En este documento, se describe cómo usar Dataplex Explore para detectar anomalías en un conjunto de datos de transacciones de venta minorista.
El área de trabajo de exploración de datos, o Explorar, permite a los analistas de datos consultar y explorar de manera interactiva conjuntos de datos grandes en tiempo real. Explorar te ayuda a obtener estadísticas de tus datos y te permite consultar datos almacenados en Cloud Storage y BigQuery. Explorar usa una plataforma Spark sin servidores, por lo que no necesitas administrar ni escalar la infraestructura subyacente.
Objetivos
En este instructivo, se muestra cómo completar las siguientes tareas:
- Usa el espacio de trabajo de Spark SQL de Explorar para escribir y ejecutar consultas de Spark SQL.
- Usa un notebook de JupyterLab para ver los resultados.
- Programa tu notebook para que se ejecute de forma recurrente, lo que te permitirá supervisar tus datos en busca de anomalías.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Cuando finalices las tareas que se describen en este documento, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
- Instala Google Cloud CLI.
-
Para inicializar la CLI de gcloud, ejecuta el siguiente comando:
gcloud init
-
Crea o selecciona un proyecto de Google Cloud.
-
Crea un proyecto de Google Cloud:
gcloud projects create PROJECT_ID
Reemplaza
PROJECT_IDpor un nombre para el proyecto de Google Cloud que estás creando. -
Selecciona el proyecto de Google Cloud que creaste:
gcloud config set project PROJECT_ID
Reemplaza
PROJECT_IDpor el nombre del proyecto de Google Cloud.
-
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
- Instala Google Cloud CLI.
-
Para inicializar la CLI de gcloud, ejecuta el siguiente comando:
gcloud init
-
Crea o selecciona un proyecto de Google Cloud.
-
Crea un proyecto de Google Cloud:
gcloud projects create PROJECT_ID
Reemplaza
PROJECT_IDpor un nombre para el proyecto de Google Cloud que estás creando. -
Selecciona el proyecto de Google Cloud que creaste:
gcloud config set project PROJECT_ID
Reemplaza
PROJECT_IDpor el nombre del proyecto de Google Cloud.
-
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
Prepara los datos para la exploración
Descarga el archivo Parquet,
retail_offline_sales_march.Crea un bucket de Cloud Storage llamado
offlinesales_curatedde la siguiente manera:- En la consola de Google Cloud, ve a la página Buckets de Cloud Storage.
- Haga clic en Crear bucket.
- En la página Crear un bucket, ingresa la información de tu bucket. Para ir al paso siguiente, haz clic en Continuar.
- En Nombre de tu bucket, ingresa un nombre que cumpla con los requisitos de nomenclatura de buckets.
-
En Elige dónde almacenar tus datos, haz lo siguiente:
- Selecciona una opción de Tipo de ubicación.
- Selecciona una opción de Ubicación.
- Para Elegir una clase de almacenamiento predeterminada para tus datos, selecciona una clase de almacenamiento.
- En Elige cómo controlar el acceso a los objetos, selecciona una opción de Control de acceso.
- Para la Configuración avanzada (opcional), especifica un método de encriptación, una política de retención o etiquetas de bucket.
- Haga clic en Crear.
Sube el archivo
offlinesales_march_parquetque descargaste en el bucketofflinesales_curatedde Cloud Storage que creaste; para ello, sigue los pasos que se indican en Sube objetos desde un sistema de archivos.Crea un lake de Dataplex y asígnale el nombre
operationssiguiendo los pasos que se indican en Crea un lake.En el lake
operations, agrega una zona y asígnale el nombreprocurement. Para ello, sigue los pasos que se indican en Agrega una zona.En la zona
procurement, agrega el bucketofflinesales_curatedde Cloud Storage que creaste como recurso. Para ello, sigue los pasos que se indican en Agrega un recurso.
Selecciona la tabla que quieres explorar
En la consola de Google Cloud, ve a la página Explorar de Dataplex.
