In diesem Dokument wird beschrieben, wie Sie die JupyterLab-Erweiterung auf einem Computer oder einer selbstverwalteten VM installieren und verwenden, die Zugriff auf Google-Dienste hat. Außerdem wird beschrieben, wie Sie serverlosen Spark-Notebook-Code entwickeln und bereitstellen.
Installieren Sie die Erweiterung in wenigen Minuten, um die folgenden Funktionen zu nutzen:
- Serverlose Spark- und BigQuery-Notebooks zum schnellen Entwickeln von Code starten
- BigQuery-Datasets in JupyterLab ansehen und in der Vorschau anzeigen
- Cloud Storage-Dateien in JupyterLab bearbeiten
- Notebook in Composer planen
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init Laden Sie Python 3.11 oder höher von
python.org/downloadsherunter und installieren Sie die Software.- Prüfen Sie, ob Python 3.11 oder höher installiert ist.
python3 --version
- Prüfen Sie, ob Python 3.11 oder höher installiert ist.
Virtualisieren Sie die Python-Umgebung.
pip3 install pipenv
- Erstellen Sie einen Installationsordner.
mkdir jupyter
- Wechseln Sie in den Installationsordner.
cd jupyter
- Erstellen Sie eine virtuelle Umgebung.
pipenv shell
- Erstellen Sie einen Installationsordner.
Installieren Sie JupyterLab in der virtuellen Umgebung.
pipenv install jupyterlab
Installieren Sie die JupyterLab-Erweiterung.
pipenv install bigquery-jupyter-plugin
jupyter lab
Die Seite Launcher von JupyterLab wird in Ihrem Browser geöffnet. Er enthält einen Abschnitt Dataproc-Jobs und -Sitzungen. Er kann auch die Abschnitte Serverless for Apache Spark Notebooks und Dataproc Cluster Notebooks enthalten, wenn Sie Zugriff auf Serverless for Apache Spark-Notebooks oder Dataproc-Cluster mit der optionalen Jupyter-Komponente haben, die in Ihrem Projekt ausgeführt wird.
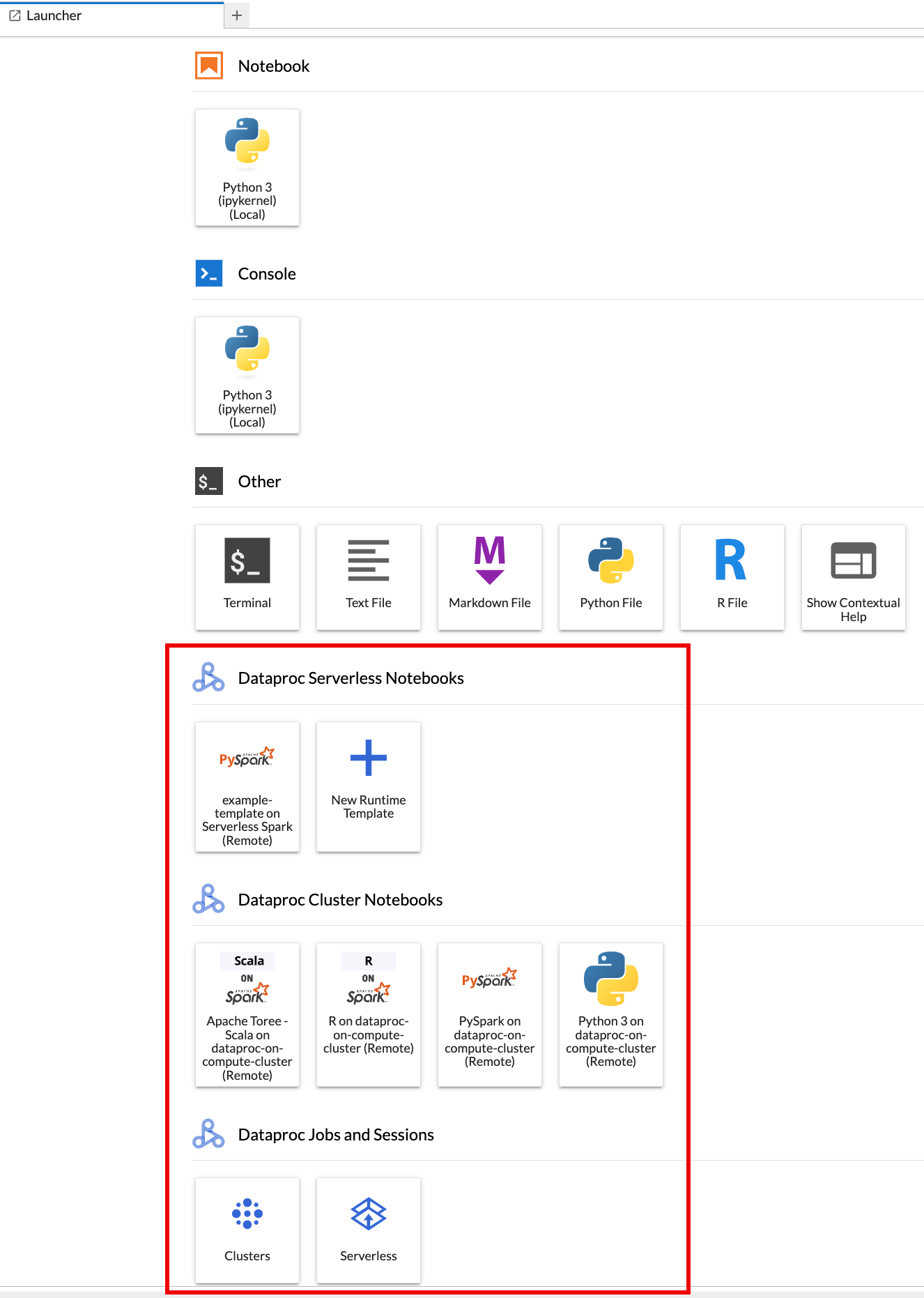
Standardmäßig wird Ihre interaktive Sitzung für Serverless for Apache Spark in dem Projekt und in der Region ausgeführt, die Sie beim Ausführen von
gcloud initunter Vorbereitung festgelegt haben. Sie können die Projekt- und Regionseinstellungen für Ihre Sitzungen in JupyterLab unter Einstellungen > Google Cloud Einstellungen > Google Cloud Projekteinstellungen ändern.Sie müssen die Erweiterung neu starten, damit die Änderungen wirksam werden.
