k-匿名性是数据集的一个属性,指示其记录的可重标识性。如果数据集中每个人的准标识符与该数据集中至少 k - 1 个其他人相同,则该数据集具有 k-匿名性。
您可以根据数据集的一个或多个列或字段计算 k-匿名性值。本主题演示了如何使用敏感数据保护功能计算数据集的 k-匿名性值。k如需从总体上详细了解 k-匿名性或风险分析,请参阅风险分析概念主题,然后再继续。
准备工作
在继续操作之前,请确保您已完成以下步骤:
- 登录您的 Google 账号。
- 在 Google Cloud 控制台的“项目选择器”页面上,选择或创建一个 Google Cloud 项目。 转到项目选择器
- 确保您的 Google Cloud 项目已启用结算功能。 了解如何确认您的项目已启用结算功能。
- 启用敏感数据保护。 启用敏感数据保护
- 选择要分析的 BigQuery 数据集。敏感数据保护通过扫描 BigQuery 表来计算 k-匿名性指标k。
- 在数据集中确定一个标识符(如果适用)和至少一个准标识符。如需了解详情,请参阅风险分析术语和技术。
计算 k-匿名性
每当运行风险分析作业时,Sensitive Data Protection 都会执行风险分析。您必须先创建作业,方法是使用 Google Cloud 控制台、发送 DLP API 请求或使用 Sensitive Data Protection 客户端库。
控制台
在 Google Cloud 控制台中,前往创建风险分析页面。
在选择输入数据部分中,通过输入包含表的项目的 ID、表的数据集 ID 以及表的名称来指定要扫描的 BigQuery 表。
在要计算的隐私权指标下,选择 k-匿名性。
在作业 ID 部分中,您可以视需要为作业提供自定义标识符,然后选择 Sensitive Data Protection 将在其中处理您的数据的资源位置。完成操作后,请点击继续。
在定义字段部分中,您可为 k-匿名性风险作业指定标识符和准标识符。敏感数据保护功能会访问您在上一步中指定的 BigQuery 表的元数据,并尝试填充字段列表。
- 选择相应的复选框,将字段指定为标识符 (ID) 或准标识符 (QI)。您必须选择 0 个或 1 个标识符以及至少 1 个准标识符。
- 如果敏感数据保护功能无法填充字段,请点击输入字段名称以手动输入一个或多个字段,并将每个字段设置为标识符或准标识符。完成操作后,请点击继续。
在添加操作部分中,您可以添加可选操作,以便在风险作业完成时执行。可用的选项包括:
- 保存到 BigQuery:将风险分析扫描的结果保存到 BigQuery 表中。
发布到 Pub/Sub:将通知发布到 Pub/Sub 主题。
通过电子邮件发送通知:向您发送电子邮件,其中包含结果。完成操作后,请点击创建。
k-匿名性风险分析作业会立即启动。
C#
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
using Google.Api.Gax.ResourceNames;
using Google.Cloud.Dlp.V2;
using Google.Cloud.PubSub.V1;
using Newtonsoft.Json;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
using static Google.Cloud.Dlp.V2.Action.Types;
using static Google.Cloud.Dlp.V2.PrivacyMetric.Types;
public class RiskAnalysisCreateKAnonymity
{
public static AnalyzeDataSourceRiskDetails.Types.KAnonymityResult KAnonymity(
string callingProjectId,
string tableProjectId,
string datasetId,
string tableId,
string topicId,
string subscriptionId,
IEnumerable<FieldId> quasiIds)
{
var dlp = DlpServiceClient.Create();
// Construct + submit the job
var KAnonymityConfig = new KAnonymityConfig
{
QuasiIds = { quasiIds }
};
var config = new RiskAnalysisJobConfig
{
PrivacyMetric = new PrivacyMetric
{
KAnonymityConfig = KAnonymityConfig
},
SourceTable = new BigQueryTable
{
ProjectId = tableProjectId,
DatasetId = datasetId,
TableId = tableId
},
Actions =
{
new Google.Cloud.Dlp.V2.Action
{
PubSub = new PublishToPubSub
{
Topic = $"projects/{callingProjectId}/topics/{topicId}"
}
}
}
};
var submittedJob = dlp.CreateDlpJob(
new CreateDlpJobRequest
{
ParentAsProjectName = new ProjectName(callingProjectId),
RiskJob = config
});
// Listen to pub/sub for the job
var subscriptionName = new SubscriptionName(callingProjectId, subscriptionId);
var subscriber = SubscriberClient.CreateAsync(
subscriptionName).Result;
// SimpleSubscriber runs your message handle function on multiple
// threads to maximize throughput.
var done = new ManualResetEventSlim(false);
subscriber.StartAsync((PubsubMessage message, CancellationToken cancel) =>
{
if (message.Attributes["DlpJobName"] == submittedJob.Name)
{
Thread.Sleep(500); // Wait for DLP API results to become consistent
done.Set();
return Task.FromResult(SubscriberClient.Reply.Ack);
}
else
{
return Task.FromResult(SubscriberClient.Reply.Nack);
}
});
done.Wait(TimeSpan.FromMinutes(10)); // 10 minute timeout; may not work for large jobs
subscriber.StopAsync(CancellationToken.None).Wait();
// Process results
var resultJob = dlp.GetDlpJob(new GetDlpJobRequest
{
DlpJobName = DlpJobName.Parse(submittedJob.Name)
});
var result = resultJob.RiskDetails.KAnonymityResult;
for (var bucketIdx = 0; bucketIdx < result.EquivalenceClassHistogramBuckets.Count; bucketIdx++)
{
var bucket = result.EquivalenceClassHistogramBuckets[bucketIdx];
Console.WriteLine($"Bucket {bucketIdx}");
Console.WriteLine($" Bucket size range: [{bucket.EquivalenceClassSizeLowerBound}, {bucket.EquivalenceClassSizeUpperBound}].");
Console.WriteLine($" {bucket.BucketSize} unique value(s) total.");
foreach (var bucketValue in bucket.BucketValues)
{
// 'UnpackValue(x)' is a prettier version of 'x.toString()'
Console.WriteLine($" Quasi-ID values: [{String.Join(',', bucketValue.QuasiIdsValues.Select(x => UnpackValue(x)))}]");
Console.WriteLine($" Class size: {bucketValue.EquivalenceClassSize}");
}
}
return result;
}
public static string UnpackValue(Value protoValue)
{
var jsonValue = JsonConvert.DeserializeObject<Dictionary<string, object>>(protoValue.ToString());
return jsonValue.Values.ElementAt(0).ToString();
}
}
Go
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
import (
"context"
"fmt"
"io"
"strings"
"time"
dlp "cloud.google.com/go/dlp/apiv2"
"cloud.google.com/go/dlp/apiv2/dlppb"
"cloud.google.com/go/pubsub"
)
// riskKAnonymity computes the risk of the given columns using K Anonymity.
func riskKAnonymity(w io.Writer, projectID, dataProject, pubSubTopic, pubSubSub, datasetID, tableID string, columnNames ...string) error {
// projectID := "my-project-id"
// dataProject := "bigquery-public-data"
// pubSubTopic := "dlp-risk-sample-topic"
// pubSubSub := "dlp-risk-sample-sub"
// datasetID := "nhtsa_traffic_fatalities"
// tableID := "accident_2015"
// columnNames := "state_number" "county"
ctx := context.Background()
client, err := dlp.NewClient(ctx)
if err != nil {
return fmt.Errorf("dlp.NewClient: %w", err)
}
// Create a PubSub Client used to listen for when the inspect job finishes.
pubsubClient, err := pubsub.NewClient(ctx, projectID)
if err != nil {
return err
}
defer pubsubClient.Close()
// Create a PubSub subscription we can use to listen for messages.
// Create the Topic if it doesn't exist.
t := pubsubClient.Topic(pubSubTopic)
topicExists, err := t.Exists(ctx)
if err != nil {
return err
}
if !topicExists {
if t, err = pubsubClient.CreateTopic(ctx, pubSubTopic); err != nil {
return err
}
}
// Create the Subscription if it doesn't exist.
s := pubsubClient.Subscription(pubSubSub)
subExists, err := s.Exists(ctx)
if err != nil {
return err
}
if !subExists {
if s, err = pubsubClient.CreateSubscription(ctx, pubSubSub, pubsub.SubscriptionConfig{Topic: t}); err != nil {
return err
}
}
// topic is the PubSub topic string where messages should be sent.
topic := "projects/" + projectID + "/topics/" + pubSubTopic
// Build the QuasiID slice.
var q []*dlppb.FieldId
for _, c := range columnNames {
q = append(q, &dlppb.FieldId{Name: c})
}
// Create a configured request.
req := &dlppb.CreateDlpJobRequest{
Parent: fmt.Sprintf("projects/%s/locations/global", projectID),
Job: &dlppb.CreateDlpJobRequest_RiskJob{
RiskJob: &dlppb.RiskAnalysisJobConfig{
// PrivacyMetric configures what to compute.
