이 문서에서는 Apache Spark용 서버리스 일괄 워크로드를 모니터링하고 문제를 해결하는 데 사용할 수 있는 도구와 파일을 설명합니다.
Google Cloud 콘솔에서 워크로드 문제 해결
일괄 작업이 실패하거나 성능이 저하되면 먼저 Google Cloud 콘솔의 배치 페이지에서 배치 세부정보 페이지를 여는 것이 좋습니다.
요약 탭 사용: 문제 해결 허브
일괄 세부정보 페이지가 열릴 때 기본적으로 선택되는 요약 탭에는 일괄 처리 상태를 빠르게 초기 평가하는 데 도움이 되는 중요한 측정항목과 필터링된 로그가 표시됩니다. 이 초기 평가 후에는 일괄 세부정보 페이지에 표시된 Spark UI, 로그 탐색기, Gemini Cloud Assist와 같은 전문 도구를 사용하여 심층 분석을 실행할 수 있습니다.
일괄 측정항목 주요 정보
일괄 세부정보 페이지의 요약 탭에는 중요한 일괄 워크로드 측정항목 값을 표시하는 차트가 포함됩니다. 측정항목 차트는 완료된 후에 채워지며 리소스 경합, 데이터 비대칭, 메모리 부족과 같은 잠재적인 문제를 시각적으로 나타냅니다.
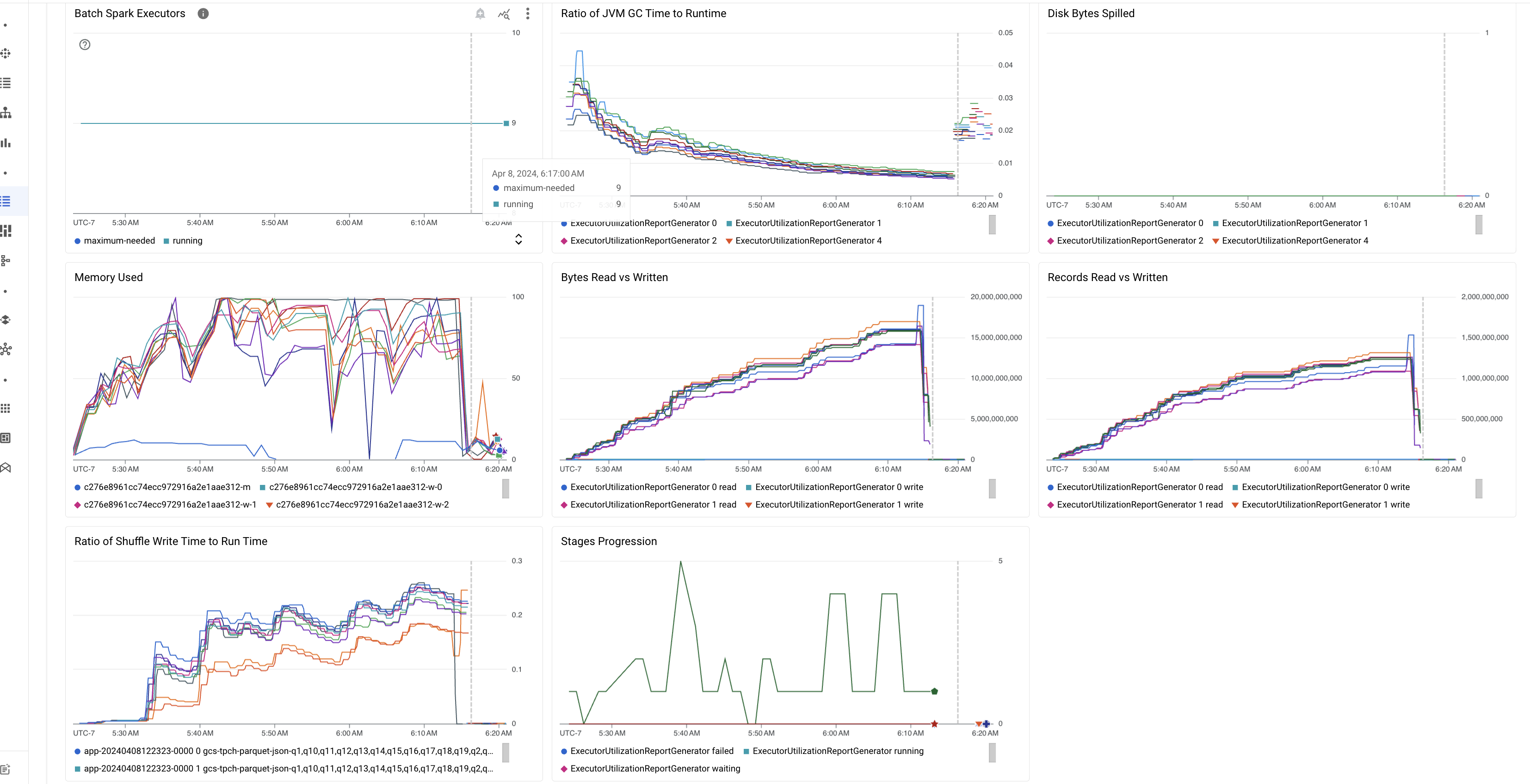
다음 표는 Google Cloud 콘솔의 일괄 세부정보 페이지에 표시되는 Spark 워크로드 측정항목을 나열하고 측정항목 값이 워크로드 상태 및 성능에 대한 통계를 제공하는 방법을 설명합니다.