Klicken Sie auf der Seite Launcher von JupyterLab im Abschnitt Serverless for Apache Spark Notebooks auf die Karte
New runtime template.
Füllen Sie das Formular Laufzeitvorlage aus.
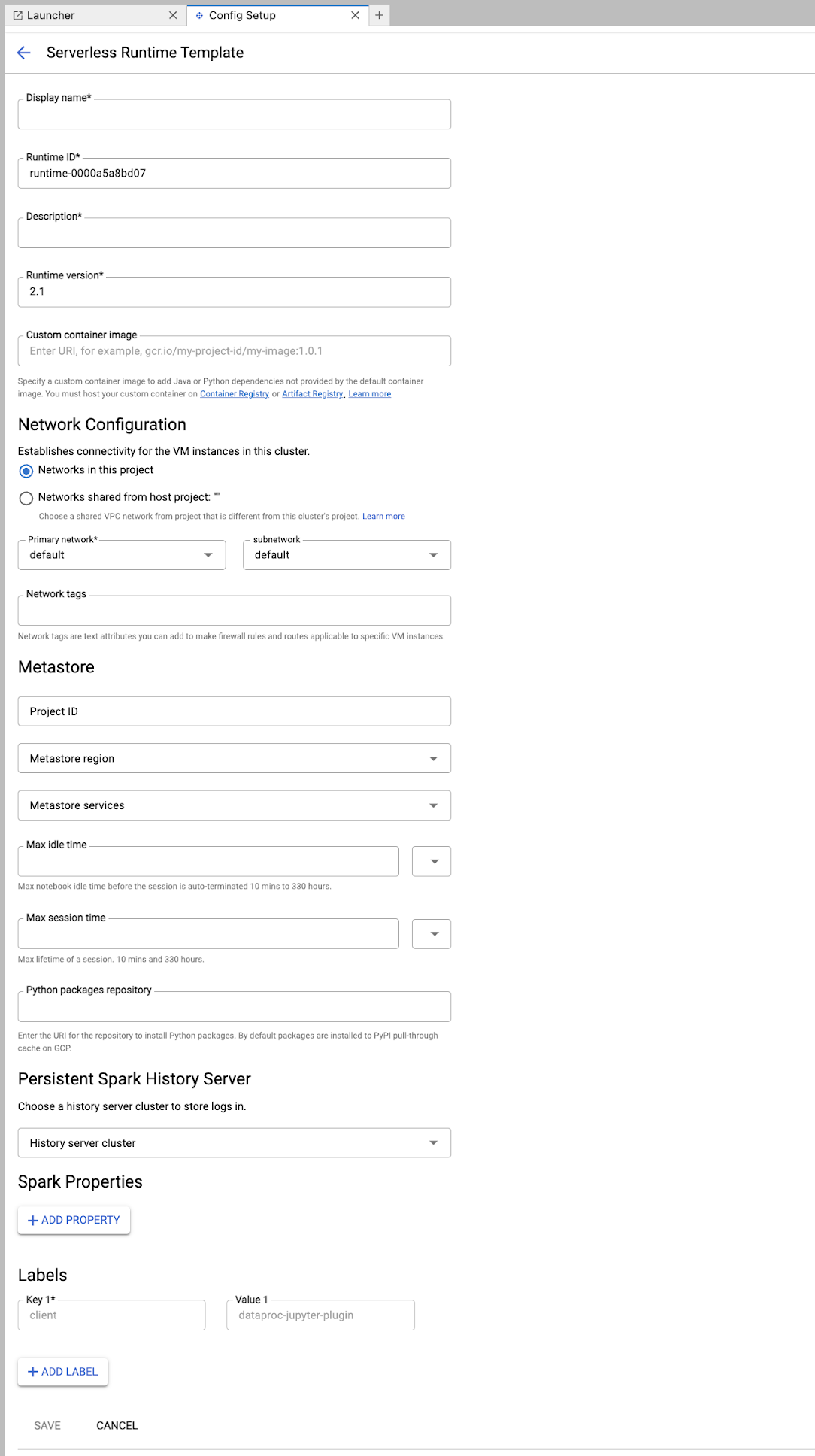
Vorlageninformationen:
- Anzeigename, Runtime-ID und Beschreibung: Akzeptieren oder füllen Sie einen Anzeigenamen, eine Runtime-ID und eine Beschreibung für die Vorlage aus.
Ausführungskonfiguration: Wählen Sie Nutzerkonto aus, um Notebooks mit der Nutzeridentität anstelle der Dataproc-Dienstkontoidentität auszuführen.
- Dienstkonto: Wenn Sie kein Dienstkonto angeben, wird das Compute Engine-Standarddienstkonto verwendet.
- Laufzeitversion: Bestätigen oder wählen Sie die Laufzeitversion aus.
- Benutzerdefiniertes Container-Image: Optional können Sie den URI eines benutzerdefinierten Container-Images angeben.
- Staging-Bucket: Optional können Sie den Namen eines Cloud Storage-Staging-Buckets angeben, der von Serverless for Apache Spark verwendet werden soll.
- Python-Paket-Repository: Standardmäßig werden Python-Pakete aus dem PyPI-Pull-Through-Cache heruntergeladen und installiert, wenn Nutzer
pip-Installationsbefehle in ihren Notebooks ausführen. Sie können das private Artefakt-Repository Ihrer Organisation für Python-Pakete als Standard-Repository für Python-Pakete angeben.
Verschlüsselung: Übernehmen Sie die Standardeinstellung Google-owned and Google-managed encryption key oder wählen Sie Vom Kunden verwalteter Verschlüsselungsschlüssel (CMEK) aus. Wenn Sie CMEK verwenden, wählen Sie die entsprechenden Optionen aus oder geben Sie die Schlüsselinformationen an.
