dashboard e report.
Lo screenshot seguente mostra una dashboard di riepilogo di esempio di Looker Studio.
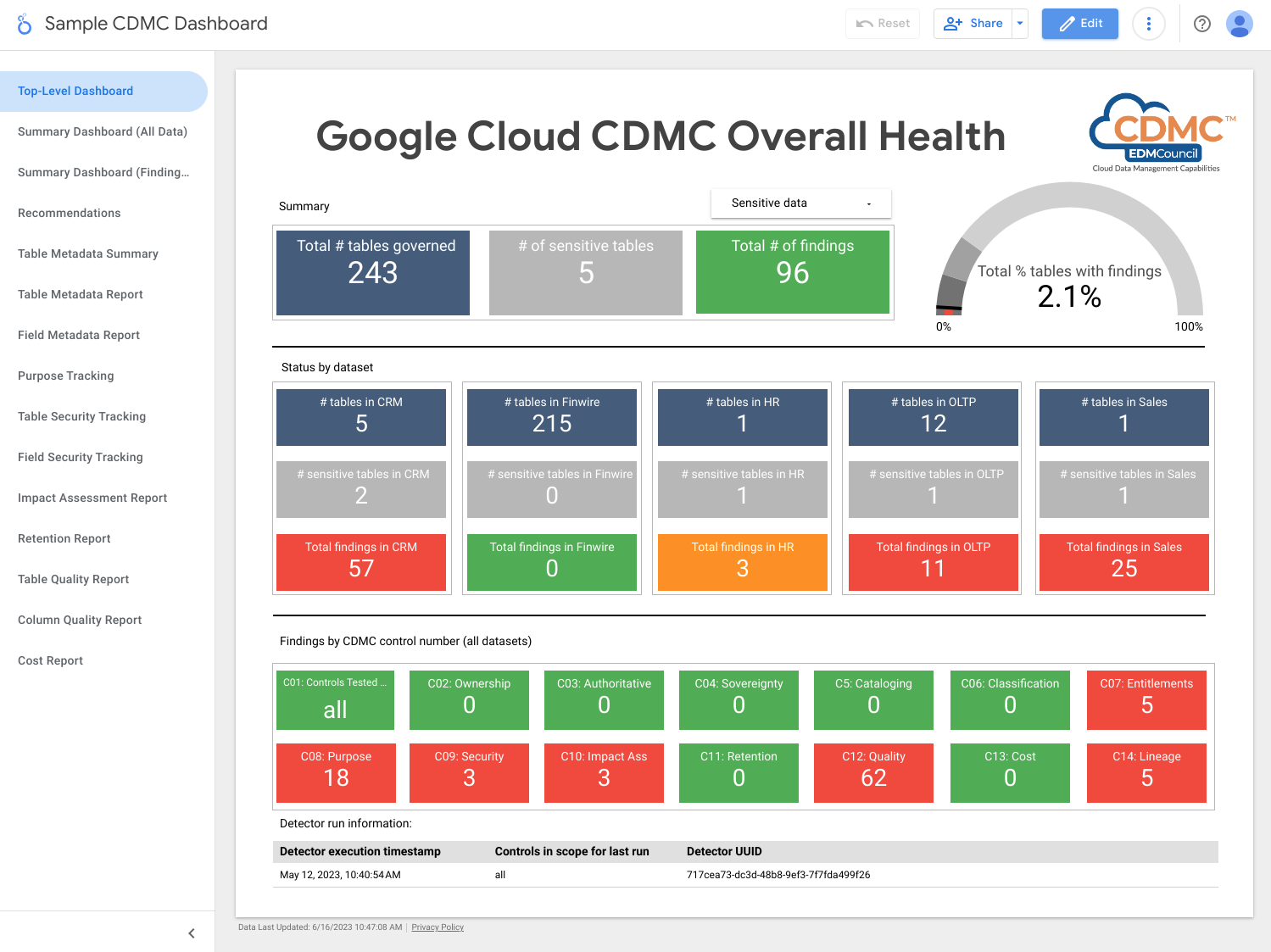
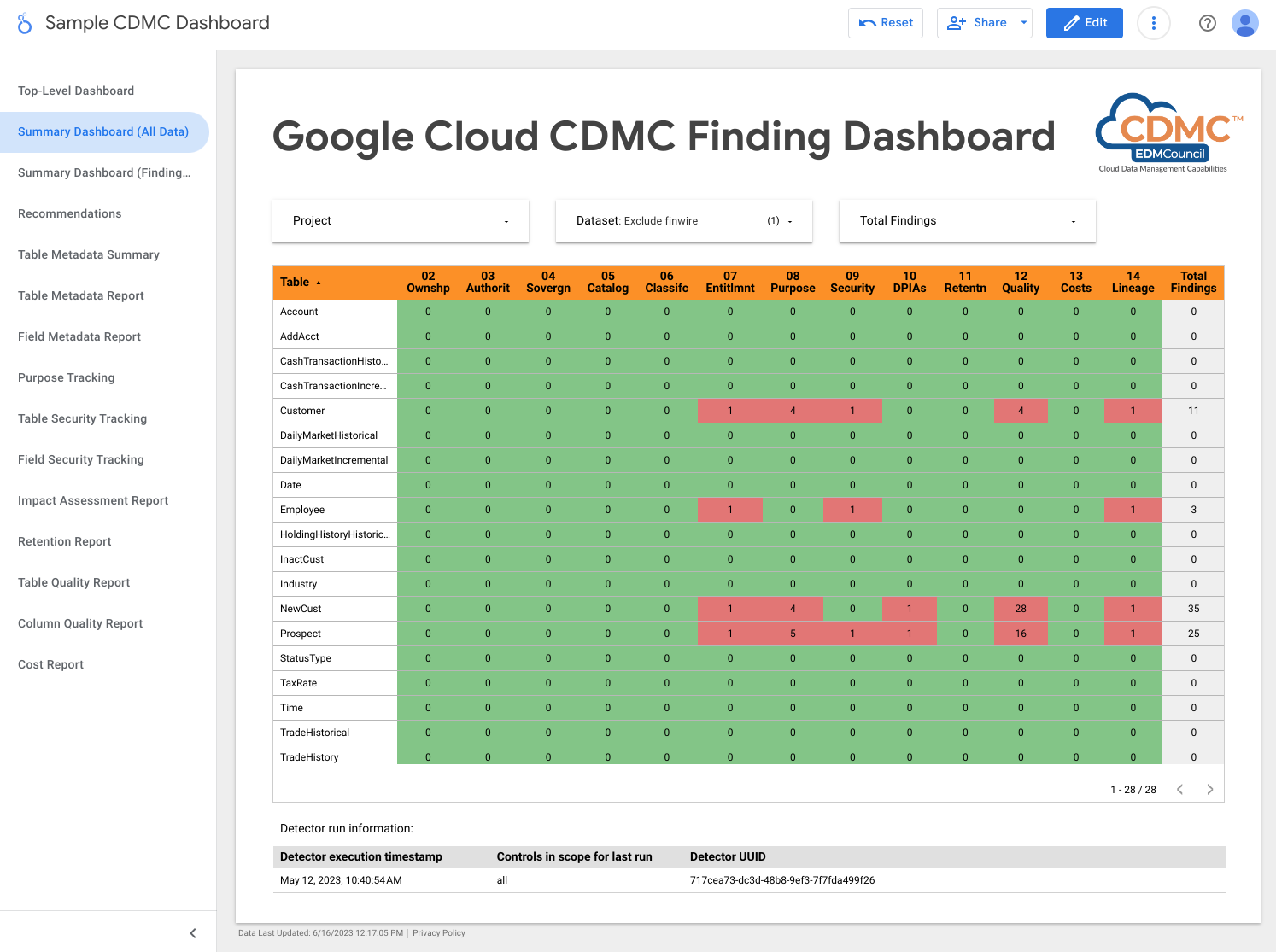
Lo screenshot seguente mostra una visualizzazione di esempio dei risultati per asset di dati.
2. La proprietà dei dati viene stabilita sia per i dati migrati sia per quelli generati nel cloud
Per soddisfare i requisiti di questo controllo, l'architettura esamina automaticamente i dati nel data warehouse BigQuery e aggiunge tag di classificazione dei dati che indicano che i proprietari sono identificati per tutti i dati sensibili.
Data Catalog gestisce due tipi di metadati: metadati tecnici e metadati aziendali. Per un determinato progetto, Data Catalog cataloga automaticamente set di dati, tabelle e viste BigQuery e compila i metadati tecnici. La sincronizzazione tra il catalogo e gli asset di dati viene mantenuta quasi in tempo reale.
L'architettura utilizza Tag Engine per aggiungere i seguenti tag di metadati aziendali a
un modello di tag CDMC controls in Data Catalog:
is_sensitive: indica se l'asset di dati contiene dati sensibili (vedi Controllo 6 per la classificazione dei dati)owner_name: il proprietario dei datiowner_email: l'indirizzo email del proprietario
I tag vengono compilati utilizzando i valori predefiniti archiviati in una tabella BigQuery di riferimento nel progetto di governance dei dati.
Per impostazione predefinita, l'architettura imposta i metadati di proprietà a livello di tabella, ma puoi modificarla in modo che i metadati vengano impostati a livello di colonna. Per maggiori informazioni, consulta la pagina Tag e modelli di tag di Data Catalog.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Due data warehouse BigQuery: uno archivia i dati riservati e l'altro archivia i valori predefiniti per la proprietà degli asset di dati.