| 측정항목 | 표시되는 정보 |
|---|---|
| 실행자 수준의 측정항목 | |
| 런타임 대비 JVM GC 시간의 비율 | 이 측정항목은 실행자당 런타임 대비 JVM GC(가비지 컬렉션) 시간의 비율을 보여줍니다. 비율이 높으면 특정 실행자 또는 비효율적인 데이터 구조에서 실행되는 태스크 내에서 메모리 누수가 발생해 객체 이탈이 늘어날 수 있습니다. |
| 분산된 디스크 바이트 | 이 측정항목은 여러 실행자 간에 분산된 총 디스크 바이트 수를 보여줍니다. 실행자에 분산된 많은 디스크 바이트가 표시되는 경우 이는 데이터 편향을 나타낼 수 있습니다. 이 측정항목이 시간이 지나면서 증가한다면 이는 메모리 부족 또는 메모리 누수가 발생한 단계가 있음을 나타낼 수 있습니다. |
| 읽고 쓴 바이트 | 이 측정항목은 실행자당 작성한 바이트 수와 읽은 바이트 수를 비교하여 보여줍니다. 읽거나 쓰는 바이트 수가 크게 불일치할 경우 복제된 조인이 특정 실행자의 데이터 증폭으로 이어지는 시나리오를 나타낼 수 있습니다. |
| 읽고 쓴 레코드 | 이 측정항목은 실행자당 읽은 레코드 수와 쓴 레코드 수를 보여줍니다. 읽은 레코드가 많은데 쓴 레코드 수가 적다면 특정 실행자의 처리 로직에 병목 현상이 발생하여 대기 중에 레코드를 읽음을 나타낼 수 있습니다. 읽기와 쓰기에 지속적으로 지연되는 실행자는 해당 노드의 리소스 경합 또는 실행자별 코드 비효율성을 나타낼 수 있습니다. |
| 셔플 쓰기 시간 대비 런타임 비율 | 이 측정항목은 전체 런타임과 비교하여 셔플 런타임에 실행자가 소비한 시간을 보여줍니다. 일부 실행자에서 이 값이 높다면 데이터 편향 또는 비효율적인 데이터 직렬화를 나타낼 수 있습니다. Spark UI에서 셔플 쓰기 시간이 긴 단계를 식별할 수 있습니다. 이러한 단계 내에서 평균 완료 시간보다 더 오래 걸리는 이상치 태스크를 찾습니다. 셔플 쓰기 시간이 높은 실행기에도 디스크 I/O 활동이 높은지 확인합니다. 더 효율적인 직렬화와 추가 파티셔닝 단계가 도움이 될 수 있습니다. 레코드 읽기에 비해 레코드 쓰기가 매우 크다면 비효율적인 조인이나 잘못된 변환으로 인해 의도하지 않은 데이터 중복이 발생한 것일 수 있습니다. |
| 애플리케이션 수준의 측정항목 | |
| 단계 진행 | 이 측정항목은 실패, 대기, 실행 중인 단계의 수를 보여줍니다. 실패하거나 대기 중인 단계가 많으면 데이터 편향이 있을 수 있습니다. 데이터 파티션을 확인하고 Spark UI의 단계 탭을 사용하여 단계 실패 이유를 디버그합니다. |
| 일괄 Spark 실행자 | 이 측정항목은 필요한 실행자 수와 실행 중인 실행자 수를 보여줍니다. 필수 실행자와 실행 중인 실행자의 차이가 크다면 자동 확장 문제를 나타낼 수 있습니다. |
| VM 수준의 측정항목 | |
| 사용된 메모리 | 이 측정항목은 사용 중인 VM 메모리의 비율을 보여줍니다. 마스터 비율이 높으면 드라이버에 메모리 부족이 발생한 것일 수 있습니다. 다른 VM 노드의 경우 비율이 높으면 실행자의 메모리가 부족하여 디스크 유출이 증가하고 워크로드 런타임이 느려질 수 있음을 의미합니다. Spark UI를 사용하여 실행자를 분석하여 GC 시간이 길고 태스크 실패가 많은지 확인합니다. 또한 대규모 데이터 세트 캐싱 및 불필요한 변수 브로드캐스트를 위해 Spark 코드를 디버그합니다. |
작업 로그
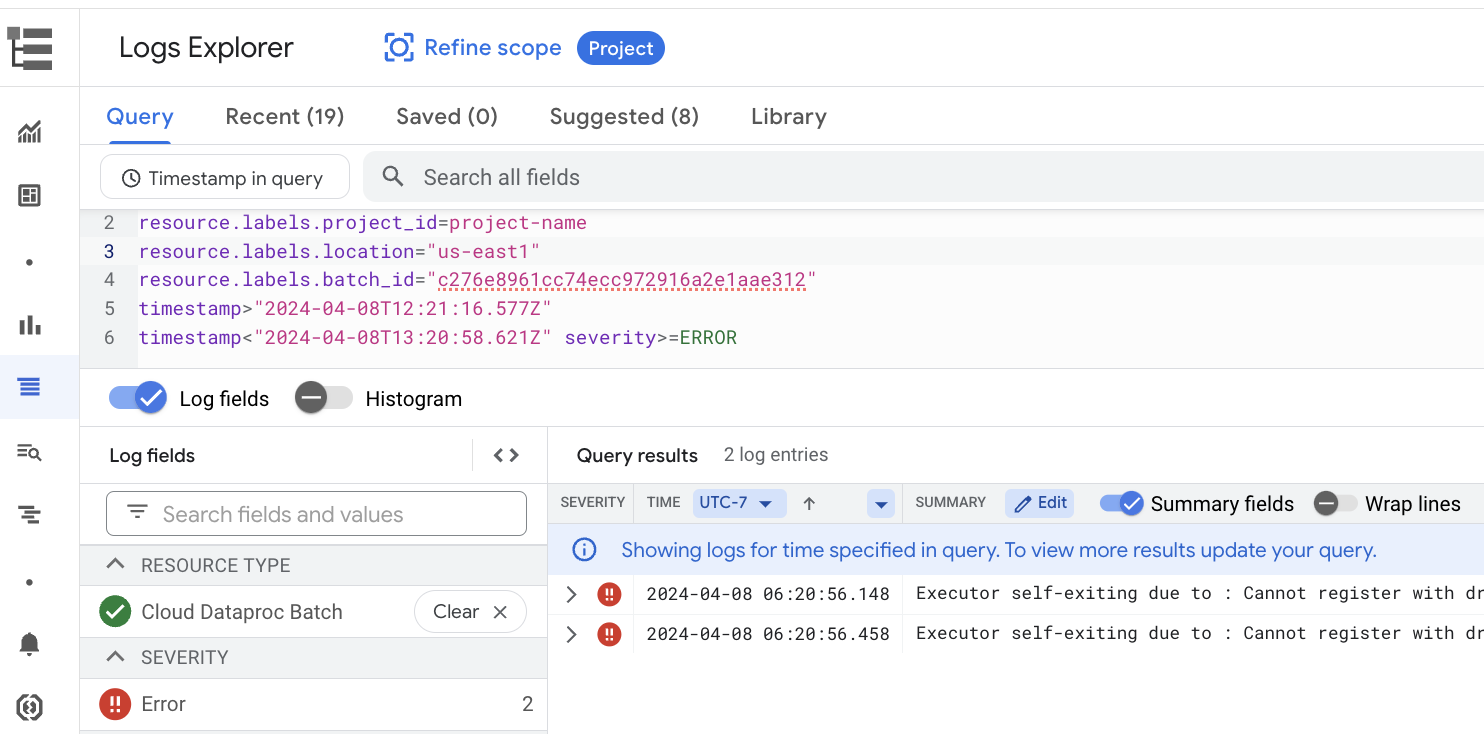
일괄 세부정보 페이지에는 작업 (일괄 워크로드) 로그에서 필터링된 경고와 오류가 나열된 작업 로그 섹션이 포함되어 있습니다. 이 기능을 사용하면 광범위한 로그 파일을 수동으로 파싱하지 않고도 심각한 문제를 빠르게 식별할 수 있습니다. 드롭다운 메뉴에서 로그 심각도 (예: Error)를 선택하고 텍스트 필터를 추가하여 결과를 좁힐 수 있습니다. 자세한 분석을 수행하려면 로그 탐색기에서 보기 아이콘을 클릭하여 로그 탐색기에서 선택한 일괄 로그를 엽니다.