Netzwerkkonfiguration: Wählen Sie ein Subnetzwerk im Projekt oder ein Subnetzwerk aus, das von einem Hostprojekt freigegeben wurde. Sie können das Projekt in JupyterLab unter Einstellungen > Google Cloud Einstellungen > Google Cloud Projekteinstellungen ändern. Sie können Netzwerk-Tags angeben, die auf das angegebene Netzwerk angewendet werden sollen. Hinweis: Bei Serverless for Apache Spark wird privater Google-Zugriff (PGA) im angegebenen Subnetz aktiviert. Informationen zu den Anforderungen an die Netzwerkverbindung finden Sie unter Google Cloud Serverless for Apache Spark-Netzwerkkonfiguration.
Sitzungskonfiguration: Sie können diese Felder optional ausfüllen, um die Dauer von Sitzungen zu begrenzen, die mit der Vorlage erstellt werden.
- Maximale Leerlaufzeit:Die maximale Leerlaufzeit, bevor die Sitzung beendet wird. Zulässiger Bereich: 10 Minuten bis 336 Stunden (14 Tage).
- Maximale Sitzungsdauer:Die maximale Lebensdauer einer Sitzung, bevor sie beendet wird. Zulässiger Bereich: 10 Minuten bis 336 Stunden (14 Tage).
Metastore: Wenn Sie einen Dataproc Metastore-Dienst mit Ihren Sitzungen verwenden möchten, wählen Sie die Metastore-Projekt-ID und den Dienst aus.
Persistent History Server: Sie können einen verfügbaren Persistent Spark History Server auswählen, um während und nach Sitzungen auf Sitzungslogs zuzugreifen.
Spark-Attribute:Sie können Spark-Attribute für Ressourcenzuweisung, Autoscaling oder GPU auswählen und hinzufügen. Klicken Sie auf Property hinzufügen, um weitere Spark-Properties hinzuzufügen. Weitere Informationen finden Sie unter Spark-Attribute.
Labels:Klicken Sie für jedes Label, das für mit der Vorlage erstellte Sitzungen festgelegt werden soll, auf Label hinzufügen.
Klicken Sie auf Speichern, um die Vorlage zu erstellen.
So rufen Sie eine Laufzeitvorlage auf oder löschen sie.
- Klicken Sie auf Einstellungen > Einstellungen. Google Cloud
Im Bereich Dataproc-Einstellungen > Vorlagen für serverlose Laufzeiten wird die Liste der Laufzeitvorlagen angezeigt.
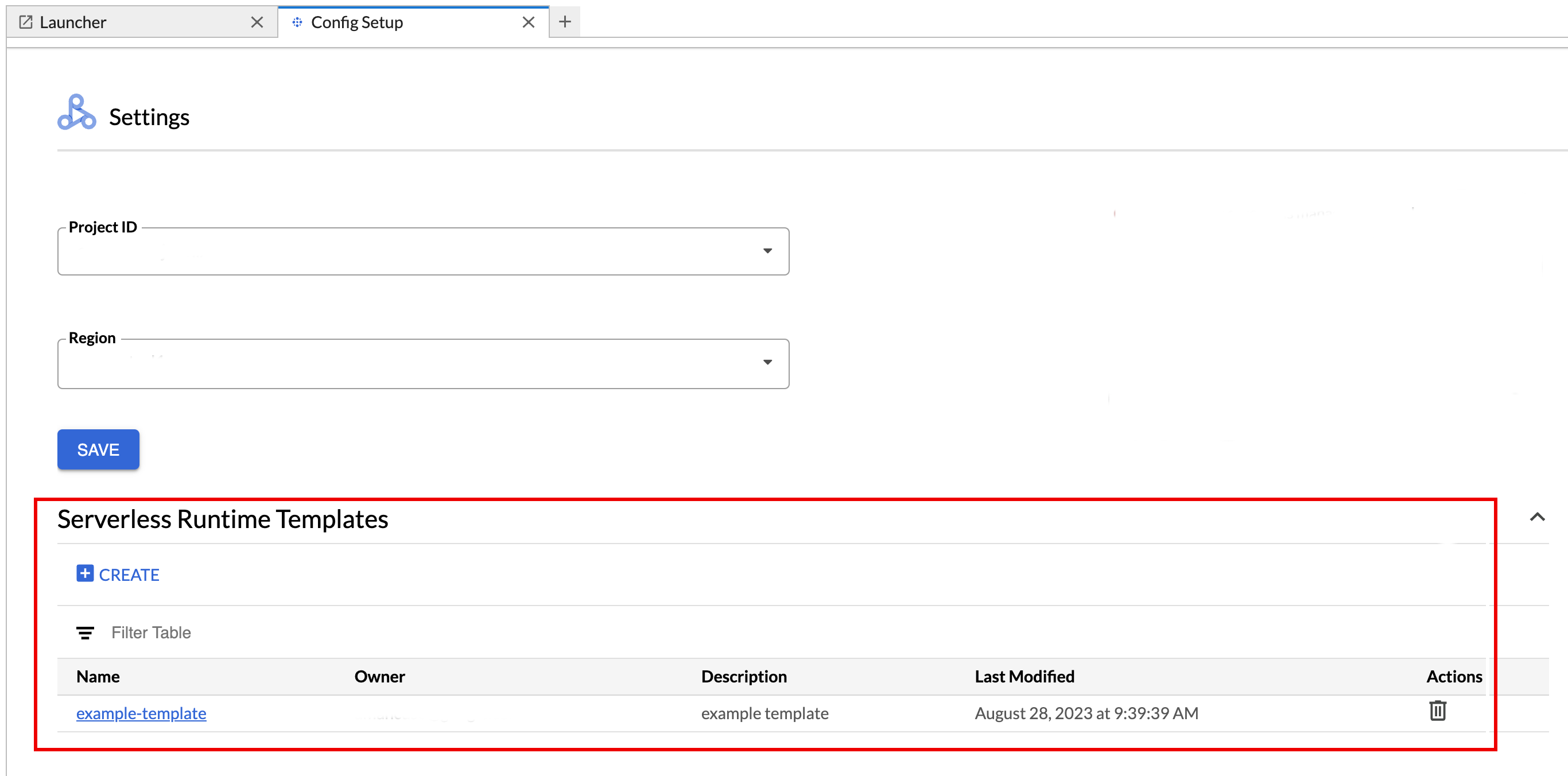
- Klicken Sie auf einen Vorlagennamen, um die Vorlagendetails aufzurufen.
