En este documento, se proporciona información sobre el ajuste automático de cargas de trabajo de Spark. Optimizar una carga de trabajo de Spark para mejorar el rendimiento y la capacidad de recuperación puede ser un desafío debido a la cantidad de opciones de configuración de Spark y a la dificultad para evaluar cómo esas opciones afectan una carga de trabajo. Google Cloud El ajuste automático de Serverless for Apache Spark proporciona una alternativa a la configuración manual de la carga de trabajo, ya que aplica automáticamente la configuración de Spark a una carga de trabajo recurrente de Spark según las prácticas recomendadas de optimización de Spark y un análisis de las ejecuciones de la carga de trabajo.
Regístrate para el ajuste automático de Google Cloud Serverless for Apache Spark
Para registrarte y obtener acceso a la versión preliminar del ajuste automático de Serverless for Apache Spark que se describe en esta página, completa y envía el formulario de registro de solicitud de acceso a la versión preliminar de Dataproc. Una vez que se aprueba el formulario, los proyectos que se indican en él tienen acceso a las funciones de vista previa.
Beneficios
Google Cloud El ajuste automático de Serverless for Apache Spark puede proporcionar los siguientes beneficios:
- Rendimiento mejorado: Ajuste de la optimización para aumentar el rendimiento
- Optimización más rápida: Configuración automática para evitar las pruebas de configuración manual que consumen mucho tiempo
- Mayor capacidad de recuperación: Asignación automática de memoria para evitar fallas relacionadas con la memoria
Limitaciones
La optimización automática deGoogle Cloud Serverless for Apache Spark tiene las siguientes limitaciones:
- El ajuste automático se calcula y se aplica a la segunda y las siguientes ejecuciones de una carga de trabajo. La primera ejecución de una carga de trabajo recurrente no se ajusta automáticamente porque el ajuste automático de Google Cloud Serverless for Apache Spark usa el historial de la carga de trabajo para la optimización.
- No se admite la reducción de memoria.
- El ajuste automático no se aplica de forma retroactiva a las cargas de trabajo en ejecución, sino solo a las cohortes de cargas de trabajo enviadas recientemente.
Cohortes de ajuste automático
El ajuste automático se aplica a las ejecuciones recurrentes de una carga de trabajo por lotes, denominadas cohortes.
El nombre de la cohorte que especificas cuando envías una carga de trabajo la identifica como una de las ejecuciones sucesivas de la carga de trabajo recurrente.
Te recomendamos que uses nombres de cohortes que describan el tipo de carga de trabajo o que ayuden a identificar las ejecuciones de una carga de trabajo como parte de una carga de trabajo recurrente. Por ejemplo, especifica daily_sales_aggregation como el nombre de la cohorte para una carga de trabajo programada que ejecuta una tarea de agregación de ventas diaria.
Situaciones de ajuste automático
Para aplicar el ajuste automático de Google Cloud Serverless for Apache Spark a tu carga de trabajo, selecciona uno o más de los siguientes casos de ajuste automático:
MEMORY: Ajusta automáticamente la asignación de memoria de Spark para predecir y evitar posibles errores de memoria insuficiente en la carga de trabajo. Corrige una carga de trabajo que falló anteriormente debido a un error de memoria insuficiente (OOM).SCALING: Ajusta automáticamente la configuración del ajuste de escala automático de Spark.BROADCAST_HASH_JOIN: Ajusta automáticamente la configuración de Spark para optimizar el rendimiento de la unión de transmisión de SQL.
Precios
Google Cloud El ajuste automático de Serverless for Apache Spark se ofrece durante la versión preliminar sin cargo adicional. Se aplican los precios estándar deGoogle Cloud Serverless for Apache Spark.
Disponibilidad regional
Puedes usar el ajuste automático de Google Cloud Serverless for Apache Spark con lotes que se envían en las regiones disponibles de Compute Engine.
Usa el ajuste automático de Google Cloud Serverless for Apache Spark
Puedes habilitar el ajuste automático de Google Cloud Serverless for Apache Spark en una carga de trabajo con la Google Cloud consola, Google Cloud CLI o la API de Dataproc.
Console
Para habilitar el ajuste automático de Google Cloud Serverless for Apache Spark en cada envío de una carga de trabajo por lotes recurrente, sigue estos pasos:
En la consola de Google Cloud , ve a la página Lotes de Dataproc.
Para crear una carga de trabajo por lotes, haz clic en Crear.
En la sección Contenedor, completa los siguientes campos para tu carga de trabajo de Spark:
Cohorte: Es el nombre de la cohorte, que identifica el lote como una de una serie de cargas de trabajo recurrentes. El ajuste automático se aplica a la segunda carga de trabajo y a las posteriores que se envían con este nombre de cohorte. Por ejemplo, especifica
daily_sales_aggregationcomo el nombre de la cohorte para una carga de trabajo programada que ejecuta una tarea de agregación de ventas diaria.Situaciones de ajuste automático: Una o más situaciones de ajuste automático para optimizar la carga de trabajo, por ejemplo,
BROADCAST_HASH_JOIN,MEMORYySCALING. Puedes cambiar la selección de situaciones con cada envío de cohortes de lotes.
