Este documento descreve como usar o Dataplex Explore para detectar anomalias em um conjunto de dados de transações de varejo.
A área de trabalho de análise de dados, ou Análise, permite que analistas de dados consultem e explorem grandes conjuntos de dados de maneira interativa em tempo real. A Análise detalhada ajuda você a ter insights sobre seus dados e consultar dados armazenados no Cloud Storage e no BigQuery. Conheça os usos de uma plataforma Spark sem servidor, para que você não precise gerenciar e dimensionar a infraestrutura subjacente.
Objetivos
Nesta seção, mostramos como concluir as seguintes tarefas:
- Use o workbench do Spark SQL do Explore para escrever e executar consultas do Spark SQL.
- Use um notebook do JupyterLab para conferir os resultados.
- Programe o notebook para execução recorrente, permitindo que você monitore os dados em busca de anomalias.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create
PROJECT_ID Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project
PROJECT_ID Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
Preparar os dados para análise detalhada
Faça o download do arquivo Parquet,
retail_offline_sales_march.Crie um bucket do Cloud Storage chamado
offlinesales_curatedda seguinte maneira:- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create bucket.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
- For Name your bucket, enter a name that meets the bucket naming requirements.
-
For Choose where to store your data, do the following:
- Select a Location type option.
- Select a Location option.
- For Choose a default storage class for your data, select a storage class.
- For Choose how to control access to objects, select an Access control option.
- For Advanced settings (optional), specify an encryption method, a retention policy, or bucket labels.
- Click Create.
Faça upload do arquivo
offlinesales_march_parquetque você fez o download para o bucket do Cloud Storageofflinesales_curatedque você criou, seguindo as etapas em Fazer upload de objetos de um sistema de arquivos.Crie um lake do Dataplex e nomeie-o como
operations, seguindo as etapas em Criar um lake.No lake
operations, adicione uma zona e nomeie-a comoprocurement, seguindo as etapas em Adicionar uma zona.Na zona
procurement, adicione o bucket do Cloud Storageofflinesales_curatedcriado como um recurso seguindo as etapas em Adicionar um recurso.
Selecione a tabela a ser analisada
No console do Google Cloud, acesse a página Explorar do Dataplex.
No campo Lago, selecione o lago
operations.Clique no lake
operations.Navegue até a zona
procuremente clique na tabela para conferir os metadados dela.Na imagem a seguir, a zona de compras selecionada tem uma tabela chamada
Offline, que tem os metadados:orderid,product,quantityordered,unitprice,orderdateepurchaseaddress.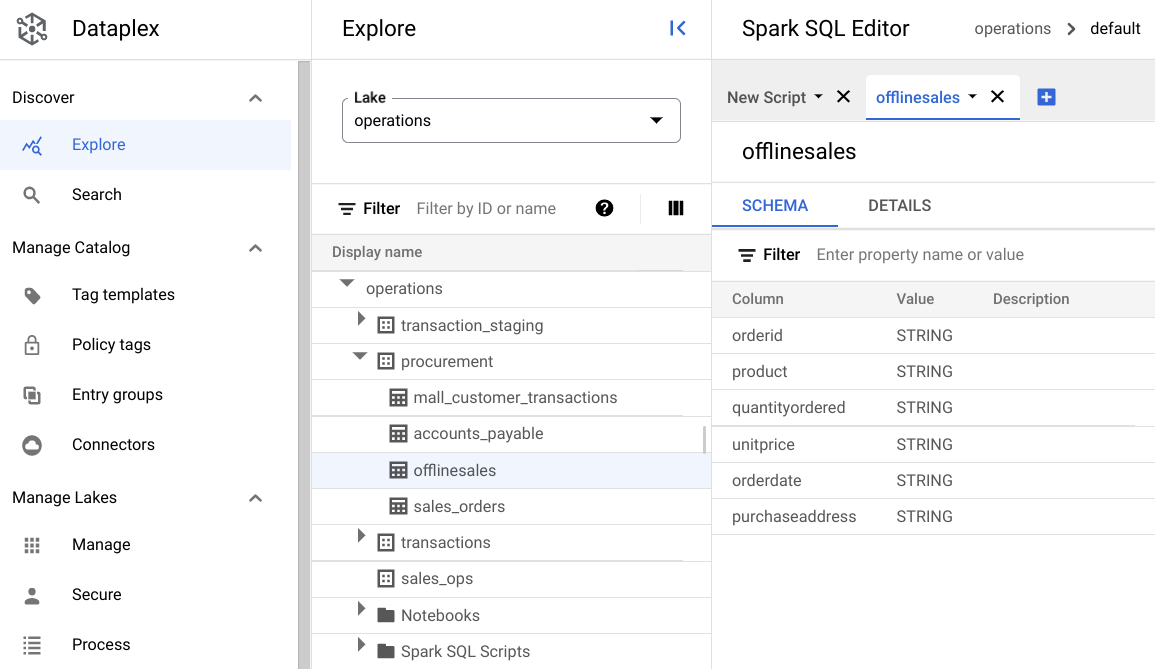
No Editor do Spark SQL, clique em Adicionar. Um script do Spark SQL aparece.
Opcional: abra o script na visualização de guias divididas para conferir os metadados e o novo script lado a lado. Clique em Mais na guia do novo script e selecione Dividir guia à direita ou Dividir guia à esquerda.
explore os dados
Um ambiente fornece recursos de computação sem servidor para que suas consultas e notebooks do Spark SQL sejam executados em um lago. Antes de escrever consultas SQL do Spark, crie um ambiente para executar as consultas.
Analise seus dados usando as consultas SparkSQL a seguir. No Editor SparkSQL, insira a consulta no painel Novo script.
Exemplo de 10 linhas da tabela
Digite a seguinte consulta:
select * from procurement.offlinesales where orderid != 'orderid' limit 10;Clique em Executar.
Conferir o número total de transações no conjunto de dados
Digite a seguinte consulta:
select count(*) from procurement.offlinesales where orderid!='orderid';Clique em Executar.
Encontrar o número de tipos de produtos diferentes no conjunto de dados
Digite a seguinte consulta:
select count(distinct product) from procurement.offlinesales where orderid!='orderid';Clique em Executar.
Encontre os produtos com um valor de transação alto
Para ter uma ideia de quais produtos têm um valor de transação alto, divida as vendas por tipo de produto e preço médio de venda.
Digite a seguinte consulta:
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;Clique em Executar.
A imagem a seguir mostra um painel Results que usa uma coluna chamada product para identificar os itens de venda com valores de transação grandes, mostrados na coluna avg_sales_amount.
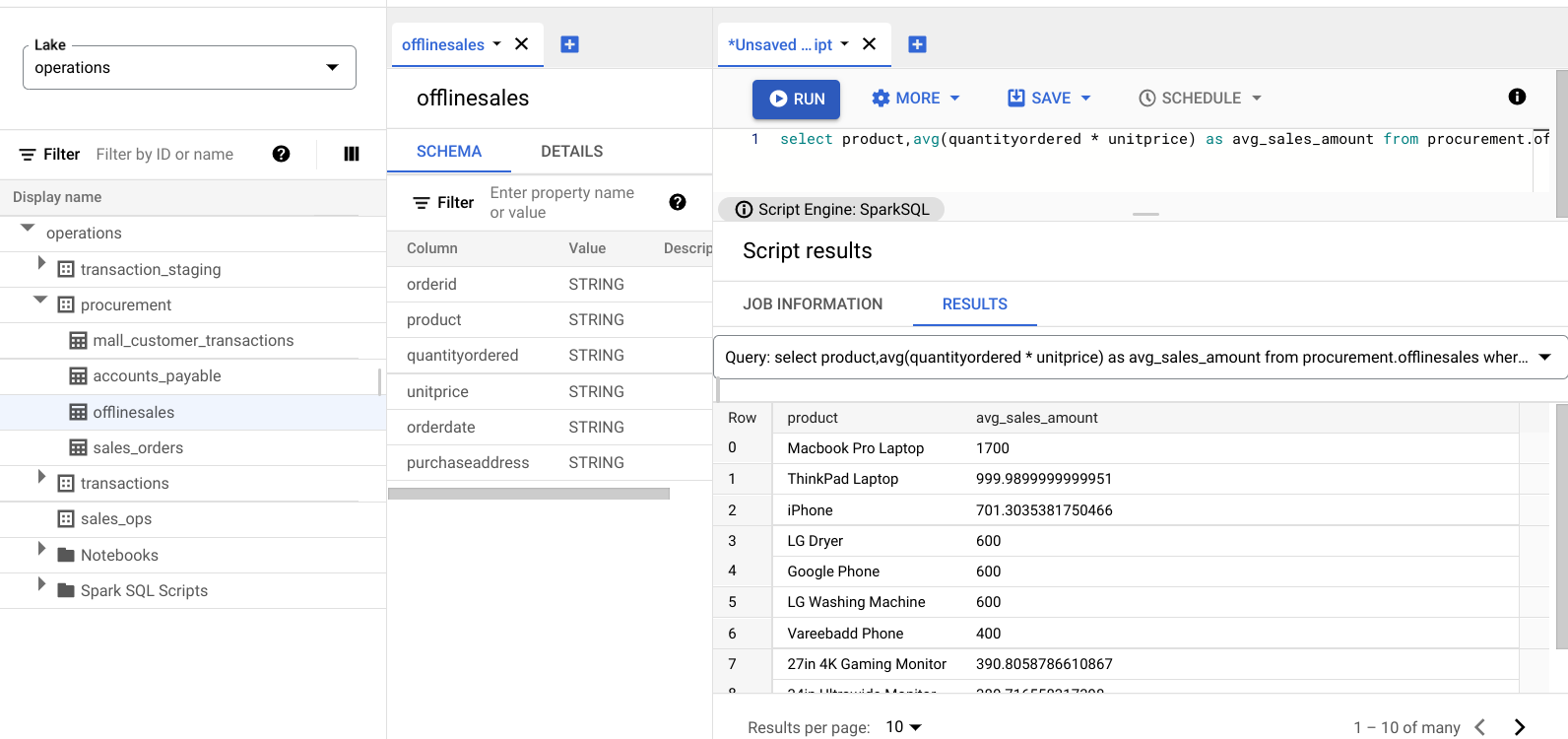
Detectar anomalias usando o coeficiente de variação
A última consulta mostrou que os laptops têm um valor médio de transação alto. A consulta a seguir mostra como detectar transações de laptop que não são anormais no conjunto de dados.
A consulta a seguir usa a métrica "coeficiente de variação",
rsd_value, para encontrar transações que não são incomuns, em que a dispersão dos
valores é baixa em comparação com o valor médio. Um coeficiente de variação menor
indica menos anomalias.
Digite a seguinte consulta:
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10Clique em Executar.
Confira os resultados do script.
Na imagem a seguir, um painel de resultados usa uma coluna chamada "produto" para identificar os itens de vendas com valores de transação dentro do coeficiente de variação de 0,2.
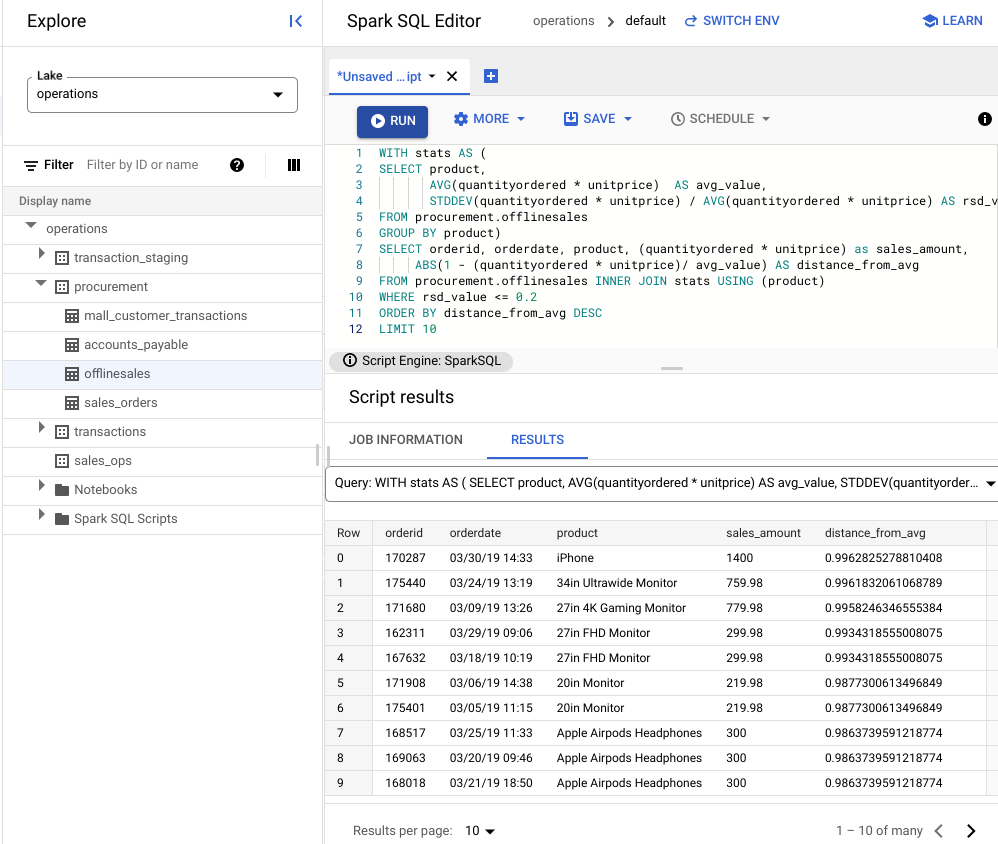
Visualizar anomalias usando um notebook do JupyterLab
Crie um modelo de ML para detectar e visualizar anomalias em grande escala.
Abra o bloco de notas em uma guia separada e aguarde o carregamento. A sessão em que você executou as consultas do Spark SQL continua.
Importe os pacotes necessários e conecte-se à tabela externa do BigQuery que contém os dados das transações. Execute o seguinte código:
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()Execute o algoritmo de floresta de isolamento para descobrir as anomalias no conjunto de dados:
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())Plote as anomalias previstas usando uma visualização do Matplotlib:
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
Esta imagem mostra os dados da transação com as anomalias destacadas em vermelho.
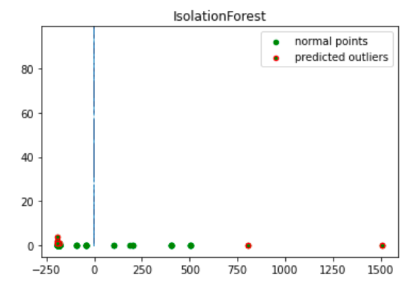
Programar o notebook
Com a Análise detalhada, você pode programar a execução periódica de um notebook. Siga as etapas para programar o Jupyter Notebook que você criou.
O Dataplex cria uma tarefa de programação para executar o notebook periodicamente. Para monitorar o progresso da tarefa, clique em Ver horários.
Compartilhar ou exportar o notebook
Com a opção "Explorar", você pode compartilhar um caderno com outras pessoas na sua organização usando permissões do IAM.
Revise as funções. Conceda ou revogue as funções de leitor do Dataplex
(roles/dataplex.viewer), editor do Dataplex
(roles/dataplex.editor) e administrador do Dataplex
(roles/dataplex.admin) para os usuários neste notebook. Depois que você compartilha um
notebook, os usuários com as funções de leitor ou editor no nível do lago podem navegar
até ele e trabalhar no notebook compartilhado.
Para compartilhar ou exportar um notebook, consulte Compartilhar um notebook ou Exportar um notebook.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Excluir o projeto
Delete a Google Cloud project:
gcloud projects deletePROJECT_ID
Excluir recursos individuais
-
Excluir o bucket:
gcloud storage buckets delete
BUCKET_NAME -
Exclua a instância:
gcloud compute instances delete
INSTANCE_NAME
A seguir
- Saiba mais sobre o Dataplex Explore.
- Programe scripts e notebooks.