- Sie können eine Vorlage über das Menü Aktion der Vorlage löschen.
Öffnen und aktualisieren Sie die Seite Launcher in JupyterLab, um die gespeicherte Notebookvorlagenkarte auf der Seite Launcher in JupyterLab zu sehen.

Erstellen Sie eine YAML-Datei mit der Konfiguration Ihrer Laufzeitvorlage.
Einfache YAML-Datei
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
Komplexe YAML-Datei
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
Erstellen Sie eine Sitzungsvorlage (Laufzeitvorlage) aus Ihrer YAML-Datei, indem Sie den folgenden Befehl gcloud beta dataproc session-templates import lokal oder in Cloud Shell ausführen:
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- Unter gcloud beta dataproc session-templates finden Sie Befehle zum Beschreiben, Auflisten, Exportieren und Löschen von Sitzungsvorlagen.
Klicken Sie auf eine Karte, um eine Serverless for Apache Spark-Sitzung zu erstellen und ein Notebook zu starten. Wenn die Sitzung erstellt wurde und der Notebook-Kernel bereit ist, ändert sich der Kernelstatus von
StartinginIdle (Ready).Notebook-Code schreiben und testen
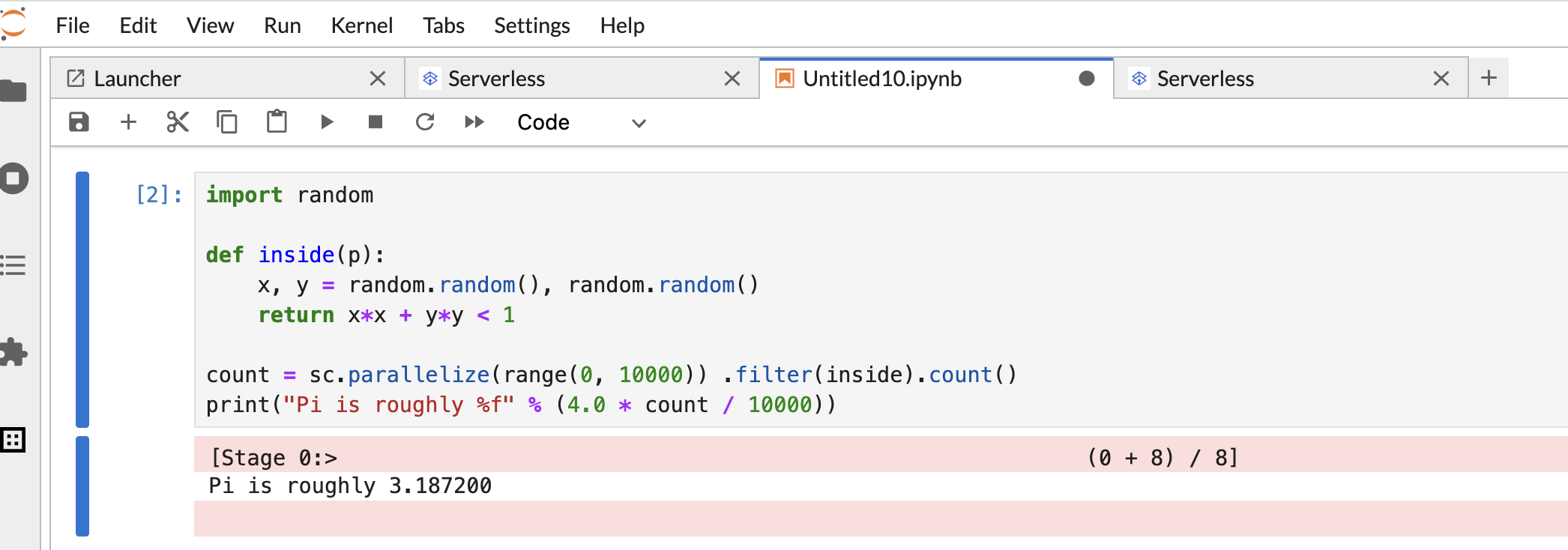
Kopieren Sie den folgenden PySpark-Code
Pi estimationund fügen Sie ihn in die PySpark-Notebookzelle ein. Drücken Sie dann Umschalt + Eingabetaste, um den Code auszuführen.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
Notebook-Ergebnis:
Nachdem Sie ein Notebook erstellt und verwendet haben, können Sie die Notebooksitzung beenden, indem Sie auf dem Tab Kernel auf Kernel herunterfahren klicken.
- Wenn Sie die Sitzung wiederverwenden möchten, erstellen Sie ein neues Notebook, indem Sie im Menü Datei>> Neu die Option Notebook auswählen. Nachdem das neue Notebook erstellt wurde, wählen Sie im Dialogfeld zur Kernelauswahl die vorhandene Sitzung aus. Im neuen Notebook wird die Sitzung wiederverwendet und der Sitzungskontext aus dem vorherigen Notebook beibehalten.
Wenn Sie die Sitzung nicht beenden, wird sie von Dataproc beendet, wenn das Zeitlimit für die Inaktivität der Sitzung abläuft. Sie können die Leerlaufzeit für Sitzungen in der Laufzeitvorlagenkonfiguration konfigurieren. Die standardmäßige Leerlaufzeit für Sitzungen beträgt eine Stunde.
Klicken Sie im Bereich Dataproc-Cluster-Notebook auf eine Karte.
Wenn sich der Kernelstatus von
StartinginIdle (Ready)ändert, können Sie mit dem Schreiben und Ausführen von Notebook-Code beginnen.Nachdem Sie ein Notebook erstellt und verwendet haben, können Sie die Notebooksitzung beenden, indem Sie auf dem Tab Kernel auf Kernel herunterfahren klicken.
Klicken Sie in der Seitenleiste des Launchers von JupyterLab auf das Symbol für den Cloud Storage-Browser, um darauf zuzugreifen. Doppelklicken Sie dann auf einen Ordner, um seinen Inhalt aufzurufen.
