La migrazione gestita è una funzionalità automatica che ti aiuta a eseguire la migrazione dei dati da un metastore Hive autogestito a un servizio Dataproc Metastore, senza tempi di inattività significativi (altrimenti noto come flag day).
Architettura della migrazione gestita
Il seguente diagramma mostra l'architettura di alto livello di una migrazione gestita.
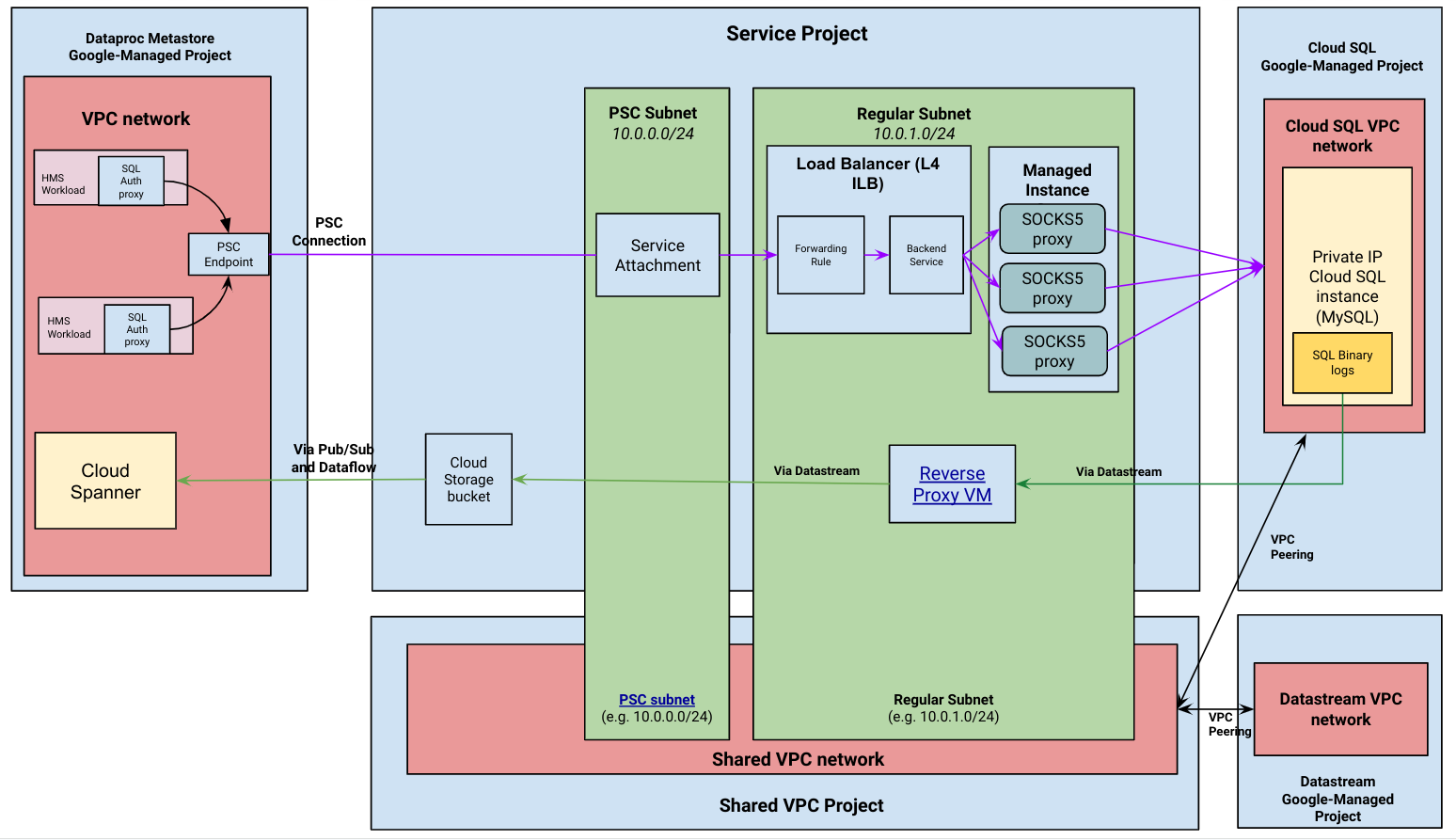
Flusso di migrazione gestita
Per completare una migrazione gestita, il servizio esegue due processi di migrazione: avvia migrazione e completa migrazione. Puoi annullare una migrazione in qualsiasi momento con la procedura di annullamento della migrazione. Esistono anche diversi comandi operativi che puoi eseguire, ma non sono necessari per completare una migrazione. Ad esempio, elenca le migrazioni o elimina le migrazioni.
Man mano che il servizio avanza in questo processo, passa anche attraverso vari stati di migrazione e fasi di migrazione. Questi stati e fasi rappresentano i
processi che si verificano in background. Ad esempio, lo stato MIGRATING
indica che il servizio sta trasferendo attivamente i dati dal database Cloud SQL a Dataproc Metastore.
Avvia migrazione
Dataproc Metastore stabilisce una connessione con la tua istanza Cloud SQL con IP privato. Una volta stabilita la connessione, Dataproc Metastore utilizza l'istanza Cloud SQL come database di backend Hive Metastore (HMS). Inoltre, rimane la fonte di verità per i tuoi dati durante la migrazione. Le letture e le scritture dei metadati si verificano ancora in Cloud SQL quando la migrazione è attiva.
Viene avviata una pipeline Change Data Capture (CDC). Questa pipeline mantiene sincronizzate l'istanza Cloud SQL nel tuo progetto e Spanner nel progetto gestito Dataproc Metastore. Ciò significa che tutte le modifiche al database HMS nell'istanza Cloud SQL vengono acquisite tramite Datastream e scritte nel database Spanner di Dataproc Metastore.
Una volta completato il processo di avvio della migrazione, puoi iniziare a indirizzare i carichi di lavoro dei dati a Dataproc Metastore. A questo punto, Cloud SQL è ancora l'origine attendibile dei tuoi dati.
Completa migrazione
Dopo aver terminato lo spostamento dei carichi di lavoro in Dataproc Metastore, puoi completare la migrazione. Quando viene chiamato un processo di migrazione completa, si verifica quanto segue:
- Dataproc Metastore passa alla modalità di sola lettura fino al termine della procedura di migrazione completa.
- Lo stream CDC trasferisce tutti i dati in transito a Dataproc Metastore.
- Dataproc Metastore si connette a Spanner e si disconnette da Cloud SQL. Dataproc Metastore ora funge da fonte di verità per i tuoi dati HMS.
Considerazioni su proxy e pipeline
Proxy
Dataproc Metastore utilizza un proxy di autenticazione Cloud SQL concatenato a un proxy SOCKS5 per connettersi all'istanza Cloud SQL con IP privato. I server proxy SOCKS5 vengono esposti tramite un collegamento del servizio, come mostrato nel diagramma dell'architettura precedente.
Ogni migrazione richiede una subnet NAT dedicata. Questo perché una subnet NAT non può avere più di un collegamento del servizio.
Per evitare problemi di latenza tra regioni, fornisci subnet che si trovano nella stessa regione dell'istanza Cloud SQL per ospitare il proxy SOCKS5. Ad esempio,
proxy_subnetenat_subnet.
Pipeline Change Data Capture
La pipeline di acquisizione delle modifiche ai dati utilizza il peering VPC per stabilire una connessione tra Datastream e Cloud SQL con IP privato
Per ogni migrazione, viene creata una nuova connessione privata e viene stabilita una nuova connessione di peering.
La rete VPC che ospita l'istanza Cloud SQL ha tante connessioni di peering quante sono le migrazioni attive. Assicurati che la tua rete VPC abbia la capacità di ospitare tutte le connessioni di peering necessarie.