PrivacyMetric: &dlppb.PrivacyMetric{
Type: &dlppb.PrivacyMetric_KAnonymityConfig_{
KAnonymityConfig: &dlppb.PrivacyMetric_KAnonymityConfig{
QuasiIds: q,
},
},
},
// SourceTable describes where to find the data.
SourceTable: &dlppb.BigQueryTable{
ProjectId: dataProject,
DatasetId: datasetID,
TableId: tableID,
},
// Send a message to PubSub using Actions.
Actions: []*dlppb.Action{
{
Action: &dlppb.Action_PubSub{
PubSub: &dlppb.Action_PublishToPubSub{
Topic: topic,
},
},
},
},
},
},
}
// Create the risk job.
j, err := client.CreateDlpJob(ctx, req)
if err != nil {
return fmt.Errorf("CreateDlpJob: %w", err)
}
fmt.Fprintf(w, "Created job: %v\n", j.GetName())
// Wait for the risk job to finish by waiting for a PubSub message.
// This only waits for 10 minutes. For long jobs, consider using a truly
// asynchronous execution model such as Cloud Functions.
ctx, cancel := context.WithTimeout(ctx, 10*time.Minute)
defer cancel()
err = s.Receive(ctx, func(ctx context.Context, msg *pubsub.Message) {
// If this is the wrong job, do not process the result.
if msg.Attributes["DlpJobName"] != j.GetName() {
msg.Nack()
return
}
msg.Ack()
time.Sleep(500 * time.Millisecond)
j, err := client.GetDlpJob(ctx, &dlppb.GetDlpJobRequest{
Name: j.GetName(),
})
if err != nil {
fmt.Fprintf(w, "GetDlpJob: %v", err)
return
}
h := j.GetRiskDetails().GetKAnonymityResult().GetEquivalenceClassHistogramBuckets()
for i, b := range h {
fmt.Fprintf(w, "Histogram bucket %v\n", i)
fmt.Fprintf(w, " Size range: [%v,%v]\n", b.GetEquivalenceClassSizeLowerBound(), b.GetEquivalenceClassSizeUpperBound())
fmt.Fprintf(w, " %v unique values total\n", b.GetBucketSize())
for _, v := range b.GetBucketValues() {
var qvs []string
for _, qv := range v.GetQuasiIdsValues() {
qvs = append(qvs, qv.String())
}
fmt.Fprintf(w, " QuasiID values: %s\n", strings.Join(qvs, ", "))
fmt.Fprintf(w, " Class size: %v\n", v.GetEquivalenceClassSize())
}
}
// Stop listening for more messages.
cancel()
})
if err != nil {
return fmt.Errorf("Receive: %w", err)
}
return nil
}
Java
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
import com.google.api.core.SettableApiFuture;
import com.google.cloud.dlp.v2.DlpServiceClient;
import com.google.cloud.pubsub.v1.AckReplyConsumer;
import com.google.cloud.pubsub.v1.MessageReceiver;
import com.google.cloud.pubsub.v1.Subscriber;
import com.google.privacy.dlp.v2.Action;
import com.google.privacy.dlp.v2.Action.PublishToPubSub;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityEquivalenceClass;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityHistogramBucket;
import com.google.privacy.dlp.v2.BigQueryTable;
import com.google.privacy.dlp.v2.CreateDlpJobRequest;
import com.google.privacy.dlp.v2.DlpJob;
import com.google.privacy.dlp.v2.FieldId;
import com.google.privacy.dlp.v2.GetDlpJobRequest;
import com.google.privacy.dlp.v2.LocationName;
import com.google.privacy.dlp.v2.PrivacyMetric;
import com.google.privacy.dlp.v2.PrivacyMetric.KAnonymityConfig;
import com.google.privacy.dlp.v2.RiskAnalysisJobConfig;
import com.google.privacy.dlp.v2.Value;
import com.google.pubsub.v1.ProjectSubscriptionName;
import com.google.pubsub.v1.ProjectTopicName;
import com.google.pubsub.v1.PubsubMessage;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
import java.util.stream.Collectors;
@SuppressWarnings("checkstyle:AbbreviationAsWordInName")
class RiskAnalysisKAnonymity {
public static void main(String[] args) throws Exception {
// TODO(developer): Replace these variables before running the sample.
String projectId = "your-project-id";
String datasetId = "your-bigquery-dataset-id";
String tableId = "your-bigquery-table-id";
String topicId = "pub-sub-topic";
String subscriptionId = "pub-sub-subscription";
calculateKAnonymity(projectId, datasetId, tableId, topicId, subscriptionId);
}
public static void calculateKAnonymity(
String projectId, String datasetId, String tableId, String topicId, String subscriptionId)
throws ExecutionException, InterruptedException, IOException {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests. After completing all of your requests, call
// the "close" method on the client to safely clean up any remaining background resources.
try (DlpServiceClient dlpServiceClient = DlpServiceClient.create()) {
// Specify the BigQuery table to analyze
BigQueryTable bigQueryTable =
BigQueryTable.newBuilder()
.setProjectId(projectId)
.setDatasetId(datasetId)
.setTableId(tableId)
.build();
// These values represent the column names of quasi-identifiers to analyze
List<String> quasiIds = Arrays.asList("Age", "Mystery");
// Configure the privacy metric for the job
List<FieldId> quasiIdFields =
quasiIds.stream()
.map(columnName -> FieldId.newBuilder().setName(columnName).build())
.collect(Collectors.toList());
KAnonymityConfig kanonymityConfig =
KAnonymityConfig.newBuilder().addAllQuasiIds(quasiIdFields).build();
PrivacyMetric privacyMetric =
PrivacyMetric.newBuilder().setKAnonymityConfig(kanonymityConfig).build();
// Create action to publish job status notifications over Google Cloud Pub/Sub
ProjectTopicName topicName = ProjectTopicName.of(projectId, topicId);
PublishToPubSub publishToPubSub =
PublishToPubSub.newBuilder().setTopic(topicName.toString()).build();
Action action = Action.newBuilder().setPubSub(publishToPubSub).build();
// Configure the risk analysis job to perform
RiskAnalysisJobConfig riskAnalysisJobConfig =
RiskAnalysisJobConfig.newBuilder()
.setSourceTable(bigQueryTable)
.setPrivacyMetric(privacyMetric)
.addActions(action)
.build();
// Build the request to be sent by the client
CreateDlpJobRequest createDlpJobRequest =
CreateDlpJobRequest.newBuilder()
.setParent(LocationName.of(projectId, "global").toString())
.setRiskJob(riskAnalysisJobConfig)
.build();
// Send the request to the API using the client
DlpJob dlpJob = dlpServiceClient.createDlpJob(createDlpJobRequest);
// Set up a Pub/Sub subscriber to listen on the job completion status
final SettableApiFuture<Boolean> done = SettableApiFuture.create();
ProjectSubscriptionName subscriptionName =
ProjectSubscriptionName.of(projectId, subscriptionId);
MessageReceiver messageHandler =
(PubsubMessage pubsubMessage, AckReplyConsumer ackReplyConsumer) -> {
handleMessage(dlpJob, done, pubsubMessage, ackReplyConsumer);
};
Subscriber subscriber = Subscriber.newBuilder(subscriptionName, messageHandler).build();
subscriber.startAsync();
// Wait for job completion semi-synchronously
// For long jobs, consider using a truly asynchronous execution model such as Cloud Functions
try {
done.get(15, TimeUnit.MINUTES);
} catch (TimeoutException e) {
System.out.println("Job was not completed after 15 minutes.");
return;
} finally {
subscriber.stopAsync();
subscriber.awaitTerminated();
}
// Build a request to get the completed job
GetDlpJobRequest getDlpJobRequest =
GetDlpJobRequest.newBuilder().setName(dlpJob.getName()).build();
// Retrieve completed job status
DlpJob completedJob = dlpServiceClient.getDlpJob(getDlpJobRequest);
System.out.println("Job status: " + completedJob.getState());
System.out.println("Job name: " + dlpJob.getName());
// Get the result and parse through and process the information
KAnonymityResult kanonymityResult = completedJob.getRiskDetails().getKAnonymityResult();
List<KAnonymityHistogramBucket> histogramBucketList =
kanonymityResult.getEquivalenceClassHistogramBucketsList();
for (KAnonymityHistogramBucket result : histogramBucketList) {