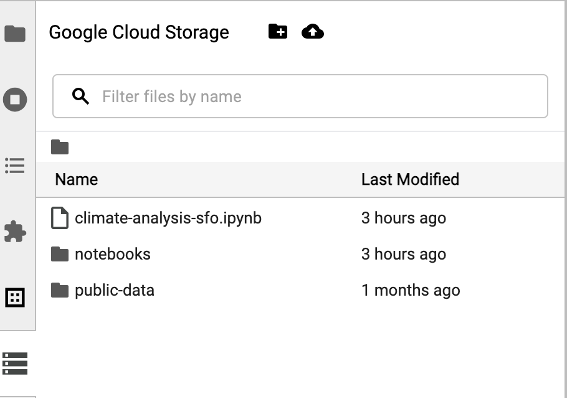
Sie können auf von Jupyter unterstützte Dateitypen klicken, um sie zu öffnen und zu bearbeiten. Wenn Sie Änderungen an den Dateien speichern, werden sie in Cloud Storage geschrieben.
Wenn Sie einen neuen Cloud Storage-Ordner erstellen möchten, klicken Sie auf das Symbol für einen neuen Ordner und geben Sie dann den Namen des Ordners ein.
Wenn Sie Dateien in einen Cloud Storage-Bucket oder einen Ordner hochladen möchten, klicken Sie auf das Upload-Symbol und wählen Sie die Dateien aus, die hochgeladen werden sollen.
Klicken Sie auf der JupyterLab-Seite Launcher im Abschnitt Serverless for Apache Spark Notebooks oder Dataproc Cluster Notebook auf eine PySpark-Karte, um ein PySpark-Notebook zu öffnen.
Klicken Sie auf der Seite Launcher von JupyterLab im Bereich Dataproc Cluster Notebook auf eine Python-Kernelkarte, um ein Python-Notebook zu öffnen.
Klicken Sie auf der JupyterLab-Seite Launcher im Abschnitt Dataproc cluster Notebook auf die Karte „Apache Toree“, um ein Notebook für die Entwicklung von Scala-Code zu öffnen.

Abbildung 1. Apache Toree-Kernelkarte auf der Seite „JupyterLab Launcher“ - Spark-Code in Serverless for Apache Spark-Notebooks entwickeln und ausführen
- Erstellen und verwalten Sie Vorlagen für die Laufzeit (Sitzung) von Serverless for Apache Spark, interaktive Sitzungen und Batcharbeitslasten.
- BigQuery-Notebooks entwickeln und ausführen
- BigQuery-Datasets durchsuchen, prüfen und in der Vorschau ansehen
- Laden Sie VS Code herunter und installieren Sie es.
- Öffnen Sie VS Code und klicken Sie in der Aktivitätsleiste auf Erweiterungen.
Suchen Sie über die Suchleiste nach der Jupyter-Erweiterung und klicken Sie dann auf Installieren. Die Jupyter-Erweiterung von Microsoft ist eine erforderliche Abhängigkeit.
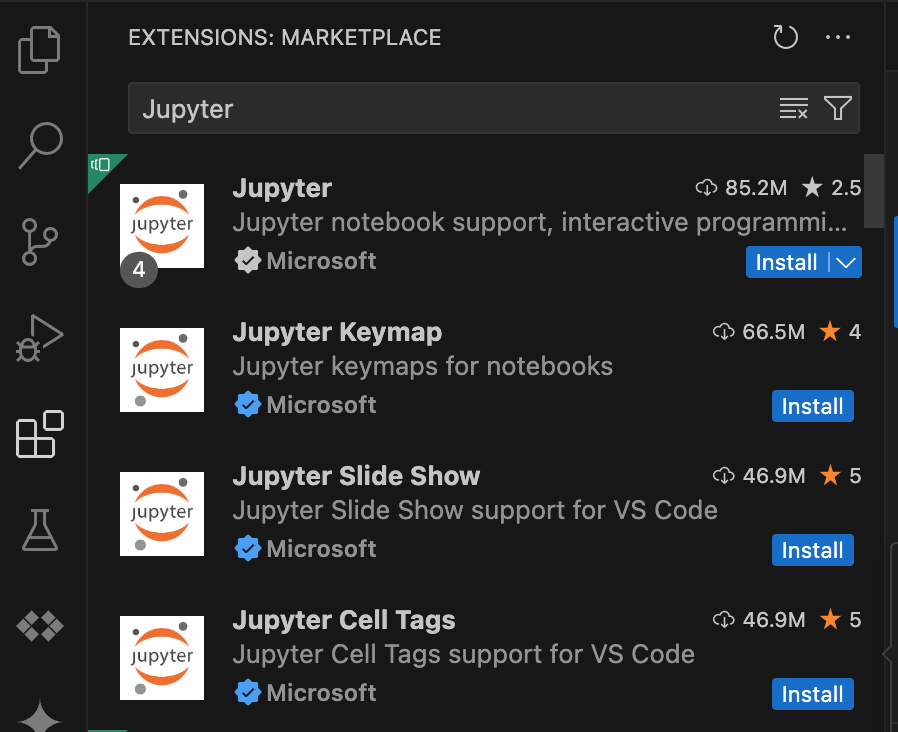
- Öffnen Sie VS Code und klicken Sie in der Aktivitätsleiste auf Erweiterungen.
Suchen Sie über die Suchleiste nach der Erweiterung Google Cloud Code und klicken Sie dann auf Installieren.

Starten Sie VS Code neu, wenn Sie dazu aufgefordert werden.
- Öffnen Sie VS Code und klicken Sie dann in der Aktivitätsleiste auf Google Cloud Code.
- Öffnen Sie den Bereich Dataproc.
- Klicken Sie auf Bei Google Cloudanmelden. Sie werden weitergeleitet, um sich mit Ihren Anmeldedaten anzumelden.
- Verwenden Sie die Anwendungstaskleiste auf oberster Ebene, um zu Code> Einstellungen> Einstellungen> Erweiterungen zu navigieren.
- Suchen Sie nach Google Cloud Code und klicken Sie auf das Symbol Verwalten, um das Menü zu öffnen.