- Data Catalog archivia i metadati di proprietà tramite tag e modelli di tag.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
Per rilevare problemi relativi a questo controllo, l'architettura verifica se ai dati sensibili è assegnato un tag con il nome del proprietario.
3. L'origine e il consumo dei dati sono regolati e supportati dall'automazione
Questo controllo richiede la classificazione degli asset di dati e un registro dei dati delle
origini autorevoli e dei distributori autorizzati. L'architettura utilizza
Data Catalog per aggiungere il tag is_authoritative al modello di tag CDMC
controls. Questo tag definisce se l'asset di dati è
autorevole.
Data Catalog cataloga set di dati, tabelle e viste BigQuery con metadati tecnici e aziendali. I metadati tecnici vengono
compilati automaticamente e includono l'URL della risorsa, ovvero la posizione del
punto di provisioning. I metadati aziendali sono definiti nel file di configurazione di Tag Engine e includono il tag is_authoritative.
Durante la successiva esecuzione pianificata, Tag Engine compila il tag is_authoritative
nel modello di tag CDMC controls con i valori predefiniti archiviati in una tabella di riferimento
in BigQuery.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Due data warehouse BigQuery: uno archivia i dati riservati e l'altro archivia i valori predefiniti per l'origine autorevole dell'asset di dati.
- Data Catalog memorizza i metadati dell'origine autorevole tramite tag.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
Per rilevare problemi relativi a questo controllo, l'architettura verifica se ai dati sensibili è assegnato il tag di origine autorevole.