System.out.printf(
"Bucket size range: [%d, %d]\n",
result.getEquivalenceClassSizeLowerBound(), result.getEquivalenceClassSizeUpperBound());
for (KAnonymityEquivalenceClass bucket : result.getBucketValuesList()) {
List<String> quasiIdValues =
bucket.getQuasiIdsValuesList().stream()
.map(Value::toString)
.collect(Collectors.toList());
System.out.println("\tQuasi-ID values: " + String.join(", ", quasiIdValues));
System.out.println("\tClass size: " + bucket.getEquivalenceClassSize());
}
}
}
}
// handleMessage injects the job and settableFuture into the message reciever interface
private static void handleMessage(
DlpJob job,
SettableApiFuture<Boolean> done,
PubsubMessage pubsubMessage,
AckReplyConsumer ackReplyConsumer) {
String messageAttribute = pubsubMessage.getAttributesMap().get("DlpJobName");
if (job.getName().equals(messageAttribute)) {
done.set(true);
ackReplyConsumer.ack();
} else {
ackReplyConsumer.nack();
}
}
}Node.js
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
// Import the Google Cloud client libraries
const DLP = require('@google-cloud/dlp');
const {PubSub} = require('@google-cloud/pubsub');
// Instantiates clients
const dlp = new DLP.DlpServiceClient();
const pubsub = new PubSub();
// The project ID to run the API call under
// const projectId = 'my-project';
// The project ID the table is stored under
// This may or (for public datasets) may not equal the calling project ID
// const tableProjectId = 'my-project';
// The ID of the dataset to inspect, e.g. 'my_dataset'
// const datasetId = 'my_dataset';
// The ID of the table to inspect, e.g. 'my_table'
// const tableId = 'my_table';
// The name of the Pub/Sub topic to notify once the job completes
// TODO(developer): create a Pub/Sub topic to use for this
// const topicId = 'MY-PUBSUB-TOPIC'
// The name of the Pub/Sub subscription to use when listening for job
// completion notifications
// TODO(developer): create a Pub/Sub subscription to use for this
// const subscriptionId = 'MY-PUBSUB-SUBSCRIPTION'
// A set of columns that form a composite key ('quasi-identifiers')
// const quasiIds = [{ name: 'age' }, { name: 'city' }];
async function kAnonymityAnalysis() {
const sourceTable = {
projectId: tableProjectId,
datasetId: datasetId,
tableId: tableId,
};
// Construct request for creating a risk analysis job
const request = {
parent: `projects/${projectId}/locations/global`,
riskJob: {
privacyMetric: {
kAnonymityConfig: {
quasiIds: quasiIds,
},
},
sourceTable: sourceTable,
actions: [
{
pubSub: {
topic: `projects/${projectId}/topics/${topicId}`,
},
},
],
},
};
// Create helper function for unpacking values
const getValue = obj => obj[Object.keys(obj)[0]];
// Run risk analysis job
const [topicResponse] = await pubsub.topic(topicId).get();
const subscription = await topicResponse.subscription(subscriptionId);
const [jobsResponse] = await dlp.createDlpJob(request);
const jobName = jobsResponse.name;
console.log(`Job created. Job name: ${jobName}`);
// Watch the Pub/Sub topic until the DLP job finishes
await new Promise((resolve, reject) => {
const messageHandler = message => {
if (message.attributes && message.attributes.DlpJobName === jobName) {
message.ack();
subscription.removeListener('message', messageHandler);
subscription.removeListener('error', errorHandler);
resolve(jobName);
} else {
message.nack();
}
};
const errorHandler = err => {
subscription.removeListener('message', messageHandler);
subscription.removeListener('error', errorHandler);
reject(err);
};
subscription.on('message', messageHandler);
subscription.on('error', errorHandler);
});
setTimeout(() => {
console.log(' Waiting for DLP job to fully complete');
}, 500);
const [job] = await dlp.getDlpJob({name: jobName});
const histogramBuckets =
job.riskDetails.kAnonymityResult.equivalenceClassHistogramBuckets;
histogramBuckets.forEach((histogramBucket, histogramBucketIdx) => {
console.log(`Bucket ${histogramBucketIdx}:`);
console.log(
` Bucket size range: [${histogramBucket.equivalenceClassSizeLowerBound}, ${histogramBucket.equivalenceClassSizeUpperBound}]`
);
histogramBucket.bucketValues.forEach(valueBucket => {
const quasiIdValues = valueBucket.quasiIdsValues
.map(getValue)
.join(', ');
console.log(` Quasi-ID values: {${quasiIdValues}}`);
console.log(` Class size: ${valueBucket.equivalenceClassSize}`);
});
});
}
await kAnonymityAnalysis();PHP
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
use Google\Cloud\Dlp\V2\RiskAnalysisJobConfig;
use Google\Cloud\Dlp\V2\BigQueryTable;
use Google\Cloud\Dlp\V2\DlpJob\JobState;
use Google\Cloud\Dlp\V2\Action;
use Google\Cloud\Dlp\V2\Action\PublishToPubSub;
use Google\Cloud\Dlp\V2\Client\DlpServiceClient;
use Google\Cloud\Dlp\V2\CreateDlpJobRequest;
use Google\Cloud\Dlp\V2\FieldId;
use Google\Cloud\Dlp\V2\GetDlpJobRequest;
use Google\Cloud\Dlp\V2\PrivacyMetric;
use Google\Cloud\Dlp\V2\PrivacyMetric\KAnonymityConfig;
use Google\Cloud\PubSub\PubSubClient;
/**
* Computes the k-anonymity of a column set in a Google BigQuery table.
*
* @param string $callingProjectId The project ID to run the API call under
* @param string $dataProjectId The project ID containing the target Datastore
* @param string $topicId The name of the Pub/Sub topic to notify once the job completes
* @param string $subscriptionId The name of the Pub/Sub subscription to use when listening for job
* @param string $datasetId The ID of the dataset to inspect
* @param string $tableId The ID of the table to inspect
* @param string[] $quasiIdNames Array columns that form a composite key (quasi-identifiers)
*/
function k_anonymity(
string $callingProjectId,
string $dataProjectId,
string $topicId,
string $subscriptionId,
string $datasetId,
string $tableId,
array $quasiIdNames
): void {
// Instantiate a client.
$dlp = new DlpServiceClient();
$pubsub = new PubSubClient();
$topic = $pubsub->topic($topicId);
// Construct risk analysis config
$quasiIds = array_map(
function ($id) {
return (new FieldId())->setName($id);
},
$quasiIdNames
);
$statsConfig = (new KAnonymityConfig())
->setQuasiIds($quasiIds);
$privacyMetric = (new PrivacyMetric())
->setKAnonymityConfig($statsConfig);
// Construct items to be analyzed
$bigqueryTable = (new BigQueryTable())
->setProjectId($dataProjectId)
->setDatasetId($datasetId)
->setTableId($tableId);
// Construct the action to run when job completes
$pubSubAction = (new PublishToPubSub())
->setTopic($topic->name());
$action = (new Action())
->setPubSub($pubSubAction);
// Construct risk analysis job config to run
$riskJob = (new RiskAnalysisJobConfig())
->setPrivacyMetric($privacyMetric)
->setSourceTable($bigqueryTable)
->setActions([$action]);
// Listen for job notifications via an existing topic/subscription.
$subscription = $topic->subscription($subscriptionId);
// Submit request
$parent = "projects/$callingProjectId/locations/global";
$createDlpJobRequest = (new CreateDlpJobRequest())
->setParent($parent)
->setRiskJob($riskJob);
$job = $dlp->createDlpJob($createDlpJobRequest);
// Poll Pub/Sub using exponential backoff until job finishes
// Consider using an asynchronous execution model such as Cloud Functions
$attempt = 1;
$startTime = time();
do {
foreach ($subscription->pull() as $message) {
if (
isset($message->attributes()['DlpJobName']) &&
$message->attributes()['DlpJobName'] === $job->getName()
) {
$subscription->acknowledge($message);
// Get the updated job. Loop to avoid race condition with DLP API.
