En este documento se explica cómo ejecutar cargas de trabajo por lotes de Apache Spark SQL y PySpark sin servidor para crear una tabla de Apache Iceberg con metadatos almacenados en el metastore de BigLake. Para obtener información sobre otras formas de ejecutar código de Spark, consulta los artículos Ejecutar código de PySpark en un cuaderno de BigQuery y Ejecutar una carga de trabajo de Apache Spark.
Antes de empezar
Si aún no lo has hecho, crea un Google Cloud proyecto y un contenedor de Cloud Storage.
Configurar un proyecto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Crea un segmento de Cloud Storage en tu proyecto.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Asigna el rol Editor de datos de BigQuery (
roles/bigquery.dataEditor) a la cuenta de servicio predeterminada de Compute EnginePROJECT_NUMBER-compute@developer.gserviceaccount.com. Para obtener instrucciones, consulta Asignar un rol concreto.Ejemplo de Google Cloud CLI:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member PROJECT_NUMBER-compute@developer.gserviceaccount.com \ --role roles/bigquery.dataEditor
Notas:
Copia los siguientes comandos de Spark SQL de forma local o en Cloud Shell en un archivo
iceberg-table.sql.USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
Haz los cambios siguientes:
- CATALOG_NAME: nombre del catálogo de Iceberg.
- BUCKET y WAREHOUSE_FOLDER: segmento y carpeta de Cloud Storage que se usan como directorio de almacén de Iceberg.
Ejecuta el siguiente comando de forma local o en Cloud Shell desde el directorio que contiene
iceberg-table.sqlpara enviar la carga de trabajo de Spark SQL.gcloud dataproc batches submit spark-sql iceberg-table.sql \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"
Notas:
- PROJECT_ID: tu ID de proyecto Google Cloud . Los IDs de proyecto se indican en la sección Información del proyecto del panel de control de la consola Google Cloud .
- REGION: una región de Compute Engine disponible para ejecutar la carga de trabajo.
- BUCKET_NAME: nombre del segmento de Cloud Storage. Spark sube las dependencias de la carga de trabajo a una carpeta
/dependenciesde este bucket antes de ejecutar la carga de trabajo por lotes. El WAREHOUSE_FOLDER se encuentra en este segmento. --version: versión 2.2 o posterior del tiempo de ejecución de Serverless for Apache Spark.- SUBNET_NAME: nombre de una subred de VPC en el
REGION. Si omite esta marca, Serverless para Apache Spark seleccionará ladefaultsubred de la región de la sesión. Serverless para Apache Spark habilita el acceso privado de Google (PGA) en la subred. Para consultar los requisitos de conectividad de red, consulta Google Cloud Configuración de red de Serverless para Apache Spark. - LOCATION: una ubicación de BigQuery admitida. La ubicación predeterminada es "US".
--propertiesPropiedades de catálogo
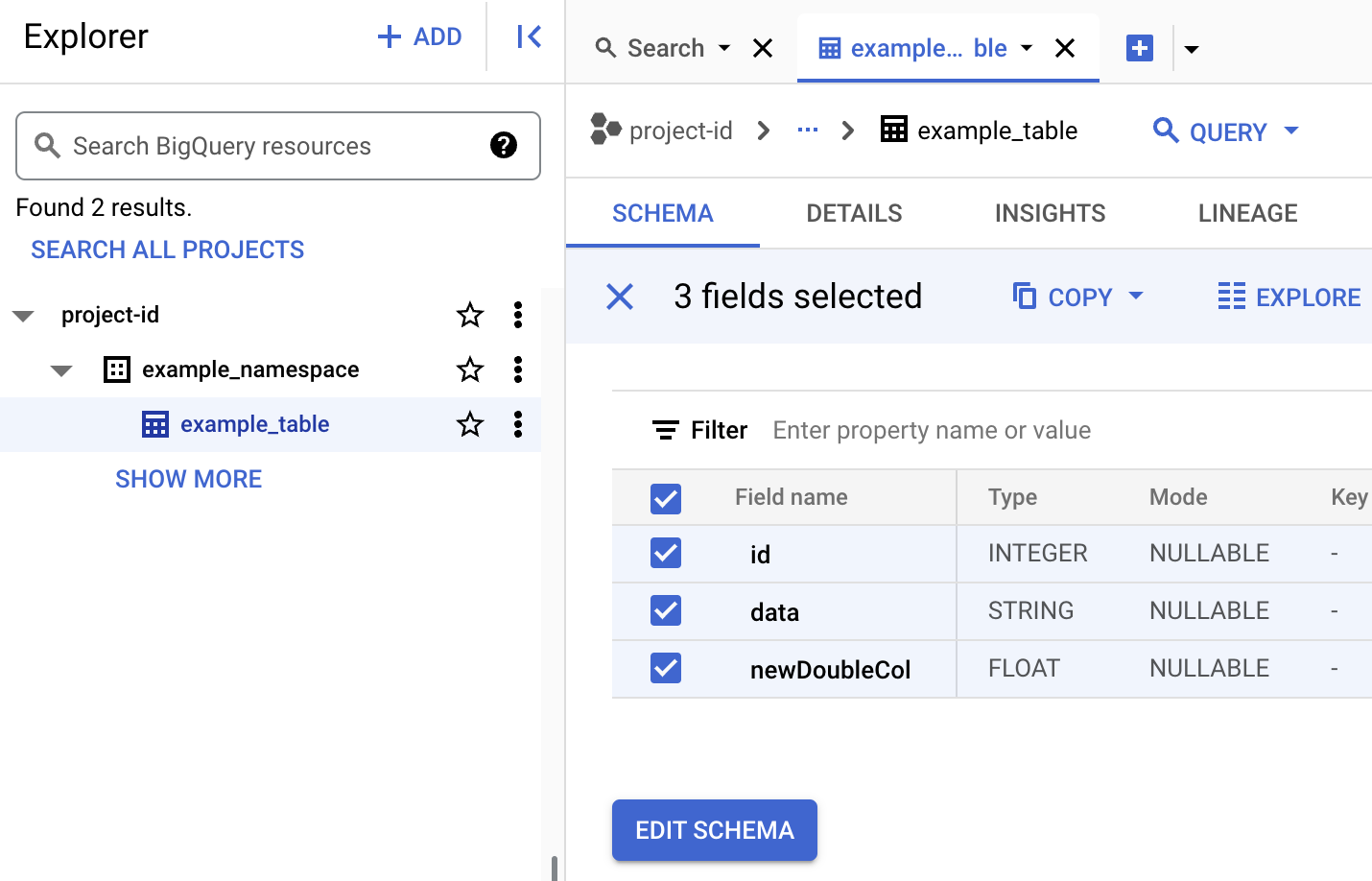
Ver metadatos de una tabla en BigQuery
En la Google Cloud consola, ve a la página BigQuery.
Ver los metadatos de una tabla Iceberg.
- Copia el siguiente código de PySpark de forma local o en Cloud Shell en un archivo