4. La sovranità dei dati e il trasferimento transfrontaliero dei dati vengono gestiti
Questo controllo richiede che l'architettura esamini il registro dei dati per i requisiti di archiviazione specifici per la regione e applichi le regole di utilizzo. Un report descrive la posizione geografica degli asset di dati.
L'architettura utilizza Data Catalog per aggiungere il tag approved_storage_location al modello di tag CDMC controls. Questo tag
definisce la posizione geografica in cui è consentito archiviare l'asset di dati.
La posizione effettiva dei dati viene archiviata come metadati tecnici nei dettagli della tabella BigQuery. BigQuery non consente agli amministratori di modificare la posizione di un set di dati o di una tabella. Se gli amministratori vogliono modificare la posizione dei dati, devono copiare il set di dati.
Il
vincolo del servizio Organization Policy per le località delle risorse
definisce le Google Cloud regioni in cui puoi archiviare i dati. Per impostazione predefinita,
l'architettura imposta il vincolo sul progetto Dati riservati, ma puoi
impostarlo a livello di organizzazione o cartella, se preferisci. Tag
Engine replica le località consentite nel modello di tag
di Data Catalog e memorizza la località nel tag approved_storage_location. Se
attivi il livello Security Command Center Premium e qualcuno aggiorna il vincolo del servizio Organization Policy
per le località delle risorse, Security Command Center genera
risultati di vulnerabilità
per le risorse archiviate al di fuori della policy aggiornata.
Gestore contesto accesso definisce la posizione geografica in cui devono trovarsi gli utenti prima di poter accedere agli asset di dati. Utilizzando i livelli di accesso, puoi specificare le regioni da cui possono provenire le richieste. Poi aggiungi i criteri di accesso al perimetro Controlli di servizio VPC per il progetto di dati riservati.
Per monitorare lo spostamento dei dati, BigQuery mantiene una traccia di controllo completa per ogni job e query su ogni set di dati. La traccia di controllo è archiviata nella visualizzazione Information Schema Jobs di BigQuery.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Il servizio Organization Policy definisce e applica il vincolo delle località delle risorse.
- Gestore contesto accesso definisce le posizioni da cui gli utenti possono accedere ai dati.
- Due data warehouse BigQuery: uno archivia i dati riservati e l'altro ospita una funzione remota utilizzata per esaminare la policy sulla posizione.
- Data Catalog archivia le posizioni di archiviazione approvate come tag.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
- Cloud Logging scrive gli audit log.
- Security Command Center segnala eventuali risultati relativi alla posizione delle risorse o all'accesso ai dati.
Per rilevare problemi relativi a questo controllo, l'architettura include un risultato che indica se il tag delle posizioni approvate include la posizione dei dati sensibili.
5. I cataloghi di dati vengono implementati, utilizzati e sono interoperabili
Questo controllo richiede l'esistenza di un catalogo di dati e che l'architettura possa scansionare asset nuovi e aggiornati per aggiungere i metadati necessari.
Per soddisfare i requisiti di questo controllo, l'architettura utilizza Data Catalog. Data Catalog registra automaticamente gli assetGoogle Cloud , inclusi set di dati, tabelle e viste BigQuery. Quando crei una nuova tabella in BigQuery, Data Catalog registra automaticamente i metadati tecnici e lo schema della nuova tabella. Quando aggiorni una tabella in BigQuery, Data Catalog aggiorna le relative voci quasi istantaneamente.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Due data warehouse BigQuery: uno archivia i dati riservati e l'altro i dati non riservati.
- Data Catalog archivia i metadati tecnici per tabelle e campi.
Per impostazione predefinita, in questa architettura Data Catalog archivia i metadati tecnici di BigQuery. Se necessario, puoi integrare Data Catalog con altre origini dati.
6. Le classificazioni dei dati vengono definite e utilizzate
Questa valutazione richiede che i dati possano essere classificati in base alla loro sensibilità, ad esempio se sono PII, identificano i clienti o soddisfano un altro standard definito dalla tua organizzazione. Per soddisfare i requisiti di questo controllo, l'architettura crea un report delle risorse di dati e della loro sensibilità. Puoi utilizzare questo report per verificare se le impostazioni di sensibilità sono corrette. Inoltre, ogni nuova risorsa di dati o modifica a una risorsa di dati esistente comporta un aggiornamento del catalogo dei dati.
Le classificazioni vengono archiviate nel tag sensitive_category nel modello di tag Data Catalog a livello di tabella e colonna. Una
tabella di riferimento per la classificazione ti consente di classificare i tipi di informazioni
(infoType) di Sensitive Data Protection disponibili, con classifiche più alte per i contenuti più sensibili.
Per soddisfare i requisiti di questo controllo, l'architettura utilizza Sensitive Data Protection, Data Catalog e Tag Engine per aggiungere i seguenti tag alle colonne sensibili nelle tabelle BigQuery:
is_sensitive: indica se l'asset di dati contiene informazioni sensibilisensitive_category: la categoria dei dati; una delle seguenti:- Informazioni sensibili che consentono l'identificazione personale
- Informazioni che consentono l'identificazione personale
- Informazioni personali sensibili
- Informazioni personali
- Informazioni pubbliche
Puoi modificare le categorie di dati in base alle tue esigenze. Ad esempio, puoi aggiungere la classificazione Material Non-Public Information (MNPI).