do {
$getDlpJobRequest = (new GetDlpJobRequest())
->setName($job->getName());
$job = $dlp->getDlpJob($getDlpJobRequest);
} while ($job->getState() == JobState::RUNNING);
break 2; // break from parent do while
}
}
print('Waiting for job to complete' . PHP_EOL);
// Exponential backoff with max delay of 60 seconds
sleep(min(60, pow(2, ++$attempt)));
} while (time() - $startTime < 600); // 10 minute timeout
// Print finding counts
printf('Job %s status: %s' . PHP_EOL, $job->getName(), JobState::name($job->getState()));
switch ($job->getState()) {
case JobState::DONE:
$histBuckets = $job->getRiskDetails()->getKAnonymityResult()->getEquivalenceClassHistogramBuckets();
foreach ($histBuckets as $bucketIndex => $histBucket) {
// Print bucket stats
printf('Bucket %s:' . PHP_EOL, $bucketIndex);
printf(
' Bucket size range: [%s, %s]' . PHP_EOL,
$histBucket->getEquivalenceClassSizeLowerBound(),
$histBucket->getEquivalenceClassSizeUpperBound()
);
// Print bucket values
foreach ($histBucket->getBucketValues() as $percent => $valueBucket) {
// Pretty-print quasi-ID values
print(' Quasi-ID values:' . PHP_EOL);
foreach ($valueBucket->getQuasiIdsValues() as $index => $value) {
print(' ' . $value->serializeToJsonString() . PHP_EOL);
}
printf(
' Class size: %s' . PHP_EOL,
$valueBucket->getEquivalenceClassSize()
);
}
}
break;
case JobState::FAILED:
printf('Job %s had errors:' . PHP_EOL, $job->getName());
$errors = $job->getErrors();
foreach ($errors as $error) {
var_dump($error->getDetails());
}
break;
case JobState::PENDING:
print('Job has not completed. Consider a longer timeout or an asynchronous execution model' . PHP_EOL);
break;
default:
print('Unexpected job state. Most likely, the job is either running or has not yet started.');
}
}Python
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
import concurrent.futures
from typing import List
import google.cloud.dlp
from google.cloud.dlp_v2 import types
import google.cloud.pubsub
def k_anonymity_analysis(
project: str,
table_project_id: str,
dataset_id: str,
table_id: str,
topic_id: str,
subscription_id: str,
quasi_ids: List[str],
timeout: int = 300,
) -> None:
"""Uses the Data Loss Prevention API to compute the k-anonymity of a
column set in a Google BigQuery table.
Args:
project: The Google Cloud project id to use as a parent resource.
table_project_id: The Google Cloud project id where the BigQuery table
is stored.
dataset_id: The id of the dataset to inspect.
table_id: The id of the table to inspect.
topic_id: The name of the Pub/Sub topic to notify once the job
completes.
subscription_id: The name of the Pub/Sub subscription to use when
listening for job completion notifications.
quasi_ids: A set of columns that form a composite key.
timeout: The number of seconds to wait for a response from the API.
Returns:
None; the response from the API is printed to the terminal.
"""
# Create helper function for unpacking values
def get_values(obj: types.Value) -> int:
return int(obj.integer_value)
# Instantiate a client.
dlp = google.cloud.dlp_v2.DlpServiceClient()
# Convert the project id into a full resource id.
topic = google.cloud.pubsub.PublisherClient.topic_path(project, topic_id)
parent = f"projects/{project}/locations/global"
# Location info of the BigQuery table.
source_table = {
"project_id": table_project_id,
"dataset_id": dataset_id,
"table_id": table_id,
}
# Convert quasi id list to Protobuf type
def map_fields(field: str) -> dict:
return {"name": field}
quasi_ids = map(map_fields, quasi_ids)
# Tell the API where to send a notification when the job is complete.
actions = [{"pub_sub": {"topic": topic}}]
# Configure risk analysis job
# Give the name of the numeric column to compute risk metrics for
risk_job = {
"privacy_metric": {"k_anonymity_config": {"quasi_ids": quasi_ids}},
"source_table": source_table,
"actions": actions,
}
# Call API to start risk analysis job
operation = dlp.create_dlp_job(request={"parent": parent, "risk_job": risk_job})
def callback(message: google.cloud.pubsub_v1.subscriber.message.Message) -> None:
if message.attributes["DlpJobName"] == operation.name:
# This is the message we're looking for, so acknowledge it.
message.ack()
