O Dataplex é uma malha de dados que unifica dados distribuídos e automatiza o gerenciamento e a governança desses dados.
Com o Dataplex, você pode:
- Crie uma malha de dados específica do domínio entre os dados armazenados em vários projetos doGoogle Cloud , sem qualquer movimentação de dados.
- Controlar e monitorar os dados de forma consistente com um único conjunto de permissões.
- Descubra e selecione metadados em vários silos usando os recursos de catálogo. Para mais informações, consulte Visão geral do Dataplex Catalog.
- Consulte metadados com segurança usando o BigQuery e ferramentas de código aberto, como Spark SQL, Presto e HiveQL.
- Executar tarefas de qualidade de dados e de gerenciamento do ciclo de vida dos dados, incluindo tarefas do Spark sem servidor.
- (Descontinuado) Analise dados usando ambientes do Spark totalmente gerenciados e sem servidor com acesso a notebooks e consultas do Spark SQL.
Por que usar o Dataplex?
As empresas têm dados distribuídos entre data lakes, data warehouses e data marts. Com o Dataplex, você pode:
- Descobrir dados
- Selecionar dados
- Unificar dados sem movimentação de dados
- Organizar dados com base nas necessidades da sua empresa
- Gerenciar, monitorar e controlar dados de maneira centralizada
O Dataplex permite padronizar e unificar metadados, políticas de segurança, governança, classificação e gerenciamento do ciclo de vida desses dados distribuídos.
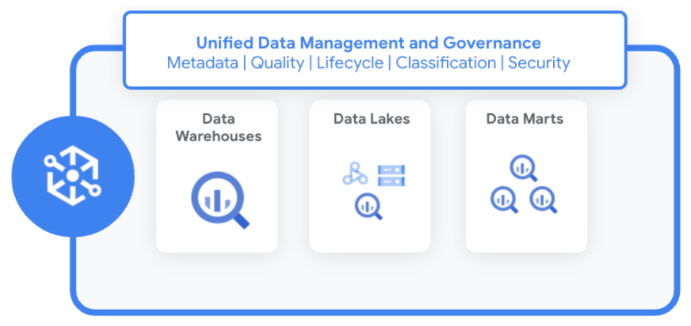
Como o Dataplex funciona
O Dataplex gerencia dados de uma forma que não exige movimentação ou duplicação de dados. Conforme você identifica novas fontes de dados, o Dataplex coleta os metadados de dados estruturados e não estruturados, usando verificações de qualidade de dados integradas para melhorar a integridade.
O Dataplex registra automaticamente todos os metadados em um metastore unificado. É possível acessar dados e metadados usando vários serviços e ferramentas, incluindo:
- Google Cloud serviços e recursos, como o BigQuery, a Metastore do Dataproc e o Dataplex Catalog.
- Ferramentas de código aberto, como Apache Spark e Presto.
Terminologia
O Dataplex abstrai os sistemas de armazenamento de dados subjacentes usando os seguintes conceitos:
Lake: um modelo lógico que representa um domínio de dados ou uma unidade de negócios. Por exemplo, para organizar dados com base no uso do grupo, é possível configurar um lake para cada departamento (por exemplo, varejo, vendas, finanças).
Zona: um subdomínio em um lake, que é útil para categorizar dados por:
- Fase: por exemplo, página de destino, dados brutos, análise de dados selecionados e ciência de dados selecionados
- Uso: por exemplo, contrato de dados
- Restrições: por exemplo, controles de segurança e níveis de acesso do usuário
Há dois tipos de zonas:
Zona bruta: contém dados no formato bruto e não está sujeita a verificações de tipo rigorosas.
Zona selecionada: contém dados limpos, formatados e prontos para análise. Os dados são colunares, particionados pelo Hive e armazenados em arquivos Parquet, Avro, ORC ou tabelas do BigQuery. Os dados passam por verificação de tipo, por exemplo, para proibir o uso de arquivos CSV porque eles não têm um bom desempenho para acesso SQL.
Recurso: mapeia para dados armazenados no Cloud Storage ou no BigQuery. É possível mapear dados armazenados em projetos Google Cloud separados como recursos em uma única zona.
Entidade: representa metadados de dados estruturados e semiestruturados (por exemplo, tabela) e não estruturados (por exemplo, conjunto de arquivos).
Casos de uso comuns
Esta seção descreve casos de uso comuns do Dataplex.
