La migration gérée est une fonctionnalité automatisée qui vous aide à migrer des données d'un métastore Hive autogéré vers un service Dataproc Metastore, sans temps d'arrêt important (également appelé jour de bascule).
Architecture de migration gérée
Le diagramme suivant présente l'architecture générale d'une migration gérée.
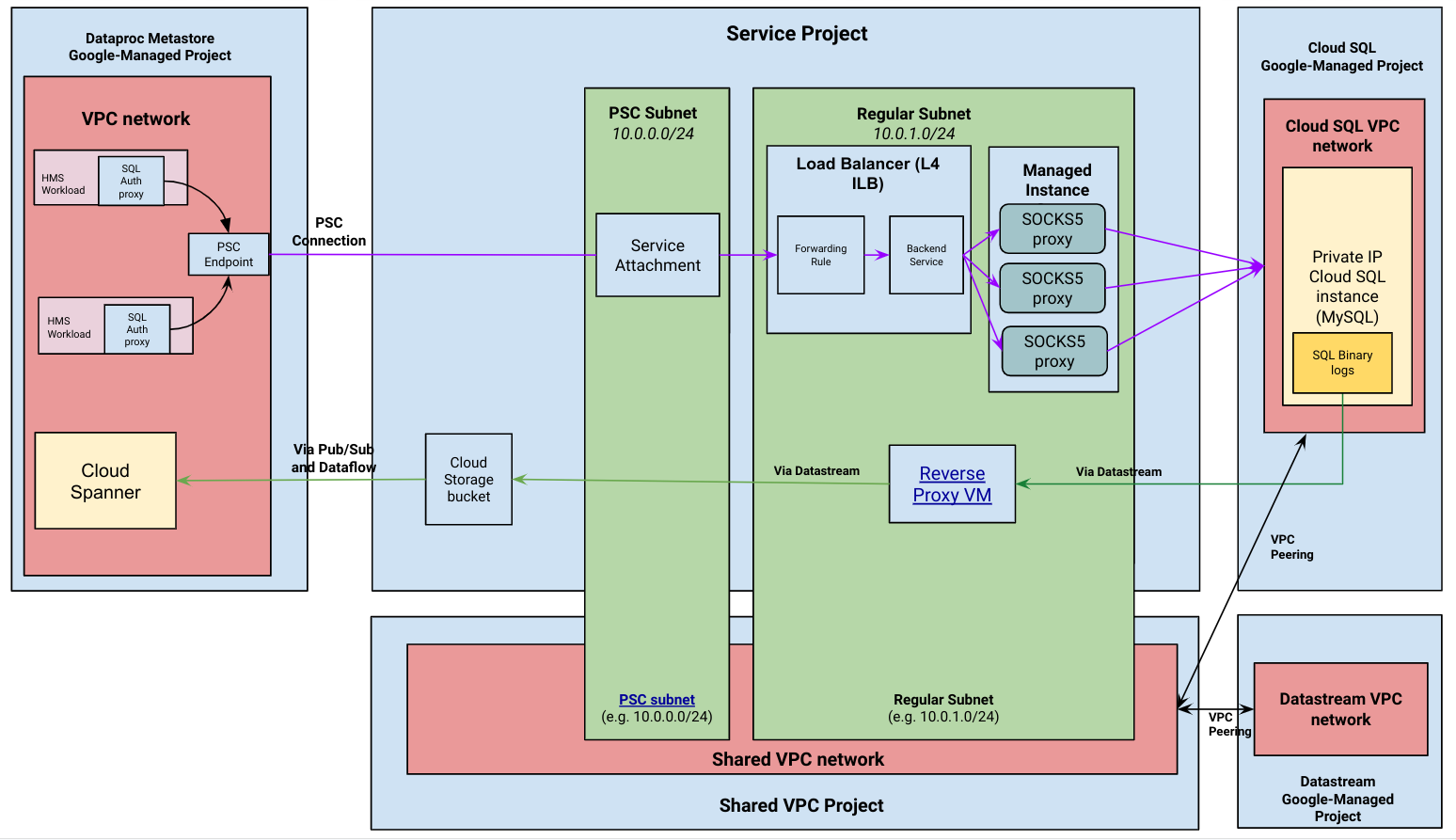
Processus de migration gérée
Pour effectuer une migration gérée, votre service exécute deux processus de migration : start migration et complete migration. Vous pouvez annuler une migration à tout moment à l'aide de la procédure Annuler la migration. Vous pouvez également exécuter un certain nombre de commandes opérationnelles, qui ne sont pas nécessaires pour effectuer une migration. Par exemple, list migrations ou delete migrations.