# Now that the job is done, fetch the results and print them.
job = dlp.get_dlp_job(request={"name": operation.name})
print(f"Job name: {job.name}")
histogram_buckets = (
job.risk_details.k_anonymity_result.equivalence_class_histogram_buckets
)
# Print bucket stats
for i, bucket in enumerate(histogram_buckets):
print(f"Bucket {i}:")
if bucket.equivalence_class_size_lower_bound:
print(
" Bucket size range: [{}, {}]".format(
bucket.equivalence_class_size_lower_bound,
bucket.equivalence_class_size_upper_bound,
)
)
for value_bucket in bucket.bucket_values:
print(
" Quasi-ID values: {}".format(
map(get_values, value_bucket.quasi_ids_values)
)
)
print(
" Class size: {}".format(
value_bucket.equivalence_class_size
)
)
subscription.set_result(None)
else:
# This is not the message we're looking for.
message.drop()
# Create a Pub/Sub client and find the subscription. The subscription is
# expected to already be listening to the topic.
subscriber = google.cloud.pubsub.SubscriberClient()
subscription_path = subscriber.subscription_path(project, subscription_id)
subscription = subscriber.subscribe(subscription_path, callback)
try:
subscription.result(timeout=timeout)
except concurrent.futures.TimeoutError:
print(
"No event received before the timeout. Please verify that the "
"subscription provided is subscribed to the topic provided."
)
subscription.close()
REST
如需运行新的风险分析作业以计算 k-匿名性,请向 projects.dlpJobs 资源发送一个请求,其中 PROJECT_ID 表示项目标识符:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
该请求包含一个由以下项组成的 RiskAnalysisJobConfig 对象:
PrivacyMetric对象。您可以在此处添加KAnonymityConfig对象来表明您正在计算 k-匿名性。BigQueryTable对象。通过包括以下所有项指定要扫描的 BigQuery 表格:projectId:表格所属项目的 ID。datasetId:表格的数据集 ID。tableId:表格的名称。
由一个或多个
Action对象组成的对象集,这些对象表示在作业完成时要按给定顺序运行的操作。每个Action对象都可以包含以下操作之一:SaveFindings对象:将风险分析扫描的结果保存到 BigQuery 表格中。JobNotificationEmails对象:向您发送电子邮件,其中包含结果。
在
KAnonymityConfig对象中,指定以下内容:quasiIds[]:要扫描的一个或多个准标识符(FieldId对象),用于计算 k-匿名性。当您指定多个准标识符时,它们会被视为单个复合键。结构体和重复数据类型不受支持,但只要嵌套字段本身不是结构体或嵌套在重复字段中,嵌套字段就受支持。entityId:可选的标识符值;如果设置此项,则指示在计算 k-匿名性时应将与每个不同entityId对应的所有行组合在一起。通常,entityId将是表示唯一用户身份的列,例如客户 ID 或用户 ID。 如果entityId出现在多个具有不同准标识符值的行中,这些行将连接形成一个多集,以用作该实体的准标识符。如需详细了解实体 ID,请参阅风险分析概念主题中的实体 ID 与 k-匿名性计算。
向 DLP API 发送请求后,它将立即启动风险分析作业。
列出已完成的风险分析作业
您可以查看当前项目中已运行的风险分析作业的列表。
控制台
如需在 Google Cloud 控制台中列出正在运行和先前运行的风险分析作业,请执行以下操作:
在 Google Cloud 控制台中,打开“敏感数据保护”。
点击页面顶部的作业和作业触发器标签页。
点击风险作业标签页。
系统会显示风险列表。
协议
如需列出正在运行和先前运行的风险分析作业,请向 projects.dlpJobs 资源发送 GET 请求。添加作业类型过滤条件 (?type=RISK_ANALYSIS_JOB) 可将响应范围缩小至风险分析作业。
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
您收到的响应将以 JSON 表示法包含所有当前和以前的风险分析作业。
查看 k-匿名性作业结果
Google Cloud 控制台中的敏感数据保护功能包含已完成的 k-匿名性作业的内置可视化功能k。按照上一部分中的说明进行操作后,请在风险分析作业列表中,选择您要查看其结果的作业。假设作业已成功运行,风险分析详情页面顶部将如下所示:
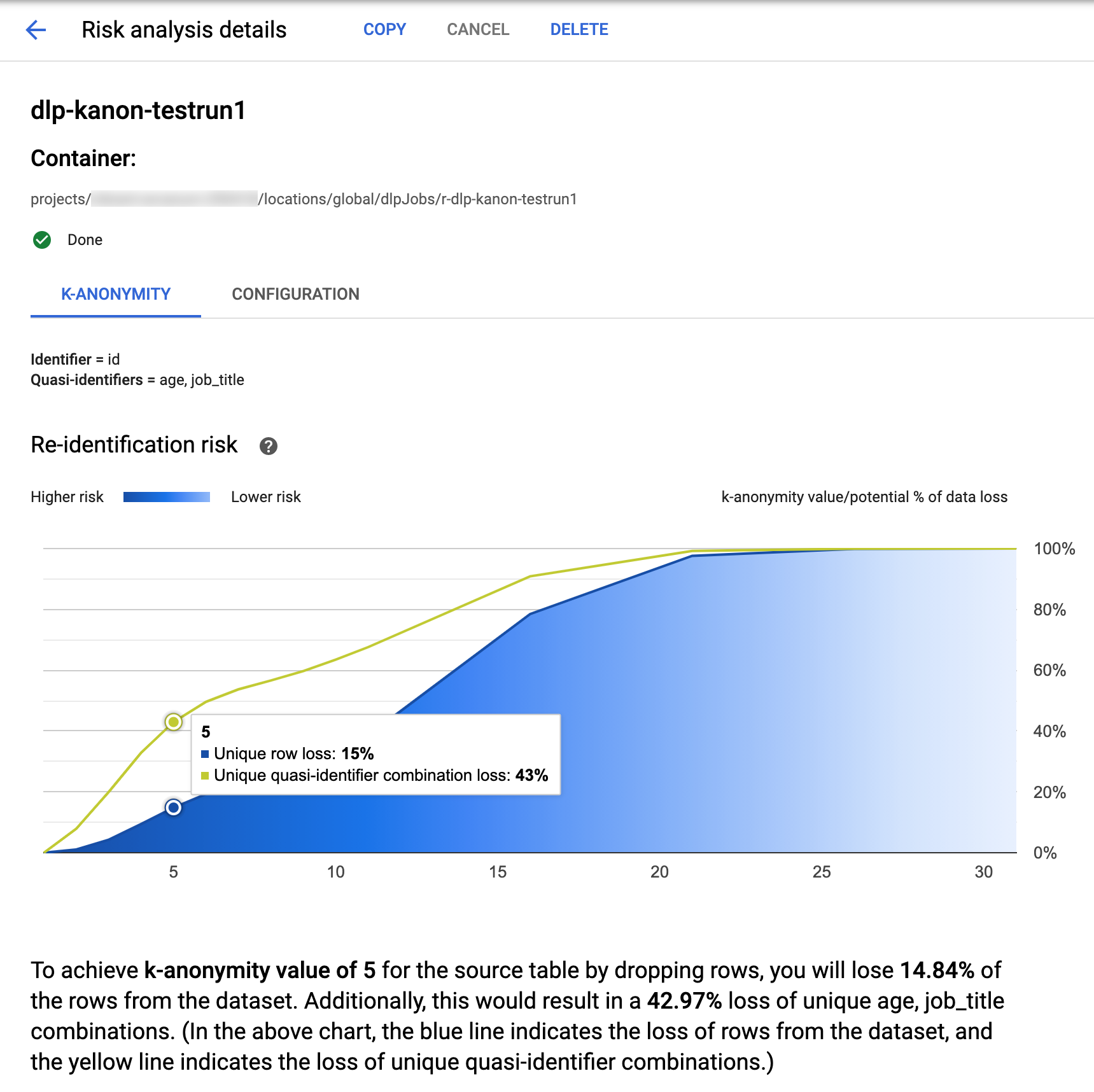
该页面顶部列出了有关 k-匿名性风险作业的信息,包括其作业 ID 以及其资源位置(在容器下)。
如需查看 k-匿名性计算的结果,请点击 K-匿名性标签页。如需查看风险分析作业的配置,请点击配置标签页。
K-匿名性标签页首先列出实体 ID(如果有)以及用于计算 k-匿名性的准标识符。
风险图表
重标识风险图表在 y 轴上绘制唯一行和唯一准标识符组合的潜在数据泄露百分比,以在 x 轴上实现 k-匿名性值。。图表的颜色还表示潜在风险程度。较深的蓝色表示风险较高,而较浅的蓝色表示风险较低。
k-匿名性值越大,表示重标识的风险越小。但是,要实现较大的 k-匿名性值,您需要移除总行数的较大百分比以及较大的唯一准标识符组合,这可能会降低数据的效用。如需查看某个 k-匿名性值的特定潜在泄露百分比值,请将光标悬停在图表上。如屏幕截图所示,图表上会显示一个提示。
如需查看特定 k-匿名性值的更多详情,请点击相应的数据点。图表下方会显示详细的说明,并且页面下方显示了示例数据表。
风险示例数据表
风险作业结果页面的第二个组成部分是示例数据表。它会显示给定目标 k-匿名性值的准标识符组合。
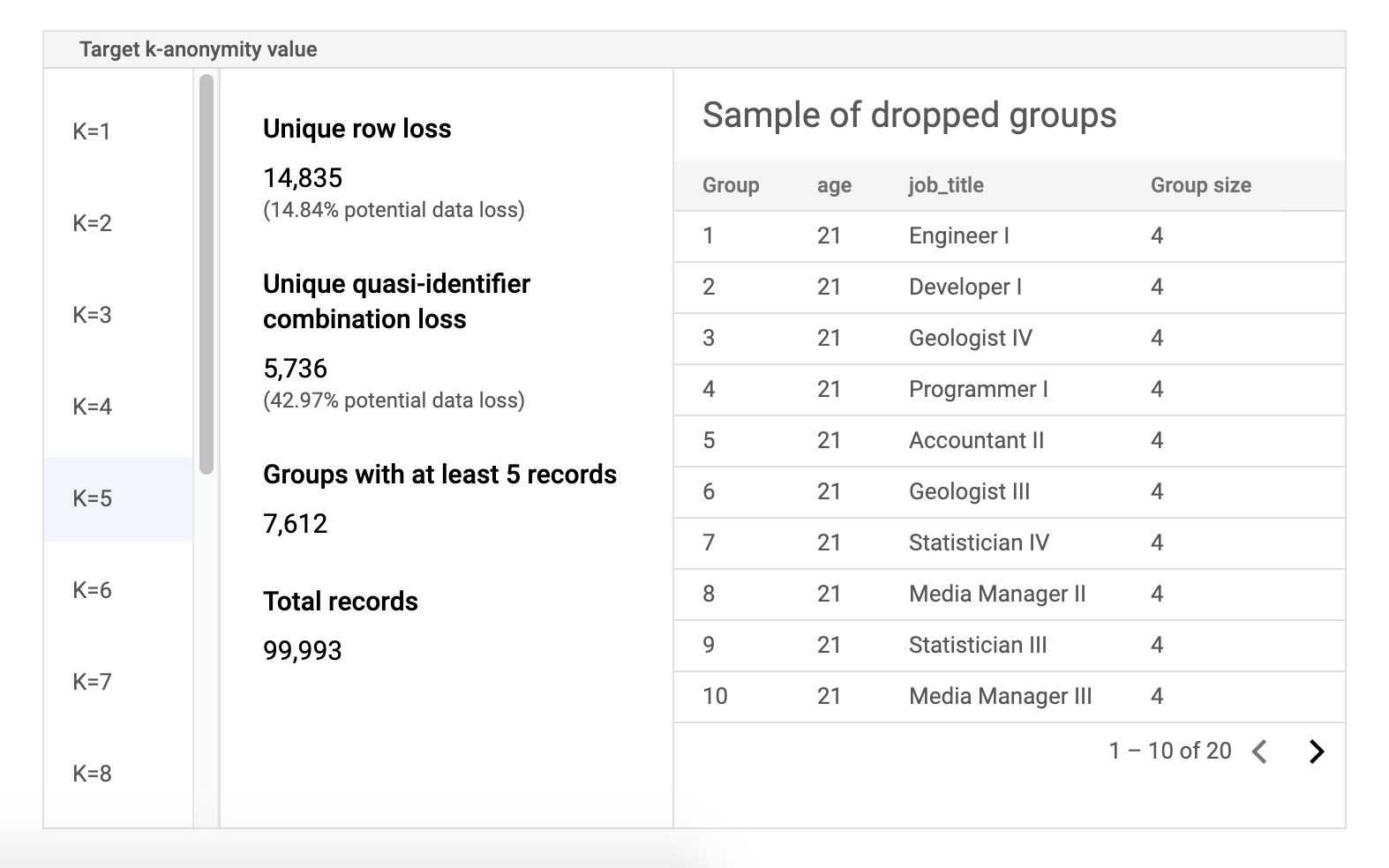
表的第一列列出了 k-匿名性值。点击 k-匿名性值以查看为达到该值而需要丢弃的相应样本数据。
第二列会显示不重复的行和准标识符组合的各自潜在的数据泄露,以及具有至少 k 条记录的群组数和记录总数。
最后一列会显示共用一个准标识符组合的群组的一个示例,以及该组合存在的记录数量。
使用 REST 检索作业详情
如需使用 REST API 检索 k-匿名性风险分析作业,请将以下 GET 请求发送到 projects.dlpJobs 资源。将 PROJECT_ID 替换为您的项目 ID,并将 JOB_ID 替换为您要获取其结果的作业的标识符。作业 ID 在启动作业时返回,也可通过列出所有作业来检索。
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
该请求会返回包含作业实例的 JSON 对象。分析的结果位于 AnalyzeDataSourceRiskDetails 对象的 "riskDetails" 键中。如需了解详情,请参阅 DlpJob 资源的 API 参考文档。
代码示例:使用实体 ID 计算 k-匿名性
此示例创建了一个风险分析作业,用于计算实体 ID 的 k-匿名性。
如需详细了解实体 ID,请参阅实体 ID 与 k-匿名性计算。k
C#
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
using System;
using System.Collections.Generic;
using System.Linq;
using Google.Api.Gax.ResourceNames;
using Google.Cloud.Dlp.V2;
using Newtonsoft.Json;
public class CalculateKAnonymityOnDataset
{
public static DlpJob CalculateKAnonymitty(
string projectId,
string datasetId,
string sourceTableId,
string outputTableId)
{
// Construct the dlp client.