- Wählen Sie Einstellungen aus.
- Geben Sie in den Feldern Projekt und Dataproc-Region den Namen des Google Cloud Projekts und der Region ein, die zum Entwickeln von Notebooks und zum Verwalten von Serverless for Apache Spark-Ressourcen verwendet werden sollen.
- Öffnen Sie VS Code und klicken Sie dann in der Aktivitätsleiste auf Google Cloud Code.
- Öffnen Sie den Bereich Notebooks und klicken Sie auf Neues Serverless Spark-Notebook.
- Wählen Sie eine Laufzeitvorlage (Sitzungsvorlage) aus oder erstellen Sie eine neue, die für die Notebook-Sitzung verwendet werden soll.
Eine neue
.ipynb-Datei mit Beispielcode wird erstellt und im Editor geöffnet.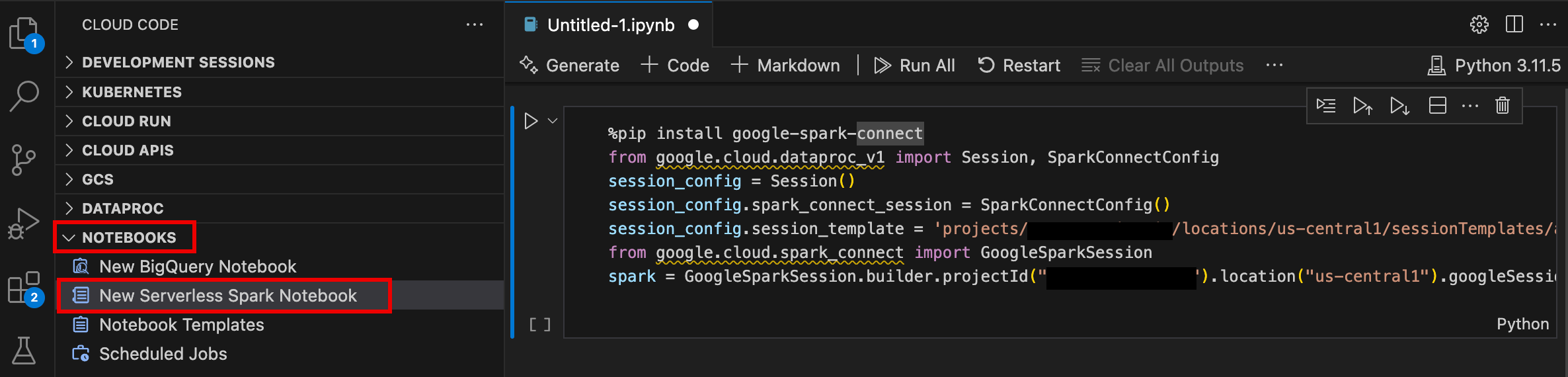
Sie können jetzt Code in Ihrem Serverless for Apache Spark-Notebook schreiben und ausführen.
- Öffnen Sie VS Code und klicken Sie dann in der Aktivitätsleiste auf Google Cloud Code.
Öffnen Sie den Bereich Dataproc und klicken Sie dann auf die folgenden Ressourcennamen:
- Cluster: Cluster und Jobs erstellen und verwalten.
- Serverless: Batcharbeitslasten und interaktive Sitzungen erstellen und verwalten.
- Spark-Laufzeitvorlagen: Sitzungsvorlagen erstellen und verwalten.

Notebook-Code in der Google Cloud Serverless für Apache Spark-Infrastruktur ausführen
Notebook-Ausführung in Cloud Composer planen
Batchjobs an die Google Cloud Serverless for Apache Spark-Infrastruktur oder an Ihren Dataproc on Compute Engine-Cluster senden.
Klicken Sie rechts oben im Notebook auf die Schaltfläche Job Scheduler (Job Scheduler).
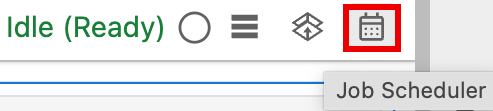
Füllen Sie das Formular Create A Scheduled Job (Geplanten Job erstellen) aus und geben Sie die folgenden Informationen an:
- Ein eindeutiger Name für den Notebook-Ausführungsjob
- Die Cloud Composer-Umgebung, die zum Bereitstellen des Notebooks verwendet werden soll
- Eingabeparameter, wenn das Notebook parametrisiert ist
- Der Dataproc-Cluster oder die serverlose Laufzeitvorlage, die zum Ausführen des Notebooks verwendet werden soll
- Wenn ein Cluster ausgewählt ist, wird der Cluster nach Abschluss der Notebook-Ausführung im Cluster angehalten.
- Anzahl der Wiederholungen und Wiederholungsverzögerung in Minuten, wenn die Notebookausführung beim ersten Versuch fehlschlägt
- Ausführungsbenachrichtigungen, die gesendet werden sollen, und die Empfängerliste. Benachrichtigungen werden über eine Airflow-SMTP-Konfiguration gesendet.
- Der Zeitplan für die Notebookausführung
Klicken Sie auf Erstellen.
Nachdem das Notebook erfolgreich geplant wurde, wird der Jobname in der Liste der geplanten Jobs in der Cloud Composer-Umgebung angezeigt.

Klicken Sie auf der Seite Launcher von JupyterLab im Abschnitt Dataproc Jobs and Sessions (Dataproc-Jobs und -Sitzungen) auf die Karte Serverless (Serverlos).
Klicken Sie auf den Tab Batch (Batch), dann auf Create Batch (Batch erstellen) und füllen Sie die Felder unter Batch Info (Batch-Informationen) aus.
Klicken Sie auf Senden, um den Job zu senden.
Klicken Sie auf der JupyterLab-Seite Launcher im Abschnitt Dataproc Jobs and Sessions auf die Karte Clusters.
Klicken Sie auf den Tab Jobs und dann auf Job senden.
Wählen Sie einen Cluster aus und füllen Sie dann die Felder für Job aus.
Klicken Sie auf Senden, um den Job zu senden.
- Klicken Sie auf die Karte Serverless.
