This document provides information about autotuning Spark workloads. Optimizing a Spark workload for performance and resiliency can be challenging due to the number of Spark configuration options and the difficulty of assessing how those options impact a workload. Google Cloud Serverless for Apache Spark autotuning provides an alternative to manual workload configuration by automatically applying Spark configuration settings to a recurring Spark workload based on Spark optimization best practices and an analysis of workload runs.
Sign up for Google Cloud Serverless for Apache Spark autotuning
To sign up for access to the Serverless for Apache Spark autotuning preview release described on this page, complete and submit the Dataproc Preview access request signup form. After the form is approved, projects listed in the form have access to preview features.
Benefits
Google Cloud Serverless for Apache Spark autotuning can provide the following benefits:
- Improved performance: Optimization tuning to increase performance
- Quicker optimization: Auto-configuration to avoid time-consuming manual configuration testing
- Increased resiliency: Automatic memory allocation to avoid memory-related failures
Limitations
Google Cloud Serverless for Apache Spark autotuning has the following limitations:
- Autotuning is calculated and applied to the second and subsequent runs of a workload. The first run of a recurring workload is not autotuned because Google Cloud Serverless for Apache Spark autotuning uses workload history for optimization.
- Memory downsizing is not supported.
- Autotuning is not applied retroactively to running workloads, only to newly submitted workload cohorts.
Autotuning cohorts
Autotuning is applied to recurring executions of a batch workload, called cohorts.
The cohort name that you specify when you submit a workload
identifies it as one of the successive runs of the recurring workload.
We recommend that you use cohort names that describe the type of
workload or that otherwise help to identify the runs of a workload as part
of a recurring workload. For example, specify daily_sales_aggregation as the
cohort name for a scheduled workload that runs a daily sales aggregation task.
Autotuning scenarios
You apply Google Cloud Serverless for Apache Spark autotuning to your workload by selecting one or more of the following autotuning scenarios:
MEMORY: Autotune Spark memory allocation to predict and avoid potential workload out-of-memory errors. Fix a previously failed workload due to an out-of-memory (OOM) error.SCALING: Autotune Spark autoscaling configuration settings.BROADCAST_HASH_JOIN: Autotune Spark configuration settings to optimize SQL broadcast join performance.
Pricing
Google Cloud Serverless for Apache Spark autotuning is offered during preview without additional charge. Standard Google Cloud Serverless for Apache Spark pricing applies.
Regional availability
You can use Google Cloud Serverless for Apache Spark autotuning with batches that are submitted in available Compute Engine regions.
Use Google Cloud Serverless for Apache Spark autotuning
You can enable Google Cloud Serverless for Apache Spark autotuning on a workload by using the Google Cloud console, Google Cloud CLI, or Dataproc API.
Console
To enable Google Cloud Serverless for Apache Spark autotuning on each submission of a recurring batch workload, perform the following steps:
In the Google Cloud console, go to the Dataproc Batches page.
To create a batch workload, click Create.
In the Container section, fill in the following fields for your Spark workload:
Cohort: the cohort name, which identifies the batch as one of a series of recurring workloads. Autotuning is applied to the second and subsequent workloads that are submitted with this cohort name. For example, specify
daily_sales_aggregationas the cohort name for a scheduled workload that runs a daily sales aggregation task.Autotuning scenarios: one or more autotuning scenarios to use to optimize the workload, for example,
BROADCAST_HASH_JOIN,MEMORY, andSCALING. You can change the scenario selection with each batch cohort submission.
Fill in other sections of the Create batch page as needed, then click Submit. For more information about these fields, see Submit a batch workload.
gcloud
To enable Google Cloud Serverless for Apache Spark autotuning on each submission
of a recurring batch workload, run the following gcloud CLI
gcloud dataproc batches submit
command locally in a terminal window or in
Cloud Shell.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Replace the following:
- COMMAND: the Spark workload type, such as
Spark,PySpark,Spark-Sql, orSpark-R. - REGION: the region where your workload will run.
COHORT: the cohort name, which identifies the batch as one of a series of recurring workloads. Autotuning is applied to the second and subsequent workloads that are submitted with this cohort name. For example, specify
daily_sales_aggregationas the cohort name for a scheduled workload that runs a daily sales aggregation task.SCENARIOS: one or more comma-separated autotuning scenarios to use to optimize the workload, for example,
--autotuning-scenarios=MEMORY,SCALING. You can change the scenario list with each batch cohort submission.
API
To enable Google Cloud Serverless for Apache Spark autotuning on each submission of a recurring batch workload, submit a batches.create request that includes the following fields:
RuntimeConfig.cohort: the cohort name, which identifies the batch as one of a series of recurring workloads. Autotuning is applied to the second and subsequent workloads submitted with this cohort name. For example, specifydaily_sales_aggregationas the cohort name for a scheduled workload that runs a daily sales aggregation task.AutotuningConfig.scenarios: one or more autotuning scenarios to use to optimize the workload, for example,BROADCAST_HASH_JOIN,MEMORY, andSCALING. You can change the scenario list with each batch cohort submission.
Example:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Before trying this sample, follow the Java setup instructions in the Serverless for Apache Spark quickstart using client libraries. For more information, see the Serverless for Apache Spark Java API reference documentation.
To authenticate to Serverless for Apache Spark, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
To enable Google Cloud Serverless for Apache Spark autotuning on each submission of a recurring batch workload, call BatchControllerClient.createBatch with a CreateBatchRequest that includes the following fields:
Batch.RuntimeConfig.cohort: The cohort name, which identifies the batch as one of a series of recurring workloads. Autotuning is applied to the second and subsequent workloads submitted with this cohort name. For example, you might specifydaily_sales_aggregationas the cohort name for a scheduled workload that runs a daily sales aggregation task.Batch.RuntimeConfig.AutotuningConfig.scenarios: One or more autotuning scenarios to use to optimize the workload, such as,BROADCAST_HASH_JOIN,MEMORY,SCALING. You can change the scenario list with each batch cohort submission. For the complete list of scenarios, see the AutotuningConfig.Scenario Javadoc.
Example:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
To use the API, you must use google-cloud-dataproc client library version 4.43.0
or later. You can use one of the following configurations to add the library to your
project.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Before trying this sample, follow the Python setup instructions in the Serverless for Apache Spark quickstart using client libraries. For more information, see the Serverless for Apache Spark Python API reference documentation.
To authenticate to Serverless for Apache Spark, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
To enable Google Cloud Serverless for Apache Spark autotuning on each submission of a recurring batch workload, call BatchControllerClient.create_batch with a Batch that includes the following fields:
batch.runtime_config.cohort: The cohort name, which identifies the batch as one of a series of recurring workloads. Autotuning is applied to the second and subsequent workloads submitted with this cohort name. For example, you might specifydaily_sales_aggregationas the cohort name for a scheduled workload that runs a daily sales aggregation task.batch.runtime_config.autotuning_config.scenarios: One or more autotuning scenarios to use to optimize the workload, such as,BROADCAST_HASH_JOIN,MEMORY,SCALING. You can change the scenario list with each batch cohort submission. For the complete list of scenarios, see the Scenario reference.
Example:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
To use the API, you must use google-cloud-dataproc client library version 5.10.1
or later. To add it to your project, you can use the following requirement:
google-cloud-dataproc>=5.10.1
Airflow
To enable Google Cloud Serverless for Apache Spark autotuning on each submission of a recurring batch workload, call BatchControllerClient.create_batch with a Batch that includes the following fields:
batch.runtime_config.cohort: The cohort name, which identifies the batch as one of a series of recurring workloads. Autotuning is applied to the second and subsequent workloads submitted with this cohort name. For example, you might specifydaily_sales_aggregationas the cohort name for a scheduled workload that runs a daily sales aggregation task.batch.runtime_config.autotuning_config.scenarios: One or more autotuning scenarios to use to optimize the workload, for example,BROADCAST_HASH_JOIN,MEMORY,SCALING. You can change the scenario list with each batch cohort submission. For the complete list of scenarios, see the Scenario reference.
Example:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
To use the API, you must use google-cloud-dataproc client library version 5.10.1
or later. You can use the following Airflow environment requirement:
google-cloud-dataproc>=5.10.1
To update the package in Cloud Composer, see Install Python dependencies for Cloud Composer .
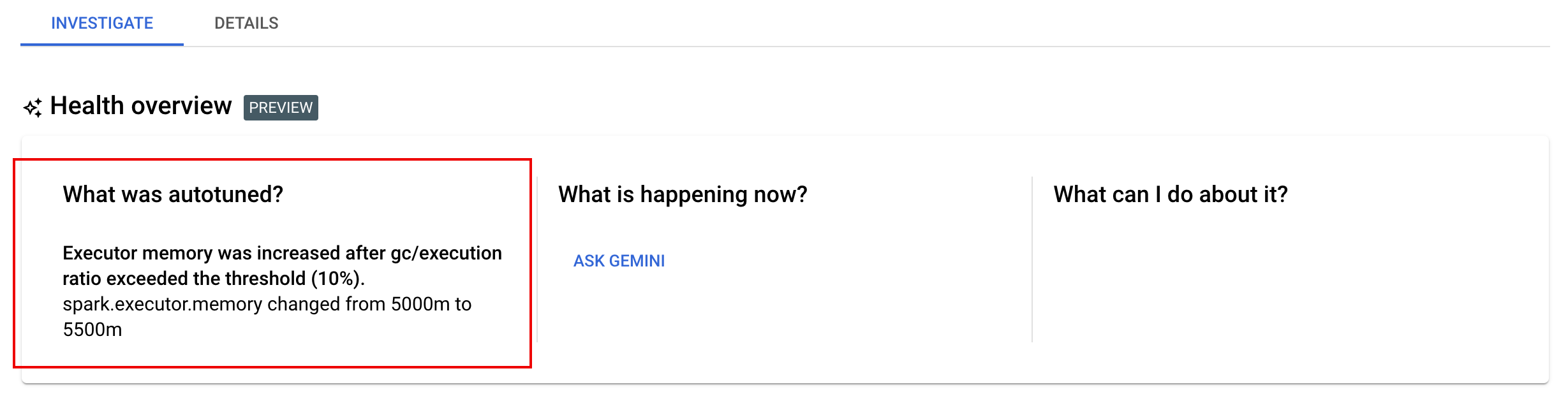
View autotuning changes
To view Google Cloud Serverless for Apache Spark autotuning changes to a batch workload,
run the
gcloud dataproc batches describe
command.
Example: gcloud dataproc batches describe output is similar to the following:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
You can view the latest autotuning changes that were applied to a running, completed, or failed workload on the Batch details page in the Google Cloud console, under the Investigate tab.