var dlp = DlpServiceClient.Create();
// Construct the k-anonymity config by setting the EntityId as user_id column
// and two quasi-identifiers columns.
var kAnonymity = new PrivacyMetric.Types.KAnonymityConfig
{
EntityId = new EntityId
{
Field = new FieldId { Name = "Name" }
},
QuasiIds =
{
new FieldId { Name = "Age" },
new FieldId { Name = "Mystery" }
}
};
// Construct risk analysis job config by providing the source table, privacy metric
// and action to save the findings to a BigQuery table.
var riskJob = new RiskAnalysisJobConfig
{
SourceTable = new BigQueryTable
{
ProjectId = projectId,
DatasetId = datasetId,
TableId = sourceTableId,
},
PrivacyMetric = new PrivacyMetric
{
KAnonymityConfig = kAnonymity,
},
Actions =
{
new Google.Cloud.Dlp.V2.Action
{
SaveFindings = new Google.Cloud.Dlp.V2.Action.Types.SaveFindings
{
OutputConfig = new OutputStorageConfig
{
Table = new BigQueryTable
{
ProjectId = projectId,
DatasetId = datasetId,
TableId = outputTableId
}
}
}
}
}
};
// Construct the request by providing RiskJob object created above.
var request = new CreateDlpJobRequest
{
ParentAsLocationName = new LocationName(projectId, "global"),
RiskJob = riskJob
};
// Send the job request.
DlpJob response = dlp.CreateDlpJob(request);
Console.WriteLine($"Job created successfully. Job name: ${response.Name}");
return response;
}
}
Go
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
import (
"context"
"fmt"
"io"
"strings"
"time"
dlp "cloud.google.com/go/dlp/apiv2"
"cloud.google.com/go/dlp/apiv2/dlppb"
)
// Uses the Data Loss Prevention API to compute the k-anonymity of a
// column set in a Google BigQuery table.
func calculateKAnonymityWithEntityId(w io.Writer, projectID, datasetId, tableId string, columnNames ...string) error {
// projectID := "your-project-id"
// datasetId := "your-bigquery-dataset-id"
// tableId := "your-bigquery-table-id"
// columnNames := "age" "job_title"
ctx := context.Background()
// Initialize a client once and reuse it to send multiple requests. Clients
// are safe to use across goroutines. When the client is no longer needed,
// call the Close method to cleanup its resources.
client, err := dlp.NewClient(ctx)
if err != nil {
return err
}
// Closing the client safely cleans up background resources.
defer client.Close()
// Specify the BigQuery table to analyze
bigQueryTable := &dlppb.BigQueryTable{
ProjectId: "bigquery-public-data",
DatasetId: "samples",
TableId: "wikipedia",
}
// Configure the privacy metric for the job
// Build the QuasiID slice.
var q []*dlppb.FieldId
for _, c := range columnNames {
q = append(q, &dlppb.FieldId{Name: c})
}
entityId := &dlppb.EntityId{
Field: &dlppb.FieldId{
Name: "id",
},
}
kAnonymityConfig := &dlppb.PrivacyMetric_KAnonymityConfig{
QuasiIds: q,
EntityId: entityId,
}
privacyMetric := &dlppb.PrivacyMetric{
Type: &dlppb.PrivacyMetric_KAnonymityConfig_{
KAnonymityConfig: kAnonymityConfig,
},
}
// Specify the bigquery table to store the findings.
// The "test_results" table in the given BigQuery dataset will be created if it doesn't
// already exist.
outputbigQueryTable := &dlppb.BigQueryTable{
ProjectId: projectID,
DatasetId: datasetId,
TableId: tableId,
}
// Create action to publish job status notifications to BigQuery table.
outputStorageConfig := &dlppb.OutputStorageConfig{
Type: &dlppb.OutputStorageConfig_Table{
Table: outputbigQueryTable,
},
}
findings := &dlppb.Action_SaveFindings{
OutputConfig: outputStorageConfig,
}
action := &dlppb.Action{
Action: &dlppb.Action_SaveFindings_{
SaveFindings: findings,
},
}
// Configure the risk analysis job to perform
riskAnalysisJobConfig := &dlppb.RiskAnalysisJobConfig{
PrivacyMetric: privacyMetric,
SourceTable: bigQueryTable,
Actions: []*dlppb.Action{
action,
},
}
// Build the request to be sent by the client
req := &dlppb.CreateDlpJobRequest{
Parent: fmt.Sprintf("projects/%s/locations/global", projectID),
Job: &dlppb.CreateDlpJobRequest_RiskJob{
RiskJob: riskAnalysisJobConfig,
},
}
// Send the request to the API using the client
dlpJob, err := client.CreateDlpJob(ctx, req)
if err != nil {
return err
}
fmt.Fprintf(w, "Created job: %v\n", dlpJob.GetName())
// Build a request to get the completed job
getDlpJobReq := &dlppb.GetDlpJobRequest{
Name: dlpJob.Name,
}
timeout := 15 * time.Minute
startTime := time.Now()
var completedJob *dlppb.DlpJob
// Wait for job completion
for time.Since(startTime) <= timeout {
completedJob, err = client.GetDlpJob(ctx, getDlpJobReq)
if err != nil {
return err
}
if completedJob.GetState() == dlppb.DlpJob_DONE {
break
}
time.Sleep(30 * time.Second)
}
if completedJob.GetState() != dlppb.DlpJob_DONE {
fmt.Println("Job did not complete within 15 minutes.")
}
// Retrieve completed job status
fmt.Fprintf(w, "Job status: %v", completedJob.State)
fmt.Fprintf(w, "Job name: %v", dlpJob.Name)
// Get the result and parse through and process the information
kanonymityResult := completedJob.GetRiskDetails().GetKAnonymityResult()
for _, result := range kanonymityResult.GetEquivalenceClassHistogramBuckets() {
fmt.Fprintf(w, "Bucket size range: [%d, %d]\n", result.GetEquivalenceClassSizeLowerBound(), result.GetEquivalenceClassSizeLowerBound())
for _, bucket := range result.GetBucketValues() {
quasiIdValues := []string{}
for _, v := range bucket.GetQuasiIdsValues() {
quasiIdValues = append(quasiIdValues, v.GetStringValue())
}
fmt.Fprintf(w, "\tQuasi-ID values: %s", strings.Join(quasiIdValues, ","))
fmt.Fprintf(w, "\tClass size: %d", bucket.EquivalenceClassSize)
}
}
return nil
}
Java
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
import com.google.cloud.dlp.v2.DlpServiceClient;
import com.google.privacy.dlp.v2.Action;
import com.google.privacy.dlp.v2.Action.SaveFindings;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityEquivalenceClass;
import com.google.privacy.dlp.v2.AnalyzeDataSourceRiskDetails.KAnonymityResult.KAnonymityHistogramBucket;
import com.google.privacy.dlp.v2.BigQueryTable;
import com.google.privacy.dlp.v2.CreateDlpJobRequest;
import com.google.privacy.dlp.v2.DlpJob;
import com.google.privacy.dlp.v2.EntityId;
import com.google.privacy.dlp.v2.FieldId;
import com.google.privacy.dlp.v2.GetDlpJobRequest;
import com.google.privacy.dlp.v2.LocationName;
import com.google.privacy.dlp.v2.OutputStorageConfig;
import com.google.privacy.dlp.v2.PrivacyMetric;
import com.google.privacy.dlp.v2.PrivacyMetric.KAnonymityConfig;
import com.google.privacy.dlp.v2.RiskAnalysisJobConfig;
import com.google.privacy.dlp.v2.Value;
import java.io.IOException;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@SuppressWarnings("checkstyle:AbbreviationAsWordInName")
public class RiskAnalysisKAnonymityWithEntityId {
public static void main(String[] args) throws IOException, InterruptedException {
// TODO(developer): Replace these variables before running the sample.