예를 들어 Google Cloud 콘솔의 일괄 세부정보 페이지에 있는 심각도 선택기에서 Errors를 선택하면 로그 탐색기가 열립니다.
Spark UI
Spark UI는 Apache Spark용 서버리스 일괄 워크로드에서 Apache Spark 실행 세부정보를 수집합니다. Spark UI 기능은 기본적으로 사용 설정되어 있으며 무료로 사용 가능합니다.
Spark UI 기능에서 수집한 데이터는 90일 동안 보관됩니다. 이 웹 인터페이스를 사용하면 영구 기록 서버를 만들지 않고도 Spark 워크로드를 모니터링하고 디버그할 수 있습니다.
필요한 Identity and Access Management 권한 및 역할
일괄 워크로드에서 Spark UI 기능을 사용하려면 다음 권한이 필요합니다.
데이터 수집 권한:
dataproc.batches.sparkApplicationWrite. 이 권한은 일괄 워크로드를 실행하는 서비스 계정에 부여되어야 합니다. 이 권한은 Serverless for Apache Spark에서 기본적으로 사용하는 Compute Engine 기본 서비스 계정에 자동으로 부여되는Dataproc Worker역할에 포함되어 있습니다 (Serverless for Apache Spark 서비스 계정 참고). 그러나 일괄 워크로드에 커스텀 서비스 계정을 지정하는 경우에는 일반적으로 서비스 계정에 DataprocWorker역할을 부여하여 해당 서비스 계정에dataproc.batches.sparkApplicationWrite권한을 추가해야 합니다.Spark UI 액세스 권한:
dataproc.batches.sparkApplicationRead.Google Cloud 콘솔에서 Spark UI에 액세스하려면 사용자에게 이 권한을 부여해야 합니다. 이 권한은Dataproc Viewer,Dataproc Editor,Dataproc Administrator역할에 포함되어 있습니다. Google Cloud 콘솔에서 Spark UI를 열려면 이러한 역할 중 하나가 있거나 이 권한이 포함된 커스텀 역할이 있어야 합니다.
Spark UI 열기
Spark UI 페이지는 Google Cloud 콘솔 일괄 워크로드에서 사용할 수 있습니다.
Apache Spark용 Dataproc Serverless 대화형 세션 페이지로 이동합니다.
일괄 ID를 클릭하여 일괄 세부정보 페이지를 엽니다.
상단 메뉴에서 Spark UI 보기를 클릭합니다.
다음 경우에는 Spark UI 보기 버튼이 사용 중지됩니다.
- 필수 권한이 부여되지 않은 경우
- 일괄 세부정보 페이지에서 Spark UI 사용 설정 체크박스를 선택 해제하는 경우
- 배치 워크로드를 제출할 때
spark.dataproc.appContext.enabled속성을false로 설정하는 경우
Gemini Cloud Assist를 사용한 AI 기반 조사 (미리보기)
개요
Gemini Cloud Assist 조사 미리보기 기능은 Gemini 고급 기능을 사용하여 Apache Spark용 서버리스 일괄 워크로드를 만들고 실행하는 데 도움을 줍니다. 이 기능은 실패한 워크로드와 느리게 실행되는 워크로드를 분석하여 근본 원인을 파악하고 수정사항을 추천합니다. 이를 통해 검토, 저장, Google Cloud 지원팀과의 공유가 가능한 지속적인 분석이 생성되어 협업을 촉진하고 문제 해결을 가속화할 수 있습니다.
기능
이 기능을 사용하여 Google Cloud 콘솔에서 조사를 만드세요.
- 조사를 만들기 전에 문제에 자연어 컨텍스트 설명을 추가합니다.
- 실패한 일괄 워크로드와 느린 일괄 워크로드를 분석합니다.
- 추천 수정사항을 통해 문제의 근본 원인을 파악합니다.
- 전체 조사 컨텍스트가 첨부된 지원 케이스를 만듭니다. Google Cloud
시작하기 전에
조사 기능을 사용하려면 Google Cloud 프로젝트에서 Gemini Cloud Assist API를 사용 설정하세요.
조사 시작하기
조사를 시작하려면 다음 중 하나를 수행하세요.
옵션 1: Google Cloud 콘솔에서 배치 목록 페이지로 이동합니다.
Failed상태의 일괄 처리에는 Gemini의 통계 열에 조사 버튼이 표시됩니다. 버튼을 클릭하여 조사를 시작합니다.
옵션 2: 일괄 워크로드의 일괄 세부정보 페이지를 열어 조사합니다.