- Klicken Sie auf den Tab Sitzungen und dann auf eine Sitzungs-ID, um die Seite Sitzungsdetails zu öffnen. Dort können Sie Sitzungseigenschaften aufrufen, Google Cloud Protokolle im Log-Explorer ansehen und eine Sitzung beenden. Hinweis: Für jedes Google Cloud Serverless for Apache Spark-Notebook wird eine eindeutige Google Cloud Serverless for Apache Spark-Sitzung erstellt.
- Klicken Sie auf den Tab Batches, um die Liste der Google Cloud Serverless for Apache Spark-Batches im aktuellen Projekt und in der aktuellen Region aufzurufen. Klicken Sie auf eine Batch-ID, um die Batchdetails aufzurufen.
- Klicken Sie auf die Karte Cluster. Der Tab Cluster ist ausgewählt, um aktive Dataproc on Compute Engine-Cluster im aktuellen Projekt und in der aktuellen Region aufzulisten. Sie können auf die Symbole in der Spalte Aktionen klicken, um einen Cluster zu starten, zu beenden oder neu zu starten. Klicken Sie auf einen Clusternamen, um die Clusterdetails aufzurufen. Sie können auf die Symbole in der Spalte Aktionen klicken, um einen Job zu klonen, zu beenden oder zu löschen.
- Klicken Sie auf die Karte Jobs, um die Liste der Jobs im aktuellen Projekt aufzurufen. Klicken Sie auf eine Job-ID, um die Jobdetails aufzurufen.
JupyterLab-Erweiterung installieren
Sie können die JupyterLab-Erweiterung auf einem Computer oder einer VM installieren und verwenden, der Zugriff auf Google-Dienste hat, z. B. auf Ihrem lokalen Computer oder einer Compute Engine-VM-Instanz.
So installieren Sie die Erweiterung:
Serverless for Apache Spark-Laufzeitvorlage erstellen
Laufzeitvorlagen für Serverless für Apache Spark (auch Sitzungsvorlagen genannt) enthalten Konfigurationseinstellungen für die Ausführung von Spark-Code in einer Sitzung. Sie können Laufzeitvorlagen mit JupyterLab oder der gcloud CLI erstellen und verwalten.
JupyterLab
gcloud
Notebooks starten und verwalten
Nachdem Sie die Dataproc JupyterLab-Erweiterung installiert haben, können Sie auf der Seite Launcher in JupyterLab auf Vorlagenkarten klicken, um:
Jupyter-Notebook in Serverless for Apache Spark starten
Im Abschnitt Serverless for Apache Spark Notebooks auf der Seite „JupyterLab Launcher“ werden Notebook-Vorlagenkarten angezeigt, die Serverless for Apache Spark-Laufzeitvorlagen zugeordnet sind (siehe Serverless for Apache Spark-Laufzeitvorlage erstellen).

Notebook in einem Dataproc in Compute Engine-Cluster starten
Wenn Sie einen Dataproc in Compute Engine-Jupyter-Cluster erstellt haben, enthält die JupyterLab-Seite Launcher den Abschnitt Dataproc Cluster Notebook mit vorinstallierten Kernelkarten.
So starten Sie ein Jupyter-Notebook in Ihrem Dataproc in Compute Engine-Cluster:
Eingabe- und Ausgabedateien in Cloud Storage verwalten
Für die Analyse explorativer Daten und die Entwicklung von ML-Modellen sind häufig dateibasierte Ein- und Ausgaben erforderlich. Serverless für Apache Spark greift auf diese Dateien in Cloud Storage zu.
Spark-Notebook-Code entwickeln
Nachdem Sie die Dataproc JupyterLab-Erweiterung installiert haben, können Sie Jupyter-Notebooks über die Seite Launcher in JupyterLab starten, um Anwendungscode zu entwickeln.
PySpark- und Python-Code entwickeln
Serverless für Apache Spark und Dataproc auf Compute Engine-Clustern unterstützen PySpark-Kernel. Dataproc in Compute Engine unterstützt auch Python-Kernel.
SQL-Code entwickeln
Wenn Sie ein PySpark-Notebook öffnen möchten, um SQL-Code zu schreiben und auszuführen, klicken Sie auf der Seite Launcher von JupyterLab im Bereich Serverless for Apache Spark Notebooks oder Dataproc Cluster Notebook auf die Karte des PySpark-Kernels.
Spark SQL-Magic:Da der PySpark-Kernel, mit dem Serverless for Apache Spark-Notebooks gestartet werden, mit Spark SQL-Magic vorab geladen wird, können Sie anstelle von spark.sql('SQL STATEMENT').show() zum Umschließen Ihrer SQL-Anweisung %%sparksql magic oben in eine Zelle eingeben und dann Ihre SQL-Anweisung in die Zelle eingeben.
BigQuery SQL:Mit dem BigQuery Spark-Connector kann in Ihrem Notebook-Code Daten aus BigQuery-Tabellen geladen, Analysen in Spark durchgeführt und die Ergebnisse in eine BigQuery-Tabelle geschrieben werden.
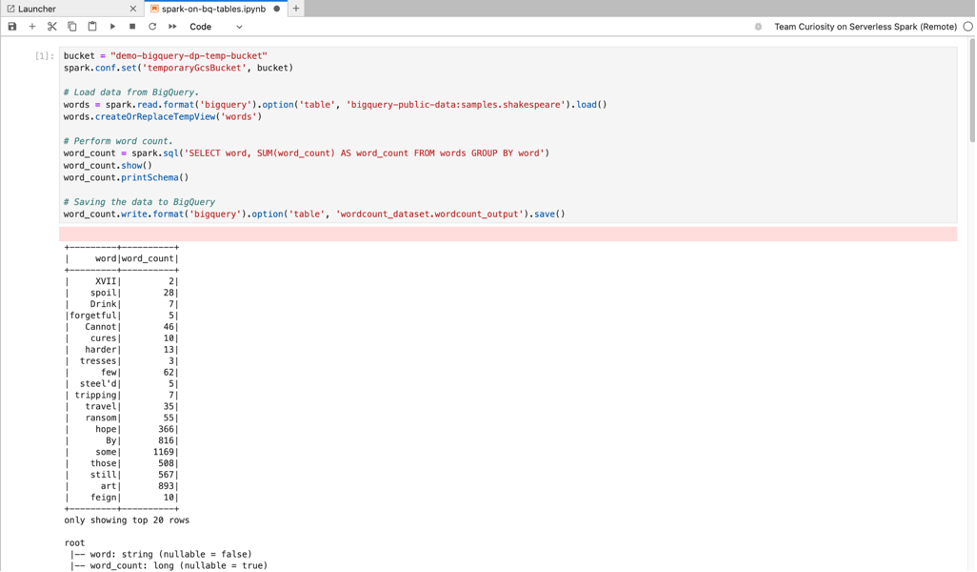
Die Serverless for Apache Spark-Runtimes 2.2und höher enthalten den BigQuery Spark-Connector.