iceberg-table.py.from pyspark.sql import SparkSession spark = SparkSession.builder.appName("iceberg-table-example").getOrCreate() catalog = "CATALOG_NAME" namespace = "NAMESPACE" spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create table and display schema spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;") # Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');") # Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE example_iceberg_table;")
Haz los cambios siguientes:
- CATALOG_NAME y NAMESPACE: el nombre del catálogo de Iceberg
y el espacio de nombres se combinan para identificar la tabla de Iceberg (
catalog.namespace.table_name).
- CATALOG_NAME y NAMESPACE: el nombre del catálogo de Iceberg
y el espacio de nombres se combinan para identificar la tabla de Iceberg (
-
Ejecuta el siguiente comando de forma local o en Cloud Shell desde el directorio que contiene
iceberg-table.pypara enviar la carga de trabajo de PySpark.gcloud dataproc batches submit pyspark iceberg-table.py \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"Notas:
- PROJECT_ID: tu ID de proyecto Google Cloud . Los IDs de proyecto se indican en la sección Información del proyecto del Google Cloud panel de control de la consola.
- REGION: una región de Compute Engine disponible para ejecutar la carga de trabajo.
- BUCKET_NAME: nombre del segmento de Cloud Storage. Spark sube las
dependencias de la carga de trabajo a una carpeta
/dependenciesde este contenedor antes de ejecutar la carga de trabajo por lotes. --version: versión 2.2 o posterior del tiempo de ejecución de Serverless for Apache Spark.- SUBNET_NAME: nombre de una subred de VPC en la
REGION. Si omite esta marca, Serverless para Apache Spark seleccionará ladefaultsubred de la región de la sesión. Serverless para Apache Spark habilita el acceso privado de Google (PGA) en la subred. Para consultar los requisitos de conectividad de red, consulta la sección Google Cloud Configuración de red de Serverless para Apache Spark. - LOCATION: una ubicación de BigQuery admitida. La ubicación predeterminada es "US".
- BUCKET y WAREHOUSE_FOLDER: segmento y carpeta de Cloud Storage que se usan como directorio de almacén de Iceberg.
--properties: Propiedades de catálogo.
- Consulta el esquema de la tabla en BigQuery.
- En la Google Cloud consola, ve a la página BigQuery. Ir a BigQuery Studio
- Ver los metadatos de una tabla Iceberg.

Asignación de recursos de OSS a recursos de BigQuery
Ten en cuenta la siguiente asignación entre los términos de recursos de código abierto y de BigQuery:
Recurso de OSS Recurso de BigQuery Espacio de nombres y base de datos Conjunto de datos Tabla con o sin particiones Tabla Ver Ver Crear una tabla Iceberg
En esta sección se muestra cómo crear una tabla de Iceberg con metadatos en el metastore de BigLake mediante cargas de trabajo por lotes de Spark SQL y PySpark de Serverless para Apache Spark.
Spark SQL
Ejecutar una carga de trabajo de Spark SQL para crear una tabla Iceberg
En los siguientes pasos se muestra cómo ejecutar una carga de trabajo por lotes de Spark SQL de Serverless para Apache Spark para crear una tabla Iceberg con metadatos de tabla almacenados en BigLake Metastore.
PySpark
En los siguientes pasos se muestra cómo ejecutar una carga de trabajo por lotes de PySpark de Serverless para Apache Spark para crear una tabla Iceberg con metadatos de tabla almacenados en BigLake Metastore.