Succeeded및Failed일괄 워크로드 모두의 경우 요약 탭의 상태 개요 섹션에 Gemini의 통계 패널에 조사 버튼이 표시됩니다. 버튼을 클릭하여 조사를 시작합니다.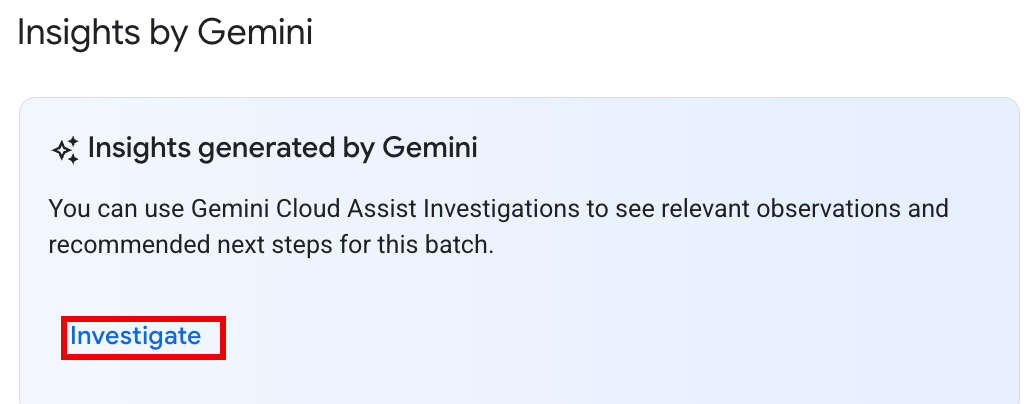
조사 버튼 텍스트는 조사 상태를 나타냅니다.
- 조사: 이 batch_details에 대해 실행된 조사가 없습니다. 버튼을 클릭하여 조사를 시작합니다.
- 조사 보기: 조사가 완료되었습니다. 버튼을 클릭하여 결과를 확인합니다.
- 조사 중: 조사가 진행 중입니다.
조사 결과 해석
조사가 완료되면 조사 세부정보 페이지가 열립니다. 이 페이지에는 다음과 같은 섹션으로 구성된 전체 Gemini 분석이 포함되어 있습니다.
- 문제: 조사 중인 일괄 워크로드의 세부정보가 자동으로 채워진 축소된 섹션입니다.
- 관련 관찰: Gemini가 로그 및 측정항목 분석 중에 발견한 주요 데이터 포인트와 비정상치를 나열하는 접힌 섹션입니다.
- 가설: 기본 섹션으로, 기본적으로 펼쳐져 있습니다.
관찰된 문제의 잠재적 근본 원인 목록을 표시합니다. 각 가설에는 다음이 포함됩니다.
- 개요: 가능한 원인에 대한 설명입니다(예: '셔플 쓰기 시간이 길고 작업이 기울어질 수 있음').
- 권장 수정사항: 잠재적인 문제를 해결하기 위한 실행 가능한 단계 목록입니다.
조치 취하기
가설과 추천을 검토한 후 다음 단계를 따르세요.
추천 수정사항을 작업 구성 또는 코드에 하나 이상 적용한 다음 작업을 다시 실행합니다.
패널 상단의 좋아요 또는 싫어요 아이콘을 클릭하여 조사 결과의 유용성에 대한 의견을 제공하세요.
조사 검토 및 에스컬레이션
이전에 실행한 조사의 결과를 검토하려면 Cloud Assist 조사 페이지에서 조사 이름을 클릭하여 조사 세부정보 페이지를 엽니다.
추가 지원이 필요한 경우 Google Cloud 지원 케이스를 여세요. 이 프로세스는 지원 엔지니어에게 Gemini가 생성한 관찰 결과와 가설을 비롯해 이전에 수행한 조사에 관한 전체 컨텍스트를 제공합니다. 이 컨텍스트 공유를 통해 지원팀과의 왕복 통신이 크게 줄어들어 케이스 해결 속도가 빨라집니다.
조사에서 지원 케이스를 만들려면 다음 단계를 따르세요.
조사 세부정보 페이지에서 지원 요청을 클릭합니다.
미리보기 상태 및 가격
공개 프리뷰 기간에는 Gemini Cloud Assist 조사에 요금이 부과되지 않습니다. 이 기능이 정식 버전(GA)으로 출시되면 요금이 청구됩니다.
정식 버전 출시 후 가격 책정에 대한 자세한 내용은 Gemini Cloud Assist 가격 책정을 참고하세요.
Gemini에게 물어보기 프리뷰 (2025년 9월 22일 지원 종료)
Gemini에게 물어보기 미리보기 기능은 Gemini에게 물어보기 버튼을 통해 Google Cloud 콘솔의 일괄 및 일괄 세부정보 페이지에 대한 유용한 정보에 원클릭으로 액세스할 수 있도록 했습니다. 이 기능은 워크로드 로그 및 측정항목을 기반으로 오류, 비정상, 잠재적인 성능 개선사항의 요약을 생성했습니다.
2025년 9월 22일에 'Gemini에게 물어보기' 프리뷰가 지원 중단된 후에도 사용자는 Gemini Cloud Assist 조사 기능을 사용하여 AI 기반 지원을 계속 받을 수 있습니다.
중요: 중단 없는 문제 해결 AI 지원을 위해 2025년 9월 22일 전에 Gemini Cloud Assist 조사를 사용 설정하는 것이 좋습니다.
Apache Spark용 서버리스 로그
Logging은 Apache Spark용 서버리스에서 기본적으로 사용 설정되며 워크로드 로그는 워크로드가 완료된 후에도 유지됩니다. Apache Spark용 서버리스는 Cloud Logging에서 워크로드 로그를 수집합니다.
로그 탐색기의 Cloud Dataproc Batch 리소스에서 Apache Spark용 서버리스 로그에 액세스할 수 있습니다.
Apache Spark용 서버리스 로그 쿼리
Google Cloud 콘솔의 로그 탐색기에는 일괄 워크로드 로그를 검사하는 쿼리를 빌드하는 데 도움이 되는 쿼리 창이 있습니다. 일괄 워크로드 로그를 검사하는 쿼리를 빌드하는 단계는 다음과 같습니다.
- 현재 프로젝트가 선택됩니다. 프로젝트 범위 세분화를 클릭하여 다른 프로젝트를 선택할 수 있습니다.
일괄 로그 쿼리를 정의합니다.
필터 메뉴를 사용하여 일괄 워크로드를 필터링합니다.
모든 리소스에서 Cloud Dataproc 일괄 리소스를 선택합니다.
