Criar um pipeline do Dataflow usando SQL
Neste guia de início rápido, você aprenderá como escrever a sintaxe SQL para consultar um tópico do Pub/Sub disponível publicamente. A consulta SQL executa um pipeline do Dataflow, e os resultados do pipeline são gravados em uma tabela do BigQuery.
Para executar um job do Dataflow SQL, use o console do Google Cloud, a Google Cloud CLI instalada em uma máquina local ou o Cloud Shell. Além do console do Google Cloud, este exemplo requer o uso de uma máquina local ou do Cloud Shell.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager e Google Cloud Data Catalog .
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager e Google Cloud Data Catalog .
Instalar e inicializar a CLI gcloud
Faça o download do pacote da CLI gcloud no sistema operacional e instale e configure a CLI gcloud.
Dependendo da sua conexão de Internet, o download pode demorar um pouco.
Crie um conjunto de dados do BigQuery
Neste guia de início rápido, o pipeline SQL do Dataflow publica um conjunto de dados do BigQuery em uma tabela do BigQuery criada na próxima seção.
Crie um conjunto de dados do BigQuery chamado
taxirides:bq mk taxirides
Executar o canal
Executar um pipeline do Dataflow SQL que calcule o número de passageiros por minuto usando dados de um tópico do Pub/Sub disponível publicamente sobre corridas de táxi. Esse comando também cria uma tabela do BigQuery chamada
passengers_per_minutepara armazenar a saída de dados.gcloud dataflow sql query \ --job-name=dataflow-sql-quickstart \ --region=us-central1 \ --bigquery-dataset=taxirides \ --bigquery-table=passengers_per_minute \ 'SELECT TUMBLE_START("INTERVAL 60 SECOND") as period_start, SUM(passenger_count) AS pickup_count, FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime` WHERE ride_status = "pickup" GROUP BY TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'Pode levar algum tempo para que o job do Dataflow SQL comece a ser executado.
Veja a seguir os valores usados no pipeline do Dataflow SQL:
dataflow-sql-quickstart: o nome do job do Dataflowus-central1: a região em que o job é executado.taxirides: o nome do conjunto de dados do BigQuery usado como coletorpassengers_per_minute: o nome da tabela do BigQuery.taxirides-realtime: o nome do tópico Pub/Sub usado como origem
O comando SQL consulta o tópico
taxirides-realtime do Pub/Sub para atingir o número total de passageiros
retirados a cada 60 segundos. Este tópico público é baseado
no conjunto de dados abertos da Comissão de Táxis e Limusines de Nova York.
Ver os resultados
Verifique se o pipeline está em execução.
Console
No console do Google Cloud, acesse a página Jobs do Dataflow.
Na lista de jobs, clique em dataflow-sql-quickstart.
No painel Informações do job, verifique se o campo Status do job está definido como Em execução.
O job pode levar vários minutos para iniciar. O Status do job é definido como Na fila até que ele seja iniciado.
Na guia gráfico do Job, confirme se todas as etapas estão em execução.
Após o início do job, as etapas podem levar vários minutos para começar a ser executadas.
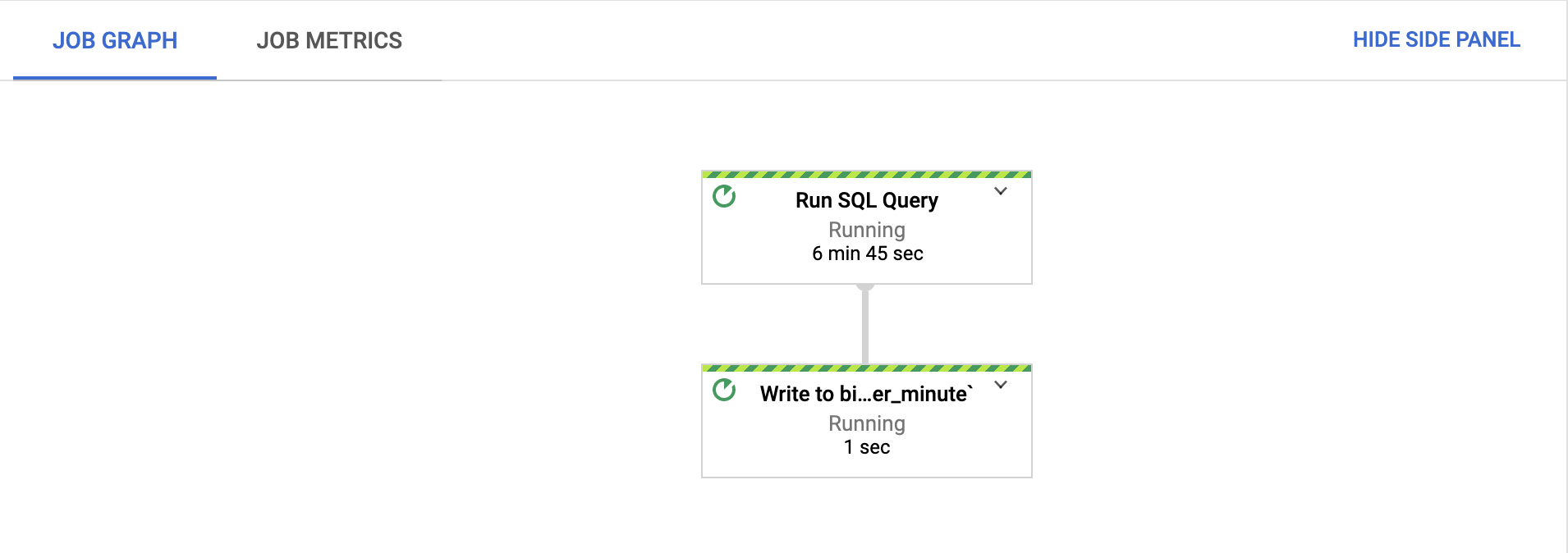
No console do Google Cloud, acesse a página BigQuery.
No Editor, cole a seguinte consulta SQL e clique em Executar:
'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'Essa consulta retorna os intervalos mais ocupados da tabela
passengers_per_minute.
gcloud
Veja a lista de jobs do Dataflow em execução no projeto:
gcloud dataflow jobs listReceba mais informações sobre o job
dataflow-sql-quickstart:gcloud dataflow jobs describe JOB_IDSubstitua
JOB_IDpelo ID do jobdataflow-sql-quickstartdo projeto.Retorne os intervalos mais ocupados da tabela
passengers_per_minute:bq query \ 'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'
Limpar
Para evitar cobranças na conta do Google Cloud pelos recursos usados nesta página, siga estas etapas.
Para cancelar o job do Dataflow, acesse a página Jobs.
Na lista de jobs, clique em dataflow-sql-quickstart.
Clique em Interromper > Cancelar > Interromper job.
Excluir o conjunto de dados
taxirides:bq rm taxiridesPara confirmar a exclusão, digite
y.
A seguir
- Saiba mais sobre como usar o SQL do Dataflow.
- Explore a CLI gcloud para o Dataflow SQL.