快速入门:使用 SQL
在本快速入门中,您将学习如何编写 SQL 语法来查询公开提供的 Pub/Sub 主题。SQL 查询会运行 Dataflow 流水线,并且流水线的结果会写入 BigQuery 表中。
您可以使用 Google Cloud Console、本地机器上安装的 Google Cloud CLI 或 Cloud Shell 来运行 Dataflow SQL 作业。除了 Cloud Console 之外,本示例还要求您使用本地机器或 Cloud Shell。
准备工作
- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Dataflow、Compute Engine、Cloud Logging、Cloud Storage、Google Cloud Storage JSON、BigQuery、Cloud Pub/Sub、Cloud Resource Manager 和 Google Cloud Data Catalog API。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Dataflow、Compute Engine、Cloud Logging、Cloud Storage、Google Cloud Storage JSON、BigQuery、Cloud Pub/Sub、Cloud Resource Manager 和 Google Cloud Data Catalog API。
安装并初始化 gcloud CLI
下载适用于您的操作系统的
gcloudCLI 软件包,然后安装并配置gcloudCLI。下载可能需要一些时间,具体取决于您的互联网连接。
创建 BigQuery 数据集
在本快速入门中,Dataflow SQL 流水线将 BigQuery 数据集发布到您在下一部分中创建的 BigQuery 表中。
创建名为
taxirides的 BigQuery 数据集:bq mk taxirides
运行流水线
运行一个 Dataflow SQL 流水线,该流水线使用关于出租车行程的公开提供的 Pub/Sub 主题中的数据来计算每分钟的乘客数量。此命令还会创建一个名为
passengers_per_minute的 BigQuery 表来存储数据输出。gcloud dataflow sql query \ --job-name=dataflow-sql-quickstart \ --region=us-central1 \ --bigquery-dataset=taxirides \ --bigquery-table=passengers_per_minute \ 'SELECT TUMBLE_START("INTERVAL 60 SECOND") as period_start, SUM(passenger_count) AS pickup_count, FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime` WHERE ride_status = "pickup" GROUP BY TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'Dataflow SQL 作业可能需要一段时间才能开始运行。
以下是 Dataflow SQL 流水线中使用的值:
dataflow-sql-quickstart:Dataflow 作业的名称us-central1:运行作业的区域taxirides:用作接收器的 BigQuery 数据集的名称passengers_per_minute:BigQuery 表的名称taxirides-realtime:用作来源的 Pub/Sub 主题的名称
SQL 命令查询 Pub/Sub 主题 taxirides-realtime,以获取每 60 秒钟搭车乘客的总数。此公共主题基于纽约市出租车和豪华轿车委员会的开放数据集。
查看结果
验证流水线正在运行。
控制台
在 Cloud Console 中,转到 Dataflow 作业页面。
在作业列表中,点击 dataflow-sql-quickstart。
在作业信息面板中,确认作业状态字段设置为正在运行。
作业可能需要几分钟才能启动。在作业启动之前,作业状态设置为已加入队列。
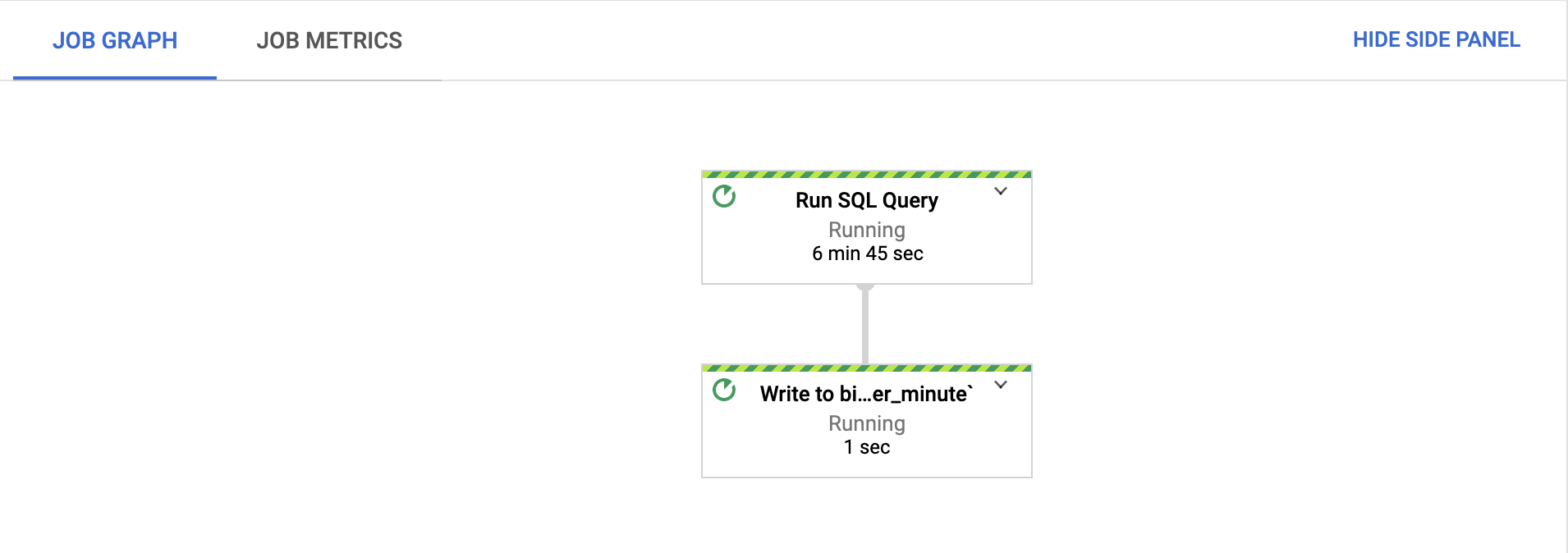
在作业图标签页中,确认每个步骤都在运行。
作业启动后,这些步骤可能需要几分钟才能开始运行。
在 Cloud Console 中,转到 BigQuery 页面。
在编辑器中,粘贴以下 SQL 查询,然后点击运行:
'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'此查询返回
passengers_per_minute表中最繁忙的间隔。
gcloud
获取项目中运行的 Dataflow 作业列表:
gcloud dataflow jobs list获取
dataflow-sql-quickstart作业的更多详细信息:gcloud dataflow jobs describe JOB_ID将
JOB_ID替换为项目中dataflow-sql-quickstart作业的作业 ID。返回
passengers_per_minute表中最繁忙的间隔:bq query \ 'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'
清理
为避免因本页中使用的资源导致您的 Google Cloud 帐号产生费用,请按照以下步骤操作。
要取消 Dataflow 作业,请转到作业页面。
在作业列表中,点击 dataflow-sql-quickstart。
点击停止 > 取消 > 停止作业。
删除
taxirides数据集:bq rm taxirides要确认删除,请输入
y。
后续步骤
- 详细了解如何使用 Dataflow SQL。
- 了解如何在 Dataflow SQL 查询中使用数据来源和目的地。
- 探索适用于 Dataflow SQL 的
gcloudCLI。