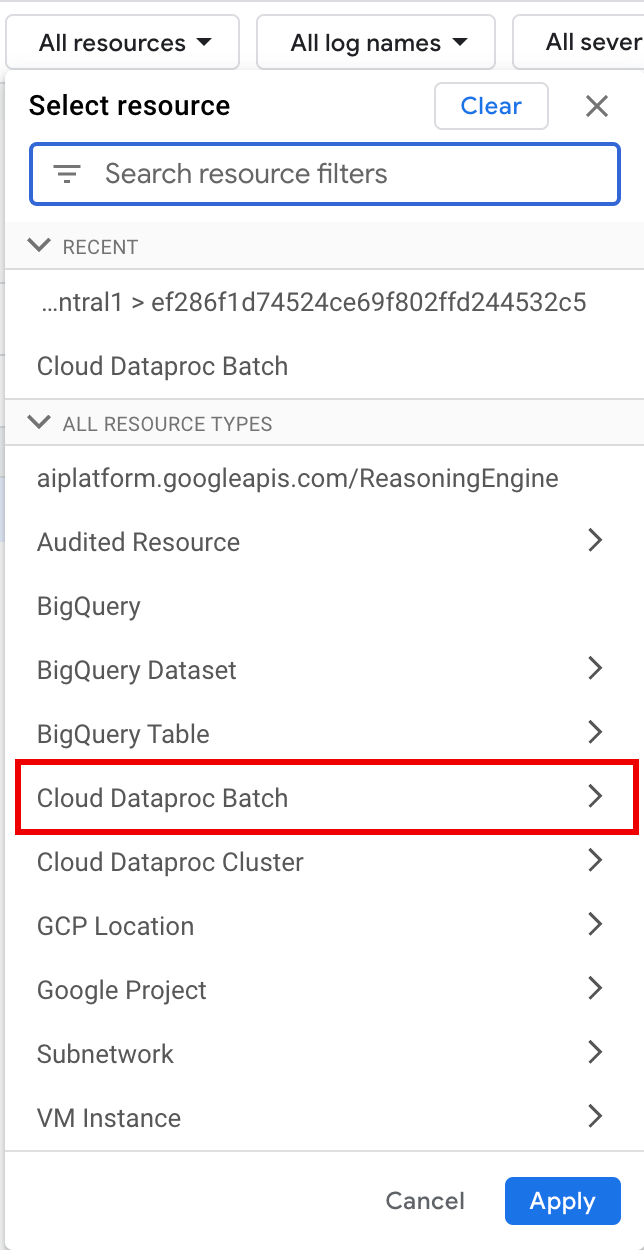
리소스 선택 패널에서 일괄 LOCATION를 선택한 다음 BATCH ID를 선택합니다. 이러한 일괄 파라미터는 Google Cloud 콘솔의 Dataproc 배치 페이지에 나열됩니다.
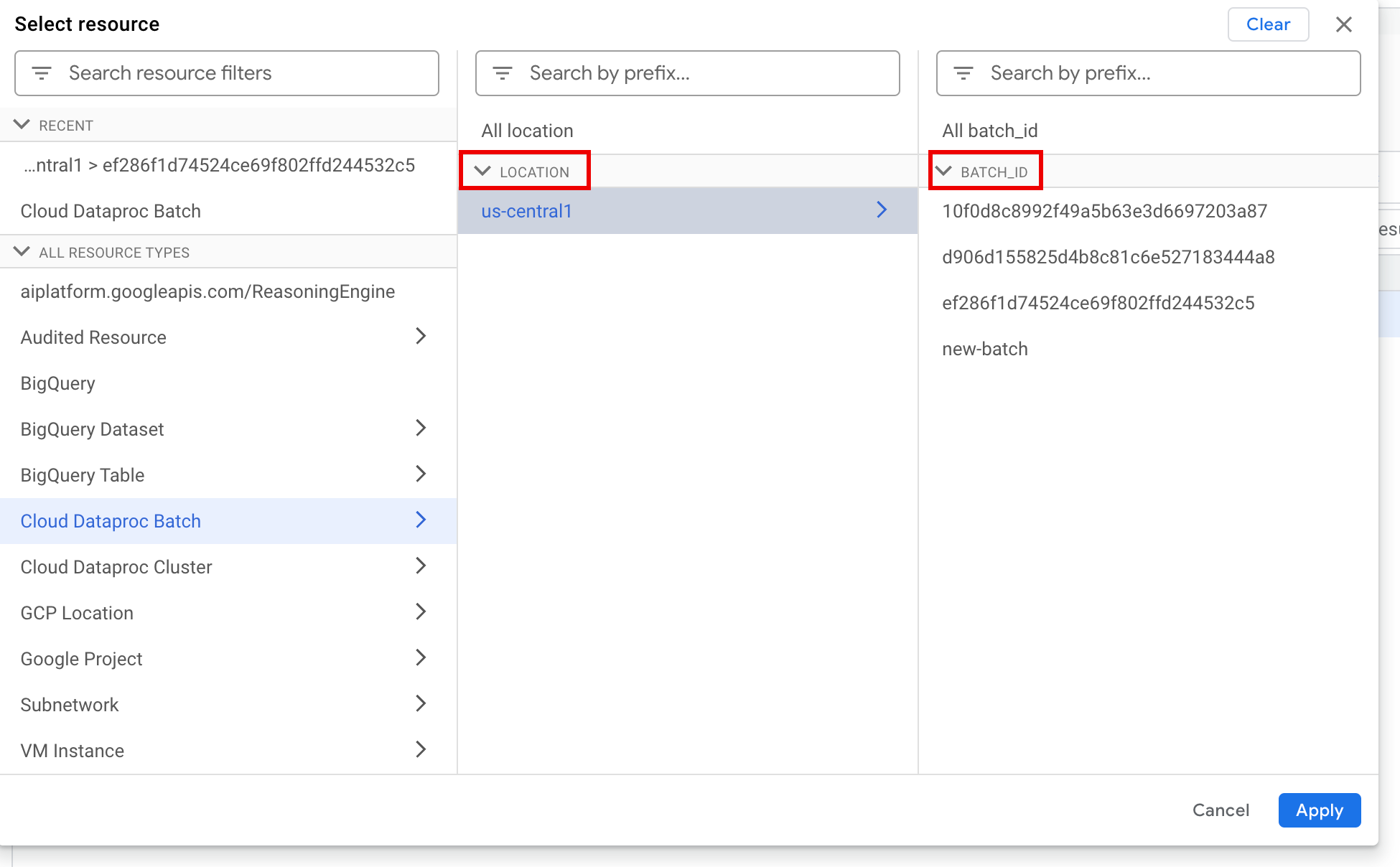
적용을 클릭합니다.