Completa otras secciones de la página Crear lote según sea necesario y, luego, haz clic en Enviar. Para obtener más información sobre estos campos, consulta Envía una carga de trabajo por lotes.
gcloud
Para habilitar el ajuste automático de Google Cloud Serverless for Apache Spark en cada envío de una carga de trabajo por lotes recurrente, ejecuta el siguiente comando de gcloud CLI de gcloudgcloud dataproc batches submit de forma local en una ventana de la terminal o en Cloud Shell.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Reemplaza lo siguiente:
- COMMAND: Es el tipo de carga de trabajo de Spark, como
Spark,PySpark,Spark-SqloSpark-R. - REGION: Es la región en la que se ejecutará tu carga de trabajo.
COHORT: Es el nombre de la cohorte, que identifica el lote como una de una serie de cargas de trabajo recurrentes. El ajuste automático se aplica a la segunda y las siguientes cargas de trabajo que se envían con este nombre de cohorte. Por ejemplo, especifica
daily_sales_aggregationcomo el nombre de la cohorte para una carga de trabajo programada que ejecuta una tarea de agregación de ventas diaria.SCENARIOS: Uno o más escenarios de ajuste automático separados por comas para optimizar la carga de trabajo, por ejemplo,
--autotuning-scenarios=MEMORY,SCALING. Puedes cambiar la lista de situaciones con cada envío de cohorte de lotes.
API
Para habilitar el ajuste automático de Google Cloud Serverless for Apache Spark en cada envío de una carga de trabajo por lotes recurrente, envía una solicitud de batches.create que incluya los siguientes campos:
RuntimeConfig.cohort: Es el nombre de la cohorte, que identifica el lote como una de una serie de cargas de trabajo recurrentes. El ajuste automático se aplica a la segunda carga de trabajo y a las posteriores que se envían con este nombre de cohorte. Por ejemplo, especificadaily_sales_aggregationcomo el nombre de la cohorte para una carga de trabajo programada que ejecuta una tarea de agregación de ventas diaria.AutotuningConfig.scenarios: Uno o más escenarios de ajuste automático para optimizar la carga de trabajo, por ejemplo,BROADCAST_HASH_JOIN,MEMORYySCALING. Puedes cambiar la lista de situaciones con cada envío de cohorte de lotes.
Ejemplo:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Antes de probar este ejemplo, sigue las instrucciones de configuración para Java que encontrarás en la guía de inicio rápido de Serverless para Apache Spark sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de Serverless para Apache Spark Java.
Para autenticarte en Serverless for Apache Spark, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Para habilitar el ajuste automático de Google Cloud Serverless for Apache Spark en cada envío de una carga de trabajo por lotes recurrente, llama a BatchControllerClient.createBatch con un CreateBatchRequest que incluya los siguientes campos:
Batch.RuntimeConfig.cohort: Es el nombre de la cohorte, que identifica el lote como una de una serie de cargas de trabajo recurrentes. El ajuste automático se aplica a la segunda carga de trabajo y a las posteriores que se envían con este nombre de cohorte. Por ejemplo, puedes especificardaily_sales_aggregationcomo el nombre de la cohorte para una carga de trabajo programada que ejecuta una tarea de agregación de ventas diaria.Batch.RuntimeConfig.AutotuningConfig.scenarios: Uno o más escenarios de ajuste automático para optimizar la carga de trabajo, comoBROADCAST_HASH_JOIN,MEMORYySCALING. Puedes cambiar la lista de situaciones con cada envío de cohorte de lotes. Para obtener la lista completa de situaciones, consulta el Javadoc de AutotuningConfig.Scenario.
Ejemplo:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Para usar la API, debes usar la versión 4.43.0 o posterior de la biblioteca cliente google-cloud-dataproc. Puedes usar una de las siguientes configuraciones para agregar la biblioteca a tu proyecto.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Antes de probar este ejemplo, sigue las instrucciones de configuración para Python que encontrarás en la guía de inicio rápido de Serverless para Apache Spark sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de Serverless para Apache Spark Python.