Wenn Sie eine frühere Laufzeit zum Starten von Serverless for Apache Spark-Notebooks verwenden, können Sie den Spark BigQuery-Connector installieren, indem Sie die folgende Spark-Property zu Ihrer Serverless for Apache Spark-Laufzeitvorlage hinzufügen:
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Scala-Codeentwicklung
Dataproc in Compute Engine-Cluster, die mit Image-Versionen 2.0 und höher erstellt wurden, enthalten Apache Toree, einen Scala-Kernel für die Jupyter Notebook-Plattform, der interaktiven Zugriff auf Spark bietet.
Code mit der Visual Studio Code-Erweiterung entwickeln
Mit der Google Cloud Visual Studio Code (VS Code)-Erweiterung können Sie Folgendes tun:
Die Visual Studio Code-Erweiterung ist kostenlos. Ihnen werden jedoch alleGoogle Cloud -Dienste in Rechnung gestellt, die Sie verwenden, einschließlich Dataproc, Serverless for Apache Spark und Cloud Storage-Ressourcen.
VS Code mit BigQuery verwenden: Sie können auch VS Code mit BigQuery verwenden, um Folgendes zu tun:
Hinweise
Google Cloud -Erweiterung installieren
Das Symbol Google Cloud Code ist jetzt in der Aktivitätsleiste von VS Code sichtbar.
Erweiterung konfigurieren
Serverless for Apache Spark-Notebooks entwickeln
Serverless for Apache Spark-Ressourcen erstellen und verwalten
Dataset Explorer
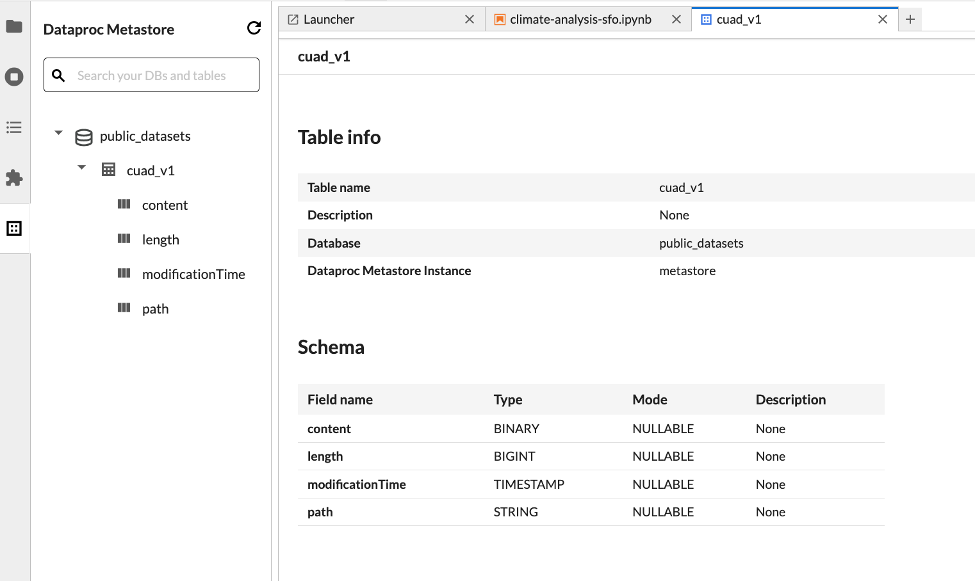
Mit dem JupyterLab-Datensatz-Explorer können Sie Datasets im BigLake Metastore ansehen.
Klicken Sie in der Seitenleiste auf das Symbol, um den JupyterLab-Datensatz-Explorer zu öffnen.
Sie können im Dataset Explorer nach einer Datenbank, Tabelle oder Spalte suchen. Klicken Sie auf einen Datenbank-, Tabellen- oder Spaltennamen, um die zugehörigen Metadaten aufzurufen.
Code bereitstellen
Nachdem Sie die Dataproc JupyterLab-Erweiterung installiert haben, können Sie JupyterLab für folgende Aufgaben verwenden:
Notebook-Ausführung in Cloud Composer planen
Führen Sie die folgenden Schritte aus, um Ihren Notebook-Code in Cloud Composer zu planen, damit er als Batchjob in Serverless for Apache Spark oder in einem Dataproc on Compute Engine-Cluster ausgeführt wird.
Batchjob an Google Cloud Serverless für Apache Spark senden
Batch-Job an einen Dataproc in Compute Engine-Cluster senden
Ressourcen ansehen und verwalten
Nachdem Sie die Dataproc JupyterLab-Erweiterung installiert haben, können Sie Google Cloud Serverless für Apache Spark und Dataproc in Compute Engine Google Cloud im Abschnitt Dataproc Jobs and Sessions (Dataproc-Jobs und -Sitzungen) auf der JupyterLab-Seite Launcher (Launcher) ansehen und verwalten.
Klicken Sie auf den Abschnitt Dataproc-Jobs und -Sitzungen, um die Karten Cluster und Serverless aufzurufen.
So rufen Sie Google Cloud Serverless for Apache Spark-Sitzungen auf und verwalten sie:
So rufen Sie Google Cloud Serverless for Apache Spark-Batches auf und verwalten sie:
So rufen Sie Dataproc in Compute Engine-Cluster auf und verwalten sie:
So rufen Sie Dataproc in Compute Engine-Jobs auf und verwalten sie: