La migración administrada es una función automatizada que te ayuda a migrar datos de un almacén de metadatos de Hive autoadministrado a un servicio de Dataproc Metastore, sin un tiempo de inactividad considerable (también conocido como día de la bandera).
Arquitectura de migración administrada
En el siguiente diagrama, se muestra la arquitectura de alto nivel de una migración administrada.
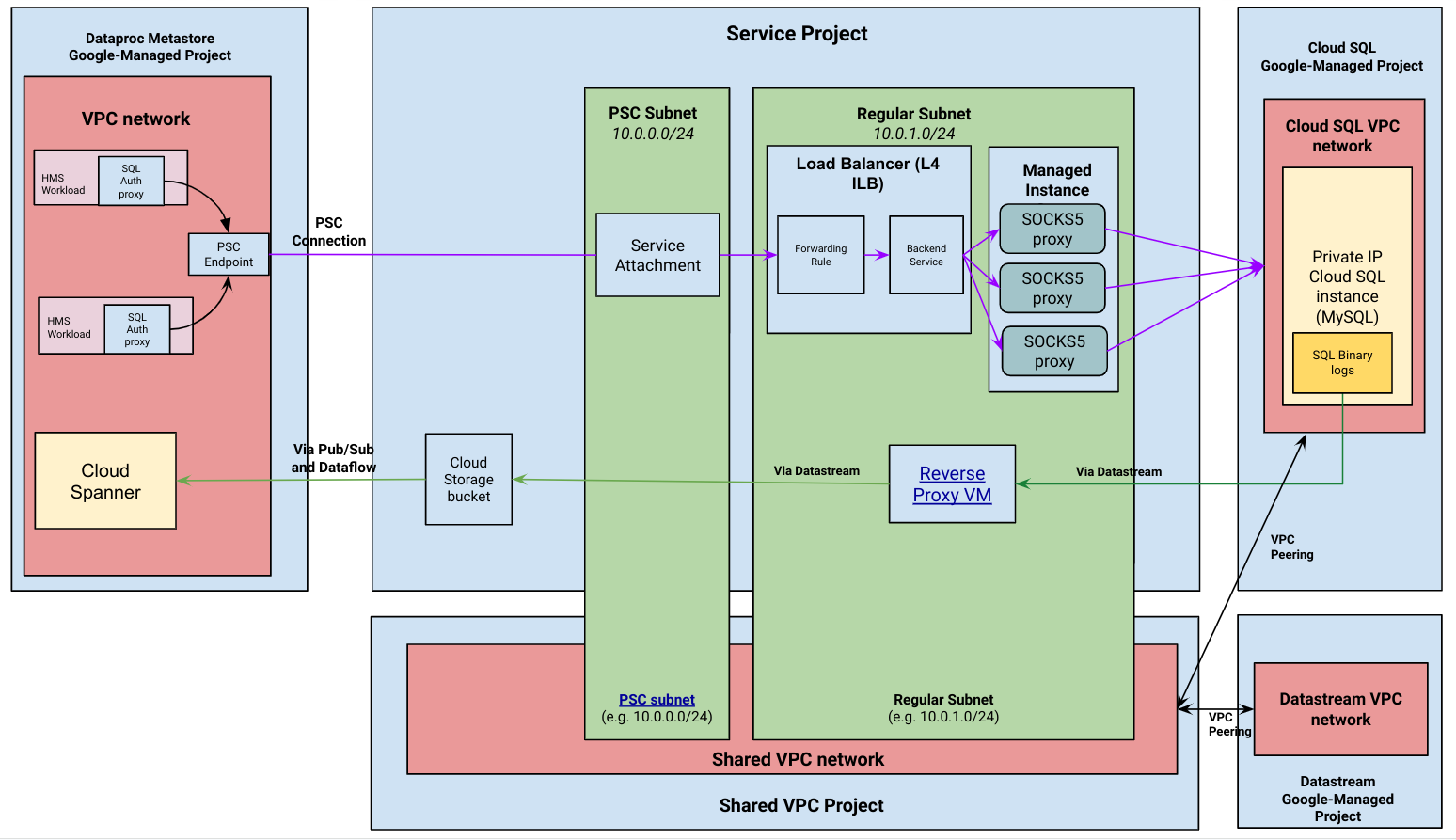
Flujo de migración administrado
Para completar una migración administrada, tu servicio debe ejecutar dos procesos de migración: iniciar migración y completar migración. Puedes cancelar una migración en cualquier momento con el proceso de cancelación de la migración. También puedes ejecutar varios comandos operativos que no son necesarios para completar una migración. Por ejemplo, list migrations o delete migrations.