로그 이름 선택에서 로그 이름 검색 상자에
dataproc.googleapis.com을 입력하여 쿼리할 로그 유형을 제한합니다. 나열된 로그 파일 이름을 하나 이상 선택합니다.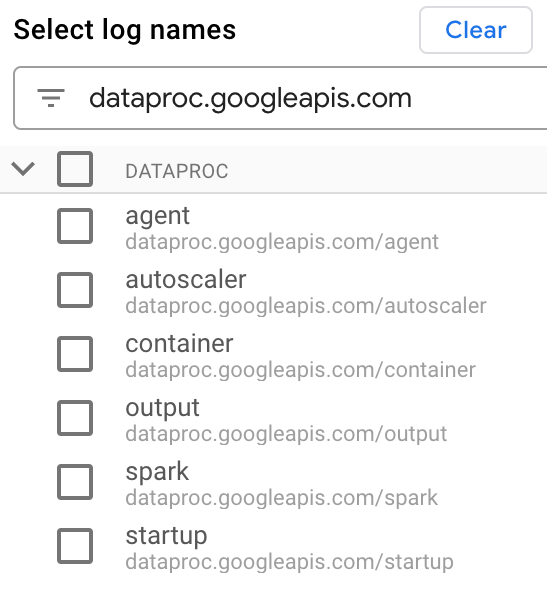
쿼리 편집기를 사용하여 VM별 로그를 필터링합니다.
다음 예시와 같이 리소스 유형 및 VM 리소스 이름을 지정합니다.
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID: 배치 UUID는 Google Cloud 콘솔의 배치 세부정보 페이지에 표시됩니다. 이 페이지는 배치 페이지에서 배치 ID를 클릭할 때 열립니다.
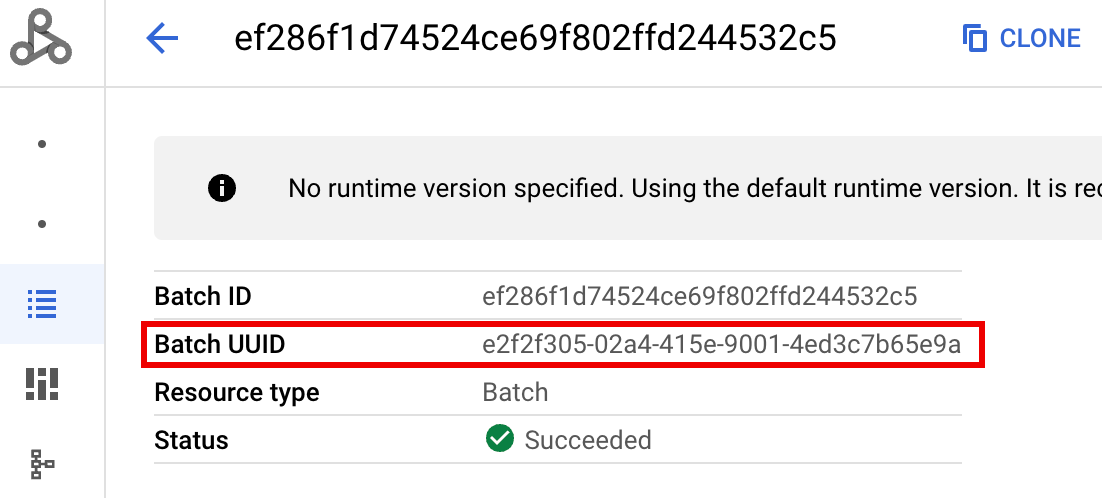
일괄 로그에는 VM 리소스 이름에 일괄 UUID도 나열됩니다. 다음은 일괄 driver.log의 예시입니다.

- BATCH_UUID: 배치 UUID는 Google Cloud 콘솔의 배치 세부정보 페이지에 표시됩니다. 이 페이지는 배치 페이지에서 배치 ID를 클릭할 때 열립니다.
쿼리 실행을 클릭합니다.
Apache Spark용 서버리스 로그 유형 및 샘플 쿼리
다음 목록에서는 다양한 Apache Spark용 서버리스 로그 유형을 설명하고 각 로그 유형에 대한 샘플 로그 탐색기 쿼리를 제공합니다.
dataproc.googleapis.com/output: 이 로그 파일에는 일괄 워크로드 출력이 포함되어 있습니다. Apache Spark용 서버리스는 일괄 출력을output네임스페이스로 스트리밍하고 파일 이름을JOB_ID.driver.log로 설정합니다.출력 로그의 샘플 로그 탐색기 쿼리:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark:spark네임스페이스는 Dataproc 클러스터 마스터 및 작업자 VM에서 실행되는 데몬 및 실행자의 Spark 로그를 집계합니다. 각 로그 항목에는 다음과 같이 로그 소스를 식별하는master,worker또는executor구성요소 라벨이 포함됩니다.executor: 사용자 코드 실행자의 로그입니다. 일반적으로 이러한 로그는 분산 로그입니다.master: Spark 독립형 리소스 관리자 마스터의 로그로, Compute Engine YARNResourceManager로그의 Dataproc과 유사합니다.worker: Spark 독립형 리소스 관리자 작업자의 로그로, Compute Engine YARNNodeManager로그의 Dataproc과 유사합니다.
spark네임스페이스의 모든 로그에 대한 샘플 로그 탐색기 쿼리:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
spark네임스페이스의 Spark 독립형 구성요소 로그에 대한 샘플 로그 탐색기 쿼리:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup:startup네임스페이스에는 일괄(클러스터) 시작 로그가 포함됩니다. 모든 초기화 스크립트 로그가 포함됩니다. 구성요소는 다음 예시와 같이 라벨로 식별됩니다.startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent:agent네임스페이스는 Dataproc 에이전트 로그를 집계합니다. 각 로그 항목에는 로그 소스를 식별하는 파일 이름 라벨이 포함되어 있습니다.지정된 작업자 VM에서 생성된 에이전트 로그에 대한 샘플 로그 탐색기 쿼리:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler:autoscaler네임스페이스는 Apache Spark용 서버리스 자동 확장 처리 로그를 집계합니다.지정된 작업자 VM에서 생성된 에이전트 로그에 대한 샘플 로그 탐색기 쿼리:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
자세한 내용은 Dataproc 로그를 참조하세요.