Dopo che Sensitive Data Protection
controlla i dati,
Tag Engine legge le tabelle DLP results per asset per compilare i risultati. Se
una tabella contiene colonne con uno o più infoType sensibili, viene determinato l'infoType più importante e sia le colonne sensibili sia l'intera tabella vengono
taggate come categoria con il ranking più alto. Tag Engine assegna anche un
tag policy
corrispondente
alla colonna e assegna il tag booleano is_sensitive alla tabella.
Puoi utilizzare Cloud Scheduler per automatizzare l'ispezione di Sensitive Data Protection.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Quattro data warehouse BigQuery archiviano le seguenti
informazioni:
- Dati riservati
- Informazioni sui risultati di Sensitive Data Protection
- Dati di riferimento per la classificazione dei dati
- Informazioni sull'esportazione dei tag
- Data Catalog archivia i tag di classificazione.
- Sensitive Data Protection ispeziona gli asset alla ricerca di infoType sensibili.
- Compute Engine esegue lo script Inspect Datasets, che attiva un job Sensitive Data Protection per ogni set di dati BigQuery.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
Per rilevare problemi relativi a questo controllo, l'architettura include i seguenti risultati:
- Se ai dati sensibili è assegnato un tag di categoria sensibile.
- Indica se ai dati sensibili è assegnato un tag di tipo di sensibilità a livello di colonna.
7. I diritti sui dati vengono gestiti, applicati e monitorati
Per impostazione predefinita, solo ai creator e ai proprietari vengono assegnati diritti e accesso ai dati sensibili. Inoltre, questo controllo richiede che l'architettura tenga traccia di tutti gli accessi ai dati sensibili.
Per soddisfare i requisiti di questo controllo, l'architettura utilizza la tassonomia dei tag di criteri cdmc
sensitive data classification in BigQuery per
controllare l'accesso alle colonne che contengono dati riservati nelle
tabelle BigQuery. La tassonomia include i seguenti tag
criterio:
- Informazioni sensibili che consentono l'identificazione personale
- Informazioni che consentono l'identificazione personale
- Informazioni personali sensibili
- Informazioni personali
I tag di criteri ti consentono di controllare chi può visualizzare le colonne sensibili nelle tabelle BigQuery. L'architettura mappa questi tag di criterio in
classificazioni di sensibilità derivate dagli infoType di Sensitive Data Protection. Ad esempio, il tag sensitive_personal_identifiable_information policy
e la categoria sensibile corrispondono a infoType come AGE, DATE_OF_BIRTH,
PHONE_NUMBER e EMAIL_ADDRESS.
L'architettura utilizza Identity and Access Management (IAM) per gestire i gruppi, gli utenti e i service account che richiedono l'accesso ai dati. Le autorizzazioni IAM vengono concesse a una determinata risorsa per l'accesso a livello di tabella. Inoltre, l'accesso a livello di colonna basato sui tag criterio consente un accesso granulare agli asset di dati sensibili. Per impostazione predefinita, gli utenti non hanno accesso alle colonne che hanno tag di policy definiti.
Per contribuire a garantire che solo gli utenti autenticati possano accedere ai dati, Google Cloud utilizza Cloud Identity, che puoi federare con i tuoi provider di identità esistenti per autenticare gli utenti.
Questo controllo richiede inoltre che l'architettura verifichi regolarmente le risorse di dati per le quali non sono stati definiti diritti. Il rilevatore, gestito da Cloud Scheduler, verifica i seguenti scenari:
- Una risorsa dati include una categoria sensibile, ma non è presente un tag di criteri correlato.
- Una categoria non corrisponde al tag di criteri.
Quando si verificano questi scenari, il rilevatore genera risultati che vengono pubblicati
da Pub/Sub e poi vengono scritti nella tabella events in
BigQuery da Dataflow. Puoi quindi distribuire i
risultati allo strumento di correzione, come descritto in
1. Conformità ai controlli dei dati.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Un data warehouse BigQuery archivia i dati riservati e i binding dei tag di criteri per i controlli dell'accesso granulare.
- IAM gestisce l'accesso.
- Data Catalog memorizza i tag a livello di tabella e colonna per la categoria sensibile.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
Per rilevare problemi relativi a questo controllo, l'architettura verifica se i dati sensibili hanno untag di criteriy corrispondente.
8. L'accesso, l'utilizzo e i risultati etici dei dati vengono gestiti
Questo controllo richiede che l'architettura memorizzi gli accordi di condivisione dei dati sia del fornitore che dei consumatori di dati, inclusa una lista di scopi di consumo approvati. Lo scopo di utilizzo dei dati sensibili viene quindi
mappato ai diritti archiviati in BigQuery utilizzando
le etichette di query.
Quando un consumatore esegue query su dati sensibili in BigQuery, deve
specificare uno scopo valido che corrisponda al suo diritto (ad esempio, SET @@query_label = “use:3”;).
L'architettura utilizza Data Catalog per aggiungere i seguenti tag al
modello di tag CDMC controls. Questi tag rappresentano l'accordo di condivisione dei dati con il fornitore di dati:
approved_use: l'utilizzo o gli utenti approvati dell'asset di datisharing_scope_geography: l'elenco delle posizioni geografiche in cui può essere condiviso l'asset di datisharing_scope_legal_entity: l'elenco delle entità concordate che possono condividere l'asset di dati
Un data warehouse BigQuery separato include il
set di dati entitlement_management con le seguenti tabelle:
provider_agreement: l'accordo di condivisione dei dati con il fornitore di dati, inclusi la persona giuridica e l'ambito geografico concordati. Questi dati sono i valori predefiniti per i tagshared_scope_geographyesharing_scope_legal_entity.consumer_agreement: l'accordo di condivisione dei dati con il consumatore di dati, inclusi la persona giuridica e l'ambito geografico concordati. Ogni contratto è associato a un binding IAM per l'asset di dati.use_purpose: lo scopo del consumo, ad esempio la descrizione dell'utilizzo e le operazioni consentite per l'asset di datidata_asset: informazioni sulla risorsa di dati, ad esempio il nome della risorsa e i dettagli sul proprietario dei dati.