// The Google Cloud project id to use as a parent resource.
String projectId = "your-project-id";
// The BigQuery dataset id to be used and the reference table name to be inspected.
String datasetId = "your-bigquery-dataset-id";
String tableId = "your-bigquery-table-id";
calculateKAnonymityWithEntityId(projectId, datasetId, tableId);
}
// Uses the Data Loss Prevention API to compute the k-anonymity of a column set in a Google
// BigQuery table.
public static void calculateKAnonymityWithEntityId(
String projectId, String datasetId, String tableId) throws IOException, InterruptedException {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests. After completing all of your requests, call
// the "close" method on the client to safely clean up any remaining background resources.
try (DlpServiceClient dlpServiceClient = DlpServiceClient.create()) {
// Specify the BigQuery table to analyze
BigQueryTable bigQueryTable =
BigQueryTable.newBuilder()
.setProjectId(projectId)
.setDatasetId(datasetId)
.setTableId(tableId)
.build();
// These values represent the column names of quasi-identifiers to analyze
List<String> quasiIds = Arrays.asList("Age", "Mystery");
// Create a list of FieldId objects based on the provided list of column names.
List<FieldId> quasiIdFields =
quasiIds.stream()
.map(columnName -> FieldId.newBuilder().setName(columnName).build())
.collect(Collectors.toList());
// Specify the unique identifier in the source table for the k-anonymity analysis.
FieldId uniqueIdField = FieldId.newBuilder().setName("Name").build();
EntityId entityId = EntityId.newBuilder().setField(uniqueIdField).build();
KAnonymityConfig kanonymityConfig = KAnonymityConfig.newBuilder()
.addAllQuasiIds(quasiIdFields)
.setEntityId(entityId)
.build();
// Configure the privacy metric to compute for re-identification risk analysis.
PrivacyMetric privacyMetric =
PrivacyMetric.newBuilder().setKAnonymityConfig(kanonymityConfig).build();
// Specify the bigquery table to store the findings.
// The "test_results" table in the given BigQuery dataset will be created if it doesn't
// already exist.
BigQueryTable outputbigQueryTable =
BigQueryTable.newBuilder()
.setProjectId(projectId)
.setDatasetId(datasetId)
.setTableId("test_results")
.build();
// Create action to publish job status notifications to BigQuery table.
OutputStorageConfig outputStorageConfig =
OutputStorageConfig.newBuilder().setTable(outputbigQueryTable).build();
SaveFindings findings =
SaveFindings.newBuilder().setOutputConfig(outputStorageConfig).build();
Action action = Action.newBuilder().setSaveFindings(findings).build();
// Configure the risk analysis job to perform
RiskAnalysisJobConfig riskAnalysisJobConfig =
RiskAnalysisJobConfig.newBuilder()
.setSourceTable(bigQueryTable)
.setPrivacyMetric(privacyMetric)
.addActions(action)
.build();
// Build the request to be sent by the client
CreateDlpJobRequest createDlpJobRequest =
CreateDlpJobRequest.newBuilder()
.setParent(LocationName.of(projectId, "global").toString())
.setRiskJob(riskAnalysisJobConfig)
.build();
// Send the request to the API using the client
DlpJob dlpJob = dlpServiceClient.createDlpJob(createDlpJobRequest);
// Build a request to get the completed job
GetDlpJobRequest getDlpJobRequest =
GetDlpJobRequest.newBuilder().setName(dlpJob.getName()).build();
DlpJob completedJob = null;
// Wait for job completion
try {
Duration timeout = Duration.ofMinutes(15);
long startTime = System.currentTimeMillis();
do {
completedJob = dlpServiceClient.getDlpJob(getDlpJobRequest);
TimeUnit.SECONDS.sleep(30);
} while (completedJob.getState() != DlpJob.JobState.DONE
&& System.currentTimeMillis() - startTime <= timeout.toMillis());
} catch (InterruptedException e) {
System.out.println("Job did not complete within 15 minutes.");
}
// Retrieve completed job status
System.out.println("Job status: " + completedJob.getState());
System.out.println("Job name: " + dlpJob.getName());
// Get the result and parse through and process the information
KAnonymityResult kanonymityResult = completedJob.getRiskDetails().getKAnonymityResult();
for (KAnonymityHistogramBucket result :
kanonymityResult.getEquivalenceClassHistogramBucketsList()) {
System.out.printf(
"Bucket size range: [%d, %d]\n",
result.getEquivalenceClassSizeLowerBound(), result.getEquivalenceClassSizeUpperBound());
for (KAnonymityEquivalenceClass bucket : result.getBucketValuesList()) {
List<String> quasiIdValues =
bucket.getQuasiIdsValuesList().stream()
.map(Value::toString)
.collect(Collectors.toList());
System.out.println("\tQuasi-ID values: " + String.join(", ", quasiIdValues));
System.out.println("\tClass size: " + bucket.getEquivalenceClassSize());
}
}
}
}
}
Node.js
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
// Imports the Google Cloud Data Loss Prevention library
const DLP = require('@google-cloud/dlp');
// Instantiates a client
const dlp = new DLP.DlpServiceClient();
// The project ID to run the API call under.
// const projectId = "your-project-id";
// The ID of the dataset to inspect, e.g. 'my_dataset'
// const datasetId = 'my_dataset';
// The ID of the table to inspect, e.g. 'my_table'
// const sourceTableId = 'my_source_table';
// The ID of the table where outputs are stored
// const outputTableId = 'my_output_table';
async function kAnonymityWithEntityIds() {
// Specify the BigQuery table to analyze.
const sourceTable = {
projectId: projectId,
datasetId: datasetId,
tableId: sourceTableId,
};
// Specify the unique identifier in the source table for the k-anonymity analysis.
const uniqueIdField = {name: 'Name'};
// These values represent the column names of quasi-identifiers to analyze
const quasiIds = [{name: 'Age'}, {name: 'Mystery'}];
// Configure the privacy metric to compute for re-identification risk analysis.
const privacyMetric = {
kAnonymityConfig: {
entityId: {
field: uniqueIdField,
},
quasiIds: quasiIds,
},
};
// Create action to publish job status notifications to BigQuery table.
const action = [
{
saveFindings: {
outputConfig: {
table: {
projectId: projectId,
datasetId: datasetId,
tableId: outputTableId,
},
},
},
},
];
// Configure the risk analysis job to perform.
const riskAnalysisJob = {
sourceTable: sourceTable,
privacyMetric: privacyMetric,
actions: action,
};
// Combine configurations into a request for the service.
const createDlpJobRequest = {
parent: `projects/${projectId}/locations/global`,
riskJob: riskAnalysisJob,
};
// Send the request and receive response from the service
const [createdDlpJob] = await dlp.createDlpJob(createDlpJobRequest);
const jobName = createdDlpJob.name;
// Waiting for a maximum of 15 minutes for the job to get complete.
let job;
let numOfAttempts = 30;
while (numOfAttempts > 0) {
// Fetch DLP Job status
[job] = await dlp.getDlpJob({name: jobName});
// Check if the job has completed.
if (job.state === 'DONE') {
break;
}
if (job.state === 'FAILED') {
console.log('Job Failed, Please check the configuration.');
return;
}
// Sleep for a short duration before checking the job status again.
await new Promise(resolve => {
setTimeout(() => resolve(), 30000);
});
numOfAttempts -= 1;
}
// Create helper function for unpacking values
const getValue = obj => obj[Object.keys(obj)[0]];
// Print out the results.
const histogramBuckets =
job.riskDetails.kAnonymityResult.equivalenceClassHistogramBuckets;
histogramBuckets.forEach((histogramBucket, histogramBucketIdx) => {
console.log(`Bucket ${histogramBucketIdx}:`);
console.log(
` Bucket size range: [${histogramBucket.equivalenceClassSizeLowerBound}, ${histogramBucket.equivalenceClassSizeUpperBound}]`
);
histogramBucket.bucketValues.forEach(valueBucket => {
const quasiIdValues = valueBucket.quasiIdsValues
.map(getValue)
.join(', ');
console.log(` Quasi-ID values: {${quasiIdValues}}`);
console.log(` Class size: ${valueBucket.equivalenceClassSize}`);
});
});
}
await kAnonymityWithEntityIds();PHP
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
use Google\Cloud\Dlp\V2\DlpServiceClient;
use Google\Cloud\Dlp\V2\RiskAnalysisJobConfig;
use Google\Cloud\Dlp\V2\BigQueryTable;
use Google\Cloud\Dlp\V2\DlpJob\JobState;
use Google\Cloud\Dlp\V2\Action;
use Google\Cloud\Dlp\V2\Action\SaveFindings;
use Google\Cloud\Dlp\V2\EntityId;
use Google\Cloud\Dlp\V2\PrivacyMetric\KAnonymityConfig;
use Google\Cloud\Dlp\V2\PrivacyMetric;
use Google\Cloud\Dlp\V2\FieldId;
use Google\Cloud\Dlp\V2\OutputStorageConfig;
/**
* Computes the k-anonymity of a column set in a Google BigQuery table with entity id.