En el campo Lake, selecciona el lake
operations.Haz clic en el lake
operations.Navega a la zona
procurementy haz clic en la tabla para explorar sus metadatos.En la siguiente imagen, la zona de adquisición seleccionada tiene una tabla llamada
Offline, que tiene los metadatosorderid,product,quantityordered,unitprice,orderdateypurchaseaddress.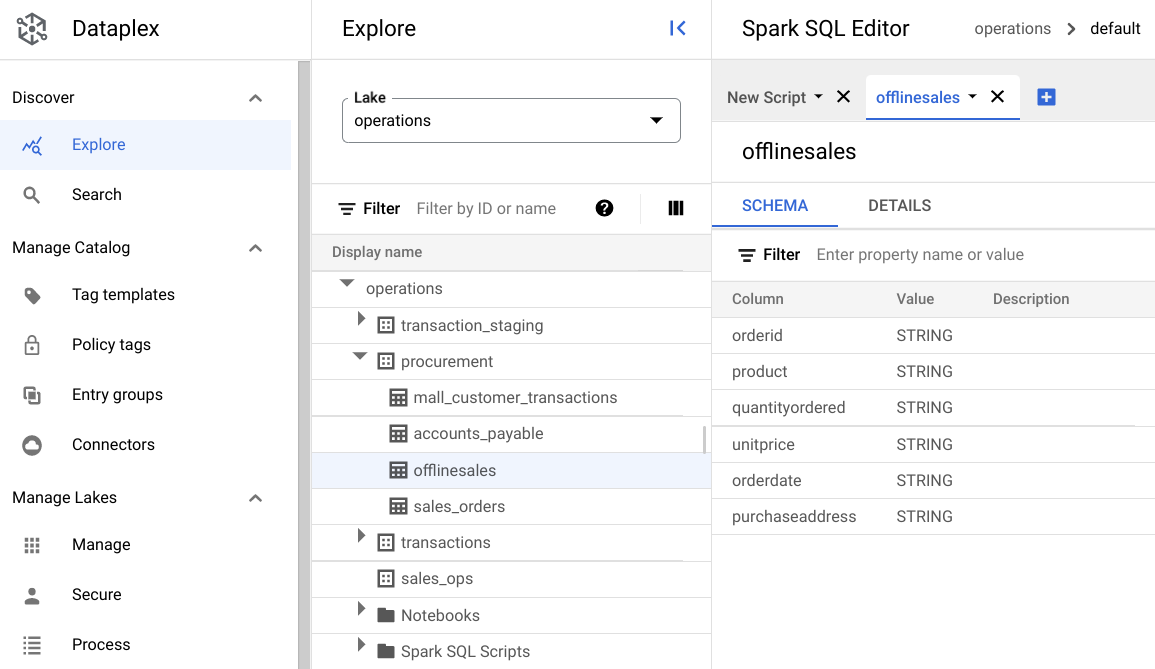
En el editor de Spark SQL, haz clic en Agregar. Aparecerá una secuencia de comandos de Spark SQL.
Opcional: Abre la secuencia de comandos en la vista de pestaña dividida para ver los metadatos y la secuencia de comandos nueva en paralelo. Haz clic en Más en la nueva pestaña de la secuencia de comandos y selecciona Dividir pestaña a la derecha o Pestaña Dividir a la izquierda.
Explora los datos
Un entorno proporciona recursos de procesamiento sin servidores para que tus consultas y notebooks de Spark SQL se ejecuten dentro de un lake. Antes de escribir consultas de Spark SQL, crea un entorno para ejecutar tus consultas.
Explora tus datos con las siguientes consultas de SparkSQL. En el Editor de SparkSQL, ingresa la consulta en el panel Nueva secuencia de comandos.
10 filas de muestra de la tabla
Ingresa la siguiente consulta:
select * from procurement.offlinesales where orderid != 'orderid' limit 10;Haz clic en Ejecutar.
Obtén la cantidad total de transacciones en el conjunto de datos
Ingresa la siguiente consulta:
select count(*) from procurement.offlinesales where orderid!='orderid';Haz clic en Ejecutar.
Determinar la cantidad de diferentes tipos de productos en un conjunto de datos
Ingresa la siguiente consulta:
select count(distinct product) from procurement.offlinesales where orderid!='orderid';Haz clic en Ejecutar.
Identifica los productos que tienen un valor de transacción alto
Para tener una idea de qué productos tienen un gran valor de transacción, desglosa las ventas por tipo de producto y precio de venta promedio.