Per controllare gli accordi di condivisione dei dati, BigQuery mantiene una traccia di controllo completa per ogni job e query su ogni set di dati. La traccia di controllo viene memorizzata nella vista Information Schema Jobs di BigQuery. Dopo aver associato un'etichetta di query a una sessione ed eseguito query all'interno della sessione, puoi raccogliere i log di controllo per le query con quell'etichetta. Per maggiori informazioni, consulta il riferimento per il log di controllo di BigQuery.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Due data warehouse BigQuery: uno memorizza i dati riservati e l'altro memorizza i dati sui diritti, che includono gli accordi di condivisione dei dati tra provider e consumatore e lo scopo di utilizzo approvato.
- Data Catalog archivia le informazioni sull'accordo di condivisione dei dati del fornitore come tag.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
Per rilevare problemi relativi a questo controllo, l'architettura include i seguenti risultati:
- Se esiste una voce per un asset di dati nel set di dati
entitlement_management. - Se un'operazione viene eseguita su una tabella sensibile con un caso d'uso scaduto (ad esempio, è stata superata la data
valid_until_dateinconsumer_agreement table). - Se un'operazione viene eseguita su una tabella sensibile con una chiave etichetta errata.
- Indica se un'operazione viene eseguita su una tabella sensibile con un valore di etichetta del caso d'uso vuoto o non approvato.
- Indica se una tabella sensibile viene interrogata con un metodo di operazione non approvato
(ad esempio
SELECToINSERT). - Se lo scopo registrato specificato dal consumatore durante la query dei dati sensibili corrisponde all'accordo di condivisione dei dati.
9. I dati sono protetti e i controlli sono documentati
Questo controllo richiede l'implementazione della crittografia e della deidentificazione dei dati per contribuire a proteggere i dati sensibili e fornire un record di questi controlli.
Questa architettura si basa sulla sicurezza predefinita di Google, che include la crittografia at-rest. Inoltre, l'architettura ti consente di gestire le tue chiavi utilizzando le chiavi di crittografia gestite dal cliente (CMEK). Cloud KMS ti consente di criptare i tuoi dati con chiavi di crittografia con supporto software o moduli di sicurezza hardware (HSM) convalidati FIPS 140-2 di livello 3.
L'architettura utilizza la mascheratura dinamica dei dati a livello di colonna configurata tramite tag dei criteri e archivia i dati riservati all'interno di un perimetro separato dei Controlli di servizio VPC. Puoi anche aggiungere la deidentificazione a livello di applicazione, che puoi implementare on-premise o come parte della pipeline di importazione dati.
Per impostazione predefinita, l'architettura implementa la crittografia CMEK con HSM, ma supporta anche Cloud External Key Manager (Cloud EKM).
La tabella seguente descrive la policy di sicurezza di esempio implementata dall'architettura per la regione us-central1. Puoi adattare le norme per soddisfare i tuoi requisiti, ad esempio aggiungendo norme diverse per regioni diverse.
| Sensibilità dei dati | Metodo di crittografia predefinito | Altri metodi di crittografia consentiti | Metodo di anonimizzazione predefinito | Altri metodi di anonimizzazione consentiti |
|---|---|---|---|---|
| Informazioni pubbliche | Crittografia predefinita | Qualsiasi | Nessuno | Qualsiasi |
| Informazioni sensibili che consentono l'identificazione personale | CMEK con HSM | EKM | Annulla | Hash SHA-256 o valore di mascheramento predefinito |
| Informazioni che consentono l'identificazione personale | CMEK con HSM | EKM | Hash SHA-256 | Annulla o Valore di mascheramento predefinito |
| Informazioni personali sensibili | CMEK con HSM | EKM | Valore di mascheramento predefinito | Hash SHA-256 o annullamento |
| Informazioni personali | CMEK con HSM | EKM | Valore di mascheramento predefinito | Hash SHA-256 o annullamento |
L'architettura utilizza Data Catalog per aggiungere il tag encryption_method
al modello di tag CDMC controls a livello di tabella. encryption_method
definisce il metodo di crittografia utilizzato dall'asset di dati.
Inoltre, l'architettura crea un tag security policy template per
identificare il metodo di deidentificazione applicato a un determinato campo. L'architettura utilizza platform_deid_method, che viene applicato utilizzando la maschera dinamica dei dati. Puoi aggiungere app_deid_method e compilarlo utilizzando le pipeline di importazione dati Dataflow e Sensitive Data Protection incluse nel blueprint del data warehouse protetto.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Due istanze facoltative di Dataflow, una esegue l'anonimizzazione a livello di applicazione e l'altra esegue la reidentificazione.
- Tre data warehouse BigQuery: uno archivia i dati riservati, uno archivia i dati non riservati e il terzo archivia la policy di sicurezza.
- Data Catalog archivia i modelli di tag di crittografia e anonimizzazione.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Risultati pubblicati di Pub/Sub.
Per rilevare problemi relativi a questo controllo, l'architettura include i seguenti risultati:
- Il valore del tag del metodo di crittografia non corrisponde ai metodi di crittografia consentiti per la sensibilità e la posizione specificate.
- Una tabella contiene colonne sensibili, ma il tag del modello di criteri di sicurezza contiene un metodo di anonimizzazione a livello di piattaforma non valido.
- Una tabella contiene colonne sensibili, ma il tag Modello di policy di sicurezza non è presente.
10. È definito e operativo un framework per la privacy dei dati
Questo controllo richiede che l'architettura esamini il catalogo dei dati e le classificazioni per determinare se devi creare un report di valutazione di impatto sulla protezione dei dati (DPIA) o un report di valutazione di impatto sulla privacy (PIA). Le valutazioni della privacy variano in modo significativo a seconda delle aree geografiche e delle autorità di regolamentazione. Per determinare se è necessaria una valutazione d'impatto, l'architettura deve considerare la residenza dei dati e quella del soggetto interessato.
L'architettura utilizza Data Catalog per aggiungere i seguenti tag al modello di tag Impact assessment:
subject_locations: la posizione dei soggetti a cui si riferiscono i dati in questo asset.is_dpia: indica se per questo asset è stata completata una valutazione di impatto sulla privacy dei dati (DPIA).is_pia: indica se è stata completata un'analisi dell'impatto sulla privacy (PIA) per questa risorsa.impact_assessment_reports: link esterno alla posizione in cui è archiviato il report di valutazione dell'impatto.most_recent_assessment: la data della valutazione dell'impatto più recente.oldest_assessment: la data della prima valutazione dell'impatto.
Tag Engine aggiunge questi tag a ogni asset di dati sensibili, come definito dal controllo 6. Il rilevatore convalida questi tag in base a una tabella delle norme in BigQuery, che include combinazioni valide di residenza dei dati, posizione del soggetto, sensibilità dei dati (ad esempio, se si tratta di PII) e il tipo di valutazione dell'impatto (PIA o DPIA) richiesto.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Quattro data warehouse BigQuery archiviano le seguenti
informazioni:
- Dati riservati
- Dati non riservati
- Norme sulla valutazione dell'impatto e timestamp dei diritti
- Esportazioni di tag utilizzate per la dashboard
- Data Catalog archivia i dettagli della valutazione dell'impatto nei tag all'interno dei modelli di tag.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
Per rilevare problemi relativi a questo controllo, l'architettura include i seguenti risultati:
- Esistono dati sensibili senza un modello di valutazione dell'impatto.
- Esistono dati sensibili senza un collegamento a un report DPIA o PIA.
- I tag non soddisfano i requisiti riportati nella tabella delle norme.
- La valutazione dell'impatto è precedente al diritto approvato più di recente per l'asset di dati nella tabella del contratto con i consumatori.
11. Il ciclo di vita dei dati è pianificato e gestito
Questo controllo richiede la possibilità di esaminare tutti gli asset di dati per determinare che esiste un criterio del ciclo di vita dei dati e che viene rispettato.
L'architettura utilizza Data Catalog per aggiungere i seguenti tag al modello di tag CDMC controls:
retention_period: il tempo, in giorni, per conservare la tabellaexpiration_action: indica se archiviare o eliminare la tabella al termine del periodo di conservazione
Per impostazione predefinita, l'architettura utilizza il seguente periodo di conservazione e azione di scadenza:
| Categoria di dati | Periodo di conservazione, in giorni | Azione di scadenza |
|---|---|---|
| Informazioni sensibili che consentono l'identificazione personale | 60 | Elimina definitivamente |
| Informazioni che consentono l'identificazione personale | 90 | Archivia |
| Informazioni personali sensibili | 180 | Archivia |
| Informazioni personali | 180 | Archivia |
Record Manager, un asset open source per BigQuery, automatizza l'eliminazione e l'archiviazione delle tabelle BigQuery in base ai valori dei tag precedenti e a un file di configurazione. La procedura di eliminazione imposta una data di scadenza per una tabella e crea una tabella snapshot con un tempo di scadenza definito nella configurazione di Record Manager. Per impostazione predefinita, il tempo di scadenza è di 30 giorni. Durante il periodo di eliminazione temporanea, puoi recuperare la tabella. La procedura di archiviazione crea una tabella esterna per ogni tabella BigQuery che supera il periodo di conservazione. La tabella è memorizzata in Cloud Storage in formato Parquet e viene eseguito l'upgrade a una tabella BigLake, che consente di taggare il file esterno con i metadati in Data Catalog.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Due data warehouse BigQuery: uno archivia i dati riservati e l'altro archivia le norme di conservazione dei dati.
- Due istanze Cloud Storage, una fornisce l'archiviazione e l'altra memorizza i record.
- Data Catalog archivia il periodo di conservazione e l'azione nei modelli di tag e nei tag.
- Due istanze Cloud Run, una esegue Record Manager e l'altra esegue il deployment dei rilevatori.
- Tre istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Un'altra istanza esegue Record Manager, che automatizza l'eliminazione e l'archiviazione delle tabelle BigQuery.
- Pub/Sub pubblica i risultati.
Per rilevare problemi relativi a questo controllo, l'architettura include i seguenti risultati:
- Per gli asset sensibili, assicurati che il metodo di conservazione sia in linea con le norme per la posizione dell'asset.
- Per gli asset sensibili, assicurati che il periodo di conservazione sia in linea con le norme per la posizione dell'asset.
12. La qualità dei dati è gestita
Questo controllo richiede la possibilità di misurare la qualità dei dati in base alla profilazione dei dati o alle metriche definite dall'utente.