Para autenticarte en Serverless for Apache Spark, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Para habilitar el ajuste automático de Google Cloud Serverless for Apache Spark en cada envío de una carga de trabajo por lotes recurrente, llama a BatchControllerClient.create_batch con un Batch que incluya los siguientes campos:
batch.runtime_config.cohort: Es el nombre de la cohorte, que identifica el lote como una de una serie de cargas de trabajo recurrentes. El ajuste automático se aplica a la segunda carga de trabajo y a las posteriores que se envían con este nombre de cohorte. Por ejemplo, puedes especificardaily_sales_aggregationcomo el nombre de la cohorte para una carga de trabajo programada que ejecuta una tarea de agregación de ventas diaria.batch.runtime_config.autotuning_config.scenarios: Uno o más escenarios de ajuste automático para optimizar la carga de trabajo, comoBROADCAST_HASH_JOIN,MEMORYySCALING. Puedes cambiar la lista de escenarios con cada envío de cohorte por lotes. Para obtener la lista completa de situaciones, consulta la referencia de Situación.
Ejemplo:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Para usar la API, debes usar la versión 5.10.1 o posterior de la biblioteca cliente google-cloud-dataproc. Para agregarlo a tu proyecto, puedes usar el siguiente requisito:
google-cloud-dataproc>=5.10.1
Airflow
Para habilitar el ajuste automático de Google Cloud Serverless for Apache Spark en cada envío de una carga de trabajo por lotes recurrente, llama a BatchControllerClient.create_batch con un Batch que incluya los siguientes campos:
batch.runtime_config.cohort: Es el nombre de la cohorte, que identifica el lote como una de una serie de cargas de trabajo recurrentes. El ajuste automático se aplica a la segunda carga de trabajo y a las posteriores que se envían con este nombre de cohorte. Por ejemplo, puedes especificardaily_sales_aggregationcomo el nombre de la cohorte para una carga de trabajo programada que ejecuta una tarea de agregación de ventas diaria.batch.runtime_config.autotuning_config.scenarios: Uno o más escenarios de ajuste automático que se usarán para optimizar la carga de trabajo, por ejemplo,BROADCAST_HASH_JOIN,MEMORY,SCALING. Puedes cambiar la lista de escenarios con cada envío de cohorte por lotes. Para obtener la lista completa de situaciones, consulta la referencia de Situación.
Ejemplo:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
Para usar la API, debes usar la versión 5.10.1 o posterior de la biblioteca cliente google-cloud-dataproc. Puedes usar el siguiente requisito del entorno de Airflow:
google-cloud-dataproc>=5.10.1
Para actualizar el paquete en Cloud Composer, consulta Instala dependencias de Python para Cloud Composer .
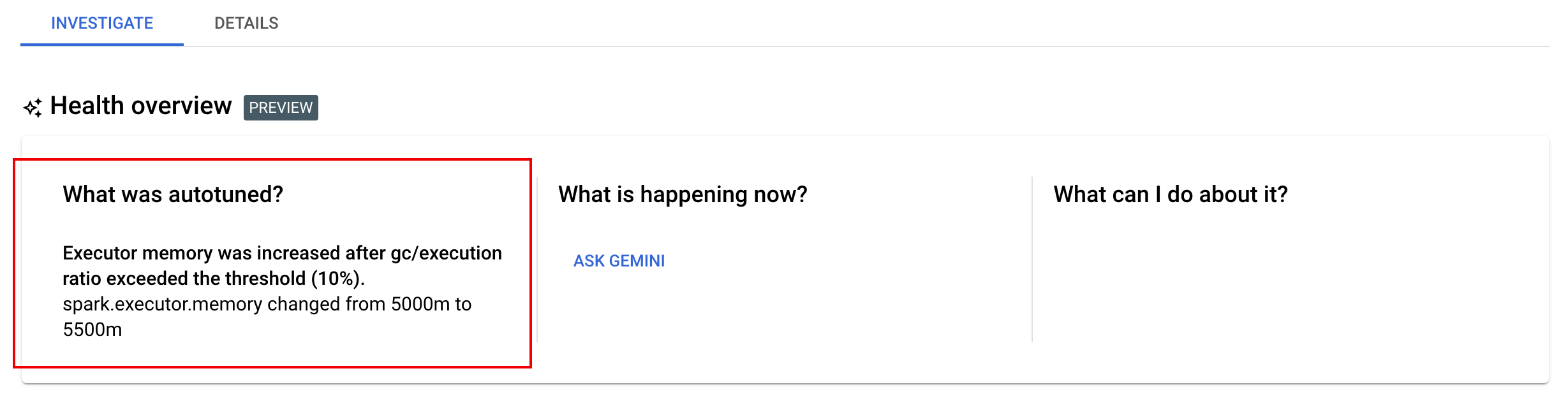
Cómo ver los cambios del ajuste automático
Para ver los cambios de ajuste automático de Google Cloud Serverless for Apache Spark en una carga de trabajo por lotes, ejecuta el comandogcloud dataproc batches describe.
Ejemplo: El resultado de gcloud dataproc batches describe es similar al siguiente:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
Puedes ver los cambios más recientes de la optimización automática que se aplicaron a una carga de trabajo en ejecución, completada o con errores en la página Detalles del lote de la consola de Google Cloud , en la pestaña Investigar.