Apache Spark용 서버리스 감사 로그에 대한 자세한 내용은 Dataproc 감사 로깅을 참고하세요.
워크로드 측정항목
Apache Spark용 서버리스는 Google Cloud 콘솔의 측정항목 탐색기 또는 일괄 세부정보 페이지에서 볼 수 있는 일괄 및 Spark 측정항목을 제공합니다.
일괄 측정항목
Dataproc batch 리소스 측정항목은 일괄 실행자 수와 같은 일괄 리소스에 대한 통계를 제공합니다. 일괄 측정항목에는 dataproc.googleapis.com/batch라는 프리픽스가 붙습니다.
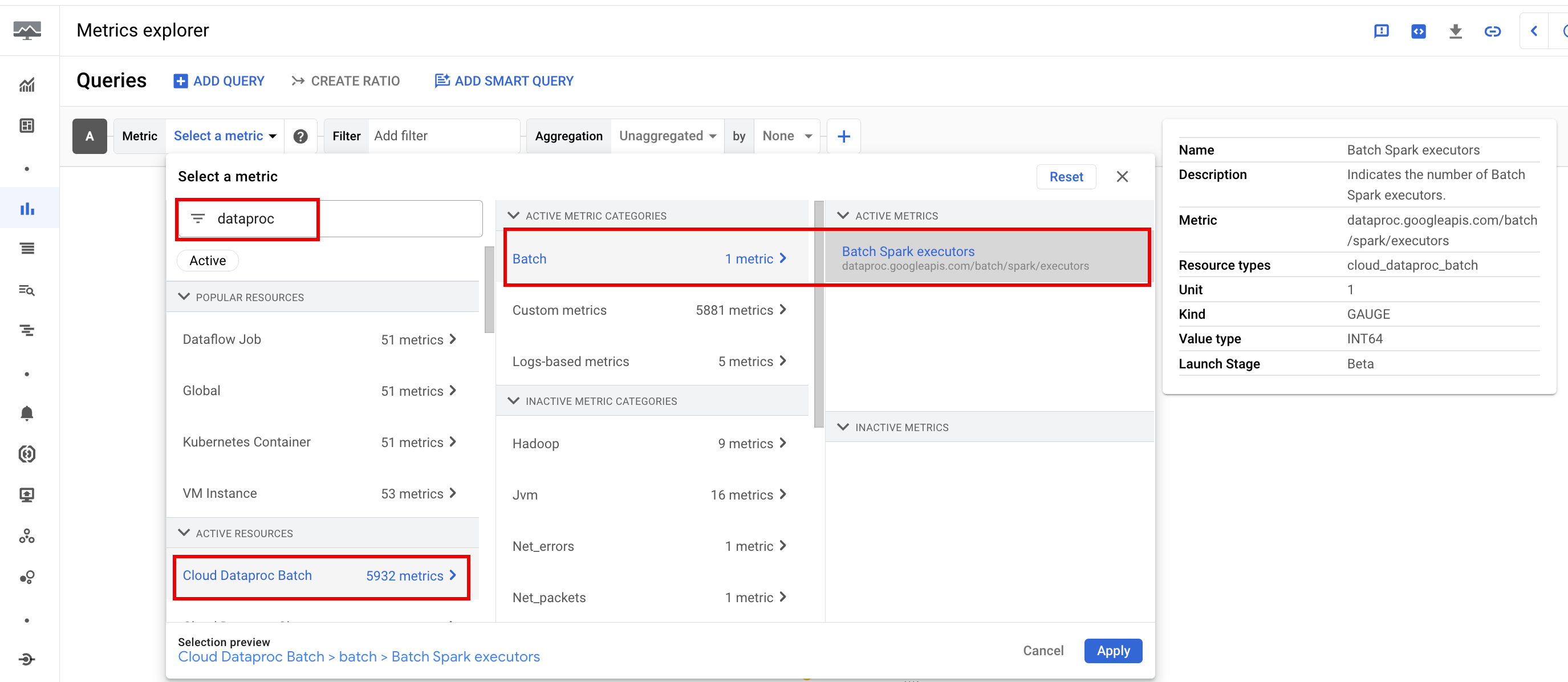
Spark 측정항목
기본적으로 Apache Spark용 서버리스는 Spark 측정항목 수집 속성을 사용하여 하나 이상의 Spark 측정항목 수집을 사용 중지하거나 재정의하지 않는 한 사용 가능한 Spark 측정항목의 수집을 사용 설정합니다.
사용 가능한 Spark 측정항목에는 Spark 드라이버 및 실행자 측정항목, 시스템 측정항목이 포함됩니다. 사용 가능한 Spark 측정항목에는 custom.googleapis.com/ 프리픽스가 추가됩니다.