L'architettura include la possibilità di definire regole di qualità dei dati per un valore individuale o aggregato e assegnare soglie a una colonna specifica della tabella. Include modelli di tag per la correttezza e la completezza. Data Catalog aggiunge i seguenti tag a ogni modello di tag:
column_name: il nome della colonna a cui si applica la metricametric: il nome della metrica o della regola di qualitàrows_validated: il numero di righe convalidatosuccess_percentage: la percentuale di valori che soddisfano questa metricaacceptable_threshold: la soglia accettabile per questa metricameets_threshold: indica se il punteggio di qualità (il valoresuccess_percentage) soddisfa la soglia accettabilemost_recent_run: l'ultima volta che la metrica o la regola di qualità è stata eseguita
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Tre data warehouse BigQuery: uno archivia i dati sensibili, uno archivia i dati non sensibili e il terzo archivia le metriche delle regole di qualità.
- Data Catalog archivia i risultati della qualità dei dati nei modelli di tag e nei tag.
- Cloud Scheduler definisce quando viene eseguito Cloud Data Quality Engine.
- Tre istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- La terza istanza esegue il motore Cloud Data Quality.
- Cloud Data Quality Engine definisce le regole per la qualità dei dati e pianifica i controlli della qualità dei dati per tabelle e colonne.
- Pub/Sub pubblica i risultati.
Una dashboard di Looker Studio mostra i report sulla qualità dei dati sia a livello di tabella che di colonna.
Per rilevare problemi relativi a questo controllo, l'architettura include i seguenti risultati:
- I dati sono sensibili, ma non vengono applicati modelli di tag di qualità dei dati (correttezza e completezza).
- I dati sono sensibili, ma il tag di qualità dei dati non è applicato alla colonna sensibile.
- I dati sono sensibili, ma i risultati sulla qualità dei dati non rientrano nella soglia impostata nella regola.
- I dati non sono sensibili e i risultati della qualità dei dati non rientrano nella soglia impostata dalla regola.
In alternativa a Cloud Data Quality Engine, puoi configurare le attività di qualità dei dati di Dataplex Universal Catalog.
13. I principi di gestione dei costi sono stabiliti e applicati
Questo controllo richiede la possibilità di ispezionare gli asset di dati per confermare l'utilizzo dei costi, in base ai requisiti delle norme e all'architettura dei dati. Le metriche dei costi devono essere complete e non limitate solo all'utilizzo e allo spostamento dello spazio di archiviazione.
L'architettura utilizza Data Catalog per aggiungere i seguenti tag al modello di tag
cost_metrics:
total_query_bytes_billed: il numero totale di byte di query fatturati per questa risorsa di dati dall'inizio del mese corrente.total_storage_bytes_billed: il numero totale di byte di spazio di archiviazione fatturati per questo asset di dati dall'inizio del mese corrente.total_bytes_transferred: la somma dei byte trasferiti tra regioni in questo asset di dati.estimated_query_cost: costo stimato della query, in dollari statunitensi, per la risorsa di dati per il mese corrente.estimated_storage_cost: costo di archiviazione stimato, in dollari statunitensi, per l'asset di dati per il mese corrente.estimated_egress_cost: uscita stimata in dollari statunitensi per il mese corrente in cui l'asset di dati è stato utilizzato come tabella di destinazione.
L'architettura esporta le informazioni sui prezzi da fatturazione Cloud in una tabella BigQuery denominata cloud_pricing_export.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Fatturazione Cloud fornisce i dati di fatturazione.
- Data Catalog archivia le informazioni sui costi nei modelli di tag e nei tag.
- BigQuery archivia le informazioni sui prezzi esportate e le informazioni storiche sui job di query tramite la visualizzazione INFORMATION_SCHEMA integrata.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
Per rilevare i problemi relativi a questo controllo, l'architettura verifica se esistono asset di dati sensibili senza metriche di costo associate.
14. La provenienza e la derivazione dei dati sono comprese
Questo controllo richiede la possibilità di ispezionare la tracciabilità dell'asset di dati dalla sua origine e qualsiasi modifica alla derivazione dell'asset di dati.
Per mantenere le informazioni sulla provenienza e sulla derivazione dei dati, l'architettura utilizza le funzionalità integrate di Data Lineage in Data Catalog. Inoltre, gli script di importazione dati definiscono l'origine finale e la aggiungono come nodo aggiuntivo al grafico della derivazione dei dati.
Per soddisfare i requisiti di questo controllo, l'architettura utilizza
Data Catalog per aggiungere il tag ultimate_source al modello di tag CDMC
controls. Il tag ultimate_source definisce l'origine di questa risorsa dati.
Il seguente diagramma mostra i servizi a cui si applica questo controllo.

Per soddisfare i requisiti di questo controllo, l'architettura utilizza i seguenti servizi:
- Due data warehouse BigQuery: uno archivia i dati riservati e l'altro archivia i dati di origine finali.
- Data Catalog archivia l'origine definitiva nei modelli di tag e nei tag.
- Gli script di importazione dei dati caricano i dati da Cloud Storage, definiscono l'origine finale e la aggiungono al grafico della lineage dei dati.
- Due istanze Cloud Run, come segue:
- Un'istanza esegue Report Engine, che verifica se i tag sono applicati e pubblica i risultati.
- Un'altra istanza esegue Tag Engine, che tagga i dati nel data warehouse protetto.
- Pub/Sub pubblica i risultati.
Per rilevare problemi relativi a questo controllo, l'architettura include i seguenti controlli:
- I dati sensibili vengono identificati senza tag di origine finale.
- Il grafico della derivazione non viene compilato per gli asset di dati sensibili.