Au fur et à mesure que votre service progresse dans ce processus, il passe également par différents états de migration et phases de migration. Ces états et phases représentent les processus qui se déroulent en arrière-plan. Par exemple, l'état MIGRATING indique que votre service transfère activement des données de votre base de données Cloud SQL vers Dataproc Metastore.
Démarrer la migration
Dataproc Metastore établit une connexion avec votre instance Cloud SQL à adresse IP privée. Une fois la connexion établie, Dataproc Metastore utilise l'instance Cloud SQL comme base de données backend Hive Metastore (HMS). Elle reste également la source de référence pour vos données pendant la migration. Les opérations de lecture et d'écriture de métadonnées ont toujours lieu dans Cloud SQL lorsque la migration est active.
Un pipeline de capture de données modifiées (CDC) est démarré. Ce pipeline permet de synchroniser l'instance Cloud SQL de votre projet et Spanner dans le projet géré Dataproc Metastore. Cela signifie que toutes les modifications apportées à la base de données HMS dans l'instance Cloud SQL sont capturées par Datastream et écrites dans la base de données Spanner Dataproc Metastore.
Une fois le processus de démarrage de la migration réussi, vous pouvez commencer à acheminer les charges de travail de données vers Dataproc Metastore. À ce stade, Cloud SQL reste la source de référence pour vos données.
Effectuer la migration
Une fois que vous avez terminé de transférer vos charges de travail vers Dataproc Metastore, vous pouvez finaliser la migration. Lorsqu'un processus de migration complète est appelé, les événements suivants se produisent :
- Dataproc Metastore passe en mode lecture seule jusqu'à la fin du processus de migration complète.
- Le flux CDC transfère toutes les données en cours de transfert vers Dataproc Metastore.
- Dataproc Metastore se connecte à Spanner et se déconnecte de Cloud SQL. Dataproc Metastore sert désormais de source de référence pour vos données HMS.
Considérations concernant les proxys et les pipelines
les proxys ;
Dataproc Metastore utilise un proxy d'authentification Cloud SQL chaîné à un proxy SOCKS5 pour se connecter à votre instance Cloud SQL à adresse IP privée. Les serveurs proxy SOCKS5 sont exposés via une pièce jointe de service, comme indiqué dans le schéma d'architecture précédent.
Chaque migration nécessite un sous-réseau NAT dédié. En effet, un sous-réseau NAT ne peut pas comporter plusieurs rattachements de service.
Pour éviter les problèmes de latence entre régions, fournissez des sous-réseaux situés dans la même région que votre instance Cloud SQL pour héberger le proxy SOCKS5. Par exemple,
proxy_subnetetnat_subnet.
Pipeline de capture des données modifiées
Le pipeline de capture des données modifiées utilise l'appairage de VPC pour établir une connexion entre Datastream et Cloud SQL avec adresse IP privée.
Pour chaque migration, une connexion privée et une connexion d'appairage sont créées.
Le réseau VPC hébergeant l'instance Cloud SQL comporte autant de connexions d'appairage que de migrations actives. Assurez-vous que votre réseau VPC a la capacité d'héberger toutes les connexions d'appairage nécessaires.