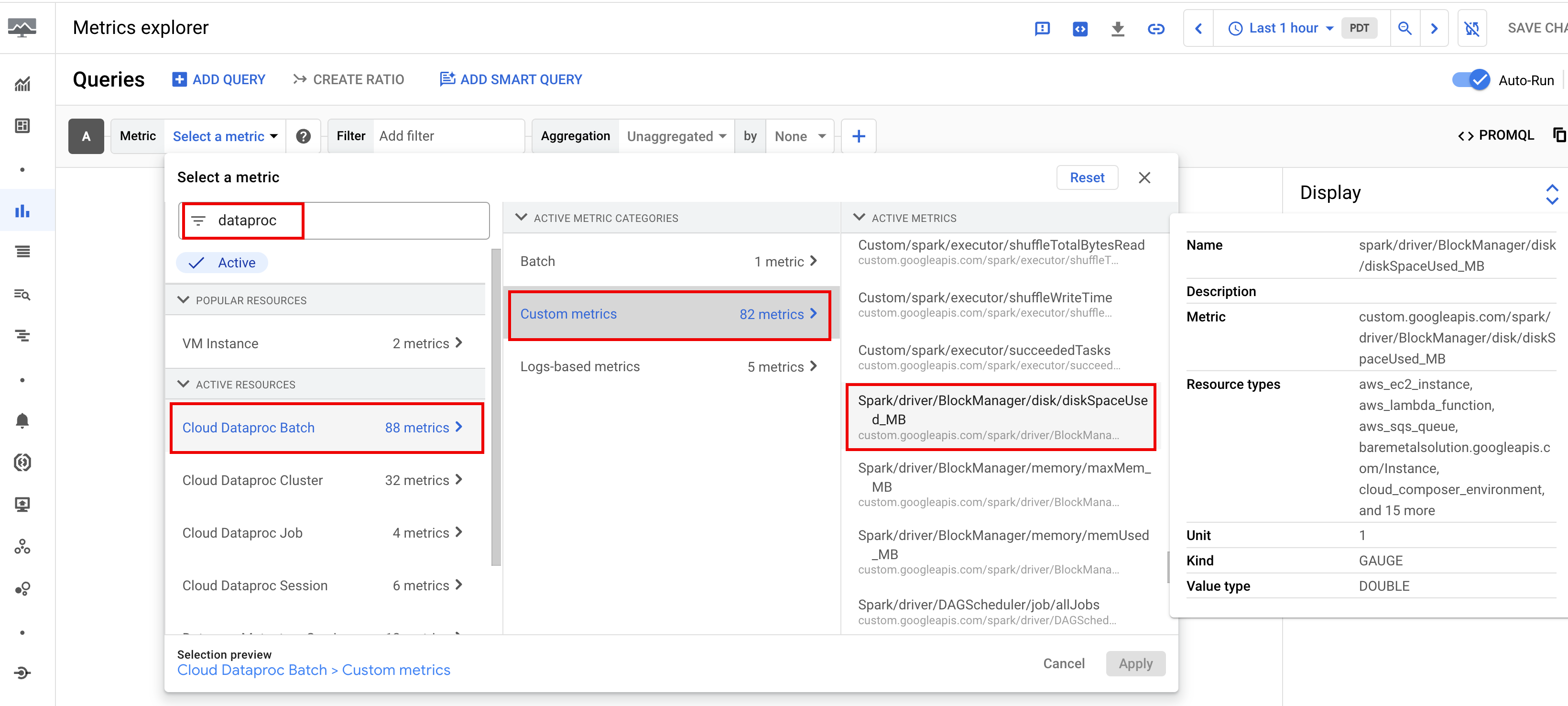
측정항목 알림 설정
Dataproc 측정항목 알림을 만들어 워크로드 문제에 대한 알림을 받을 수 있습니다.
차트 만들기
Google Cloud 콘솔의 측정항목 탐색기를 사용하여 워크로드 측정항목을 시각화하는 차트를 만들 수 있습니다. 예를 들어 disk:bytes_used를 표시하는 차트를 만든 다음 batch_id로 필터링할 수 있습니다.
Cloud Monitoring
Monitoring은 워크로드 메타데이터와 측정항목을 사용하여 Apache Spark용 서버리스 워크로드의 상태와 성능에 대한 통계를 제공합니다. 워크로드 측정항목에는 Spark 측정항목, 일괄 측정항목, 작업 측정항목이 포함됩니다.
Google Cloud 콘솔에서 Cloud Monitoring을 사용하여 측정항목을 탐색하고, 차트를 추가하고, 대시보드를 만들고, 알림을 만들 수 있습니다.
대시보드 만들기
여러 프로젝트 및 다양한 Google Cloud 제품의 측정항목을 사용하여 워크로드를 모니터링하는 대시보드를 만들 수 있습니다. 자세한 내용은 커스텀 대시보드 만들기 및 관리를 참고하세요.
영구 기록 서버
Apache Spark용 서버리스는 워크로드를 실행하는 데 필요한 컴퓨팅 리소스를 만들고 해당 리소스에서 워크로드를 실행한 후 워크로드가 완료되면 리소스를 삭제합니다. 워크로드가 완료된 후에 워크로드 측정항목 및 이벤트가 지속되지 않습니다. 하지만 영구 기록 서버(PHS)를 사용하여 Cloud Storage의 워크로드 애플리케이션 기록(이벤트 로그)을 보관할 수 있습니다.
일괄 워크로드에서 PHS를 사용하려면 다음 단계를 따르세요.
워크로드를 제출할 때 PHS를 지정합니다.
구성요소 게이트웨이를 사용하여 PHS에 연결하여 애플리케이션 세부정보, 스케줄러 단계, 태스크 수준 세부정보, 환경 및 실행자 정보를 확인합니다.
자동 조정
- Apache Spark용 서버리스에 자동 조정 사용 설정: Google Cloud 콘솔, gcloud CLI 또는 Dataproc API를 사용하여 반복되는 각 Spark 일괄 워크로드를 제출할 때 Apache Spark용 서버리스에 자동 조정을 사용 설정할 수 있습니다.
콘솔
반복되는 각 Spark 일괄 워크로드에 자동 조정을 사용 설정하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 Dataproc 배치 페이지로 이동합니다.
일괄 워크로드를 만들려면 만들기를 클릭합니다.
컨테이너 섹션에서 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름을 입력합니다. 이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 Gemini 지원 분석이 적용됩니다. 예를 들어 일일 TPC-H 쿼리를 실행하는 예약된 워크로드의 동질 집단 이름으로
TPCH-Query1을 지정합니다.필요에 따라 일괄 만들기 페이지의 다른 섹션을 작성한 다음 제출을 클릭합니다. 자세한 내용은 일괄 워크로드 제출을 참조하세요.
gcloud
터미널 창 또는 Cloud Shell에서 다음 gcloud CLI gcloud dataproc batches submit 명령어를 로컬로 실행하여 반복되는 각 Spark 일괄 워크로드에 자동 조정을 사용 설정합니다.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
다음을 바꿉니다.
- COMMAND: Spark 워크로드 유형(예:
Spark,PySpark,Spark-Sql또는Spark-R). - REGION: 워크로드가 실행되는 리전.
- COHORT: 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름.
이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 Gemini 지원 분석이 적용됩니다. 예를 들어 일일 TPC-H 쿼리를 실행하는 예약된 워크로드의 동질 집단 이름으로
TPCH Query 1을 지정합니다.
API
반복되는 각 Spark 일괄 워크로드에서 자동 조정을 사용 설정하려면 batches.create 요청에 RuntimeConfig.cohort 이름을 포함합니다. 이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 자동 조정이 적용됩니다. 예를 들어 일일 TPC-H 쿼리를 실행하는 예약된 워크로드의 동질 집단 이름으로 TPCH-Query1을 지정합니다.
예:
...
runtimeConfig:
cohort: TPCH-Query1
...