*
* @param string $callingProjectId The project ID to run the API call under.
* @param string $datasetId The ID of the dataset to inspect.
* @param string $tableId The ID of the table to inspect.
* @param string[] $quasiIdNames Array columns that form a composite key (quasi-identifiers).
*/
function k_anonymity_with_entity_id(
// TODO(developer): Replace sample parameters before running the code.
string $callingProjectId,
string $datasetId,
string $tableId,
array $quasiIdNames
): void {
// Instantiate a client.
$dlp = new DlpServiceClient();
// Specify the BigQuery table to analyze.
$bigqueryTable = (new BigQueryTable())
->setProjectId($callingProjectId)
->setDatasetId($datasetId)
->setTableId($tableId);
// Create a list of FieldId objects based on the provided list of column names.
$quasiIds = array_map(
function ($id) {
return (new FieldId())
->setName($id);
},
$quasiIdNames
);
// Specify the unique identifier in the source table for the k-anonymity analysis.
$statsConfig = (new KAnonymityConfig())
->setEntityId((new EntityId())
->setField((new FieldId())
->setName('Name')))
->setQuasiIds($quasiIds);
// Configure the privacy metric to compute for re-identification risk analysis.
$privacyMetric = (new PrivacyMetric())
->setKAnonymityConfig($statsConfig);
// Specify the bigquery table to store the findings.
// The "test_results" table in the given BigQuery dataset will be created if it doesn't
// already exist.
$outBigqueryTable = (new BigQueryTable())
->setProjectId($callingProjectId)
->setDatasetId($datasetId)
->setTableId('test_results');
$outputStorageConfig = (new OutputStorageConfig())
->setTable($outBigqueryTable);
$findings = (new SaveFindings())
->setOutputConfig($outputStorageConfig);
$action = (new Action())
->setSaveFindings($findings);
// Construct risk analysis job config to run.
$riskJob = (new RiskAnalysisJobConfig())
->setPrivacyMetric($privacyMetric)
->setSourceTable($bigqueryTable)
->setActions([$action]);
// Submit request.
$parent = "projects/$callingProjectId/locations/global";
$job = $dlp->createDlpJob($parent, [
'riskJob' => $riskJob
]);
$numOfAttempts = 10;
do {
printf('Waiting for job to complete' . PHP_EOL);
sleep(10);
$job = $dlp->getDlpJob($job->getName());
if ($job->getState() == JobState::DONE) {
break;
}
$numOfAttempts--;
} while ($numOfAttempts > 0);
// Print finding counts
printf('Job %s status: %s' . PHP_EOL, $job->getName(), JobState::name($job->getState()));
switch ($job->getState()) {
case JobState::DONE:
$histBuckets = $job->getRiskDetails()->getKAnonymityResult()->getEquivalenceClassHistogramBuckets();
foreach ($histBuckets as $bucketIndex => $histBucket) {
// Print bucket stats.
printf('Bucket %s:' . PHP_EOL, $bucketIndex);
printf(
' Bucket size range: [%s, %s]' . PHP_EOL,
$histBucket->getEquivalenceClassSizeLowerBound(),
$histBucket->getEquivalenceClassSizeUpperBound()
);
// Print bucket values.
foreach ($histBucket->getBucketValues() as $percent => $valueBucket) {
// Pretty-print quasi-ID values.
printf(' Quasi-ID values:' . PHP_EOL);
foreach ($valueBucket->getQuasiIdsValues() as $index => $value) {
print(' ' . $value->serializeToJsonString() . PHP_EOL);
}
printf(
' Class size: %s' . PHP_EOL,
$valueBucket->getEquivalenceClassSize()
);
}
}
break;
case JobState::FAILED:
printf('Job %s had errors:' . PHP_EOL, $job->getName());
$errors = $job->getErrors();
foreach ($errors as $error) {
var_dump($error->getDetails());
}
break;
case JobState::PENDING:
printf('Job has not completed. Consider a longer timeout or an asynchronous execution model' . PHP_EOL);
break;
default:
printf('Unexpected job state. Most likely, the job is either running or has not yet started.');
}
}Python
如需了解如何安装和使用敏感数据保护客户端库,请参阅 敏感数据保护客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
import time
from typing import List
import google.cloud.dlp_v2
from google.cloud.dlp_v2 import types
def k_anonymity_with_entity_id(
project: str,
source_table_project_id: str,
source_dataset_id: str,
source_table_id: str,
entity_id: str,
quasi_ids: List[str],
output_table_project_id: str,
output_dataset_id: str,
output_table_id: str,
) -> None:
"""Uses the Data Loss Prevention API to compute the k-anonymity using entity_id
of a column set in a Google BigQuery table.
Args:
project: The Google Cloud project id to use as a parent resource.
source_table_project_id: The Google Cloud project id where the BigQuery table
is stored.
source_dataset_id: The id of the dataset to inspect.
source_table_id: The id of the table to inspect.
entity_id: The column name of the table that enables accurately determining k-anonymity
in the common scenario wherein several rows of dataset correspond to the same sensitive
information.
quasi_ids: A set of columns that form a composite key.
output_table_project_id: The Google Cloud project id where the output BigQuery table
is stored.
output_dataset_id: The id of the output BigQuery dataset.
output_table_id: The id of the output BigQuery table.
"""
# Instantiate a client.
dlp = google.cloud.dlp_v2.DlpServiceClient()
# Location info of the source BigQuery table.
source_table = {
"project_id": source_table_project_id,
"dataset_id": source_dataset_id,
"table_id": source_table_id,
}
# Specify the bigquery table to store the findings.
# The output_table_id in the given BigQuery dataset will be created if it doesn't
# already exist.
dest_table = {
"project_id": output_table_project_id,
"dataset_id": output_dataset_id,
"table_id": output_table_id,
}
# Convert quasi id list to Protobuf type
def map_fields(field: str) -> dict:
return {"name": field}
# Configure column names of quasi-identifiers to analyze
quasi_ids = map(map_fields, quasi_ids)
# Tell the API where to send a notification when the job is complete.
actions = [{"save_findings": {"output_config": {"table": dest_table}}}]
# Configure the privacy metric to compute for re-identification risk analysis.
# Specify the unique identifier in the source table for the k-anonymity analysis.
privacy_metric = {
"k_anonymity_config": {
"entity_id": {"field": {"name": entity_id}},
"quasi_ids": quasi_ids,
}
}
# Configure risk analysis job.
risk_job = {
"privacy_metric": privacy_metric,
"source_table": source_table,
"actions": actions,
}
# Convert the project id into a full resource id.
parent = f"projects/{project}/locations/global"
# Call API to start risk analysis job.
response = dlp.create_dlp_job(
request={
"parent": parent,
"risk_job": risk_job,
}
)
job_name = response.name
print(f"Inspection Job started : {job_name}")
# Waiting for a maximum of 15 minutes for the job to be completed.
job = dlp.get_dlp_job(request={"name": job_name})
no_of_attempts = 30
while no_of_attempts > 0:
# Check if the job has completed
if job.state == google.cloud.dlp_v2.DlpJob.JobState.DONE:
break
if job.state == google.cloud.dlp_v2.DlpJob.JobState.FAILED:
print("Job Failed, Please check the configuration.")
return
# Sleep for a short duration before checking the job status again
time.sleep(30)
no_of_attempts -= 1
# Get the DLP job status
job = dlp.get_dlp_job(request={"name": job_name})
if job.state != google.cloud.dlp_v2.DlpJob.JobState.DONE:
print("Job did not complete within 15 minutes.")
return
# Create helper function for unpacking values
def get_values(obj: types.Value) -> str:
return str(obj.string_value)
# Print out the results.
print(f"Job name: {job.name}")
histogram_buckets = (
job.risk_details.k_anonymity_result.equivalence_class_histogram_buckets
)
# Print bucket stats
for i, bucket in enumerate(histogram_buckets):
print(f"Bucket {i}:")
if bucket.equivalence_class_size_lower_bound:
print(
f"Bucket size range: [{bucket.equivalence_class_size_lower_bound}, "
f"{bucket.equivalence_class_size_upper_bound}]"
)
for value_bucket in bucket.bucket_values:
print(
f"Quasi-ID values: {get_values(value_bucket.quasi_ids_values[0])}"
)
print(f"Class size: {value_bucket.equivalence_class_size}")
else:
print("No findings.")