Uma malha de dados centrada no domínio
Com esse tipo de malha de dados, os dados são organizados em vários domínios em uma
empresa, por exemplo, Sales, Customers e Products. Você pode
descentralizar a propriedade dos dados. É possível assinar dados de diferentes
domínios. Por exemplo, cientistas e analistas de dados podem extrair dados de diferentes
domínios para alcançar objetivos de negócios, como machine learning e inteligência
de negócios.
No diagrama a seguir, os domínios são representados por data lakes do Dataplex e são de propriedade de produtores de dados separados. Os produtores de dados são responsáveis pela criação, seleção e controle de acesso nos domínios. Os consumidores de dados podem solicitar acesso aos lakes (domínios) ou zonas (subdomínios) para análise.
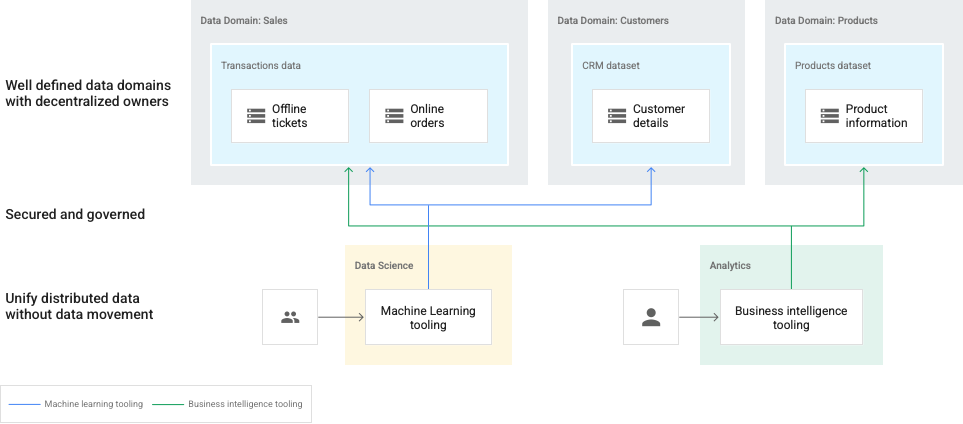
Nesse caso, os administradores de dados precisam manter uma visão holística de todo o cenário de dados.
Este diagrama inclui os seguintes elementos:
- Dataplex: uma malha de vários domínios de dados
- Domínio: data lakes para dados
Sales,CustomerseProduct - Zona em um domínio: para equipes individuais ou para fornecer contratos de dados gerenciados
- Recursos: dados armazenados em um bucket do Cloud Storage ou em um conjunto de dados do BigQuery, que pode existir em um projeto Google Cloudseparado da malha do Dataplex.
É possível ampliar esse cenário dividindo os dados que estão nas zonas em camadas brutas e selecionadas. Para isso, crie zonas para cada permutação de um domínio e dados brutos ou selecionados:
- Vendas brutas
- Vendas selecionadas
- Clientes brutos
- Clientes selecionados
- Produtos brutos
- Produtos selecionados
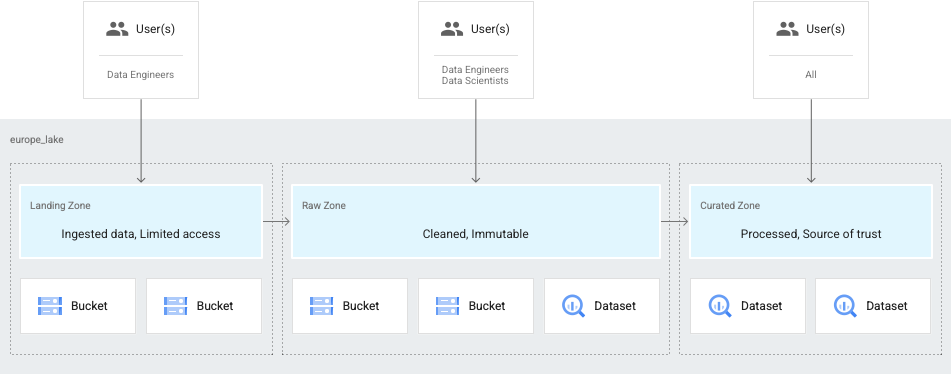
Classificação de dados com base na prontidão
Outro caso de uso comum é quando seus dados só podem ser acessados por engenheiros de dados e são refinados e disponibilizados para cientistas de dados e analistas. Nesse caso, você pode configurar um data lake para ter o seguinte:
- Uma zona de destino para os dados que os engenheiros podem acessar.
- Uma zona bruta para os dados disponíveis para cientistas e analistas de dados.
A seguir
- Começar a usar o Dataplex
- Criar uma malha de dados
- Criar um lake
- Conheça os recursos do catálogo no Dataplex