Sie können die RunInference API zum Erstellen von Pipelines verwenden, die mehrere Modelle enthalten. Pipelines mit mehreren Modellen sind für Aufgaben wie A/B-Tests und das Erstellen von Gruppen nützlich, um Geschäftsprobleme zu lösen, die mehr als ein ML-Modell erfordern.
Mehrere Modelle verwenden
Die folgenden Codebeispiele zeigen, wie Sie mit der RunInference-Transformation mehrere Modelle zu Ihrer Pipeline hinzufügen.
Wenn Sie Pipelines mit mehreren Modellen erstellen, können Sie eines der beiden folgenden Muster verwenden:
- A/B-Branch-Muster: Ein Teil der Eingabedaten geht an ein Modell und der Rest an ein zweites Modell.
- Sequenzmuster: Die Eingabedaten durchlaufen zwei Modelle, eins nach dem anderen.
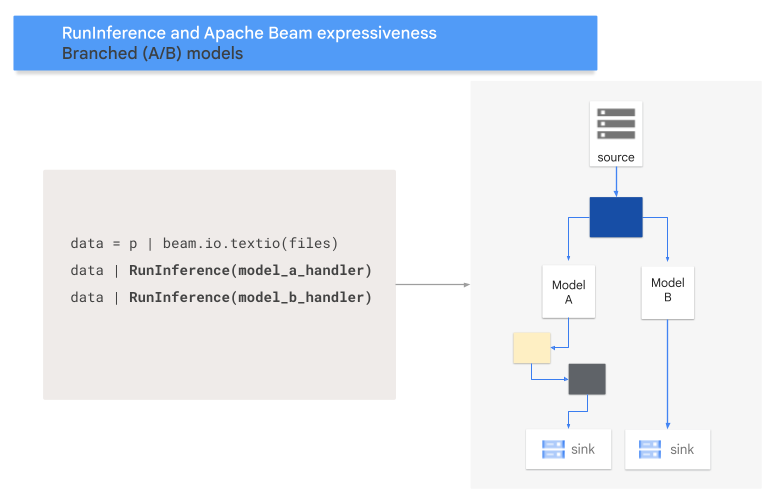
A/B-Muster
Der folgende Code zeigt, wie Sie Ihrer Pipeline mit der RunInference-Transformation ein A/B-Muster hinzufügen.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A und MODEL_HANDLER_B sind der Einrichtungscode des Modell-Handlers.
Das folgende Diagramm bietet eine visuelle Darstellung dieses Prozesses.
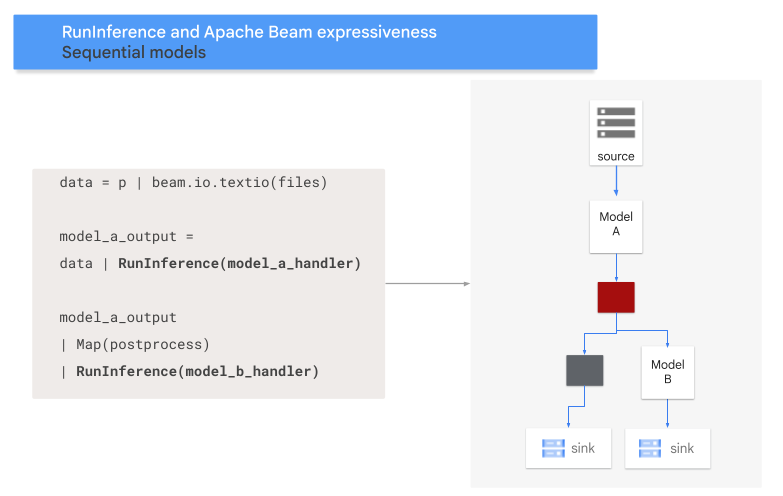
Sequenzmuster
Der folgende Code zeigt, wie Sie Ihrer Pipeline mit der RunInference-Transformation ein Sequenzmuster hinzufügen.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A und MODEL_HANDLER_B sind der Einrichtungscode des Modell-Handlers.
Das folgende Diagramm bietet eine visuelle Darstellung dieses Prozesses.
Modelle zu Schlüsseln zuordnen
Sie können mehrere Modelle laden und diese mithilfe eines schlüsselbasierten Modell-Handlers Schlüsseln zuordnen.
Durch die Zuordnung von Modellen zu Schlüsseln können Sie verschiedene Modelle in derselben RunInference-Transformation verwenden.
Im folgenden Beispiel wird ein schlüsselbasierter Modell-Handler verwendet, der ein Modell mithilfe von CONFIG_1 und ein zweites Modell mithilfe von CONFIG_2 lädt.
Die Pipeline verwendet das mit CONFIG_1 verknüpfte Modell, um Inferenzen für mit KEY_1 verknüpfte Beispiele auszuführen.
Das mit CONFIG_2 verknüpfte Modell führt Inferenzen für Beispiele durch, die mit KEY_2 und KEY_3 verknüpft sind.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
Ein ausführlicheres Beispiel finden Sie unter ML-Inferenz mit mehreren unterschiedlich trainierten Modellen ausführen.
Arbeitsspeicher verwalten
Wenn Sie mehrere Modelle gleichzeitig laden, können möglicherweise Fehler aufgrund von unzureichendem Arbeitsspeicher (OOMs) auftreten. Wenn Sie einen schlüsselbasierten Modell-Handler verwenden, begrenzt Apache Beam die Anzahl der in den Speicher geladenen Modelle nicht automatisch. Wenn die Modelle nicht alle in den Speicher passen, tritt ein Fehler aufgrund von unzureichendem Arbeitsspeicher auf und die Pipeline schlägt fehl.
Zur Vermeidung dieses Problems verwenden Sie den max_models_per_worker_hint-Parameter, um die Anzahl der Modelle zu begrenzen, die gleichzeitig in den Speicher geladen werden. Im folgenden Beispiel wird ein schlüsselbasierter Modell-Handler mit dem Parameter max_models_per_worker_hint verwendet.
Da der Parameterwert max_models_per_worker_hint auf 2 gesetzt ist, lädt die Pipeline maximal zwei Modelle gleichzeitig in jeden SDK-Worker-Prozess.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
Achten Sie beim Entwerfen der Pipeline darauf, dass die Worker genügend Arbeitsspeicher für die Modelle und die Pipelinetransformationen haben. Da der von den Modellen verwendete Arbeitsspeicher möglicherweise nicht sofort freigegeben wird, fügen Sie einen zusätzlichen Arbeitsspeicherpuffer hinzu, um OOMs zu vermeiden.
Wenn Sie viele Modelle haben und einen niedrigen Wert mit dem Parameter max_models_per_worker_hint verwenden, kann es zu einem Speicher-Seitenflattern kommen. Speicher-Seitenflattern tritt auf, wenn übermäßige Ausführungszeit zum Austauschen von Modellen in den und aus dem Arbeitsspeicher verwendet wird. Zur Vermeidung dieses Problems fügen Sie vor dem Inferenzschritt eine GroupByKey-Transformation in die Pipeline ein. Die GroupByKey-Transformation sorgt dafür, dass sich Elemente mit demselben Schlüssel und Modell auf demselben Worker befinden.
Weitere Informationen
- Informationen zu Pipelines mit mehreren Modellen in der Apache Beam-Dokumentation
- ML-Inferenz mit mehreren unterschiedlich trainierten Modellen ausführen
- Führen Sie ein Interaktives Notebook in Colab aus.