Ingresa la siguiente consulta:
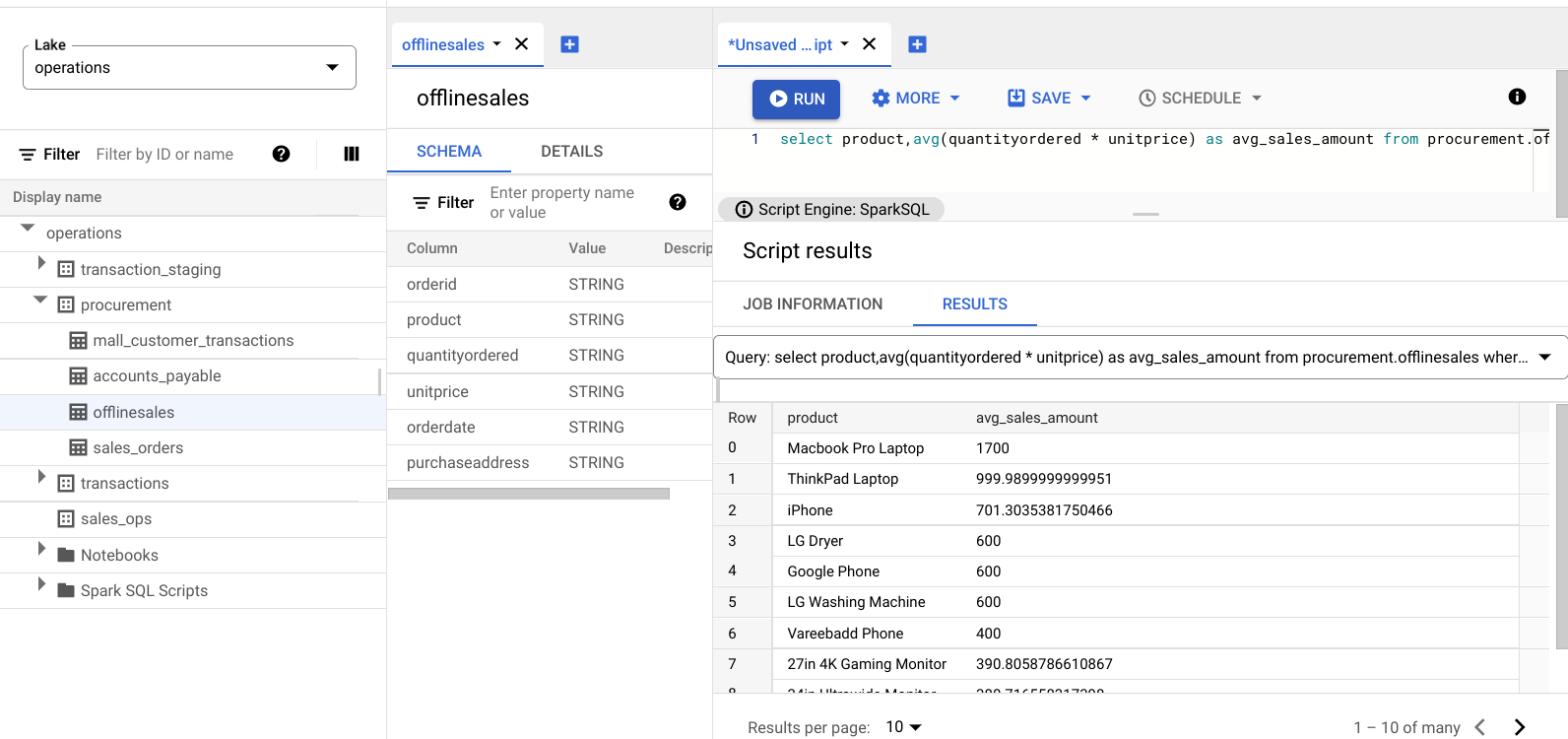
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;Haz clic en Ejecutar.
En la siguiente imagen, se muestra un panel Results que usa una columna llamada product para identificar los elementos de venta con valores de transacción grandes, que se muestran en la columna llamada avg_sales_amount.
Detecta anomalías con el coeficiente de variación
La última consulta mostró que las laptops tienen un importe promedio alto por transacciones. La siguiente consulta muestra cómo detectar transacciones de laptop que no sean anómalas en el conjunto de datos.
En la siguiente consulta, se usa la métrica "coeficiente de variación", rsd_value, para encontrar transacciones que no sean inusuales, en las que la dispersión de los valores es baja en comparación con el valor promedio. Un coeficiente de variación más bajo
indica menos anomalías.