A medida que tu servicio avanza en este proceso, también pasa por varios estados de migración y fases de migración. Estos estados y fases representan los procesos que ocurren en segundo plano. Por ejemplo, el estado MIGRATING indica que tu servicio está transfiriendo datos de forma activa desde tu base de datos de Cloud SQL a Dataproc Metastore.
Iniciar migración
Dataproc Metastore establece una conexión con tu instancia de Cloud SQL de IP privada. Después de establecer la conexión, Dataproc Metastore usa la instancia de Cloud SQL como su base de datos de backend de Hive Metastore (HMS). También sigue siendo la fuente de verdad para tus datos durante la migración. Las lecturas y escrituras de metadatos siguen ocurriendo en Cloud SQL cuando la migración está activa.
Se inicia una canalización de captura de datos modificados (CDC). Esta canalización mantiene sincronizada la instancia de Cloud SQL en tu proyecto y Spanner en el proyecto administrado de Dataproc Metastore. Esto significa que todos los cambios en la base de datos de HMS en la instancia de Cloud SQL se capturan a través de Datastream y se escriben en la base de datos de Spanner de Dataproc Metastore.
Una vez que el proceso de inicio de la migración se complete correctamente, podrás comenzar a enrutar las cargas de trabajo de datos a Dataproc Metastore. En este punto, Cloud SQL sigue siendo la fuente de verdad para tus datos.
Completa la migración
Después de terminar de mover tus cargas de trabajo a Dataproc Metastore, puedes completar la migración. Cuando se llama a un proceso de migración completa, sucede lo siguiente:
- Dataproc Metastore pasa a un modo de solo lectura hasta que finaliza el proceso de migración completa.
- La transmisión de CDC transfiere todos los datos en tránsito a Dataproc Metastore.
- Dataproc Metastore se conecta a Spanner y se desconecta de Cloud SQL. Dataproc Metastore ahora actúa como la fuente de verdad para tus datos de HMS.
Consideraciones sobre el proxy y la canalización
Proxies
Dataproc Metastore usa un proxy de autenticación de Cloud SQL encadenado a un proxy SOCKS5 para conectarse a tu instancia de Cloud SQL con IP privada. Los servidores proxy SOCKS5 se exponen a través de una vinculación de servicio, como se muestra en el diagrama de arquitectura anterior.
Cada migración requiere una subred NAT dedicada. Esto se debe a que una subred NAT no puede tener más de un adjunto de servicio.
Para evitar problemas de latencia entre regiones, proporciona subredes que se encuentren en la misma región que tu instancia de Cloud SQL para alojar el proxy SOCKS5. Por ejemplo,
proxy_subnetynat_subnet
Canalización de captura de datos de cambio
La canalización de captura de datos modificados usa el intercambio de tráfico de VPC para establecer una conexión entre Datastream y la IP privada de Cloud SQL.
Para cada migración, se crea una nueva conexión privada y se establece una nueva conexión de intercambio de tráfico.
La red de VPC que aloja la instancia de Cloud SQL tiene tantas conexiones de intercambio de tráfico como migraciones activas. Asegúrate de que tu red de VPC tenga la capacidad de alojar todas las conexiones de intercambio de tráfico necesarias.