Riferimento al tag
Questa sezione descrive i modelli di tag e i tag utilizzati da questa architettura per soddisfare i requisiti dei controlli chiave CDMC.
Modelli di tag di controllo CDMC a livello di tabella
La tabella seguente elenca i tag che fanno parte del modello di tag di controllo CDMC e che vengono applicati alle tabelle.
| Tag | ID tag | Controllo delle chiavi applicabile |
|---|---|---|
| Località di archiviazione approvata | approved_storage_location |
4 |
| Utilizzo approvato | approved_use |
8 |
| Email del proprietario dei dati | data_owner_email |
2 |
| Nome del proprietario dei dati | data_owner_name |
2 |
| Metodo di crittografia | encryption_method |
9 |
| Azione di scadenza | expiration_action |
11 |
| È autorevole | is_authoritative |
3 |
| È sensibile | is_sensitive |
6 |
| Categoria sensibile | sensitive_category |
6 |
| Regione dell'ambito di condivisione | sharing_scope_geography |
8 |
| Persona giuridica dell'ambito di condivisione | sharing_scope_legal_entity |
8 |
| Periodo di conservazione | retention_period |
11 |
| Ultimate Source | ultimate_source |
14 |
Modello di tag Valutazione dell'impatto
La tabella seguente elenca i tag che fanno parte del modello di tag Valutazione dell'impatto e che vengono applicati alle tabelle.
| Tag | ID tag | Controllo delle chiavi applicabile |
|---|---|---|
| Posizioni del soggetto | subject_locations |
10 |
| Valutazione dell'impatto della DPIA | is_dpia |
10 |
| Valutazione dell'impatto della PIA | is_pia |
10 |
| Report sulla valutazione dell'impatto | impact_assessment_reports |
10 |
| Valutazione dell'impatto più recente | most_recent_assessment |
10 |
| Valutazione dell'impatto meno recente | oldest_assessment |
10 |
Modello di tag Metriche relative ai costi
La tabella seguente elenca i tag che fanno parte del modello di tag Metriche dei costi e che vengono applicati alle tabelle.
| Tag | Scheda ID | Controllo delle chiavi applicabile |
|---|---|---|
| Costo stimato della query | estimated_query_cost |
13 |
| Costo di archiviazione stimato | estimated_storage_cost |
13 |
| Costo stimato dell'uscita | estimated_egress_cost |
13 |
| Byte totali delle query fatturati | total_query_bytes_billed |
13 |
| Byte di archiviazione totali fatturati | total_storage_bytes_billed |
13 |
| Byte totali trasferiti | total_bytes_transferred |
13 |
Modello di tag Sensibilità dei dati
La tabella seguente elenca i tag che fanno parte del modello di tag Sensibilità dei dati e che vengono applicati ai campi.
| Tag | ID tag | Controllo delle chiavi applicabile |
|---|---|---|
| Campo sensibile | sensitive_field |
6 |
| Tipo di sensibilità | sensitive_category |
6 |
Modello di tag della policy di sicurezza
La tabella seguente elenca i tag che fanno parte del modello di tag della norma sulla sicurezza e che vengono applicati ai campi.
| Tag | ID tag | Controllo delle chiavi applicabile |
|---|---|---|
| Metodo di anonimizzazione dell'applicazione | app_deid_method |
9 |
| Metodo di anonimizzazione della piattaforma | platform_deid_method |
9 |
Modelli di tag di qualità dei dati
La tabella seguente elenca i tag che fanno parte dei modelli di tag Qualità dei dati di completezza e correttezza e che vengono applicati ai campi.
| Tag | ID tag | Controllo delle chiavi applicabile |
|---|---|---|
| Soglia accettabile | acceptable_threshold |
12 |
| Nome colonna | column_name |
12 |
| Raggiunge la soglia | meets_threshold |
12 |
| Metrica | metric |
12 |
| Esecuzione più recente | most_recent_run |
12 |
| Righe convalidate | rows_validated |
12 |
| Percentuale di successo | success_percentage |
12 |
Tag di policy CDMC a livello di campo
La seguente tabella elenca i tag di policy che fanno parte della tassonomia tag di criteri di classificazione dei dati sensibili del CDMC e che vengono applicati ai campi. Questi tag dei criteri limitano l'accesso a livello di campo e consentono la deidentificazione dei dati a livello di piattaforma.
| Classificazione dati | Nome tag | Controllo delle chiavi applicabile |
|---|---|---|
| Informazioni che consentono l'identificazione personale | personal_identifiable_information |
7 |
| Informazioni personali | personal_information |
7 |
| Informazioni sensibili che consentono l'identificazione personale | sensitive_personal_identifiable_information |
7 |
| Informazioni personali sensibili | sensitive_personal_data |
7 |
Metadati tecnici precompilati
La tabella seguente elenca i metadati tecnici sincronizzati per impostazione predefinita in Data Catalog per tutti gli asset di dati BigQuery.
| Metadati | Controllo delle chiavi applicabile |
|---|---|
| Tipo di asset | — |
| Ora creazione | — |
| Data di scadenza | 11 |
| Località | 4 |
| URL risorsa | 3 |
Passaggi successivi
- Scopri di più su CDMC.
- Scopri di più sui controlli di sicurezza utilizzati dal progetto base per il data warehouse protetto.
- Scopri Data Catalog.
- Scopri di più su Dataplex Universal Catalog.
- Scopri di più sul motore di tagging.
- Implementa questa soluzione utilizzando l'Google Cloud architettura di riferimento CDMC in GitHub.