Ingresa la siguiente consulta:
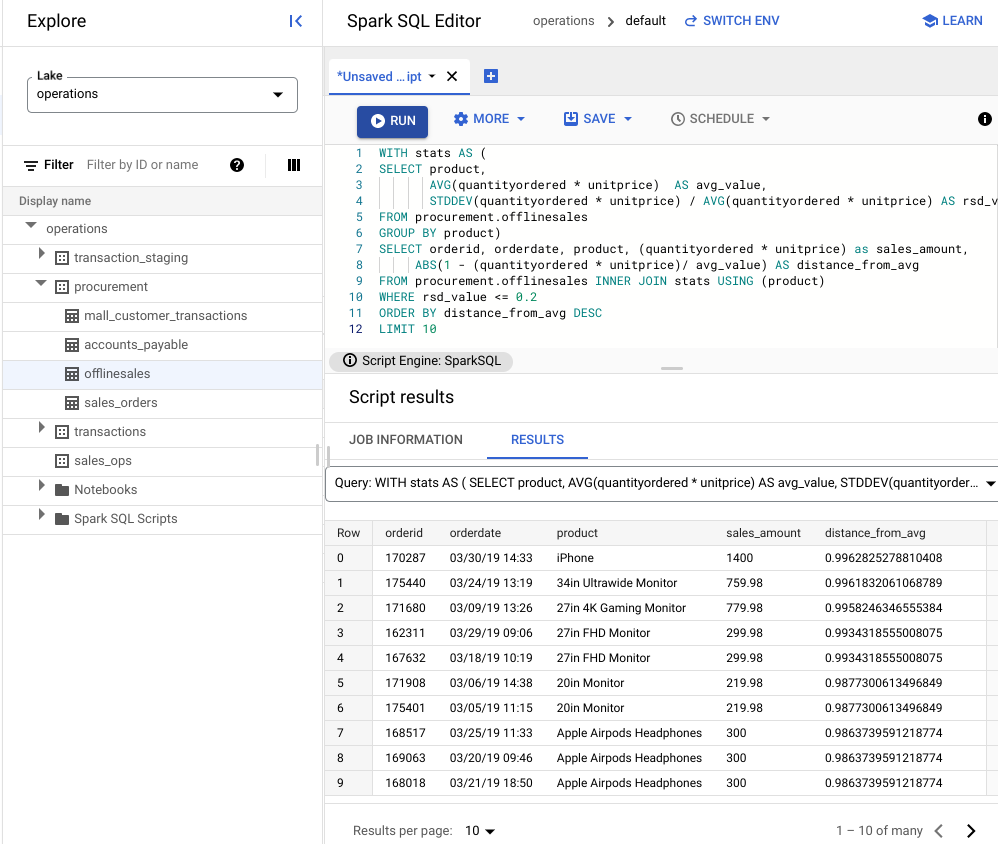
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10Haz clic en Ejecutar.
Consulta los resultados de la secuencia de comandos.
En la siguiente imagen, el panel de resultados utiliza una columna llamada producto para identificar los artículos de venta con valores de transacción que se encuentran dentro del coeficiente de variación de 0.2.
Visualiza anomalías con un notebook de JupyterLab
Crear un modelo de AA para detectar y visualizar anomalías a gran escala
Abre el notebook en otra pestaña y espera a que se cargue. La sesión en la que ejecutaste las consultas de Spark SQL continúa.
Importa los paquetes necesarios y conéctate a la tabla externa de BigQuery que contiene los datos de las transacciones. Ejecuta el siguiente código:
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()Ejecuta el algoritmo del bosque de aislamiento para descubrir las anomalías en el conjunto de datos:
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())Traza las anomalías predichas con una visualización de Matplotlib:
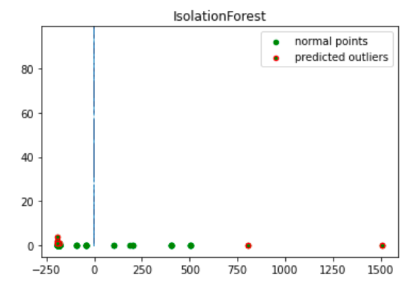
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
En esta imagen, se muestran los datos de la transacción con las anomalías destacadas en rojo.
Programa el notebook
Explorar te permite programar un notebook para que se ejecute periódicamente. Sigue los pasos para programar el notebook de Jupyter que creaste.
Dataplex crea una tarea de programación para ejecutar tu notebook de forma periódica. Para supervisar el progreso de la tarea, haz clic en Ver programaciones.
Compartir o exportar el notebook
Explorar te permite compartir un notebook con otras personas en tu organización mediante los permisos de IAM.
Revisa los roles. Otorga o revoca los roles de visualizador de Dataplex
(roles/dataplex.viewer), de editor de Dataplex
(roles/dataplex.editor) y de administrador de Dataplex
(roles/dataplex.admin) a los usuarios de este notebook. Después de compartir un notebook, los usuarios con funciones de visualizador o editor a nivel del lake pueden navegar al lake y trabajar en el notebook compartido.
Para compartir o exportar un notebook, consulta Comparte un notebook o Exporta un notebook.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
Borra un proyecto de Google Cloud:
gcloud projects delete PROJECT_ID
Borra los recursos individuales
- Borra el depósito
gcloud storage buckets delete BUCKET_NAME
- Borra la instancia:
gcloud compute instances delete INSTANCE_NAME
¿Qué sigue?
- Obtén más información sobre Dataplex Explore.
- Programa secuencias de comandos y notebooks.